
5 Top-Crawling-Statistiken in der Google Search Console
Veröffentlicht: 2021-04-16Es gibt einen Bericht in der Google Search Console, der sowohl wahnsinnig nützlich als auch ziemlich schwer zu finden ist, besonders wenn Sie Ihre SEO-Reise gerade erst beginnen.
Es ist eines der leistungsstärksten Tools für jeden SEO-Profi, auch wenn Sie nicht einmal über die Hauptoberfläche der Google Search Console darauf zugreifen können.
Ich spreche vom Crawl-Statistikbericht.
In diesem Artikel erfahren Sie, warum dieser Bericht so wichtig ist, wie Sie darauf zugreifen und wie Sie ihn für SEO-Vorteile nutzen können.
Wie wird Ihre Website gecrawlt?
Das Crawling-Budget (die Anzahl der Seiten, die der Googlebot crawlen kann und will) ist für SEO unerlässlich, insbesondere für große Websites.
Wenn Sie Probleme mit dem Crawling-Budget Ihrer Website haben, indexiert Google möglicherweise einige Ihrer wertvollen Seiten nicht.
Und wie heißt es so schön: Wenn Google etwas nicht indexiert hat, existiert es nicht.
Die Google Search Console kann Ihnen zeigen, wie viele Seiten Ihrer Website täglich vom Googlebot besucht werden.
Mit diesem Wissen können Sie Anomalien finden, die Ihre SEO-Probleme verursachen können.
Tauchen Sie ein in Ihre Crawling-Statistiken: 5 wichtige Erkenntnisse
Um auf Ihren Crawl-Statistikbericht zuzugreifen, melden Sie sich bei Ihrem Google Search Console-Konto an und navigieren Sie zu Einstellungen > Crawl-Statistiken .
Hier sind alle Datendimensionen, die Sie im Crawl-Statistikbericht einsehen können:
1. Gastgeber
Stellen Sie sich vor, Sie haben einen E-Commerce-Shop auf shop.website.com und einen Blog auf blog.website.com.
Mithilfe des Crawling-Statistikberichts können Sie ganz einfach die Crawling-Statistiken für jede Subdomain Ihrer Website anzeigen.
Leider funktioniert diese Methode derzeit nicht mit Unterordnern.
2. HTTP-Status
Ein weiterer Anwendungsfall für den Crawl-Statistikbericht ist die Betrachtung der Statuscodes von gecrawlten URLs.
Das liegt daran, dass Sie nicht möchten, dass der Googlebot Ressourcen für das Crawlen von Seiten aufwendet, die nicht HTTP 200 OK sind. Es ist eine Verschwendung Ihres Crawl-Budgets.
Um die Aufschlüsselung der gecrawlten URLs nach Statuscode anzuzeigen, gehen Sie zu Einstellungen > Crawling-Statistiken > Aufschlüsselung der Crawling-Anfragen .
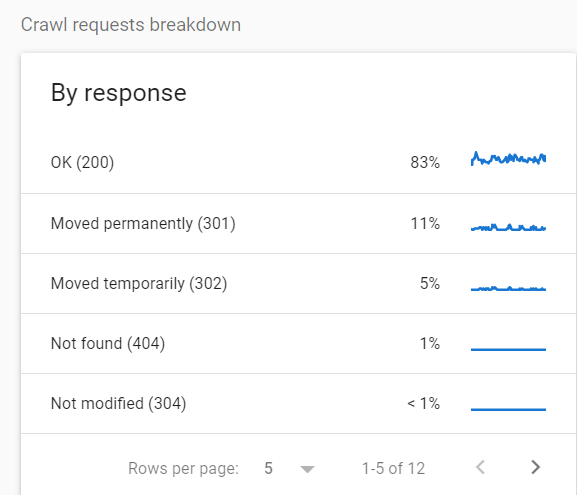
In diesem speziellen Fall wurden 16 % aller Anfragen nach umgeleiteten Seiten gestellt.
Wenn Sie Statistiken wie diese sehen, empfehle ich, weitere Untersuchungen durchzuführen und nach Redirect-Hops und anderen potenziellen Problemen zu suchen.
Meiner Meinung nach ist einer der schlimmsten Fälle, die Sie hier sehen können, eine große Anzahl von 5xx-Fehlern.
Um die Dokumentation von Google zu zitieren: „Wenn die Website langsamer wird oder mit Serverfehlern antwortet, sinkt das Limit und der Googlebot crawlt weniger.“
Wenn Sie an diesem Thema interessiert sind, hat Roger Montti einen ausführlichen Artikel über 5xx-Fehler in der Google Search Console geschrieben.
3. Zweck
Der Crawling-Statistikbericht unterteilt den Crawling-Zweck in zwei Kategorien:
- URLs, die zu Aktualisierungszwecken gecrawlt wurden (ein erneutes Crawlen bereits bekannter Seiten, z. B. besucht der Googlebot Ihre Homepage, um neue Links und Inhalte zu entdecken).
- Zu Discovery-Zwecken gecrawlte URLs (URLs, die zum ersten Mal gecrawlt wurden).
Diese Aufschlüsselung ist wahnsinnig nützlich, und hier ist ein Beispiel:
Ich bin vor Kurzem auf eine Website gestoßen, auf der ungefähr 1 Million Seiten als „Entdeckt – derzeit nicht indiziert“ eingestuft wurden.
Dieses Problem wurde für 90 % aller Seiten dieser Website gemeldet.
(Wenn Sie damit nicht vertraut sind, bedeutet „Entdeckt, aber nicht indexiert“, dass Google eine bestimmte Seite entdeckt, aber nicht besucht hat. Wenn Sie beispielsweise ein neues Restaurant in Ihrer Stadt entdeckt, es aber nicht ausprobiert haben .)
Eine der Optionen war zu warten, in der Hoffnung, dass Google diese Seiten nach und nach indexiert.
Eine andere Möglichkeit bestand darin, sich die Daten anzusehen und das Problem zu diagnostizieren.
Also habe ich mich bei der Google Search Console angemeldet und zu Settings > Crawl Stats > Crawl Requests: HTML navigiert.
Es stellte sich heraus, dass Google im Durchschnitt nur 7460 Seiten dieser Website pro Tag besuchte.
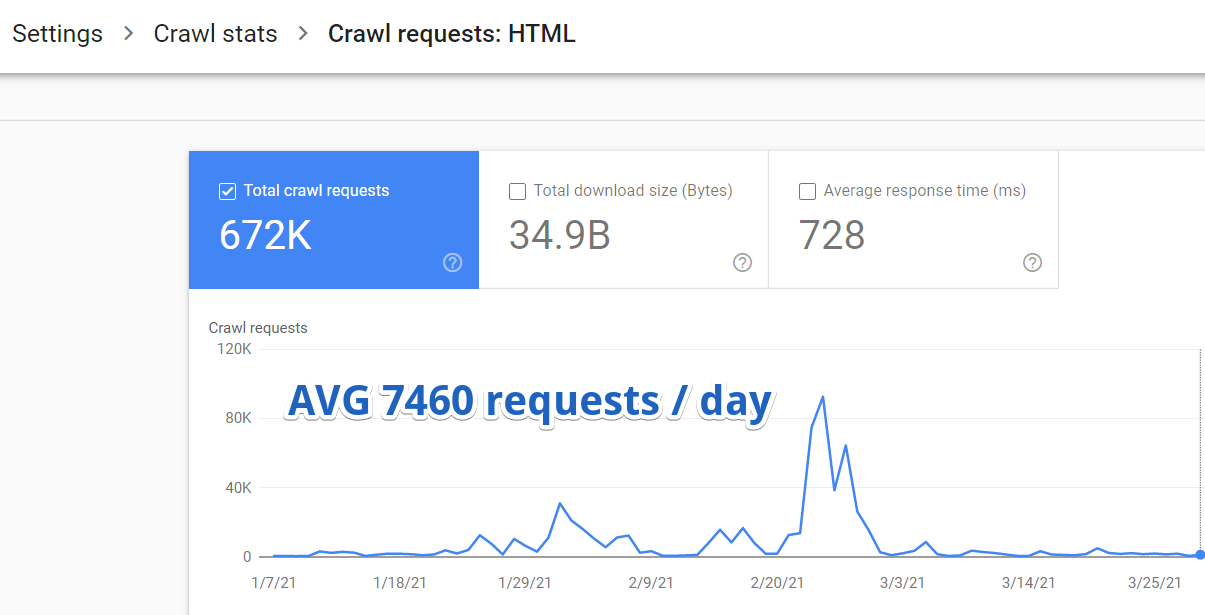
Aber hier ist etwas noch Wichtigeres.
Dank des Crawl-Statistikberichts fand ich heraus, dass nur 35 % dieser 7460 URLs aus Entdeckungsgründen gecrawlt wurden.
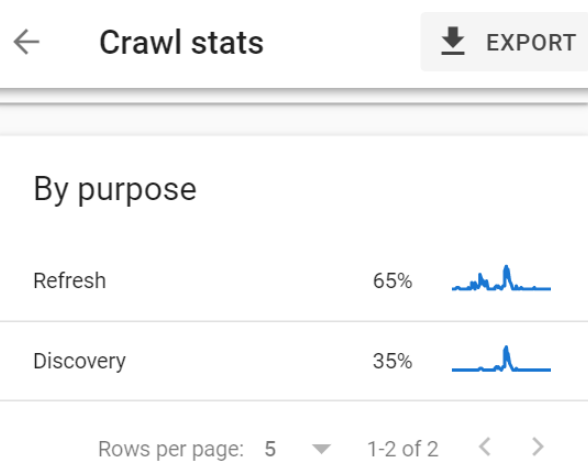

Das sind nur 2611 neue Seiten, die von Google pro Tag entdeckt werden.
2611 von über einer Million.
Es würde 382 Tage dauern, bis Google die gesamte Website in diesem Tempo vollständig indexiert hätte.
Das herauszufinden, war ein Gamechanger. Alle anderen Suchoptimierungen wurden verschoben, da wir uns voll und ganz auf die Optimierung des Crawl-Budgets konzentriert haben.
4. Dateityp
GSC-Crawling-Statistiken können für JavaScript-Websites hilfreich sein. Sie können leicht überprüfen, wie oft der Googlebot JS-Dateien crawlt, die für eine ordnungsgemäße Wiedergabe erforderlich sind.
Wenn Ihre Website voller Bilder ist und die Bildsuche für Ihre SEO-Strategie von entscheidender Bedeutung ist, wird dieser Bericht ebenfalls sehr hilfreich sein – Sie können sehen, wie gut der Googlebot Ihre Bilder crawlen kann.
5. Googlebot-Typ
Schließlich bietet Ihnen der Crawl-Statistikbericht eine detaillierte Aufschlüsselung des Googlebot-Typs, der zum Crawlen Ihrer Website verwendet wird.
Sie können den Prozentsatz der Anfragen ermitteln, die entweder von mobilen oder Desktop-Googlebots und Bild-, Video- und Anzeigen-Bots gestellt wurden.
Andere nützliche Informationen
Es ist erwähnenswert, dass der Crawl-Statistikbericht unschätzbare Informationen enthält, die Sie nicht in Ihren Serverprotokollen finden:
- DNS-Fehler.
- Seiten-Timeouts.
- Hostprobleme wie Probleme beim Abrufen der robots.txt-Datei.
Verwenden von Crawling-Statistiken im URL-Inspektionstool
Sie können auch außerhalb des Crawling-Statistikberichts im URL-Inspektionstool auf einige detaillierte Crawling-Daten zugreifen.
Ich habe kürzlich mit einer großen E-Commerce-Website gearbeitet und nach einigen ersten Analysen zwei dringende Probleme festgestellt:
- Viele Produktseiten wurden in Google nicht indexiert.
- Es gab keine interne Verlinkung zwischen den Produkten. Die einzige Möglichkeit für Google, neue Inhalte zu entdecken, waren Sitemaps und paginierte Kategorieseiten.
Ein natürlicher nächster Schritt bestand darin, auf Serverprotokolle zuzugreifen und zu überprüfen, ob Google die paginierten Kategorieseiten gecrawlt hatte.
Der Zugriff auf Serverprotokolle ist jedoch oft sehr schwierig, insbesondere wenn Sie mit einer großen Organisation zusammenarbeiten.
Der Crawl-Statistikbericht der Google Search Console kam zu Hilfe.
Lassen Sie mich Sie durch den Prozess führen, den ich verwendet habe und den Sie verwenden können, wenn Sie mit einem ähnlichen Problem zu kämpfen haben:
1. Suchen Sie zuerst eine URL im URL-Inspektionstool. Ich habe eine der paginierten Seiten aus einer der Hauptkategorien der Website ausgewählt.
2. Navigieren Sie dann zu Abdeckung > Crawling-Bericht .
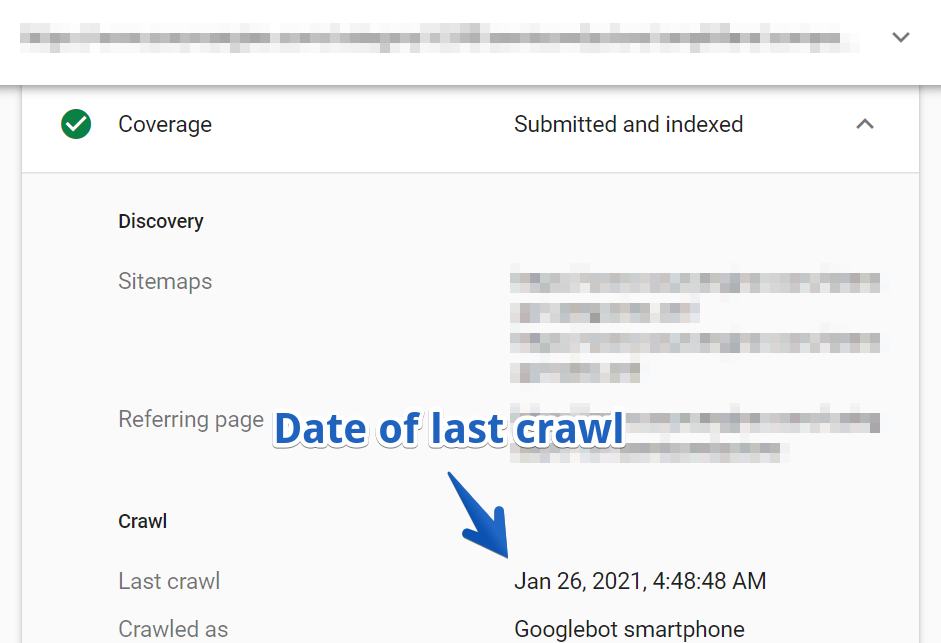
In diesem Fall wurde die URL zuletzt vor drei Monaten gecrawlt.
Denken Sie daran, dass dies eine der Hauptkategorieseiten der Website war, die seit über drei Monaten nicht mehr gecrawlt wurde!
Ich ging tiefer und überprüfte eine Probe anderer Kategorieseiten.
Es stellte sich heraus, dass der Googlebot viele Hauptkategorieseiten nie besuchte. Viele davon sind Google noch unbekannt.
Ich glaube nicht, dass ich erklären muss, wie wichtig es ist, diese Informationen zu haben, wenn Sie daran arbeiten, die Sichtbarkeit einer Website zu verbessern.
Mit dem Crawl-Statistikbericht können Sie solche Dinge innerhalb von Minuten nachschlagen.
Einpacken
Wie Sie sehen können, ist der Crawl-Statistikbericht ein leistungsstarkes SEO-Tool, obwohl Sie die Google Search Console jahrelang verwenden könnten, ohne ihn jemals zu finden.
Es hilft Ihnen, Indizierungsprobleme zu diagnostizieren und Ihr Crawl-Budget zu optimieren, damit Google Ihre wertvollen Inhalte schnell finden und indexieren kann, was besonders für große Websites wichtig ist.
Ich habe Ihnen ein paar Anwendungsfälle genannt, an die Sie denken sollten, aber jetzt liegt der Ball bei Ihnen.
Wie werden Sie diese Daten verwenden, um die Sichtbarkeit Ihrer Website zu verbessern?
Mehr Ressourcen:
- Crawl-First-SEO: Eine 12-Schritte-Anleitung, die Sie vor dem Crawlen befolgen sollten
- 7 Tipps zur Optimierung des Crawl-Budgets für SEO
- Wie Suchmaschinen funktionieren
Bildnachweis
Alle Screenshots vom Autor, April 2021