
Statistische Signifikanz ist nicht gleich Validität (oder warum Sie imaginäre Aufzüge erhalten)
Veröffentlicht: 2020-10-06Ein sehr häufiges Szenario: Ein Unternehmen führt im Laufe eines Jahres Dutzende von A/B-Tests durch, und viele von ihnen „gewinnen“. Einige Tests bringen Ihnen eine Umsatzsteigerung von 25 % oder sogar noch mehr.
Doch wenn Sie die Änderung einführen, steigt der Umsatz nicht um 25 %. Und 12 Monate nach der Durchführung all dieser Tests ist die Conversion-Rate immer noch ziemlich gleich. Woher?
Die Antwort lautet: Ihre Erhebungen waren imaginär. Es gab zunächst keine Erhebung.
Ja, Ihr Testtool sagte, Sie hätten ein statistisches Signifikanzniveau von 95 % (oder höher). Nun, das hat nicht viel zu bedeuten. Statistische Signifikanz und Validität sind nicht identisch.
Statistische Signifikanz ist keine Stoppregel.
Wenn Ihr Test sagt, dass Sie ein Konfidenzniveau von 95 % oder sogar 99 % erreicht haben, bedeutet das nicht, dass Sie eine gewinnbringende Variante haben.
Hier ist ein Beispiel, das ich zuvor verwendet habe. Zwei Tage nach Beginn eines Tests waren dies die Ergebnisse:

Die von mir erstellte Variante verlor stark – um mehr als 89 % (und keine Überschneidung in der Fehlerspanne). Hier steht, dass Variante 1 eine Chance von 0 % hat, die Kontrolle zu schlagen.
Ist das ein statistisch signifikantes Ergebnis? Ja, so ist es. Geben Sie dieselben Zahlen in einen beliebigen A/B-Testrechner ein, und sie werden dasselbe sagen. Hier sind die Ergebnisse mit diesem Signifikanzrechner:
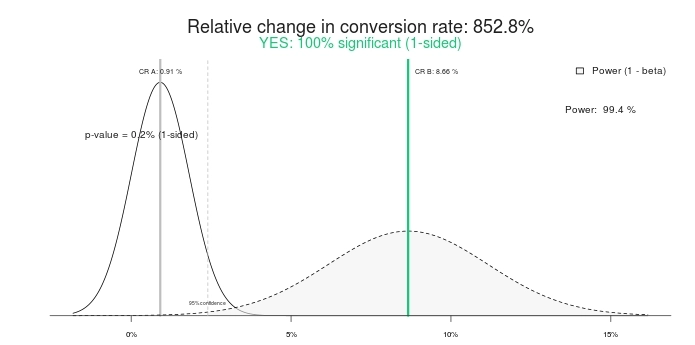
Also ein 100 % signifikanter Test und 852,8 % Prozent Steigerung (oder besser gesagt, die Kontrolle ist über > 800 % besser als die Behandlung). Lassen Sie uns den Test beenden, sollen wir? Kontrolle gewinnt! Oder wie wäre es, wenn wir ihm stattdessen etwas mehr Zeit geben?
So sah es 10 Tage später aus:

Das ist richtig, die Variante, die eine Chance von 0 % hatte, die Kontrolle zu schlagen, gewann jetzt mit 95 % Vertrauen. Was ist damit? Wie kommt es, dass „100 % Bedeutung“ und „0 % Gewinnchance“ bedeutungslos wurden? Weil sie sind.
Wenn Sie den Test vorzeitig beenden, besteht eine große Chance, dass Sie den falschen Gewinner auswählen. In diesem Szenario gehen viele (die meisten?) Unternehmen immer noch vor und implementieren die Änderung (dh führen die gewinnbringende Variante auf 100 % des Traffics aus), während der 800 %-Lift tatsächlich null oder sogar negativ wird (verliert).
Noch schlimmer als der imaginäre Aufstieg ist das falsche Selbstvertrauen, das Sie jetzt haben. Sie denken, Sie hätten etwas gelernt und wenden dieses Gelernte an anderer Stelle auf der Website an. Aber das Lernen ist tatsächlich ungültig, wodurch alle Ihre Bemühungen und Ihre Zeit zu einer völligen Verschwendung werden.
Dasselbe gilt für den zweiten Test-Screenshot (10 Tage später) – obwohl dort eine Signifikanz von 95 % angegeben ist, ist er immer noch nicht „gekocht“. Die Stichprobe ist zu klein; Der absolute Unterschied bei den Conversions beträgt nur 19 Transaktionen. Das kann sich an einem Tag ändern.

Ton Wesseling sagt dazu:
Sie sollten wissen, dass das Abbrechen eines Tests, sobald er signifikant ist, die Todsünde Nummer 1 im Land der A/B-Tests ist. Siebenundsiebzig Prozent der A/A-Tests (gleiche Seite gegen gleiche Seite) erreichen an einem bestimmten Punkt Signifikanz.
Erfahren Sie, was Bedeutung wirklich ist.
Statistische Signifikanz allein sollte nicht darüber entscheiden, ob Sie einen Test beenden oder nicht. Es ist keine Stoppregel.
Die statistische Signifikanz sagt uns nicht die Wahrscheinlichkeit, dass B besser ist als A. Sie sagt uns auch nicht die Wahrscheinlichkeit, dass wir einen Fehler machen, wenn wir B gegenüber A auswählen.
Dies sind beides außerordentlich verbreitete Missverständnisse, aber sie sind falsch. Um zu erfahren, worum es bei p-Werten wirklich geht, lesen Sie diesen Beitrag.
Führen Sie Ihre Tests länger aus.
Wenn Sie Ihre Tests nach ein paar Tagen abbrechen, machen Sie etwas falsch. Es spielt keine Rolle, ob Sie 10.000 Transaktionen pro Tag erhalten. Die absolute Anzahl der Transaktionen zählt, aber Sie brauchen auch reine Zeit.

Matt Gershoff von Conductrics erklärt warum:
Eine der Schwierigkeiten bei der Durchführung von Online-Tests besteht darin, dass wir keine Kontrolle über unsere Benutzerkohorten haben. Dies kann ein Problem sein, wenn die Benutzer nach Zeit und Wochentag und sogar nach Jahreszeit unterschiedlich verteilt sind. Aus diesem Grund möchten wir wahrscheinlich sicherstellen, dass wir unsere Daten über alle relevanten Datenzyklen sammeln. Auf diese Weise werden unsere Behandlungen einer repräsentativeren Stichprobe der durchschnittlichen Benutzerpopulation ausgesetzt.
Beachten Sie, dass die Segmentierung uns nicht wirklich aus dieser Sache herausholt, da wir immer noch über die Wochentage, Wochenenden usw. abtasten müssen und wir wahrscheinlich jeden Tag oder Tagesteil ein paar Mal treffen möchten, um externe Ereignisse zu mitteln die sich auf den Verkehrsfluss/die Konversion auswirken könnten, um gute Schätzungen der zeitbasierten Auswirkungen von Merkmalen/Segmenten auf die Konversion zu erhalten.
Ich sehe immer wieder folgendes Szenario:
- Die ersten paar Tage: B gewinnt groß. In der Regel aufgrund des Neuheitsfaktors.
- Nach Woche #1: B gewinnt stark.
- Nach Woche #2: B gewinnt immer noch, aber der relative Unterschied ist geringer.
- Nach Woche #4: Regression zum Mittelwert – der Uplift ist verschwunden.
Wenn Sie also den Test vor vier Wochen (vielleicht sogar nach ein paar Tagen) beenden, denken Sie, dass Sie eine erfolgreiche Variante haben, aber das stimmt nicht. Wenn Sie es live ausrollen, haben Sie das, was ich einen „imaginären Lift“ nenne. Sie denken, dass Sie einen Auftrieb haben, weil Ihr Testtool ein Wachstum von >25 % anzeigt, aber Sie sehen kein Wachstum auf Ihrem Bankkonto.

Führen Sie Ihre Tests länger aus. Stellen Sie sicher, dass sie zwei Geschäftszyklen umfassen, genügend absolute Conversions/Transaktionen aufweisen und zeitlich ausreichend lang waren.
Beispiel für einen imaginären Aufzug
Hier ist ein Test, den wir für einen E-Commerce-Kunden durchgeführt haben. Die Testdauer betrug 35 Tage, zielte nur auf Desktop-Besucher ab und hatte fast 3.000 Transaktionen pro Variante.
Spoiler: Der Test endete mit „kein Unterschied“. Hier ist die Optimizely-Umsatzübersicht (zum Vergrößern anklicken):

Sehen wir uns jetzt an:
- Die ersten paar Tage: Blau (Variante Nr. 3) gewinnt viel – etwa 16 $ pro Besucher gegenüber 12,5 $ für Control (#Winning!). Viele Leute beenden den Test hier (#Fail!).
- Nach 7 Tagen: Blau gewinnt immer noch, und der relative Unterschied ist groß.
- Nach 14 Tagen: Orange (#4) gewinnt!
- Nach 21 Tagen: Orange gewinnt immer noch!
- Ende: Kein Unterschied.
Hätten Sie den Test also weniger als vier Wochen lang durchgeführt, hätten Sie den Gewinner falsch genannt.
Die Stoppregeln
Also, wann wird ein Test gekocht?
Leider gibt es da draußen keine universelle himmlische Antwort, und es gibt viele „es kommt darauf an“-Faktoren. Das heißt, Sie können für die meisten Fälle einige ziemlich gute Stoppregeln haben.
Hier sind meine Stoppregeln:
- Testdauer mindestens 3 Wochen (besser 4).
- Minimale vorberechnete Stichprobengröße erreicht (mit verschiedenen Tools). Ich werde keinem Test glauben, der weniger als 250–400 Conversions pro Variante hat.
- Statistische Signifikanz von mindestens 95 %.
Bei manchen Tests mag es aufgrund von Besonderheiten anders sein, aber in den meisten Fällen halte ich mich an diese Regeln.
Hier mischt sich Wesseling wieder ein:
Sie möchten so lange wie möglich testen – mindestens einen Kaufzyklus – je mehr Daten, desto höher die statistische Aussagekraft Ihres Tests!
Mehr Verkehr bedeutet, dass Sie eine höhere Chance haben, Ihren Gewinner auf dem Signifikanzniveau zu erkennen, auf dem Sie testen! Kleine Änderungen können eine große Wirkung haben, aber große Wirkungen treten nicht allzu oft auf – meistens ist Ihre Variation etwas besser, sodass Sie viele Daten benötigen, um einen signifikanten Gewinner zu erkennen.
Aber wenn Ihre Tests andauern, neigen die Leute dazu, ihre Cookies zu löschen (10 % in zwei Wochen). Wenn sie in Ihren Test zurückkehren, können sie in der falschen Variation landen – so dass Ihre Proben im Laufe der Wochen immer mehr verschmutzen und am Ende die gleichen Konversionsraten aufweisen.
Testen Sie maximal 4 Wochen lang.
Was ist, wenn – nach drei oder vier Wochen – die Stichprobengröße weniger als 400 Conversions pro Variante beträgt?
Ich habe den Test länger laufen lassen. Wenn nach 4 Wochen die Stichprobengröße nicht erreicht ist, füge ich eine weitere Woche hinzu.
Testen Sie immer volle Wochen. Wenn Sie den Test an einem Montag beginnen, sollte er an einem Sonntag enden. Wenn Sie nicht jeweils eine ganze Woche lang testen, können Sie Ihre Ergebnisse verfälschen.
Führen Sie auf Ihrer Website einen Bericht zu Conversions pro Wochentag aus. Sehen Sie, wie viel Fluktuation es gibt.
Was siehst du unten? Donnerstags verdienen Sie doppelt so viel wie samstags und sonntags, und die Conversion-Rate ist donnerstags fast doppelt so hoch wie an einem Samstag.

Wenn wir nicht volle Wochen lang testen würden, wären die Ergebnisse ungenau. Testen Sie ganze Wochen am Stück.
Für jedes Segment gelten die gleichen Halteregeln.
Segmentierung ist der Schlüssel zum Lernen aus A/B-Tests. Es ist üblich, dass B in den Gesamtergebnissen gegen A verliert, aber A in bestimmten Segmenten schlägt (z. B. Facebook-Verkehr, Benutzer von Mobilgeräten usw.).
Bevor Sie segmentierte Daten analysieren können, stellen Sie sicher, dass Sie in jedem Segment über eine ausreichend große Stichprobengröße verfügen. Sie benötigen also 250–400 Conversions pro Variation in jedem Segment, das Sie sich ansehen.
Ich empfehle sogar, zielgerichtete Tests zu erstellen (Zielgruppe/Segment in der Testkonfiguration festlegen), anstatt die Ergebnisse nach einem Test segmentübergreifend zu analysieren. Dadurch wird sichergestellt, dass Tests nicht vorzeitig aufgerufen werden und jedes Segment über eine angemessene Stichprobengröße verfügt.
Mein Freund Andre Morys sagte folgendes über seine Stoppregeln:

Ich sage den Leuten immer, dass Sie eine repräsentative Probe brauchen, wenn Ihre Daten valide sein sollen.
Was bedeutet „Vertreter“? Zunächst müssen Sie alle Wochentage und Wochenenden einbeziehen. Sie brauchen ein anderes Wetter, weil es das Käuferverhalten beeinflusst. Aber am wichtigsten ist, dass Ihr Traffic alle Traffic-Quellen haben muss, insbesondere Newsletter, Sonderkampagnen, TV … alles! Je länger die Testläufe, desto mehr Einblicke erhalten Sie.
Wir haben gerade mitten in der Sommerschlussverkaufsphase einen Test für einen großen Modehändler durchgeführt. Es war sehr interessant zu sehen, wie die Ergebnisse während der „Hard-Sale-Phase“ mit 70 % und mehr dramatisch einbrachen – sich aber eine Woche nach Ende der Phase wieder erholten. Das hätten wir nie erfahren, wenn der Test nicht fast vier Wochen gelaufen wäre.
Unsere „Faustregel“ lautet: 3.000–4.000 Conversions pro Variante und 3–4 Wochen Testdauer. Das ist genug Verkehr, sodass wir sogar von validen Daten sprechen können, wenn wir uns in Segmente aufschlüsseln.
Testen von „Sünde“ Nummer 1: Suche nach Uplifts innerhalb von Segmenten, wenn Sie keine statistische Gültigkeit haben (z. B. 85 vs. 97 Conversions). Das ist Blödsinn.
Aus Tests zu lernen ist super wichtig – sogar wichtiger als Gewinne zu erzielen. Und die Segmentierung Ihrer Testdaten ist eine der besseren Lernmethoden. Stellen Sie einfach sicher, dass Ihre Segmente über genügend Daten verfügen, bevor Sie voreilige Schlüsse ziehen.
Fazit
Stoppen Sie den Test nicht, nur weil Ihr Test ein Signifikanzniveau von 95 % oder höher erreicht. Achten Sie auch auf die absolute Anzahl der Conversions pro Variante und Testdauer.