
Błędy typu I i typu II w testach A/B oraz jak ich uniknąć
Opublikowany: 2020-12-04Testy A/B polegają na losowym dzieleniu ruchu przychodzącego w witrynie między wiele odmian konkretnej strony internetowej, aby ocenić, która z nich ma pozytywny wpływ na krytyczne dane. Całkiem proste, prawda? Cóż, nie tak bardzo. Chociaż testy A/B mogą wydawać się proste, nauka i matematyka stojąca za jego działaniem i obliczaniem wyników mogą być dość trudne.
Statystyka to podstawa testów A/B, a obliczanie prawdopodobieństw to podstawa statystyk. Dlatego nigdy nie można być w 100% pewnym dokładności otrzymywanych wyników lub zmniejszyć ryzyko do 0%. Zamiast tego możesz tylko zwiększyć prawdopodobieństwo, że wynik testu będzie prawdziwy. Ale jako właściciele testów nie powinieneś się tym przejmować, ponieważ Twoje narzędzie powinno się tym zająć.
Nawet po wykonaniu wszystkich niezbędnych kroków raporty z wynikami testów mogą zostać wypaczone przez błędy, które nieświadomie wkradają się do procesu. Powszechnie znane jako błędy typu I i typu II, prowadzą one w zasadzie do błędnego zakończenia testów i/lub błędnej deklaracji zwycięzcy i przegranego. Powoduje to błędną interpretację raportów wyników testów, co ostatecznie wprowadza w błąd cały program optymalizacji i może kosztować konwersje, a nawet przychody.

Przyjrzyjmy się bliżej, co dokładnie rozumiemy przez błędy typu I i typu II, ich konsekwencje i jak możesz ich uniknąć.
Jakie błędy pojawiają się w wynikach testu A/B?
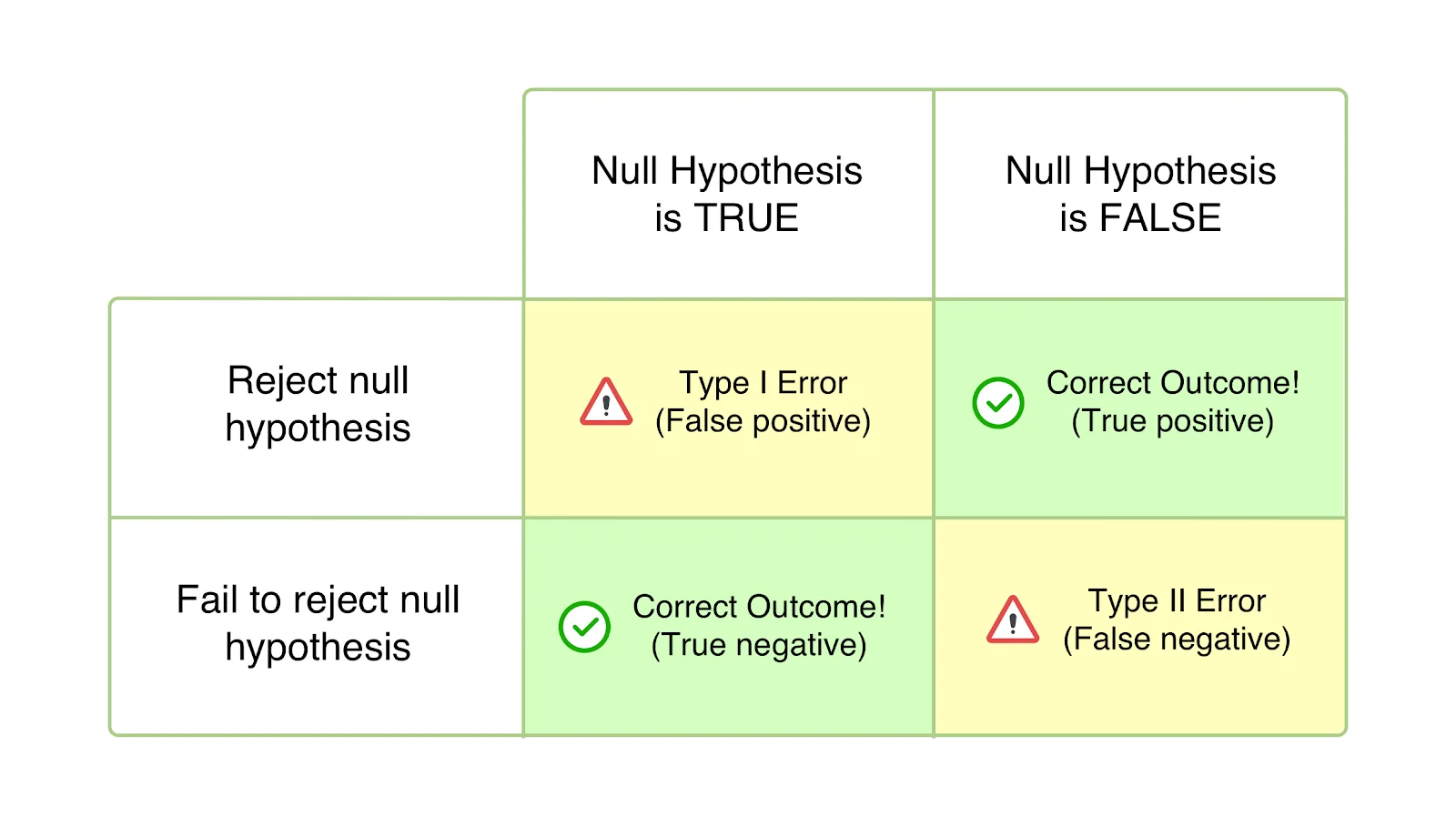
Błędy typu I
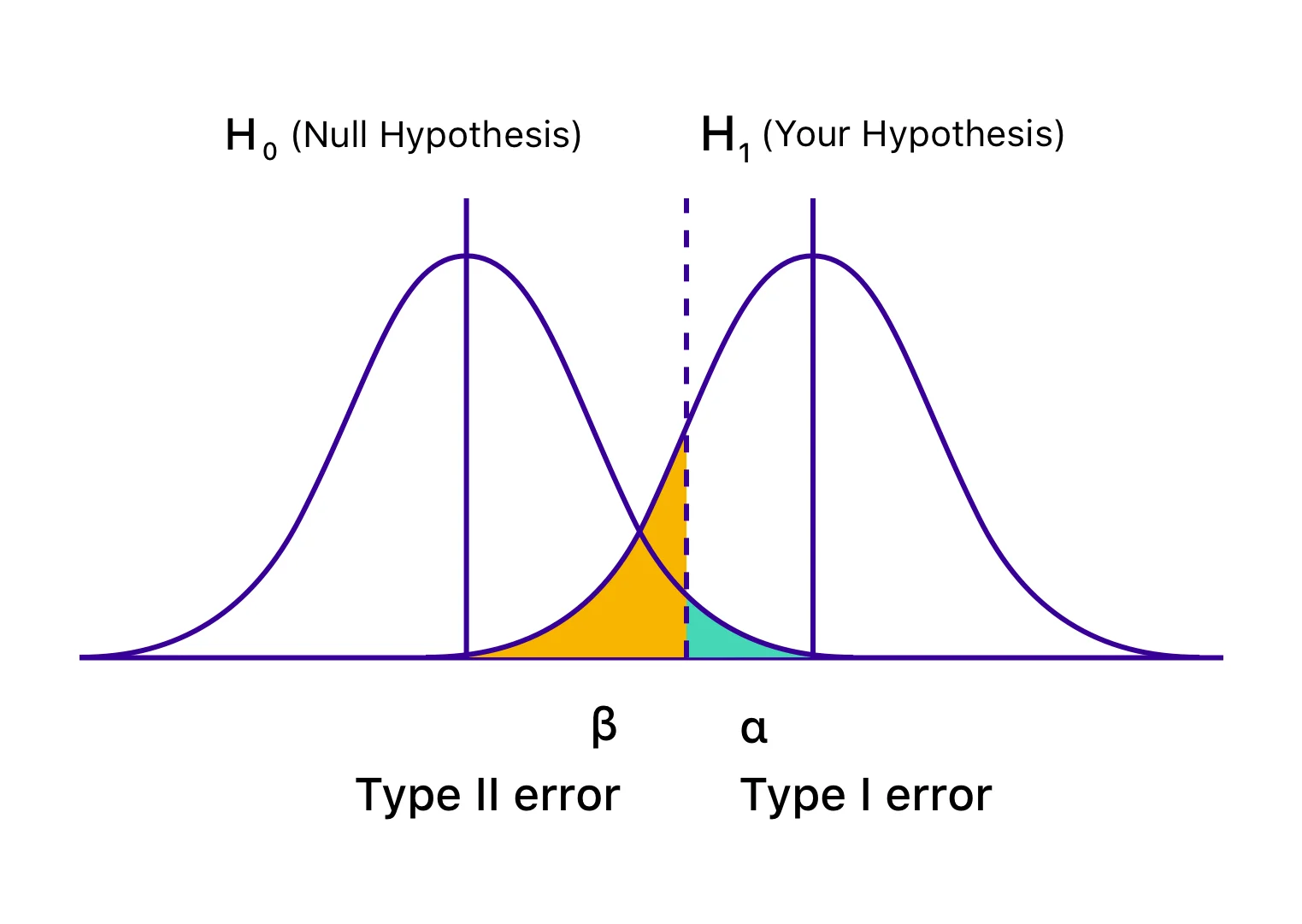
Nazywane również błędami alfa (α) lub fałszywie dodatnimi, w przypadku błędu typu I twój test wydaje się być pomyślny, a twoja odmiana wydaje się mieć wpływ (lepszy lub gorszy) na cele określone dla testu. Jednak wzrost lub spadek jest w rzeczywistości tylko tymczasowy i nie będzie trwały po uniwersalnym wdrożeniu zwycięskiej wersji i zmierzeniu jej wpływu przez dłuższy czas. Dzieje się tak, gdy zakończysz test przed osiągnięciem istotności statystycznej lub wstępnie ustalonych kryteriów i pospiesz się z odrzuceniem hipotezy zerowej i zaakceptowaniem zwycięskiej odmiany. Hipoteza zerowa mówi, że wspomniana zmiana nie będzie miała wpływu na daną metrykę/cel. A w przypadku błędów typu I hipoteza zerowa jest prawdziwa, ale odrzucona z powodu przedwczesnego zakończenia testów lub błędnego obliczenia kryteriów wniosku.
Prawdopodobieństwo popełnienia błędu Typu I jest oznaczane przez „α” i skorelowane z poziomem ufności, na którym decydujesz się zakończyć test. Oznacza to, że jeśli zakończysz test na poziomie ufności 95%, zgadzasz się, że istnieje 5% prawdopodobieństwo otrzymania błędnego wyniku. Podobnie, jeśli ten poziom ufności wynosi 99%, prawdopodobieństwo błędnego wyniku testu wynosi 1%. Można to nazwać zwykłym pechem, ale jeśli natrafisz na błąd α nawet po zakończeniu testu na poziomie ufności 95%, oznacza to, że wystąpiło zdarzenie z prawdopodobieństwem zaledwie 5%.
Załóżmy, że wymyślasz hipotezę, że przeniesienie CTA na stronę docelową powyżej części ekranu spowoduje wzrost liczby rejestracji. Hipoteza zerowa jest taka, że zmiana miejsca CTA nie miałaby wpływu na liczbę otrzymanych rejestracji. Po rozpoczęciu testu masz ochotę zajrzeć do wyników i zauważyć aż 45% wzrost liczby rejestracji generowanych przez tę odmianę w ciągu tygodnia. Jesteś przekonany, że kontrast jest znacznie lepszy i kończysz test, odrzucając hipotezę zerową i stosując uniwersalną odmianę — tylko po to, by zauważyć, że nie ma już podobnego wpływu, ale nie ma żadnego wpływu. Jedynym wyjaśnieniem jest to, że raport z wynikami testu został wypaczony przez błąd typu I.
Jak uniknąć błędów typu I
Chociaż nie można całkowicie wyeliminować możliwości napotkania błędu typu I, z pewnością można go zmniejszyć. W tym celu upewnij się, że kończysz testy dopiero wtedy, gdy osiągną wystarczająco wysoki poziom ufności. 95% poziom ufności jest uważany za idealny i właśnie do tego musisz dążyć. Nawet po osiągnięciu 95% poziomu ufności wyniki testu mogą zostać zmienione przez błąd typu I (jak omówiono powyżej). Dlatego musisz również upewnić się, że przeprowadzasz testy wystarczająco długo, aby zagwarantować, że przetestowano dobrą wielkość próbki, zwiększając w ten sposób wiarygodność wyników testu.
Możesz użyć kalkulatora czasu trwania testów A/B VWO, aby określić idealny okres, w którym musisz przeprowadzić konkretny test. Podobnie, możesz również obliczyć wielkość próby testu A/B, aby upewnić się, że przeprowadzasz testy tylko wtedy, gdy masz najmniejszą szansę na uzyskanie zafałszowanych wyników.
Oparty na modelach Bayesowski silnik statystyczny VWO, SmartStats, pomaga zmniejszyć prawdopodobieństwo napotkania błędu typu 1.
Błędy typu II
Znany również jako błędy beta (β) lub fałszywie ujemne, w przypadku błędów typu II, konkretny test wydaje się niejednoznaczny lub nieudany, a hipoteza zerowa wydaje się być prawdziwa. W rzeczywistości zmienność wpływa na pożądany cel, ale wyniki nie są widoczne, a dowody przemawiają za hipotezą zerową. W związku z tym kończysz (niepoprawnie) akceptując hipotezę zerową i odrzucając swoją hipotezę i wariację.
Błędy typu II zwykle prowadzą do porzucenia i zniechęcenia do testów, ale w najgorszych przypadkach brak motywacji do podążania za mapą drogową CRO, ponieważ zwykle lekceważy się wysiłki, zakładając, że nie miały one żadnego wpływu.
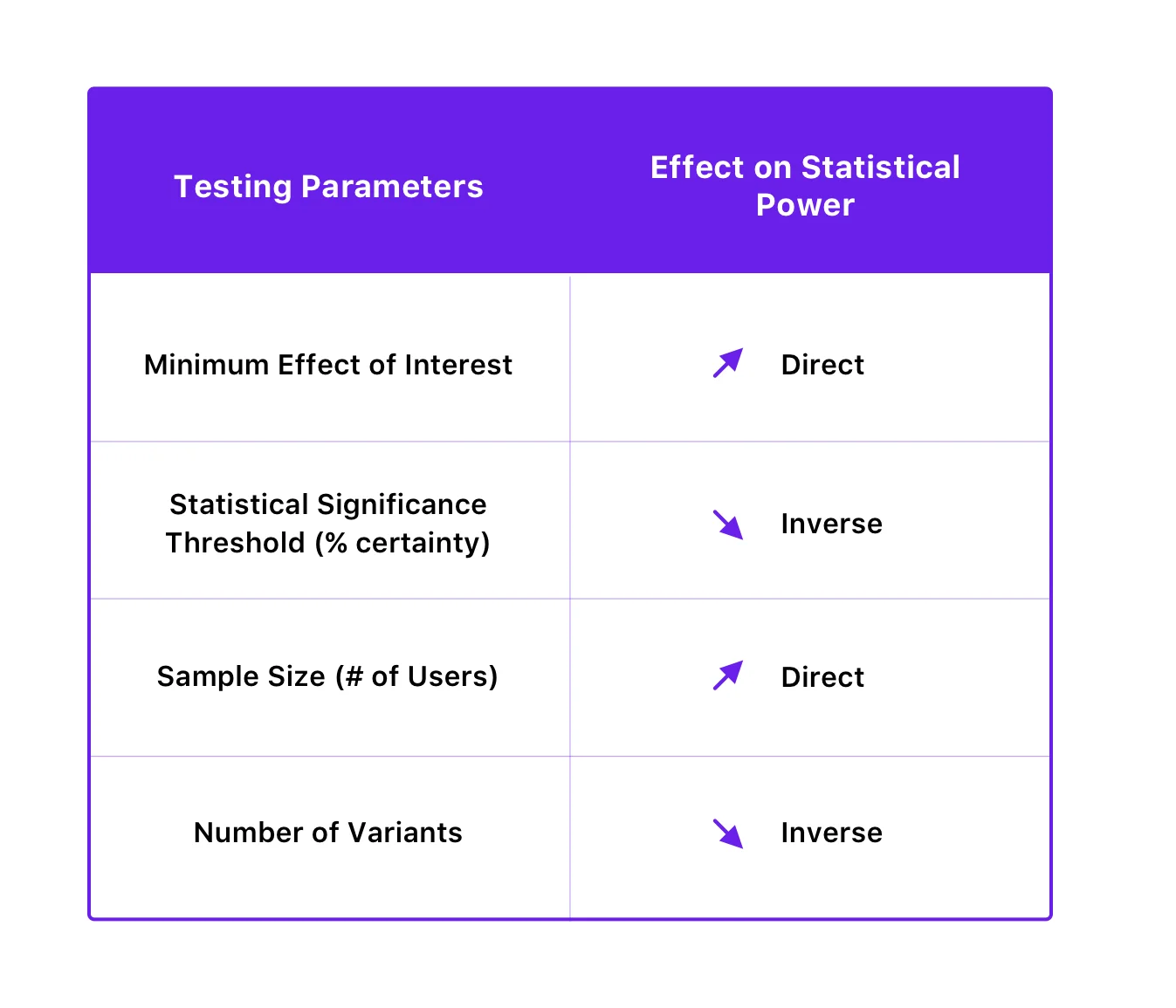
„β” oznacza prawdopodobieństwo popełnienia błędu typu II. Prawdopodobieństwo nie popełnienia błędu typu II jest oznaczane przez 1 – β, w zależności od mocy statystycznej testu. Im wyższa moc statystyczna twojego testu, tym mniejsze prawdopodobieństwo napotkania błędu typu II. Jeśli przeprowadzasz test z 90% mocą statystyczną, istnieje tylko 10% szansy, że otrzymasz fałszywie negatywny wynik.

Siła statystyczna testu zależy od progu istotności statystycznej, wielkości próby, minimalnej wielkości interesującego efektu, a nawet liczby wariacji testu.
Oto jak są ze sobą powiązane:
Załóżmy, że stawiasz hipotezę, że dodanie plakietek bezpieczeństwa na stronie płatności pomogłoby w zmniejszeniu odsetka rezygnacji na tym etapie. Tworzysz odmianę strony płatności z plakietkami bezpieczeństwa i uruchamiasz test tylko po to, aby zerknąć na wyniki 10 dni po jego rozpoczęciu. Gdy zauważysz brak zmian w liczbie konwersji lub porzuceń, decydujesz się zakończyć test i zadeklarować prawdziwość hipotezy zerowej. Nie przekonany do wyników testu, decydujesz się na powtórzenie testu – tylko tym razem pozwalasz mu działać dłużej. W rezultacie tym razem zauważasz znaczną poprawę celu konwersji. To, co wydarzyło się za pierwszym razem, polegało na tym, że napotkałeś błąd typu II, kończąc test przed wymaganym czasem.
Jak uniknąć błędów typu II
Poprawiając siłę statystyczną swoich testów, możesz uniknąć błędów typu II. Możesz to zrobić, zwiększając wielkość próbki i zmniejszając liczbę wariantów. Co ciekawe, poprawę mocy statystycznej w celu zmniejszenia prawdopodobieństwa błędów typu II można również osiągnąć poprzez zmniejszenie progu istotności statystycznej, ale z kolei zwiększa to prawdopodobieństwo błędów typu I. Jednakże, ponieważ zmniejszenie prawdopodobieństwa błędów typu I zwykle ma pierwszeństwo przed unikaniem błędów typu II (ponieważ jego konsekwencje mogą być poważniejsze), zaleca się nie ingerować w próg istotności statystycznej ze względu na poprawę mocy.
VWO SmartStats – mądrzejszy, bayesowski sposób na podejmowanie decyzji biznesowych
W idealnym przypadku, jako właściciel testu, statystyki nie są czymś, na czym powinieneś się koncentrować, ponieważ Twoim zadaniem nie jest znalezienie prawdy za pomocą eksperymentów — Twoim motywem jest podjęcie lepszej decyzji biznesowej, która przyniesie Ci wyższe przychody. Dlatego ważne jest, aby pracować z narzędziem, które pomoże Ci dokonać lepszego, mądrzejszego wyboru — bez konieczności zagłębiania się w szczegóły statystyk.
Zgodnie z częstym modelem statystyki wnioskowania, zakończenie testu jest całkowicie zależne od osiągnięcia istotności statystycznej. Jeśli zakończysz test, zanim osiągnie on istotność statystyczną, prawdopodobnie otrzymasz fałszywie pozytywny wynik (błąd typu I).
Silnik statystyk VWO oparty na modelu Bayesa, SmartStats, oblicza prawdopodobieństwo, że ta zmiana pokona kontrolę, a także potencjalną stratę, którą możesz ponieść po jej wdrożeniu. VWO pokazuje możliwą stratę związaną z wdrożeniem odmiany, dzięki czemu możesz dokonać świadomego wyboru.
Ta potencjalna strata pomaga również zdecydować, kiedy zakończyć dany test. Po zakończeniu testu zmiana jest ogłaszana zwycięzcą tylko wtedy, gdy potencjalna utrata zmiany jest poniżej określonego progu. Próg ten ustalany jest na podstawie współczynnika konwersji wersji kontrolnej, liczby odwiedzających, którzy byli częścią testu oraz wartości stałej.
VWO SmartStats nie tylko skraca czas testowania o 50% — ponieważ nie polegasz na osiągnięciu ustalonego czasu i wielkości próbki, aby zakończyć test — ale także zapewnia większą kontrolę nad eksperymentami. Daje ci jasne prawdopodobieństwo, które pomaga podejmować decyzje w oparciu o rodzaj testu, który prowadzisz. Na przykład, jeśli testujesz zmianę o niewielkim wpływie, taką jak zmiana koloru przycisku, być może 90% prawdopodobieństwo jest wystarczające, aby nazwać odmianę zwycięzcą. Lub, jeśli testujesz coś na ostatnim etapie ścieżki, możesz poczekać do 99% prawdopodobieństwa. Jesteś więc w stanie zwiększyć swoją prędkość testowania, szybciej kończąc testy o niskim wpływie i nadając priorytet tym o dużym wpływie w swojej mapie drogowej.
Model statystyczny oparty na frequencyistach daje prawdopodobieństwo zauważenia różnicy w odmianach tylko przy założeniu, że jest to test A/A. To podejście zakłada jednak, że wykonujesz obliczenia testowe dopiero po uzyskaniu wystarczającej wielkości próby. VWO SmartStats nie przyjmuje żadnych założeń, zamiast tego umożliwia podejmowanie mądrzejszych decyzji biznesowych poprzez zmniejszenie prawdopodobieństwa napotkania błędów typu I i typu II. Dzieje się tak, ponieważ szacuje prawdopodobieństwo, że zmienność pokona kontrolę, o ile, wraz z powiązaną potencjalną stratą, umożliwiając ciągłe monitorowanie tych metryk podczas wykonywania testu.
Ponieważ dążenie do absolutnej pewności jest niezwykle trudne w przypadku statystyk, nie można wyeliminować możliwości, że wyniki testu nie zostaną przekrzywione z powodu błędu. Jednak wybierając solidne narzędzie, takie jak VWO, możesz zmniejszyć swoje szanse na popełnienie błędów lub zmniejszyć ryzyko związane z tymi błędami do akceptowalnego poziomu. Aby dowiedzieć się więcej o tym, jak dokładnie VWO może uchronić Cię przed takimi błędami, wypróbuj bezpłatną wersję próbną VWO lub poproś o demonstrację jednego z naszych ekspertów ds. optymalizacji.
