
統計的有意性は妥当性(または想像上の上昇を得る理由)と等しくありません
公開: 2020-10-06非常に一般的なシナリオ:企業は1年間に数十から数十のA / Bテストを実行し、それらの多くは「勝ち」ます。 一部のテストでは、収益が25%以上向上します。
ただし、変更を展開しても、収益は25%増加しません。 そして、これらすべてのテストを実行してから12か月後も、コンバージョン率はほぼ同じです。 どうして?
答えはこれです:あなたの隆起は想像上のものでした。 そもそも隆起はありませんでした。
はい、あなたのテストツールはあなたが95%(またはそれ以上)の統計的有意水準を持っていると言いました。 まあ、それはあまり意味がありません。 統計的有意性と妥当性は同じではありません。
統計的有意性は停止規則ではありません。
テストで95%または99%の信頼水準に達したと示された場合、それはあなたが勝利のバリエーションを持っていることを意味しません。
これは私が以前に使用した例です。 テストを開始してから2日後、次の結果が得られました。

私が作成したバリエーションは、89%以上(許容誤差の重複なし)、ひどく失われていました。 ここでは、バリエーション1がコントロールを打ち負かす可能性が0%であると述べています。
これは統計的に有意な結果ですか? はい、そうです。 同じ数字をA/Bテスト計算機に打ち込むと、同じ数字になります。 この有意性計算機を使用した結果は次のとおりです。
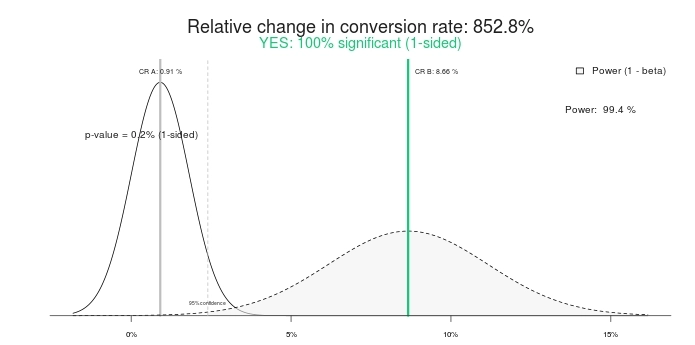
したがって、100%の有意なテスト、および852.8%の上昇率(つまり、コントロールは治療よりも800%以上優れています)。 テストを終了しましょう。 コントロールが勝ちます! または、代わりにもう少し時間を与えてはどうでしょうか。
これは、10日後の様子です。

そうです、コントロールを破る可能性が0%だったバリエーションは、95%の自信を持って勝っていました。 どうしたの? 「100%の意義」と「0%の勝率」が無意味になったのはなぜですか? 彼らがいるからです。
テストを早期に終了すると、間違った勝者を選ぶ可能性が高くなります。 このシナリオでは、多くの(ほとんどの?)企業がまだ先に進んで変更を実装しています(つまり、勝利のバリエーションをトラフィックの100%に展開します)が、実際には、800%の伸びはゼロ、またはマイナス(負け)にさえなります。
想像上のリフトよりもさらに悪いのは、あなたが今持っている誤った自信です。 あなたは何かを学んだと思い、その学習をサイトの他の場所に適用し続けます。 しかし、学習は実際には無効であるため、すべての努力と時間を完全に無駄にします。
2番目のテストスクリーンショット(10日後)でも同じです。95%の重要性が示されていますが、まだ「調理済み」ではありません。 サンプルが小さすぎます。 コンバージョンの絶対差はわずか19トランザクションです。 それは1日で変わる可能性があります。

トンウェッセリングはそれについてこう言っています:
重要なテストを停止することは、A/Bテストの土地で致命的な罪の1番であることを知っておく必要があります。 A / Aテストの77%(同じページに対して同じページ)は、特定の時点で重要性に達します。
本当に重要なことを学びましょう。
統計的有意性だけでは、テストを終了するかどうかを決定することはできません。 それは停止規則ではありません。
統計的有意性は、BがAよりも優れている確率を示していません。また、AよりもBを選択する際に間違いを犯す可能性も示していません。
これらは両方とも非常に一般的な誤解ですが、誤りです。 p値が実際に何であるかを知るには、この投稿を読んでください。
テストをより長く実行します。
数日後にテストを停止すると、間違った結果になります。 1日あたり10,000件のトランザクションを取得するかどうかは関係ありません。 トランザクションの絶対数は重要ですが、純粋な時間も必要です。

ConductricsのMattGershoffが理由を説明します。
オンラインでテストを実行する際の問題の1つは、ユーザーコホートを管理できないことです。 これは、ユーザーが時間と曜日、さらには季節によっても異なる方法で配布する場合に問題になる可能性があります。 このため、関連するデータサイクルにわたってデータを確実に収集する必要があります。 このようにして、私たちの治療は、平均的なユーザー集団のより代表的なサンプルにさらされます。
平日や週末などでもサンプリングする必要があるため、セグメンテーションでは実際にはこれから抜け出せないことに注意してください。おそらく、毎日または日の一部を数回ヒットして、平均化および外部イベントを実行する必要があります。これは、コンバージョンへの影響時間ベースの機能/セグメントの適切な見積もりを取得するために、トラフィックフロー/コンバージョンに影響を与える可能性があります。
私はいつも次のシナリオを見ています:
- 最初の数日:Bが大勝しています。 通常、目新しさの要因によるものです。
- 1週目以降:Bが強く勝ちました。
- 2週目以降:Bはまだ勝っていますが、相対的な差は小さくなっています。
- 第4週以降:平均への回帰—隆起は消えました。
したがって、4週間前に(おそらく数日後でも)テストを停止した場合、勝利のバリエーションがあると思いますが、そうではありません。 ライブで展開すると、私が「架空のリフト」と呼んでいるものがあります。 テストツールが25%を超える成長を示したため、上昇したと思いますが、銀行口座の成長は見られません。

テストをより長く実行します。 2つのビジネスサイクルが含まれ、十分な絶対コンバージョン/トランザクションがあり、時間的に十分な期間があることを確認してください。
架空のリフトの例
これがeコマースクライアントに対して実行したテストです。 テスト期間は35日で、デスクトップの訪問者のみを対象とし、バリエーションごとに3,000近くのトランザクションがありました。
ネタバレ:テストは「違いなし」で終了しました。 収益のOptimizelyの概要は次のとおりです(クリックして拡大)。

今見てみましょう:
- 最初の数日:青(バリエーション#3)が大きな勝利を収めています。たとえば、訪問者1人あたり16ドルであるのに対し、コントロール(#Winning!)は12.5ドルです。 多くの人がここでテストを終了します(#Fail!)。
- 7日後:ブルーはまだ勝っていて、相対的な違いは大きいです。
- 14日後:オレンジ(#4)が勝ちました!
- 21日後:オレンジはまだ勝っています!
- 終了:違いはありません。
したがって、4週間未満のテストを実行した場合、勝者を間違って呼び出すことになります。
停止規則
では、テストはいつ調理されますか?
悲しいかな、そこには普遍的な天の答えはなく、「それは依存する」要因がたくさんあります。 そうは言っても、ほとんどの場合、かなり良い停止ルールを設定できます。
これが私の停止ルールです:
- 少なくとも3週間のテスト期間(4の場合はより良い)。
- 事前に計算された最小サンプルサイズに達しました(さまざまなツールを使用)。 バリエーションあたりのコンバージョン数が250〜400未満のテストは信じられません。
- 少なくとも95%の統計的有意性。
一部のテストでは特殊性のために異なる場合がありますが、ほとんどの場合、私はそれらのルールを順守します。
ヴェッセリングのチャイムが再び鳴り響きます。
できるだけ長く(少なくとも1回の購入サイクルで)テストする必要があります。データが多いほど、テストの統計的検出力が高くなります。
トラフィックが多いということは、テストしている有意水準で勝者を認識する可能性が高いことを意味します。 小さな変更は大きな影響を与える可能性がありますが、大きな影響はそれほど頻繁には発生しません。ほとんどの場合、バリエーションはわずかに優れているため、重要な勝者に気付くには大量のデータが必要です。
しかし、あなたのテストが最後で最後の場合、人々は彼らのクッキーを削除する傾向があります(2週間で10%)。 テストに戻ったときに、間違ったバリエーションになる可能性があります。そのため、数週間が経過すると、サンプルはますます汚染され、同じ変換率になります。
最大4週間テストします。
3週間または4週間後、サンプルサイズがバリエーションあたり400変換未満である場合はどうなるでしょうか?
テストをもっと長く実行させました。 4週間までにサンプルサイズが達成されない場合は、さらに1週間追加します。
常に丸1週間テストしてください。 月曜日にテストを開始する場合は、日曜日に終了する必要があります。 一度に丸1週間テストしないと、結果が歪む可能性があります。
サイトで曜日ごとのコンバージョンレポートを実行します。 どれだけの変動があるかを見てください。
下に何が見えますか? 木曜日は土曜日と日曜日の2倍の収益があり、木曜日のコンバージョン率は土曜日のほぼ2倍です。

丸1週間テストしなかった場合、結果は不正確になります。 一度に丸1週間テストします。
同じ停止ルールが各セグメントに適用されます。
セグメント化は、A/Bテストから学ぶための鍵です。 全体的な結果ではBがAに負けるのが一般的ですが、特定のセグメント(Facebookトラフィック、モバイルデバイスユーザーなど)ではAに勝っています。
セグメント化されたデータを分析する前に、各セグメント内に十分なサンプルサイズがあることを確認してください。 したがって、見ている各セグメント内のバリエーションごとに250〜400の変換が必要です。
テスト後にセグメント全体の結果を分析するのではなく、ターゲットを絞ったテストを作成する(テスト構成でターゲットオーディエンス/セグメントを設定する)ことをお勧めします。 これにより、テストが早期に呼び出されないことが保証され、各セグメントに適切なサンプルサイズがあります。
私の友人のアンドレ・モリスは、彼の停止規則について次のように述べています。

データが有効である必要がある場合は、代表的なサンプルが必要であることを常に人々に伝えます。
「代表」とはどういう意味ですか? まず、すべての平日と週末を含める必要があります。 購入者の行動に影響を与えるため、別の天気が必要です。 しかし、最も重要なことは、トラフィックにはすべてのトラフィックソース、特にニュースレター、特別キャンペーン、テレビなどすべてが含まれている必要があります。 テストの実行時間が長いほど、より多くの洞察が得られます。
夏のセールフェーズの途中で、大手ファッション小売業者のテストを実行しました。 「ハードセールフェーズ」で結果が70%以上と劇的に低下したが、フェーズが終了してから1週間後に回復したことを確認するのは非常に興味深いことでした。 テストが4週間近く実行されていなかったら、これを学ぶことはなかったでしょう。
私たちの「経験則」は次のとおりです。バリエーションごとに3,000〜4,000回の変換、3〜4週間のテスト期間。 これは十分なトラフィックであるため、セグメントにドリルダウンすると、有効なデータについて話すこともできます。
「sin」番号1のテスト:統計的妥当性がない場合のセグメント内の隆起の検索(たとえば、85対97の変換)。 それはでたらめです。
テストから学ぶことは非常に重要です—勝利を得る以上に。 また、テストデータをセグメント化することは、学習するためのより良い方法の1つです。 結論にジャンプする前に、セグメントに十分なデータがあることを確認してください。
結論
テストが95%以上の有意水準に達したからといって、テストを停止しないでください。 バリエーションごとのコンバージョンの絶対数とテスト期間にも注意してください。