
統計意義不等於有效性(或為什麼你會得到想像的提升)
已發表: 2020-10-06一個非常常見的場景:一家企業在一年的時間裡運行了數十個 A/B 測試,其中許多“獲勝”。 有些測試可以讓您的收入增加 25%,甚至更高。
然而,當您推出更改時,收入並沒有增加 25%。 在運行所有這些測試 12 個月後,轉換率仍然幾乎相同。 怎麼來的?
答案是這樣的:你的提升是虛構的。 一開始沒有任何提升。
是的,您的測試工具顯示您的統計顯著性水平為 95%(或更高)。 嗯,這並不意味著什麼。 統計意義和有效性是不一樣的。
統計顯著性不是停止規則。
當您的測試表明您已達到 95% 甚至 99% 的置信水平時,這並不意味著您有一個成功的變體。
這是我以前用過的一個例子。 開始測試兩天后,結果如下:

我構建的變體損失慘重——損失超過 89%(並且誤差範圍沒有重疊)。 這裡說 Variation 1 有 0% 的機會擊敗 Control。
這是一個具有統計學意義的結果嗎? 是的。 在任何 A/B 測試計算器中輸入相同的數字,他們會說同樣的。 以下是使用此顯著性計算器的結果:
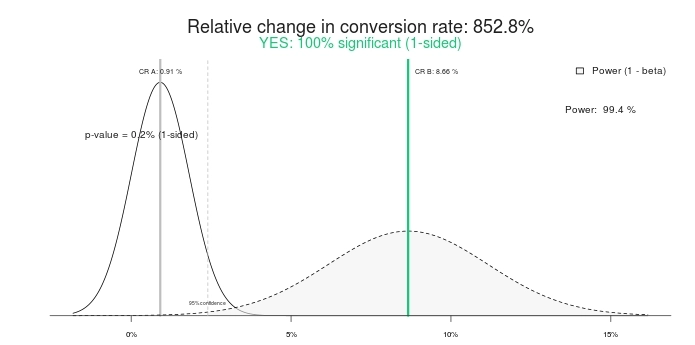
所以一個 100% 的顯著測試和 852.8% 的提升(或者,更確切地說,控制組比治療組好 800% 以上)。 讓我們結束測試,好嗎? 控制勝利! 或者我們給它更多時間怎麼樣?
這是10天后的樣子:

沒錯,以 0% 的機會擊敗控制的變體現在以 95% 的信心獲勝。 那是怎麼回事? “100%意義”和“0%中獎”怎麼就變得毫無意義了? 因為他們是。
如果您提前結束測試,您很有可能會選錯獲勝者。 在這種情況下,許多(大多數?)企業仍然繼續實施改變(即,將獲勝的變化推廣到 100% 的流量),而事實上,800% 的提升變為零,甚至是負數(失敗)。
比想像中的提升更糟糕的是你現在擁有的虛假自信。 你認為你學到了一些東西,並繼續在網站的其他地方應用這些知識。 但是學習實際上是無效的,從而使您的所有努力和時間完全浪費了。
第二個測試屏幕截圖(10 天后)也是如此——儘管它表示 95% 的顯著性,但它仍然沒有“熟”。 樣本太小; 轉換的絕對差異僅為 19 次交易。 這可以在一天內改變。

Ton Wesseling 對此有話要說:
您應該知道,一旦測試很重要就停止測試是 A/B 測試領域的第 1 大罪。 77% 的 A/A 測試(同一頁對同一頁)將在某個點達到顯著性。
了解真正的意義是什麼。
僅統計顯著性不應決定您是否結束測試。 這不是一個停止規則。
統計顯著性並沒有告訴我們 B 優於 A 的概率。它也沒有告訴我們在選擇 B 而不是 A 時出錯的概率。
這些都是非常普遍的誤解,但它們是錯誤的。 要了解 p 值的真正含義,請閱讀這篇文章。
運行你的測試更長的時間。
如果你在幾天后停止測試,那你就錯了。 如果您每天獲得 10,000 筆交易,這並不重要。 交易的絕對數量很重要,但您也需要純粹的時間。

Conductrics 的 Matt Gershoff 解釋了原因:
在線運行測試的困難之一是我們無法控制我們的用戶群。 如果用戶按時間和星期幾,甚至按季節分佈不同,這可能是一個問題。 因此,我們可能希望確保在任何相關數據周期內收集數據。 這樣,我們的治療就可以接觸到更具代表性的普通用戶群體樣本。
請注意,細分並不能真正讓我們擺脫這種情況,因為我們仍需要在工作日、週末等進行採樣,並且我們可能希望在每天或每天的部分中點擊幾次以平均和外部事件這可能會影響交通流量/轉換,以便對基於時間的特徵/細分對轉換的影響進行良好估計。
我一直看到以下場景:
- 前幾天:B 贏了很多。 通常是由於新穎性因素。
- 第 1 週後:B 強勢獲勝。
- 第 2 週之後:B 仍然獲勝,但相對差異較小。
- 第 4 週之後:回歸均值——隆起消失了。
因此,如果您在 4 週之前(甚至可能在幾天之後)停止測試,您認為您有一個成功的變化,但您沒有。 如果你現場推出它,你就有了我所說的“想像中的電梯”。 您認為您有提升,因為您的測試工具顯示 > 25% 的增長,但您沒有看到您的銀行賬戶增長。

運行你的測試更長的時間。 確保它們包括兩個業務週期,有足夠的絕對轉化/交易,並且在時間上有足夠的持續時間。
假想電梯示例
這是我們為電子商務客戶進行的測試。 測試持續時間為 35 天,僅針對桌面訪問者,每個變體有近 3,000 筆交易。
劇透:測試以“沒有區別”結束。 以下是收入的 Optimizely 概覽(點擊放大):

現在讓我們看看:
- 前幾天:Blue(變體 #3)贏得了巨額獎金,例如每位訪客 16 美元,而 Control 則為 12.5 美元(#Winning!)。 許多人在這裡結束測試(#Fail!)。
- 7天后:藍方依舊中獎,相對差距較大。
- 14 天后:Orange (#4) 獲勝!
- 21 天后:Orange 仍然獲勝!
- 結束:沒有區別。
所以,如果你運行測試不到四個星期,你就會錯誤地稱獲勝者。
停止規則
那麼,什麼時候做一個測試呢?
唉,那裡沒有普遍的天堂般的答案,並且有很多“取決於”因素。 也就是說,對於大多數情況,您可以有一些非常好的停止規則。
這是我的停止規則:
- 至少 3 週的測試持續時間(最好是 4 週)。
- 達到最小預先計算的樣本量(使用不同的工具)。 我不會相信任何每個變體轉換少於 250-400 次的測試。
- 統計顯著性至少為 95%。
由於特殊性,某些測試可能會有所不同,但在大多數情況下,我會遵守這些規則。
Wesseling 再次插話:
您希望盡可能長時間地進行測試——至少一個購買週期——數據越多,測試的統計能力就越高!
更多的流量意味著您有更高的機會在您正在測試的顯著性水平上識別出您的獲勝者! 小的變化可以產生大的影響,但大的影響不會經常發生——大多數時候,你的變化會稍微好一點,所以你需要大量的數據來發現一個重要的贏家。
但是,如果您的測試持續且持續,人們往往會刪除他們的 cookie(兩週內 10%)。 當它們在您的測試中返回時,它們最終可能會出現錯誤的變化——因此,當幾週過去時,您的樣本污染越來越多,最終會得到相同的轉化率。
最多測試 4 週。
如果在三到四個星期後,每個變體的樣本量少於 400 次轉化怎麼辦?
我讓測試運行更長時間。 如果到 4 週後仍未達到樣本量,我會再增加一周。
始終測試整週。 如果您在星期一開始考試,則應該在星期日結束。 如果您一次不測試一整週,您的結果可能會出現偏差。
在您的網站上運行每週每天的轉化報告。 看看有多少波動。
你在下面看到什麼? 週四比周六和周日多賺 2 倍,週四的轉化率幾乎是周六的 2 倍。

如果我們整週不進行測試,結果將不准確。 一次測試整整幾週。
相同的停止規則適用於每個段。
細分是從 A/B 測試中學習的關鍵。 B 在整體結果上輸給 A 但在某些領域(例如 Facebook 流量、移動設備用戶等)擊敗 A 是很常見的。
在分析任何分段數據之前,請確保每個分段中的樣本量足夠大。 因此,您需要在所查看的每個細分中的每個變體進行 250–400 次轉化。
我什至建議您創建有針對性的測試(在測試配置中設置目標受眾/細分),而不是在測試後跨細分分析結果。 這樣可以確保不會提前調用測試,並且每個段都有足夠的樣本量。
我的朋友 Andre Morys 談到了他的停止規則:

我總是告訴人們,如果你的數據應該是有效的,你需要一個有代表性的樣本。
“代表”是什麼意思? 首先,您需要包括所有工作日和周末。 您需要不同的天氣,因為它會影響買家的行為。 但最重要的是,您的流量需要擁有所有流量來源,尤其是時事通訊、特別活動、電視......一切! 測試運行的時間越長,您獲得的見解就越多。
我們剛剛在夏季促銷階段中期對一家大型時裝零售商進行了測試。 看到結果在“硬銷售階段”急劇下降 70% 甚至更多——但在該階段結束一周後恢復,這非常有趣。 如果測試沒有運行近四個星期,我們永遠不會知道這一點。
我們的“經驗法則”是:每個變體 3,000–4,000 次轉化和 3–4 週的測試持續時間。 這是足夠的流量,所以如果我們深入細分,我們甚至可以談論有效數據。
測試“罪過”1:當您沒有統計有效性時(例如,85 對 97 次轉化),在細分中搜索提升。 那是胡說。
從測試中學習非常重要——甚至比獲勝更重要。 對測試數據進行分段是更好的學習方法之一。 在您得出結論之前,請確保您的細分有足夠的數據。
結論
不要僅僅因為您的測試達到 95% 或更高的顯著性水平,就停止測試。 還要注意每個變體的絕對轉化次數和測試持續時間。