
A/B 测试中的 I 型和 II 型错误以及如何避免它们
已发表: 2020-12-04A/B 测试涉及将您网站上的传入流量随机分配给特定网页的多个变体,以衡量哪一个会对您的关键指标产生积极影响。 很简单,对吧? 好吧,没有那么多。 虽然 A/B 测试听起来很简单,但其操作背后的科学和数学以及结果的计算可能会变得相当棘手。
统计是A/B测试的基石,计算概率是统计的基础。 因此,您永远无法 100% 确定收到的结果的准确性或将风险降低到 0%。 相反,您只能增加测试结果为真的可能性。 但是作为测试所有者,您不需要为此烦恼,因为您的工具应该会处理好这个问题。
即使遵循了所有基本步骤,您的测试结果报告也可能会因不知不觉地潜入过程中的错误而出现偏差。 通常被称为 I 型和 II 型错误,这些错误基本上会导致错误的测试结论和/或错误的赢家和输家声明。 这会导致对测试结果报告的误解,最终误导您的整个优化计划,并可能导致您的转换甚至收入损失。

让我们仔细看看 I 型和 II 型错误的确切含义、它们的后果以及如何避免它们。
您的 A/B 测试结果中会出现哪些错误?
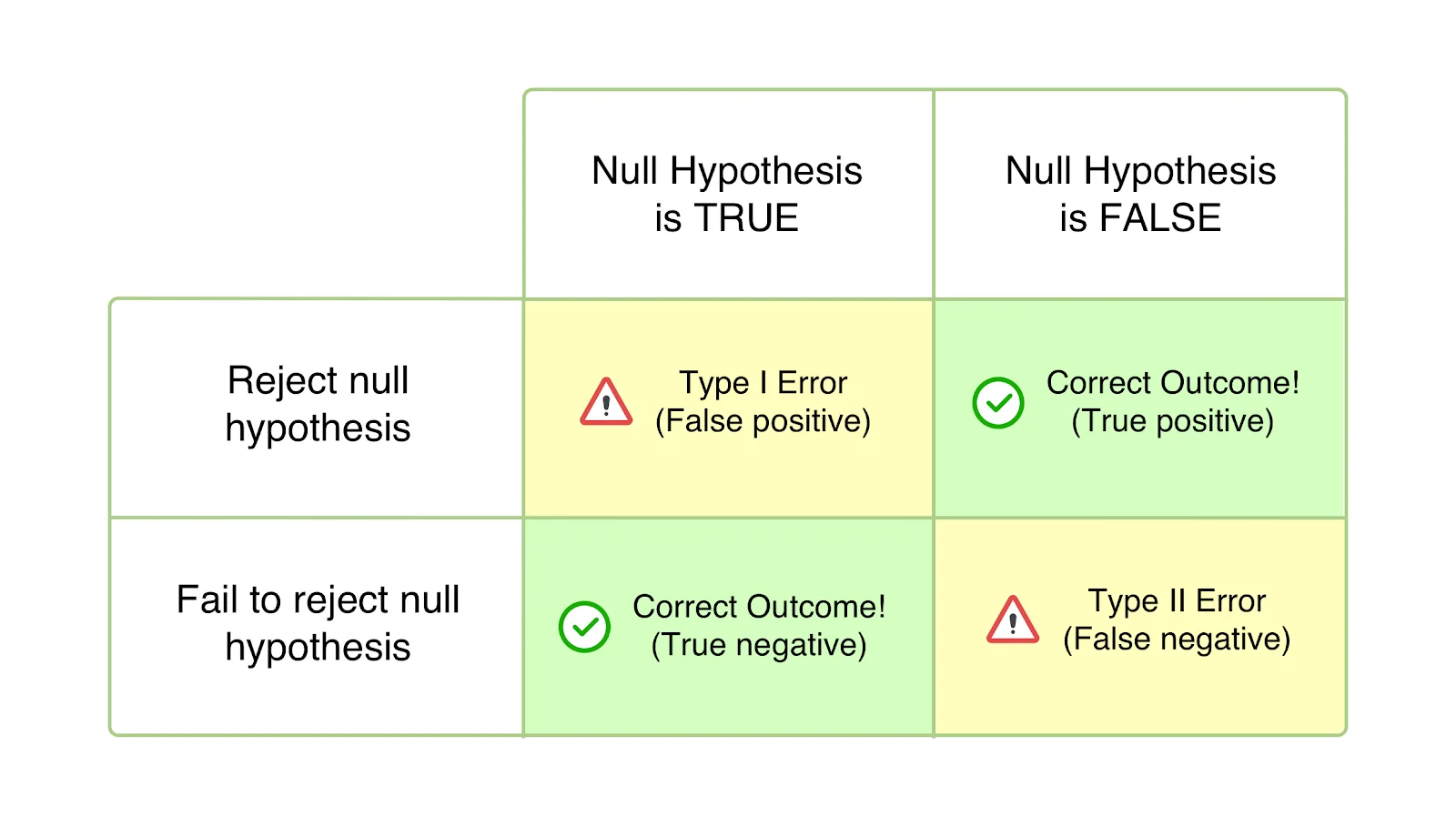
第一类错误
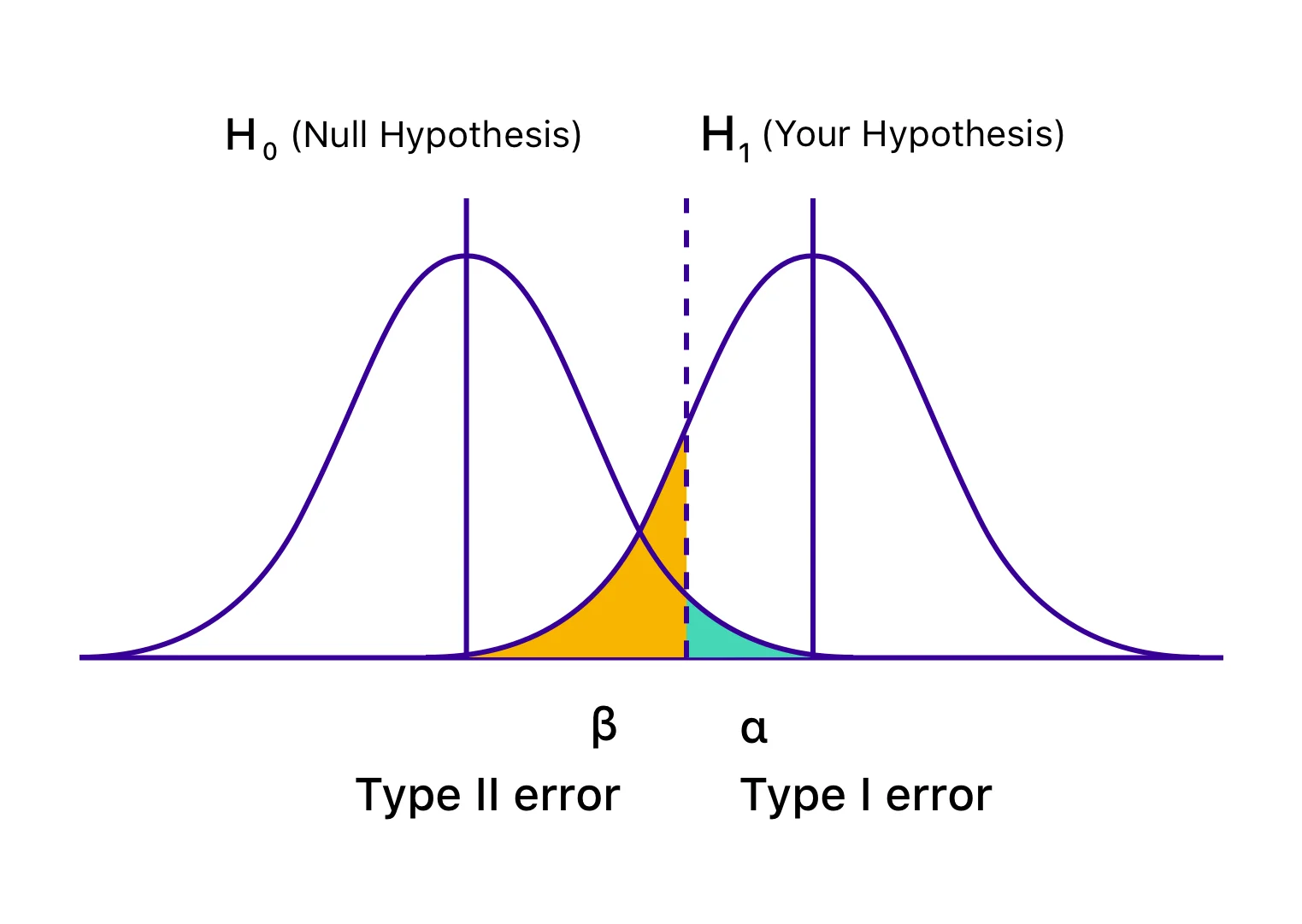
也称为 Alpha (α) 错误或误报,在 I 类错误的情况下,您的测试似乎是成功的,并且您的变化似乎会对为测试定义的目标造成影响(更好或更坏)。 然而,事实上,上升或下降只是暂时的,一旦你普遍部署获胜版本并衡量其在很长一段时间内的影响,它就不会持续下去。 当您在达到统计显着性或预先确定的标准之前结束测试并急于拒绝您的零假设并接受获胜的变化时,就会发生这种情况。 零假设表明上述变化对给定的指标/目标没有影响。 在第一类错误的情况下,原假设为真,但由于检验结论不及时或结论标准计算错误而被拒绝。
犯 I 类错误的概率用“α”表示,并与您决定结束测试的置信水平相关。 这意味着,如果您以 95% 的置信水平结束测试,则您接受有 5% 的概率得到错误结果。 同样,如果该置信水平为 99%,则测试结果错误的概率为 1%。 你可以称之为纯粹的运气不好,但如果即使在 95% 的置信水平下结束测试后仍遇到 α 错误,这意味着仅发生了 5% 概率的事件。
假设您设计了一个假设,即将着陆页 CTA 移到首屏会导致注册数量增加。 这里的零假设是,更改 CTA 的位置不会对收到的注册数量产生影响。 测试开始后,您很想查看结果,并注意到一周内因变化而产生的注册量增加了 45%。 您确信对比度要好得多,并最终结束检验,拒绝原假设,并普遍部署变体 - 只是注意到它不再具有类似的影响,而是根本没有影响。 唯一的解释是您的测试结果报告被 I 类错误所歪曲。
如何避免 I 类错误
虽然您不能完全消除遇到 I 类错误的可能性,但您当然可以减少它。 为此,请确保仅在测试达到足够高的置信度后才结束测试。 95% 的置信水平被认为是理想的,这是您必须达到的目标。 即使达到 95% 的置信水平,您的测试结果也可能会因 I 类错误而改变(如上所述)。 因此,您还需要确保您运行测试的时间足够长,以保证已经测试了良好的样本量,从而提高了测试结果的可信度。
您可以使用 VWO 的 A/B 测试持续时间计算器来确定您必须运行特定测试的理想时间段。 同样,您还可以计算您的 A/B 测试样本量,以确保仅在您获得掺假结果的可能性最低时才结束测试。
VWO 的基于贝叶斯模型的统计引擎 SmartStats 可帮助您降低遇到 1 类错误的可能性。
II 类错误
也称为 Beta (β) 错误或假阴性,在 II 类错误的情况下,特定测试似乎没有结论或不成功,零假设似乎为真。 实际上,变化会影响预期目标,但结果未能显示,并且证据支持零假设。 因此,您最终(错误地)接受了原假设并拒绝了您的假设和变异。
II 类错误通常会导致放弃和阻碍测试,但在最坏的情况下,缺乏追求 CRO 路线图的动力,因为人们往往会忽视这些努力,假设它没有产生任何影响。
“β”表示犯第二类错误的概率。 不遇到 II 类错误的概率用 1 – β 表示,取决于检验的统计功效。 测试的统计功效越高,遇到 II 类错误的可能性就越低。 如果您以 90% 的统计功效运行测试,那么您最终可能会出现假阴性的可能性只有 10%。

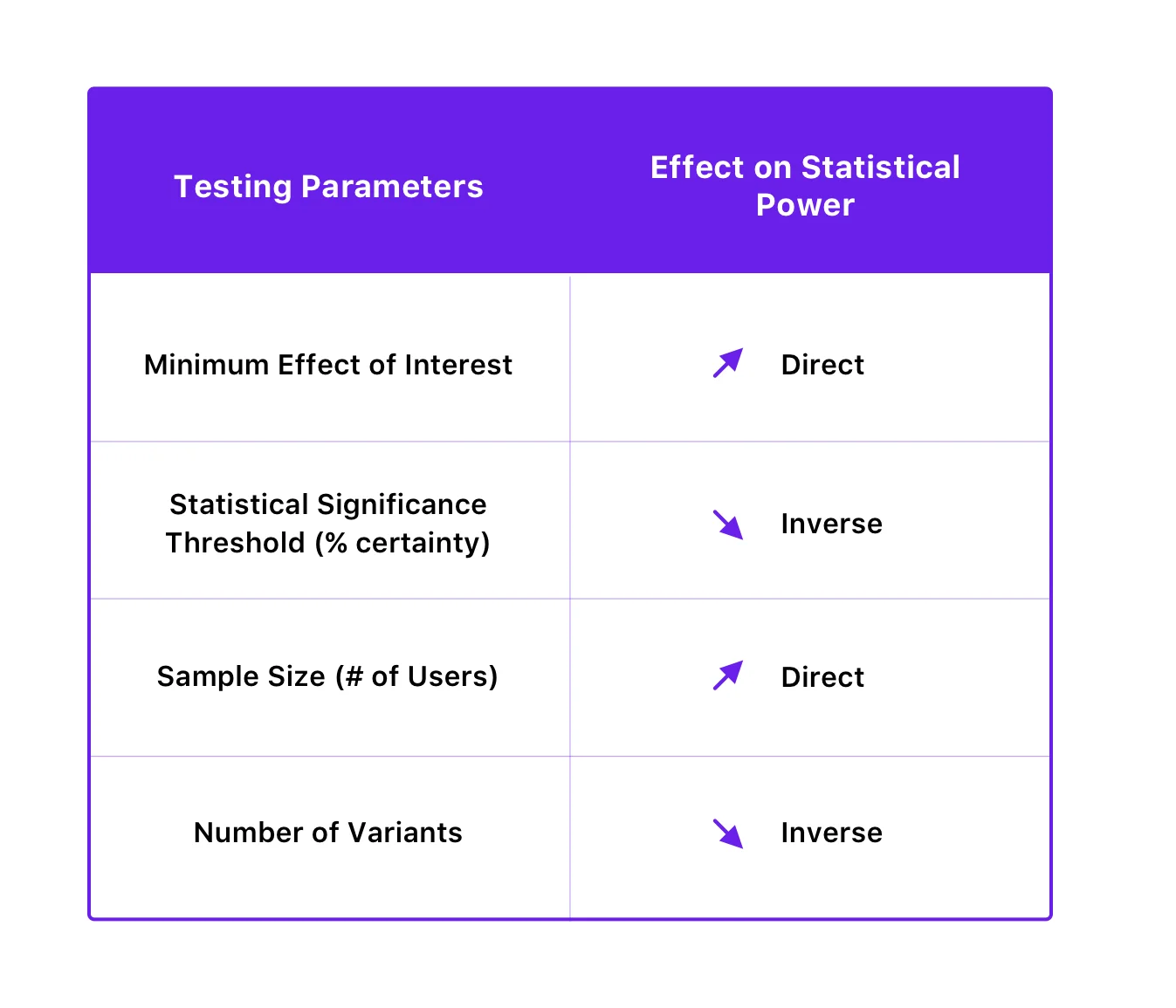
检验的统计功效取决于统计显着性阈值、样本量、感兴趣的最小效应量,甚至检验的变异数。
以下是它们的关系:
让我们假设您假设在您的支付页面上添加安全徽章将帮助您减少该阶段的流失率。 您使用安全徽章创建付款页面的变体并运行您的测试,只是在开始 10 天后查看结果。 在注意到转化次数或下降次数没有变化后,您决定结束检验并声明原假设为真。 不相信测试结果,您决定重新运行测试——只是这一次您让它运行更长时间。 因此,您注意到这次的转化目标有了显着改善。 第一次发生的情况是您在要求的时间之前结束测试,遇到了 II 类错误。
如何避免 II 类错误
通过提高测试的统计能力,您可以避免 II 类错误。 您可以通过增加样本量和减少变体数量来做到这一点。 有趣的是,提高统计能力以降低 II 类错误的概率也可以通过降低统计显着性阈值来实现,但反过来,它会增加 I 类错误的概率。 然而,由于降低 I 类错误的概率通常优先于避免 II 类错误(因为其后果可能更严重),为了提高功效,建议不要干扰统计显着性阈值。
VWO SmartStats – 更智能的贝叶斯商业决策方式
理想情况下,作为测试负责人,您不应该关注统计数据,因为您的任务不是通过实验找到真相——您的动机是做出更好的业务决策,从而为您带来更高的收入。 因此,重要的是使用一种工具来帮助您做出更好、更明智的选择,而无需深入了解统计数据的细节。
根据推论统计的频率论模型,测试的结论完全取决于达到统计显着性。 如果您在测试达到统计显着性之前结束测试,您可能会得到误报(I 型错误)。
VWO 的基于贝叶斯模型的统计引擎 SmartStats 会计算出这种变化超出控制的概率,以及在部署它时可能遭受的潜在损失。 VWO 向您显示与部署变体相关的可能损失,以便您做出明智的选择。
这种潜在的损失也有助于决定何时结束特定的测试。 测试结束后,只有当变体的潜在损失低于某个阈值时,才会宣布变体获胜。 这个阈值是通过考虑控制版本的转换率、作为测试的一部分的访问者数量和一个常数值来确定的。
VWO SmartStats 不仅可以将您的测试时间减少 50%(因为您不依赖于达到设定的时间和样本量来结束您的测试),而且还可以让您更好地控制您的实验。 它为您提供明确的概率,帮助您根据正在运行的测试类型做出决策。 例如,如果您正在测试影响较小的更改,例如更改按钮颜色,则可能有 90% 的概率足以称变体为赢家。 或者,如果您在漏斗的最后一步测试某些东西,您可能希望等到 99% 的概率。 然后,您可以通过更快地完成低影响测试并在路线图中优先考虑高影响测试来提高测试速度。
通过假设它是 A/A 测试,基于频率的统计模型只会让您看到变化差异的概率。 但是,这种方法假定您仅在获得足够的样本量后才进行测试计算。 VWO SmartStats 不做任何假设,而是通过减少遇到 I 类和 II 类错误的可能性,使您能够做出更明智的业务决策。 这是因为它估计了变化超过控制的概率,以及相关的潜在损失,允许您在测试运行时持续监控这些指标。
由于统计数据很难达到绝对确定性,因此您无法消除测试结果不会因错误而出现偏差的可能性。 但是,通过选择像 VWO 这样的强大工具,您可以降低出错的机会或将与这些错误相关的风险降低到可接受的水平。 要详细了解 VWO 究竟如何让您避免陷入此类错误,请试用 VWO 的免费试用版或请求我们的一位优化专家进行演示。
