
La importancia estadística no es igual a la validez (o por qué se obtienen aumentos imaginarios)
Publicado: 2020-10-06Un escenario muy común: una empresa ejecuta decenas y decenas de pruebas A/B en el transcurso de un año, y muchas de ellas "ganan". Algunas pruebas le dan un aumento del 25 % en los ingresos, o incluso más.
Sin embargo, cuando implementa el cambio, los ingresos no aumentan un 25 %. Y 12 meses después de ejecutar todas esas pruebas, la tasa de conversión sigue siendo prácticamente la misma. ¿Cómo?
La respuesta es esta: Tus elevaciones fueron imaginarias. Para empezar, no hubo levantamiento.
Sí, su herramienta de prueba dijo que tenía un nivel de significación estadística del 95 % (o superior). Bueno, eso no significa mucho. La significación estadística y la validez no son lo mismo.
La significación estadística no es una regla de parada.
Cuando sus pruebas dicen que ha alcanzado un nivel de confianza del 95 % o incluso del 99 %, eso no significa que tenga una variación ganadora.
Aquí hay un ejemplo que he usado antes. Dos días después de comenzar una prueba, estos fueron los resultados:

La variación que construí estaba perdiendo mucho, en más del 89% (y sin superposición en el margen de error). Aquí dice que la Variación 1 tiene un 0% de posibilidades de vencer al Control.
¿Es este un resultado estadísticamente significativo? Sí, lo es. Ingrese los mismos números en cualquier calculadora de prueba A/B y dirán lo mismo. Aquí están los resultados usando esta calculadora de significado:
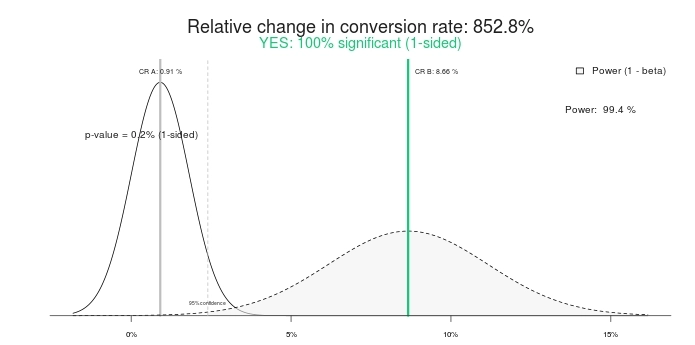
Por lo tanto, una prueba 100 % significativa y un 852,8 % de elevación (o, más bien, el Control es >800 % mejor que el tratamiento). Vamos a terminar la prueba, ¿de acuerdo? ¡El control gana! ¿O qué tal si le damos un poco más de tiempo?
Así se veía 10 días después:

Así es, la variación que tenía un 0 % de probabilidad de vencer al control ahora ganaba con un 95 % de confianza. ¿Que pasa con eso? ¿Cómo es que "100% de importancia" y "0% de posibilidades de ganar" dejaron de tener sentido? Porque ellos son.
Si finaliza la prueba antes de tiempo, existe una gran posibilidad de que elija al ganador equivocado. En este escenario, muchas empresas (¿la mayoría?) siguen adelante e implementan el cambio (es decir, implementan la variación ganadora al 100 % del tráfico), mientras que, de hecho, el aumento del 800 % se vuelve cero o incluso negativo (perdedor).
Incluso peor que el ascensor imaginario es la falsa confianza que ahora tienes. Crees que aprendiste algo y sigues aplicando ese aprendizaje en otras partes del sitio. Pero el aprendizaje en realidad no es válido, lo que hace que todos sus esfuerzos y tiempo sean una completa pérdida.
Es lo mismo con la segunda captura de pantalla de prueba (10 días después), aunque dice 95% de importancia, todavía no está "cocinada". La muestra es demasiado pequeña; la diferencia absoluta en las conversiones es de solo 19 transacciones. Eso puede cambiar en un día.

Ton Wesseling tiene esto que decir al respecto:
Debe saber que detener una prueba una vez que es significativa es el pecado mortal número 1 en la tierra de las pruebas A/B. El setenta y siete por ciento de las pruebas A/A (misma página contra la misma página) alcanzarán la significación en un punto determinado.
Aprende qué significa realmente.
La significación estadística por sí sola no debería determinar si finaliza una prueba o no. No es una regla de parada.
La significancia estadística no nos dice la probabilidad de que B sea mejor que A. Tampoco nos dice la probabilidad de que cometamos un error al seleccionar B sobre A.
Estos son conceptos erróneos extraordinariamente comunes, pero son falsos. Para saber de qué se tratan realmente los valores p, lea esta publicación.
Ejecute sus pruebas por más tiempo.
Si detiene sus pruebas después de unos días, lo está haciendo mal. No importa si obtiene 10,000 transacciones por día. El número absoluto de transacciones es importante, pero también necesita tiempo puro.

Matt Gershoff de Conductrics explica por qué:
Una de las dificultades de realizar pruebas en línea es que no tenemos el control de nuestras cohortes de usuarios. Esto puede ser un problema si los usuarios distribuyen de manera diferente según la hora y el día de la semana, e incluso según la temporada. Debido a esto, probablemente queramos asegurarnos de recopilar nuestros datos durante cualquier ciclo de datos relevante. De esa forma, nuestros tratamientos están expuestos a una muestra más representativa de la población media de usuarios.
Tenga en cuenta que la segmentación realmente no nos saca de esto, ya que aún necesitaremos muestrear durante los días de semana, los fines de semana, etc., y probablemente queramos golpear cada día o parte del día un par de veces para promediar y eventos externos. que podría estar afectando el flujo de tráfico/la conversión para obtener buenas estimaciones de las funciones/segmentos basados en el tiempo de impacto en la conversión.
Veo el siguiente escenario todo el tiempo:
- Primer par de días: B está ganando a lo grande. Normalmente debido al factor novedad.
- Después de la semana #1: B ganando fuerte.
- Después de la semana #2: B sigue ganando, pero la diferencia relativa es menor.
- Después de la semana n.° 4: Regresión a la media: la elevación ha desaparecido.
Entonces, si detiene la prueba antes de cuatro semanas (tal vez incluso después de unos días), cree que tiene una variación ganadora, pero no es así. Si lo implementa en vivo, tiene lo que yo llamo un "ascensor imaginario". Cree que tiene un aumento porque su herramienta de prueba mostró un crecimiento superior al 25 %, pero no ve un crecimiento en su cuenta bancaria.
Ejecute sus pruebas por más tiempo. Asegúrese de que incluyan dos ciclos comerciales, tengan suficientes conversiones/transacciones absolutas y hayan tenido suficiente duración en el tiempo.

Ejemplo de un ascensor imaginario
Esta es una prueba que realizamos para un cliente de comercio electrónico. La duración de la prueba fue de 35 días, solo para visitantes de escritorio y tuvo cerca de 3000 transacciones por variación.
Spoiler: la prueba terminó con "ninguna diferencia". Aquí está la descripción general de Optimizely para los ingresos (haga clic para ampliar):

Veamos ahora:
- Primer par de días: Azul (variación n.º 3) está ganando mucho, como $16 por visitante frente a $12,5 para Control (¡#Ganar!). Muchas personas terminan la prueba aquí (¡#Fail!).
- Después de 7 días: Azul sigue ganando y la diferencia relativa es grande.
- Después de 14 días: ¡Orange (#4) está ganando!
- Después de 21 días: ¡Orange sigue ganando!
- Fin: No hay diferencia.
Entonces, si hubiera realizado la prueba durante menos de cuatro semanas, habría dicho que el ganador estaba equivocado.
Las reglas de parada
Entonces, ¿cuándo se cocina una prueba?
Por desgracia, no existe una respuesta celestial universal, y hay muchos factores de "depende". Dicho esto, puede tener algunas reglas de parada bastante buenas para la mayoría de los casos.
Aquí están mis reglas de parada:
- Duración de la prueba de al menos 3 semanas (mejor si 4).
- Tamaño de muestra mínimo precalculado alcanzado (utilizando diferentes herramientas). No creeré ninguna prueba que tenga menos de 250 a 400 conversiones por variación.
- Significación estadística de al menos el 95%.
Puede ser diferente para algunas pruebas debido a las peculiaridades, pero en la mayoría de los casos, me adhiero a esas reglas.
Aquí está Wesseling interviniendo de nuevo:
Desea probar el mayor tiempo posible, al menos un ciclo de compra, ¡cuantos más datos, mayor será el poder estadístico de su prueba!
¡Más tráfico significa que tiene más posibilidades de reconocer a su ganador en el nivel de importancia en el que está probando! Los pequeños cambios pueden tener un gran impacto, pero los grandes impactos no ocurren con demasiada frecuencia; la mayoría de las veces, su variación es ligeramente mejor, por lo que necesita una gran cantidad de datos para notar un ganador significativo.
Pero si sus pruebas duran y duran, la gente tiende a borrar sus cookies (10% en dos semanas). Cuando regresan a su prueba, pueden terminar en la variación incorrecta, por lo que, cuando pasan las semanas, sus muestras contaminan cada vez más y terminan con las mismas tasas de conversión.
Prueba durante un máximo de 4 semanas.
¿Qué sucede si, después de tres o cuatro semanas, el tamaño de la muestra es inferior a 400 conversiones por variación?
Dejé que la prueba durara más. Si, a las 4 semanas, no se alcanza el tamaño de la muestra, agrego otra semana.
Siempre prueba semanas completas . Si comienza la prueba un lunes, debe terminar un domingo. Si no prueba una semana completa a la vez, puede sesgar sus resultados.
Ejecute un informe de conversiones por día de la semana en su sitio. Vea cuánta fluctuación hay.
¿Qué ves abajo? Los jueves generan 2 veces más dinero que los sábados y domingos, y la tasa de conversión de los jueves es casi 2 veces mejor que la de un sábado.

Si no hiciéramos pruebas durante semanas completas, los resultados serían inexactos. Pruebe semanas completas a la vez.
Se aplican las mismas reglas de parada para cada segmento.
La segmentación es clave para aprender de las pruebas A/B. Es común que B pierda frente a A en los resultados generales, pero supere a A en ciertos segmentos (p. ej., tráfico de Facebook, usuarios de dispositivos móviles, etc.).
Antes de que pueda analizar cualquier dato segmentado, asegúrese de tener un tamaño de muestra lo suficientemente grande dentro de cada segmento. Por lo tanto, necesita de 250 a 400 conversiones por variación dentro de cada segmento que está viendo.
Incluso recomiendo que cree pruebas dirigidas (establezca el público objetivo/segmento en la configuración de la prueba) en lugar de analizar los resultados en todos los segmentos después de una prueba. Esto garantiza que las pruebas no se llamen antes de tiempo y que cada segmento tenga un tamaño de muestra adecuado.
Mi amigo Andre Morys dijo esto sobre sus reglas de parada:

Siempre le digo a la gente que necesita una muestra representativa si sus datos deben ser válidos.
¿Qué significa "representante"? En primer lugar, debe incluir todos los días de la semana y los fines de semana. Necesita un clima diferente porque afecta el comportamiento del comprador. Pero lo más importante, su tráfico debe tener todas las fuentes de tráfico, especialmente boletines, campañas especiales, TV... ¡todo! Cuanto más se ejecute la prueba, más información obtendrá.
Acabamos de realizar una prueba para un gran minorista de moda en medio de la fase de rebajas de verano. Fue muy interesante ver cómo los resultados cayeron drásticamente durante la "fase de venta dura" con un 70% y más, pero se recuperaron una semana después de que terminó la fase. Nunca hubiéramos aprendido esto si la prueba no se hubiera realizado durante casi cuatro semanas.
Nuestra "regla general" es la siguiente: 3000–4000 conversiones por variación y 3–4 semanas de duración de la prueba. Eso es suficiente tráfico para que incluso podamos hablar sobre datos válidos si profundizamos en segmentos.
Probar el "pecado" número 1: buscar mejoras dentro de los segmentos cuando no tiene validez estadística (p. ej., 85 frente a 97 conversiones). Eso es una mierda.
Aprender de las pruebas es muy importante, incluso más que obtener victorias. Y segmentar sus datos de prueba es una de las mejores formas de aprender. Solo asegúrese de que sus segmentos tengan suficientes datos antes de sacar conclusiones precipitadas.
Conclusión
Solo porque su prueba alcance un nivel de significación del 95 % o superior, no detenga la prueba. Preste atención al número absoluto de conversiones por variación y también a la duración de la prueba.