
La signification statistique n'est pas égale à la validité (ou pourquoi vous obtenez des ascenseurs imaginaires)
Publié: 2020-10-06Un scénario très courant : une entreprise exécute des dizaines et des dizaines de tests A/B au cours d'une année, et beaucoup d'entre eux « gagnent ». Certains tests vous permettent d'augmenter vos revenus de 25 %, voire plus.
Pourtant, lorsque vous déployez le changement, les revenus n'augmentent pas de 25 %. Et 12 mois après avoir exécuté tous ces tests, le taux de conversion est toujours à peu près le même. Comment venir?
La réponse est la suivante : vos élévations étaient imaginaires. Il n'y a pas eu d'élévation au départ.
Oui, votre outil de test a indiqué que vous aviez un niveau de signification statistique de 95 % (ou plus). Eh bien, cela ne veut pas dire grand-chose. La signification statistique et la validité ne sont pas les mêmes.
La signification statistique n'est pas une règle d'arrêt.
Lorsque vos tests indiquent que vous avez atteint un niveau de confiance de 95 % ou même de 99 %, cela ne signifie pas que vous avez une variante gagnante.
Voici un exemple que j'ai déjà utilisé. Deux jours après le début d'un test, voici les résultats :

La variation que j'ai construite perdait beaucoup - de plus de 89% (et aucun chevauchement dans la marge d'erreur). Il est dit ici que la variante 1 a 0% de chances de battre le contrôle.
Est-ce un résultat statistiquement significatif ? Oui c'est le cas. Tapez les mêmes chiffres dans n'importe quelle calculatrice de test A/B, et ils diront la même chose. Voici les résultats à l'aide de ce calculateur de signification :
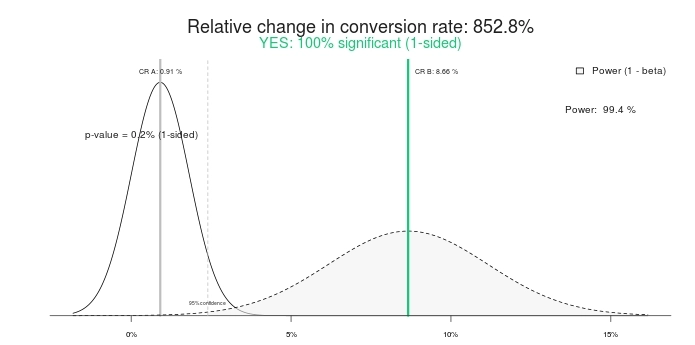
Donc, un test significatif à 100 % et une augmentation de 852,8 % (ou plutôt, le contrôle est supérieur à > 800 % par rapport au traitement). Finissons le test, d'accord ? Le contrôle gagne ! Ou que diriez-vous de lui donner un peu plus de temps à la place ?
Voici à quoi cela ressemblait 10 jours plus tard :

C'est vrai, la variation qui avait 0 % de chance de battre le contrôle gagnait maintenant avec 95 % de confiance. Qu'est-ce qui se passe avec ça? Comment se fait-il que "100 % d'importance" et "0 % de chances de gagner" n'aient plus de sens ? Parce qu'ils sont.
Si vous terminez le test plus tôt, il y a de fortes chances que vous choisissiez le mauvais gagnant. Dans ce scénario, de nombreuses entreprises (la plupart ?) vont encore de l'avant et mettent en œuvre le changement (c'est-à-dire déployer la variante gagnante à 100 % du trafic), alors qu'en fait, l'augmentation de 800 % devient nulle, voire négative (perdante).
Encore pire que l'ascenseur imaginaire, c'est la fausse confiance que vous avez maintenant. Vous pensez avoir appris quelque chose et continuez à appliquer cet apprentissage ailleurs sur le site. Mais l'apprentissage est en fait invalide, rendant ainsi tous vos efforts et votre temps une perte totale.
C'est la même chose avec la deuxième capture d'écran de test (10 jours après) - même si elle indique une signification de 95 %, elle n'est toujours pas "cuite". L'échantillon est trop petit ; la différence absolue dans les conversions n'est que de 19 transactions. Cela peut changer en un jour.

Ton Wesseling a ceci à dire à ce sujet :
Vous devez savoir qu'arrêter un test une fois qu'il est significatif est le péché mortel numéro 1 dans le monde des tests A/B. Soixante-dix-sept pour cent des tests A/A (même page contre même page) atteindront la signification à un certain point.
Apprenez ce qu'est vraiment la signification.
La signification statistique seule ne devrait pas déterminer si vous terminez un test ou non. Ce n'est pas une règle d'arrêt.
La signification statistique ne nous dit pas la probabilité que B soit meilleur que A. Elle ne nous dit pas non plus la probabilité que nous fassions une erreur en sélectionnant B plutôt que A.
Ce sont deux idées fausses extraordinairement courantes, mais elles sont fausses. Pour savoir ce que sont vraiment les p-values, lisez cet article.
Exécutez vos tests plus longtemps.
Si vous arrêtez vos tests après quelques jours, vous vous trompez. Peu importe si vous obtenez 10 000 transactions par jour. Le nombre absolu de transactions compte, mais vous avez également besoin de temps pur.

Matt Gershoff de Conductrics explique pourquoi :
L'une des difficultés avec l'exécution des tests en ligne est que nous ne contrôlons pas nos cohortes d'utilisateurs. Cela peut être un problème si les utilisateurs répartissent différemment selon l'heure et le jour de la semaine, et même selon la saison. Pour cette raison, nous voulons probablement nous assurer que nous collectons nos données sur tous les cycles de données pertinents. De cette façon, nos traitements sont exposés à un échantillon plus représentatif de la population moyenne d'utilisateurs.
Notez que la segmentation ne nous sort pas vraiment de là, car nous devrons encore échantillonner les jours de semaine, les week-ends, etc., et nous voulons probablement frapper chaque jour ou partie de la journée plusieurs fois pour faire la moyenne des événements externes. susceptibles d'affecter le flux de trafic/la conversion afin d'obtenir de bonnes estimations de l'impact temporel des fonctionnalités/segments sur la conversion.
Je vois tout le temps le scénario suivant :
- Premiers jours : B gagne gros. Généralement en raison du facteur de nouveauté.
- Après la semaine #1 : B gagne fort.
- Après la semaine #2 : B gagne toujours, mais la différence relative est plus petite.
- Après la semaine #4 : Régression vers la moyenne — le soulèvement a disparu.
Donc, si vous arrêtez le test avant quatre semaines (peut-être même après quelques jours), vous pensez avoir une variante gagnante, mais ce n'est pas le cas. Si vous le déployez en direct, vous avez ce que j'appelle un "ascenseur imaginaire". Vous pensez que vous avez un coup de pouce parce que votre outil de test a affiché une croissance > 25 %, mais vous ne voyez pas de croissance dans votre compte bancaire.
Exécutez vos tests plus longtemps. Assurez-vous qu'ils incluent deux cycles économiques, qu'ils ont suffisamment de conversions/transactions absolues et qu'ils ont eu une durée suffisante dans le temps.

Exemple d'ascenseur imaginaire
Voici un test que nous avons effectué pour un client de commerce électronique. La durée du test était de 35 jours, ciblait uniquement les visiteurs de bureau et comptait près de 3 000 transactions par variante.
Spoiler: Le test s'est terminé par "aucune différence". Voici l'aperçu d'Optimizely pour les revenus (cliquez pour agrandir) :

Voyons maintenant :
- Premiers jours : Blue (variante #3) gagne gros, comme 16 $ par visiteur contre 12,5 $ pour Control (#Winning !). Beaucoup de gens terminent le test ici (#Fail!).
- Après 7 jours : Bleu gagne toujours, et la différence relative est grande.
- Après 14 jours : Orange (#4) gagne !
- Après 21 jours : Orange toujours gagnant !
- Fin : Aucune différence.
Donc, si vous aviez fait le test pendant moins de quatre semaines, vous auriez mal appelé le gagnant.
Les règles d'arrêt
Alors, quand un test est-il cuit ?
Hélas, il n'y a pas de réponse céleste universelle là-bas, et il y a beaucoup de facteurs "ça dépend". Cela dit, vous pouvez avoir de très bonnes règles d'arrêt dans la plupart des cas.
Voici mes règles d'arrêt :
- Durée du test d'au moins 3 semaines (mieux si 4).
- Taille d'échantillon minimale précalculée atteinte (à l'aide d'outils différents). Je ne croirai aucun test qui compte moins de 250 à 400 conversions par variation.
- Signification statistique d'au moins 95 %.
Cela peut être différent pour certains tests en raison de particularités, mais dans la plupart des cas, j'adhère à ces règles.
Voici Wesseling qui intervient à nouveau :
Vous souhaitez tester le plus longtemps possible - au moins un cycle d'achat - plus vous avez de données, plus la puissance statistique de votre test est élevée !
Plus de trafic signifie que vous avez plus de chances de reconnaître votre gagnant au niveau de signification sur lequel vous testez ! De petits changements peuvent avoir un impact important, mais les impacts importants ne se produisent pas trop souvent - la plupart du temps, votre variation est légèrement meilleure, vous avez donc besoin de beaucoup de données pour remarquer un gagnant significatif.
Mais si vos tests durent et durent, les gens ont tendance à supprimer leurs cookies (10% en deux semaines). Lorsqu'ils reviennent dans votre test, ils peuvent se retrouver dans la mauvaise variation. Ainsi, au fil des semaines, vos échantillons polluent de plus en plus et se retrouvent avec les mêmes taux de conversion.
Testez pendant 4 semaines maximum.
Que se passe-t-il si, après trois ou quatre semaines, la taille de l'échantillon est inférieure à 400 conversions par variante ?
J'ai laissé le test durer plus longtemps. Si, à 4 semaines, la taille de l'échantillon n'est pas atteinte, j'ajoute une autre semaine.
Testez toujours des semaines complètes . Si vous commencez le test un lundi, il devrait se terminer un dimanche. Si vous ne testez pas une semaine complète à la fois, vous risquez de fausser vos résultats.
Générez un rapport sur les conversions par jour de la semaine sur votre site. Voyez combien il y a de fluctuations.
Que voyez-vous ci-dessous ? Le jeudi rapporte 2 fois plus d'argent que le samedi et le dimanche, et le taux de conversion le jeudi est presque 2 fois meilleur que le samedi.

Si nous ne testions pas pendant des semaines complètes, les résultats seraient inexacts. Testez des semaines complètes à la fois.
Les mêmes règles d'arrêt s'appliquent pour chaque segment.
La segmentation est essentielle pour apprendre des tests A/B. Il est courant que B perde face à A dans les résultats globaux, mais bat A dans certains segments (par exemple, le trafic Facebook, les utilisateurs d'appareils mobiles, etc.).
Avant de pouvoir analyser des données segmentées, assurez-vous que vous disposez d'un échantillon suffisamment important dans chaque segment. Vous avez donc besoin de 250 à 400 conversions par variation dans chaque segment que vous examinez.
Je vous recommande même de créer des tests ciblés (définissez le public/segment cible dans la configuration du test) au lieu d'analyser les résultats sur tous les segments après un test. Cela garantit que les tests ne sont pas appelés tôt et que chaque segment a une taille d'échantillon adéquate.
Mon ami André Morys a dit ceci à propos de ses règles d'arrêt :

Je dis toujours aux gens que vous avez besoin d'un échantillon représentatif si vos données doivent être valides.
Que veut dire "représentant" ? Tout d'abord, vous devez inclure tous les jours de la semaine et les week-ends. Vous avez besoin d'une météo différente car elle a un impact sur le comportement des acheteurs. Mais le plus important, votre trafic doit avoir toutes les sources de trafic, en particulier la newsletter, les campagnes spéciales, la télévision… tout ! Plus le test est long, plus vous obtenez d'informations.
Nous venons de faire un test pour un grand détaillant de mode au milieu de la phase de soldes d'été. Il était très intéressant de voir comment les résultats ont chuté de façon spectaculaire pendant la « phase de vente ferme » avec 70 % et plus, mais ont récupéré une semaine après la fin de la phase. Nous n'aurions jamais appris cela si le test n'avait pas duré près de quatre semaines.
Notre « règle empirique » est la suivante : 3 000 à 4 000 conversions par variante et une durée de test de 3 à 4 semaines. C'est suffisamment de trafic pour que nous puissions même parler de données valides si nous explorons les segments.
Tester le « péché » 1 : rechercher des augmentations dans les segments lorsque vous n'avez aucune validité statistique (par exemple, 85 par rapport à 97 conversions). C'est n'importe quoi.
Apprendre des tests est super important, encore plus que d'obtenir des victoires. Et la segmentation de vos données de test est l'un des meilleurs moyens d'apprendre. Assurez-vous simplement que vos segments contiennent suffisamment de données avant de tirer des conclusions.
Conclusion
Ne l'arrêtez pas simplement parce que votre test atteint un niveau de signification de 95 % ou plus. Faites attention au nombre absolu de conversions par variation et à la durée du test également.