
Cele mai importante 5 statistici privind accesarea cu crawlere în Google Search Console
Publicat: 2021-04-16Există un raport în Google Search Console care este atât nebunește de util, cât și destul de greu de găsit, mai ales dacă abia începi călătoria SEO.
Este unul dintre cele mai puternice instrumente pentru fiecare profesionist SEO, chiar dacă nici măcar nu îl puteți accesa din interfața principală a Google Search Console.
Vorbesc despre raportul statistici Crawl.
În acest articol, veți afla de ce acest raport este atât de important, cum să îl accesați și cum să îl utilizați pentru avantajul SEO.
Cum este accesat cu crawlere site-ul dvs.?
Bugetul de accesare cu crawlere (numărul de pagini pe care Googlebot poate și vrea să le acceseze cu crawlere) este esențial pentru SEO, în special pentru site-urile mari.
Dacă aveți probleme cu bugetul de accesare cu crawlere al site-ului dvs., este posibil ca Google să nu indexeze unele dintre paginile dvs. valoroase.
Și după cum se spune, dacă Google nu a indexat ceva, atunci nu există.
Google Search Console vă poate arăta câte pagini de pe site-ul dvs. sunt vizitate de Googlebot în fiecare zi.
Înarmat cu aceste cunoștințe, puteți găsi anomalii care vă pot cauza probleme SEO.
Scufundați-vă în statisticile dvs. de crawl: 5 informații cheie
Pentru a accesa raportul privind statisticile de accesare cu crawlere, conectați-vă la contul Google Search Console și navigați la Setări > Statistici de accesare cu crawlere .
Iată toți parametrii de date pe care îi puteți inspecta în raportul Statistici de accesare cu crawlere:
1. Gazdă
Imaginați-vă că aveți un magazin de comerț electronic pe shop.website.com și un blog pe blog.website.com.
Folosind raportul Statistici de accesare cu crawlere, puteți vedea cu ușurință statisticile de accesare cu crawlere aferente fiecărui subdomeniu al site-ului dvs.
Din păcate, această metodă nu funcționează în prezent cu subdosare.
2. Stare HTTP
Un alt caz de utilizare pentru raportul privind statisticile accesării cu crawlere se referă la codurile de stare ale adreselor URL accesate cu crawlere.
Asta pentru că nu doriți ca Googlebot să cheltuiască resurse accesând cu crawlere pagini care nu sunt HTTP 200 OK. Este o risipă a bugetului de accesare cu crawlere.
Pentru a vedea defalcarea adreselor URL accesate cu crawlere în funcție de codul de stare, accesați Setări > Statistici de accesare cu crawlere > Detalierea solicitărilor de accesare cu crawlere .
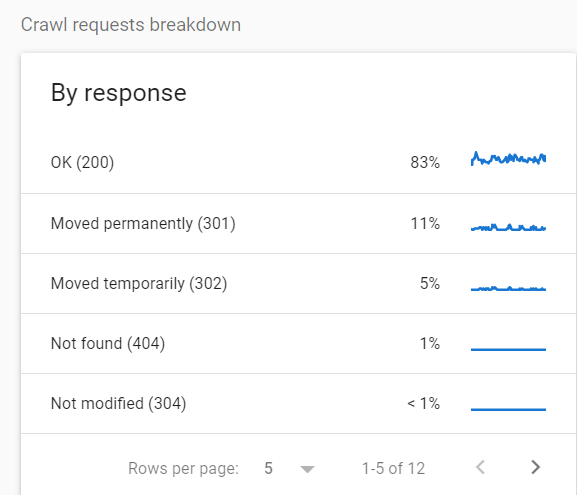
În acest caz particular, 16% din toate solicitările au fost făcute pentru pagini redirecționate.
Dacă vedeți statistici ca acestea, vă recomand să investigați în continuare și să căutați hopuri de redirecționare și alte probleme potențiale.
În opinia mea, unul dintre cele mai grave cazuri pe care le puteți vedea aici este o cantitate mare de erori 5xx.
Pentru a cita documentația Google: „Dacă site-ul încetinește sau răspunde cu erori de server, limita scade și Googlebot accesează cu crawlere mai puțin.”
Dacă sunteți interesat de acest subiect, Roger Montti a scris un articol detaliat despre erorile 5xx în Google Search Console.
3. Scop
Raportul Statistici de accesare cu crawlere împarte scopul accesării cu crawlere în două categorii:
- Adrese URL accesate cu crawlere în scopuri de reîmprospătare (o recrawler a paginilor deja cunoscute, de exemplu, Googlebot vă vizitează pagina de pornire pentru a descoperi noi linkuri și conținut).
- Adrese URL accesate cu crawlere în scopuri de descoperire (adrese URL care au fost accesate cu crawlere pentru prima dată).
Această defalcare este nebunește de utilă și iată un exemplu:
Am întâlnit recent un site web cu ~ 1 milion de pagini clasificate drept „Descoperite – momentan neindexate”.
Această problemă a fost raportată pentru 90% din toate paginile de pe site-ul respectiv.
(Dacă nu sunteți familiarizat cu acesta, „Descoperit, dar nu indexați” înseamnă că Google a descoperit o anumită pagină, dar nu a vizitat-o. Dacă ați descoperit un nou restaurant în orașul dvs., dar nu ați încercat, de exemplu .)
Una dintre opțiuni a fost să aștepte, în speranța ca Google să indexeze aceste pagini treptat.
O altă opțiune a fost să te uiți la datele și să diagnosticezi problema.
Așa că m-am conectat la Google Search Console și am navigat la Setări > Statistici de accesare cu crawlere > Solicitări de accesare cu crawlere: HTML .
S-a dovedit că, în medie, Google vizita doar 7460 de pagini pe acel site pe zi.
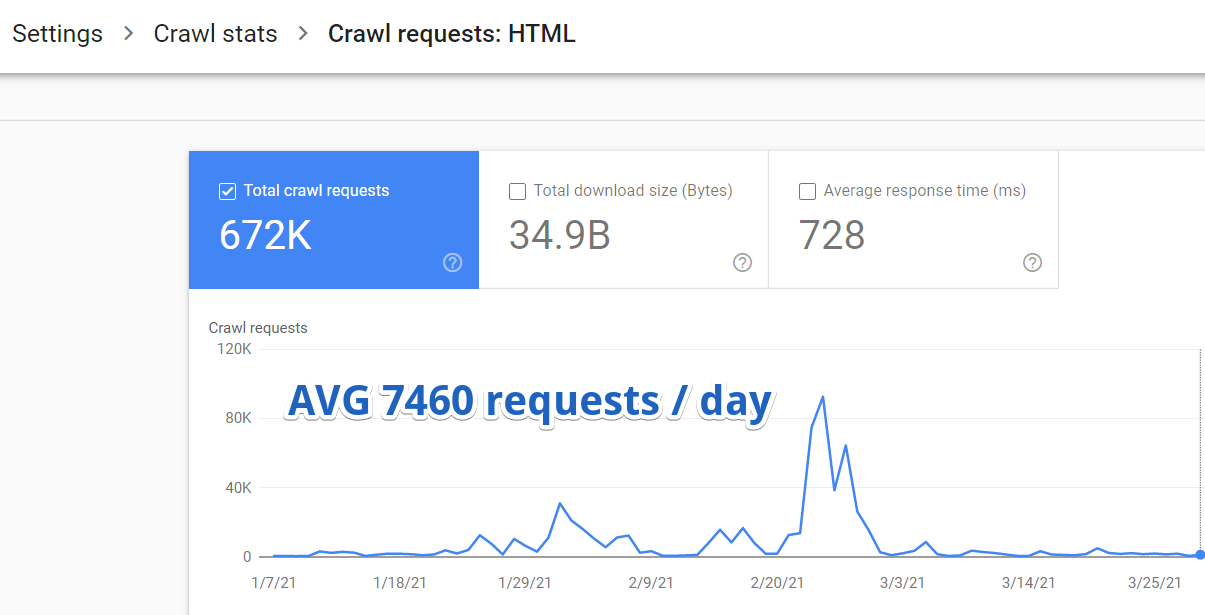
Dar iată ceva și mai important.
Datorită raportului privind statisticile de accesare cu crawlere, am aflat că doar 35% dintre aceste 7460 de adrese URL au fost accesate cu crawlere din motive de descoperire.
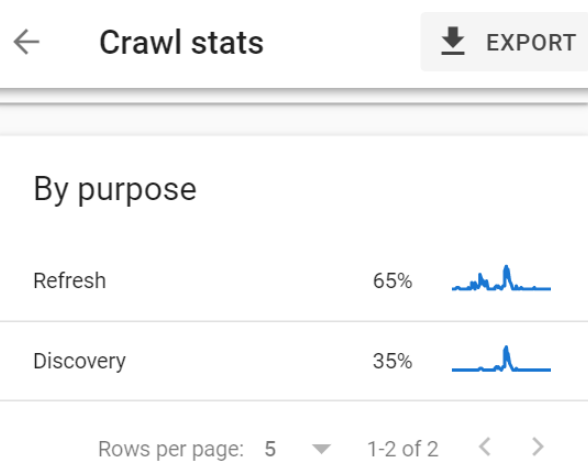

Sunt doar 2611 pagini noi descoperite de Google pe zi.
2611 din peste un milion.
Ar dura 382 de zile pentru ca Google să indexeze complet întregul site în acest ritm.
Aflarea asta a schimbat jocul. Toate celelalte optimizări ale căutării au fost amânate, deoarece ne-am concentrat pe deplin pe optimizarea bugetului de accesare cu crawlere.
4. Tip de fișier
Statisticile de accesare cu crawlere GSC pot fi utile pentru site-urile web JavaScript. Puteți verifica cu ușurință cât de des Googlebot accesează cu crawlere fișierele JS care sunt necesare pentru randarea corectă.
Dacă site-ul dvs. este plin de imagini, iar căutarea de imagini este crucială pentru strategia dvs. de SEO, acest raport vă va ajuta foarte mult - puteți vedea cât de bine vă poate accesa Googlebot cu crawlere imaginilor.
5. Tip Googlebot
În cele din urmă, raportul Statistici de accesare cu crawlere vă oferă o detaliere a tipului de robot Google utilizat pentru accesarea cu crawlere a site-ului dvs.
Puteți afla procentul de solicitări făcute de Googlebot mobil sau desktop și de roboții de imagine, video și anunțuri.
Alte informații utile
Este demn de remarcat faptul că raportul Statistici de accesare cu crawlere conține informații neprețuite pe care nu le veți găsi în jurnalele de server:
- Erori DNS.
- Timp de expirare a paginii.
- Probleme de gazdă, cum ar fi probleme la preluarea fișierului robots.txt.
Utilizarea Statisticilor de accesare cu crawlere în Instrumentul de inspecție URL
De asemenea, puteți accesa unele date detaliate de accesare cu crawlere în afara raportului Statistici de accesare cu crawlere, în Instrumentul de inspecție a adreselor URL.
Am lucrat recent cu un mare site de comerț electronic și, după câteva analize inițiale, am observat două probleme stringente:
- Multe pagini de produse nu au fost indexate în Google.
- Nu a existat nicio legătură internă între produse. Singura modalitate prin care Google poate descoperi conținut nou a fost prin intermediul sitemap-urilor și paginilor de categorii paginate.
Un pas natural următor a fost să accesezi jurnalele serverului și să verifici dacă Google a accesat cu crawlere paginile de categorii paginate.
Dar obținerea accesului la jurnalele de server este adesea foarte dificilă, mai ales atunci când lucrați cu o organizație mare.
Raportul privind statisticile de accesare cu crawlere de la Google Search Console a venit în ajutor.
Permiteți-mi să vă ghidez prin procesul pe care l-am folosit și pe care îl puteți folosi dacă vă confruntați cu o problemă similară:
1. Mai întâi, căutați o adresă URL în Instrumentul de inspecție URL. Am ales una dintre paginile paginate din una dintre categoriile principale ale site-ului.
2. Apoi, navigați la Acoperire > Raport de accesare cu crawlere .
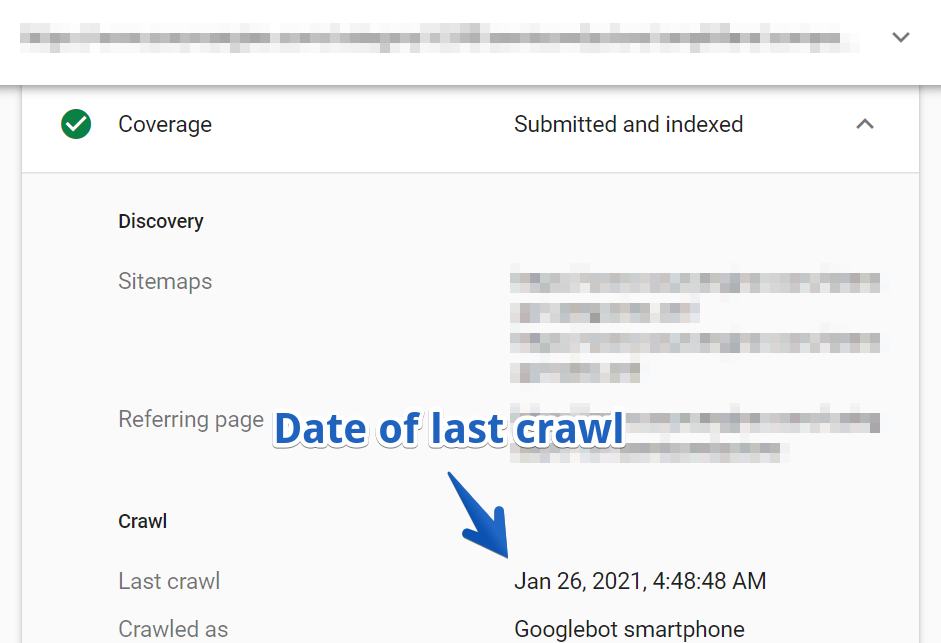
În acest caz, adresa URL a fost accesată cu crawlere ultima dată în urmă cu trei luni.
Rețineți că aceasta a fost una dintre paginile de categorie principale ale site-ului web care nu a fost accesată cu crawlere de peste trei luni!
Am aprofundat și am verificat un eșantion de pagini din alte categorii.
S-a dovedit că Googlebot nu a vizitat niciodată multe pagini din categoria principală. Multe dintre ele sunt încă necunoscute Google.
Nu cred că trebuie să explic cât de crucial este să ai acele informații atunci când lucrezi la îmbunătățirea vizibilității oricărui site web.
Raportul Statistici de accesare cu crawlere vă permite să vedeți astfel de lucruri în câteva minute.
Încheierea
După cum puteți vedea, raportul Statistici de accesare cu crawlere este un instrument SEO puternic, chiar dacă ați putea folosi Google Search Console ani de zile fără a-l găsi vreodată.
Vă va ajuta să diagnosticați problemele de indexare și să optimizați bugetul de accesare cu crawlere, astfel încât Google să găsească și să indexeze rapid conținutul dvs. valoros, ceea ce este deosebit de important pentru site-urile mari.
Ți-am dat câteva cazuri de utilizare la care să te gândești, dar acum mingea este în terenul tău.
Cum veți folosi aceste date pentru a îmbunătăți vizibilitatea site-ului dvs.?
Mai multe resurse:
- Crawl-First SEO: un ghid în 12 pași de urmat înainte de a accesa cu crawlere
- 7 sfaturi pentru a optimiza bugetul de accesare cu crawlere pentru SEO
- Cum funcționează motoarele de căutare
Credite de imagine
Toate capturile de ecran realizate de autor, aprilie 2021