
5 meilleures statistiques d'exploration dans Google Search Console
Publié: 2021-04-16Il existe un rapport dans Google Search Console qui est à la fois incroyablement utile et assez difficile à trouver, surtout si vous commencez tout juste votre parcours SEO.
C'est l'un des outils les plus puissants pour tous les professionnels du référencement, même si vous ne pouvez même pas y accéder depuis l'interface principale de Google Search Console.
Je parle du rapport de statistiques Crawl.
Dans cet article, vous apprendrez pourquoi ce rapport est si important, comment y accéder et comment l'utiliser à des fins de référencement.
Comment votre site Web est-il exploré ?
Le budget de crawl (le nombre de pages que Googlebot peut et veut explorer) est essentiel pour le référencement, en particulier pour les grands sites Web.
Si vous rencontrez des problèmes avec le budget d'exploration de votre site Web, Google peut ne pas indexer certaines de vos pages importantes.
Et comme le dit le dicton, si Google n'a pas indexé quelque chose, alors ça n'existe pas.
Google Search Console peut vous montrer combien de pages de votre site sont visitées par Googlebot chaque jour.
Fort de ces connaissances, vous pouvez trouver des anomalies qui peuvent être à l'origine de vos problèmes de référencement.
Plonger dans vos statistiques de crawl : 5 informations clés
Pour accéder à votre rapport de statistiques de crawl, connectez-vous à votre compte Google Search Console et accédez à Paramètres > Statistiques de crawl .
Voici toutes les dimensions de données que vous pouvez inspecter dans le rapport de statistiques Crawl :
1. Hôte
Imaginez que vous ayez une boutique en ligne sur shop.website.com et un blog sur blog.website.com.
À l'aide du rapport de statistiques de crawl, vous pouvez facilement voir les statistiques de crawl liées à chaque sous-domaine de votre site Web.
Malheureusement, cette méthode ne fonctionne pas actuellement avec les sous-dossiers.
2. Statut HTTP
Un autre cas d'utilisation du rapport de statistiques d'exploration consiste à examiner les codes d'état des URL explorées.
C'est parce que vous ne voulez pas que Googlebot dépense des ressources pour explorer des pages qui ne sont pas HTTP 200 OK. C'est un gaspillage de votre budget de crawl.
Pour voir la répartition des URL explorées par code d'état, accédez à Paramètres > Statistiques d'exploration > Répartition des demandes d'exploration .
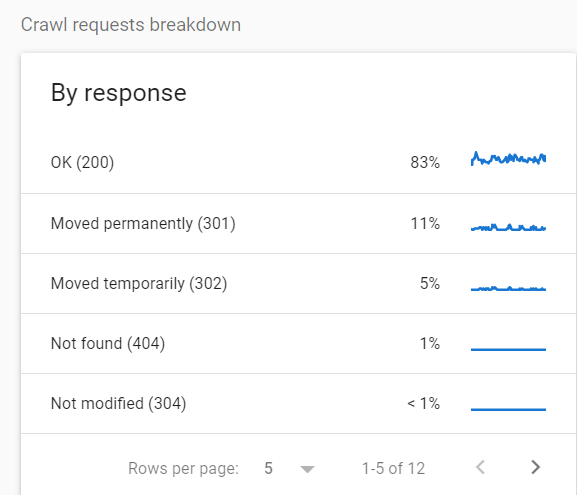
Dans ce cas particulier, 16 % de toutes les requêtes concernaient des pages redirigées.
Si vous voyez des statistiques comme celles-ci, je vous recommande d'enquêter davantage et de rechercher des sauts de redirection et d'autres problèmes potentiels.
À mon avis, l'un des pires cas que vous pouvez voir ici est une grande quantité d'erreurs 5xx.
Pour citer la documentation de Google : "Si le site ralentit ou répond avec des erreurs de serveur, la limite diminue et Googlebot explore moins."
Si ce sujet vous intéresse, Roger Montti a écrit un article détaillé sur les erreurs 5xx dans Google Search Console.
3. Objectif
Le rapport sur les statistiques de crawl décompose l'objectif de crawl en deux catégories :
- URL explorées à des fins d'actualisation (une nouvelle exploration de pages déjà connues, par exemple, Googlebot visite votre page d'accueil pour découvrir de nouveaux liens et contenus).
- URL explorées à des fins de découverte (URL explorées pour la première fois).
Cette répartition est incroyablement utile, et voici un exemple :
J'ai récemment rencontré un site Web avec environ 1 million de pages classées comme "Découvertes - actuellement non indexées".
Ce problème a été signalé pour 90 % de toutes les pages de ce site.
(Si vous ne le connaissez pas, "Découvert mais pas indexé" signifie que Google a découvert une page donnée mais ne l'a pas visitée. Si vous avez découvert un nouveau restaurant dans votre ville mais que vous ne l'avez pas essayé, par exemple .)
Une des options était d'attendre, en espérant que Google indexe progressivement ces pages.
Une autre option consistait à examiner les données et à diagnostiquer le problème.
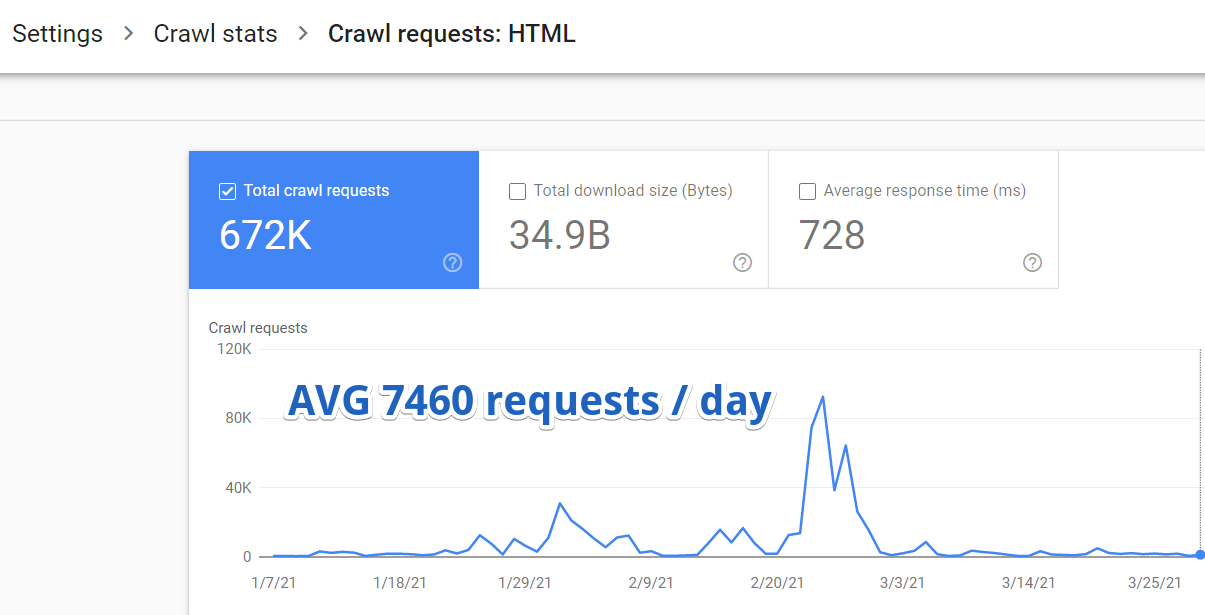
Je me suis donc connecté à Google Search Console et j'ai navigué vers Paramètres > Statistiques d'exploration > Demandes d'exploration : HTML .
Il s'est avéré qu'en moyenne, Google ne visitait que 7460 pages sur ce site Web par jour.
Mais voici quelque chose d'encore plus important.
Grâce au rapport Crawl stats, j'ai découvert que seulement 35% de ces 7460 URL étaient crawlées pour des raisons de découverte.
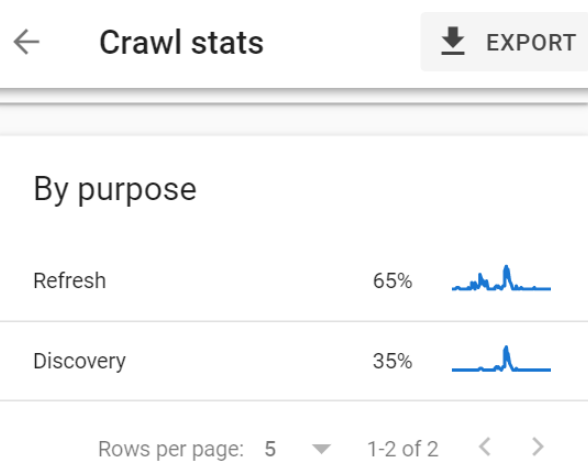

Ce n'est que 2611 nouvelles pages découvertes par Google par jour.
2611 sur plus d'un million.
Il faudrait 382 jours à Google pour indexer entièrement l'ensemble du site Web à ce rythme.
Découvrir cela a changé la donne. Toutes les autres optimisations de recherche ont été reportées car nous nous sommes entièrement concentrés sur l'optimisation du budget de crawl.
4. Type de fichier
Les statistiques de GSC Crawl peuvent être utiles pour les sites Web JavaScript. Vous pouvez facilement vérifier la fréquence à laquelle Googlebot explore les fichiers JS requis pour un rendu correct.
Si votre site regorge d'images et que la recherche d'images est cruciale pour votre stratégie de référencement, ce rapport vous aidera également beaucoup - vous pouvez voir à quel point Googlebot peut explorer vos images.
5. Type de Googlebot
Enfin, le rapport sur les statistiques d'exploration vous donne une ventilation détaillée du type de Googlebot utilisé pour explorer votre site.
Vous pouvez connaître le pourcentage de requêtes effectuées par les Googlebots mobiles ou de bureau et les bots d'images, de vidéos et d'annonces.
Autres informations utiles
Il convient de noter que le rapport Crawl stats contient des informations inestimables que vous ne trouverez pas dans les journaux de votre serveur :
- Erreurs DNS.
- Délais d'expiration des pages.
- Problèmes d'hôte tels que des problèmes de récupération du fichier robots.txt.
Utilisation des statistiques d'exploration dans l'outil d'inspection d'URL
Vous pouvez également accéder à certaines données d'exploration granulaires en dehors du rapport de statistiques d'exploration, dans l'outil d'inspection d'URL.
J'ai récemment travaillé avec un grand site de commerce électronique et, après quelques analyses initiales, j'ai remarqué deux problèmes urgents :
- De nombreuses pages de produits n'étaient pas indexées dans Google.
- Il n'y avait pas de lien interne entre les produits. Le seul moyen pour Google de découvrir de nouveaux contenus était par le biais de plans de site et de pages de catégories paginées.
Une prochaine étape naturelle consistait à accéder aux journaux du serveur et à vérifier si Google avait exploré les pages de catégories paginées.
Mais l'accès aux journaux du serveur est souvent très difficile, surtout lorsque vous travaillez avec une grande organisation.
Le rapport de statistiques Crawl de Google Search Console est venu à la rescousse.
Laissez-moi vous guider à travers le processus que j'ai utilisé et que vous pouvez utiliser si vous rencontrez un problème similaire :
1. Tout d'abord, recherchez une URL dans l'outil d'inspection d'URL. J'ai choisi une des pages paginées d'une des principales catégories du site.
2. Ensuite, accédez au rapport Coverage > Crawl .
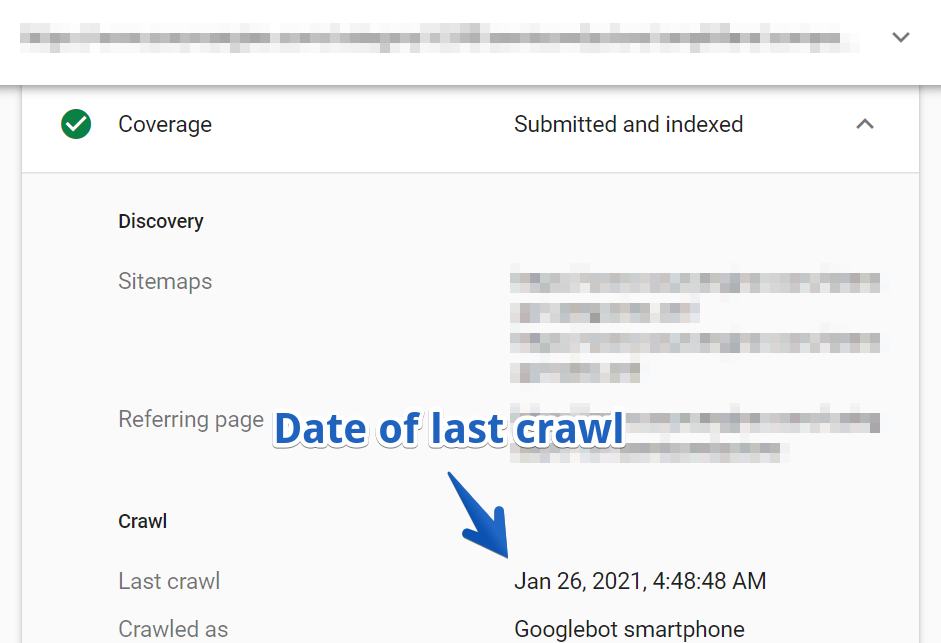
Dans ce cas, l'URL a été explorée pour la dernière fois il y a trois mois.
Gardez à l'esprit qu'il s'agissait de l'une des principales pages de catégorie du site Web qui n'avait pas été explorée depuis plus de trois mois !
Je suis allé plus loin et j'ai vérifié un échantillon d'autres pages de catégorie.
Il s'est avéré que Googlebot n'a jamais visité de nombreuses pages de catégories principales. Beaucoup d'entre eux sont encore inconnus de Google.
Je ne pense pas avoir besoin d'expliquer à quel point il est crucial de disposer de ces informations lorsque vous travaillez à l'amélioration de la visibilité d'un site Web.
Le rapport de statistiques Crawl vous permet de rechercher des choses comme celle-ci en quelques minutes.
Emballer
Comme vous pouvez le constater, le rapport de statistiques Crawl est un puissant outil de référencement, même si vous pouvez utiliser Google Search Console pendant des années sans jamais le trouver.
Il vous aidera à diagnostiquer les problèmes d'indexation et à optimiser votre budget de crawl afin que Google puisse trouver et indexer rapidement votre précieux contenu, ce qui est particulièrement important pour les grands sites.
Je vous ai donné quelques cas d'utilisation auxquels réfléchir, mais maintenant la balle est dans votre camp.
Comment allez-vous utiliser ces données pour améliorer la visibilité de votre site ?
Davantage de ressources:
- Crawl-First SEO : un guide en 12 étapes à suivre avant de crawler
- 7 conseils pour optimiser le budget de crawl pour le référencement
- Comment fonctionnent les moteurs de recherche
Crédits image
Toutes les captures d'écran prises par l'auteur, avril 2021