
Fehler vom Typ I und Typ II beim A/B-Testen und wie man sie vermeidet
Veröffentlicht: 2020-12-04A/B-Tests beinhalten das zufällige Aufteilen des eingehenden Datenverkehrs auf Ihrer Website auf mehrere Variationen einer bestimmten Webseite, um zu messen, welche sich positiv auf Ihre kritischen Metriken auswirkt. Ziemlich einfach, oder? Nun, nicht so sehr. Während A/B-Tests einfach klingen mögen, können die Wissenschaft und Mathematik hinter seiner Funktionsweise und die Berechnung der Ergebnisse ziemlich knifflig werden.
Statistiken sind der Eckpfeiler von A/B-Tests, und die Berechnung von Wahrscheinlichkeiten ist die Grundlage von Statistiken. Daher können Sie sich der Genauigkeit der erhaltenen Ergebnisse nie zu 100 % sicher sein oder das Risiko auf 0 % reduzieren. Stattdessen können Sie nur die Wahrscheinlichkeit erhöhen, dass das Testergebnis wahr ist. Aber als Testbesitzer sollten Sie sich darum nicht kümmern müssen, da Ihr Tool sich darum kümmern sollte.
Selbst nachdem Sie alle wesentlichen Schritte ausgeführt haben, können Ihre Testergebnisberichte durch Fehler verzerrt werden, die sich unwissentlich in den Prozess einschleichen. Im Volksmund als Typ-I- und Typ-II-Fehler bekannt, führen diese im Wesentlichen zu einem falschen Abschluss von Tests und/oder einer fehlerhaften Bestimmung von Gewinner und Verlierer. Dies führt zu einer Fehlinterpretation von Testergebnisberichten, was letztendlich Ihr gesamtes Optimierungsprogramm in die Irre führt und Sie Konversionen und sogar Einnahmen kosten kann.

Schauen wir uns genauer an, was wir unter Fehlern 1. und 2. Art verstehen, welche Folgen sie haben und wie Sie sie vermeiden können.
Welche Fehler schleichen sich in Ihre A/B-Testergebnisse ein?
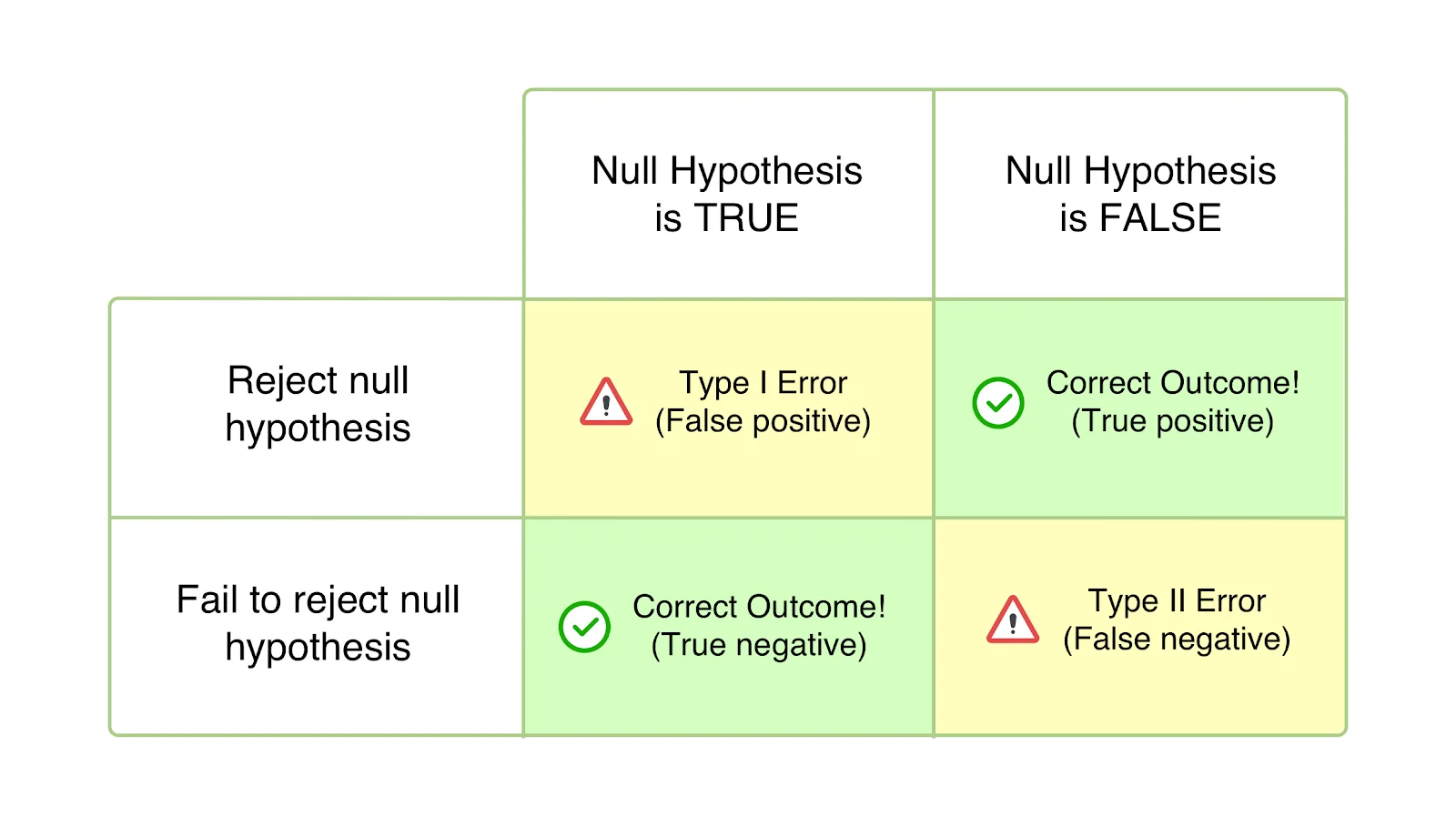
Fehler vom Typ I
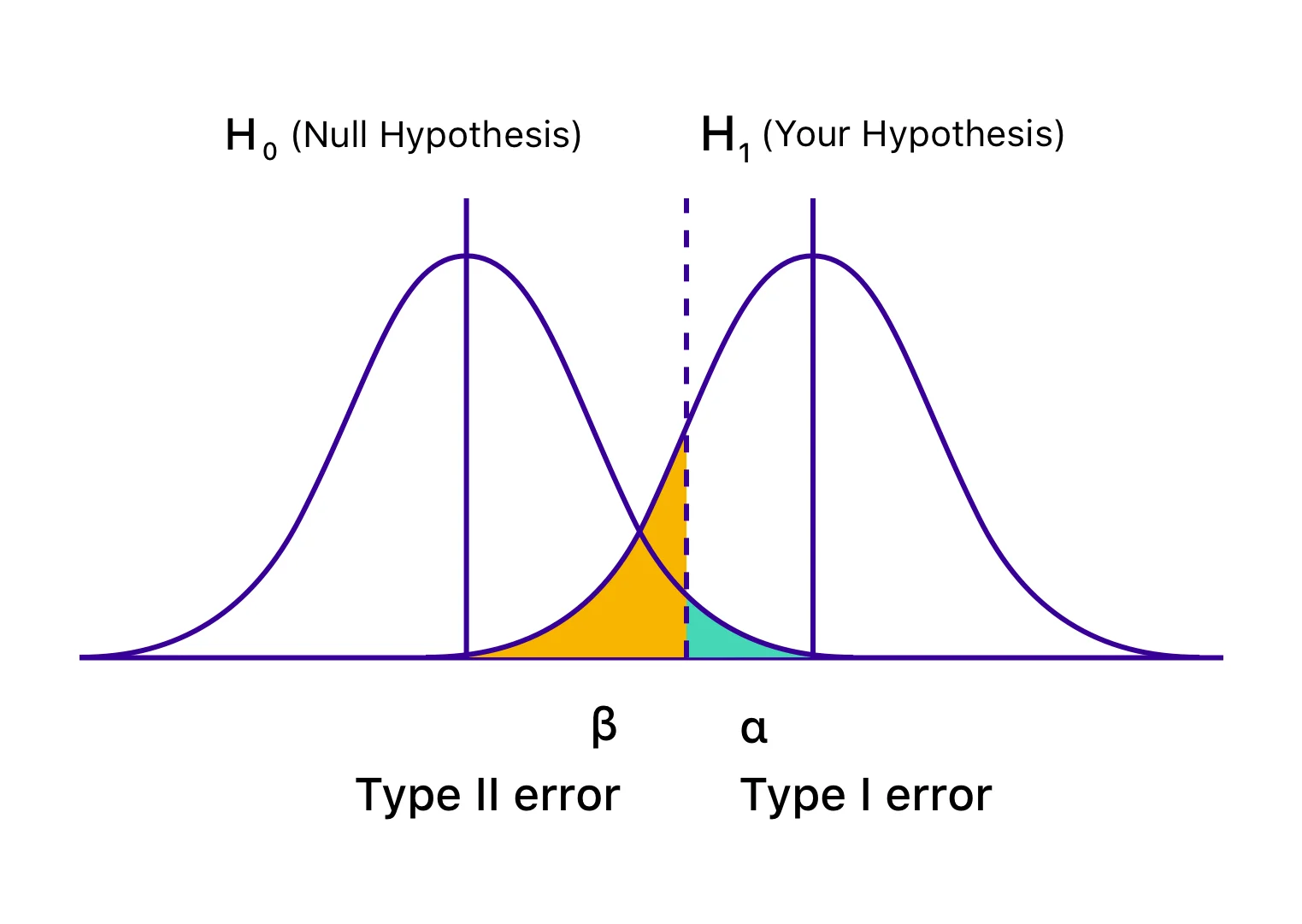
Auch als Alpha (α)-Fehler oder Fehlalarme bekannt, scheint Ihr Test im Falle eines Typ-I-Fehlers erfolgreich zu sein, und Ihre Abweichung scheint sich (besser oder schlechter) auf die für den Test definierten Ziele auszuwirken. Allerdings ist der Anstieg oder Rückgang tatsächlich nur vorübergehend und wird nicht von Dauer sein, wenn Sie die Gewinnerversion universell einsetzen und ihre Auswirkungen über einen längeren Zeitraum messen. Es passiert, wenn Sie Ihren Test abschließen, bevor Sie die statistische Signifikanz oder die vorher festgelegten Kriterien erreicht haben, und Ihre Nullhypothese übereilt ablehnen und die Gewinnervariante akzeptieren. Die Nullhypothese besagt, dass die besagte Änderung keinen Einfluss auf die gegebene Metrik/das gegebene Ziel haben wird. Und im Fall von Fehlern 1. Art ist die Nullhypothese wahr, wird aber aufgrund des vorzeitigen Abschlusses von Tests oder einer falschen Berechnung der Kriterien für die Schlussfolgerung zurückgewiesen.
Die Wahrscheinlichkeit, einen Fehler erster Art zu machen, wird mit „α“ bezeichnet und korreliert mit dem Konfidenzniveau, bei dem Sie sich entscheiden, Ihren Test abzuschließen. Das heißt, wenn Sie Ihren Test mit einem Konfidenzniveau von 95 % abschließen, akzeptieren Sie, dass mit einer Wahrscheinlichkeit von 5 % ein falsches Ergebnis erzielt wird. Wenn dieses Konfidenzniveau 99 % beträgt, beträgt die Wahrscheinlichkeit, dass das Testergebnis falsch ist, 1 %. Man könnte es reines Pech nennen, aber wenn Sie selbst nach Abschluss Ihres Tests mit einem Konfidenzniveau von 95 % auf einen α-Fehler stoßen, bedeutet dies, dass ein Ereignis mit einer Wahrscheinlichkeit von nur 5 % eingetreten ist.
Nehmen wir an, Sie stellen eine Hypothese auf, dass die Verschiebung Ihres CTA auf der Zielseite auf „above the fold“ zu einer Erhöhung der Anzahl der Anmeldungen führt. Die Nullhypothese lautet hier, dass eine Änderung der Platzierung des CTA keinen Einfluss auf die Anzahl der eingegangenen Anmeldungen hätte. Sobald der Test beginnt, sind Sie versucht, einen Blick auf die Ergebnisse zu werfen und einen satten Anstieg der Anmeldungen um 45 % zu bemerken, der durch die Variation innerhalb einer Woche generiert wurde. Sie sind überzeugt, dass der Kontrast deutlich besser ist und schließen den Test ab, verwerfen die Nullhypothese und setzen die Variante universell ein – nur um festzustellen, dass sie nicht mehr ähnlich, sondern gar nicht mehr wirkt. Die einzige Erklärung ist, dass Ihr Testergebnisbericht durch den Typ-I-Fehler verzerrt wurde.
Wie man Fehler 1. Art vermeidet
Obwohl Sie die Möglichkeit, auf einen Fehler 1. Art zu stoßen, nicht vollständig ausschließen können, können Sie ihn sicherlich reduzieren. Stellen Sie daher sicher, dass Sie Ihre Tests erst abschließen, wenn sie ein ausreichend hohes Konfidenzniveau erreicht haben. Ein Konfidenzniveau von 95 % gilt als ideal, und das müssen Sie anstreben. Selbst nach Erreichen eines Konfidenzniveaus von 95 % können Ihre Testergebnisse durch den Fehler 1. Art (wie oben beschrieben) verändert werden. Daher müssen Sie auch sicherstellen, dass Sie Ihre Tests lange genug durchführen, um sicherzustellen, dass eine gute Stichprobengröße getestet wurde, wodurch die Glaubwürdigkeit Ihrer Testergebnisse erhöht wird.
Sie können den A/B-Testdauer-Rechner von VWO verwenden, um den idealen Zeitraum zu ermitteln, für den Sie einen bestimmten Test durchführen müssen. In ähnlicher Weise können Sie auch die Stichprobengröße Ihrer A/B-Tests berechnen, um sicherzustellen, dass Sie Tests nur dann abschließen, wenn Sie die geringste Chance haben, mit verfälschten Ergebnissen zu enden.
SmartStats, die auf Bayes'schen Modellen basierende Statistik-Engine von VWO, hilft Ihnen, die Wahrscheinlichkeit zu verringern, dass ein Typ-1-Fehler auftritt.
Fehler vom Typ II
Auch als Beta (β)-Fehler oder falsch negative Ergebnisse bekannt, scheint im Fall von Typ-II-Fehlern ein bestimmter Test nicht schlüssig oder erfolglos zu sein, wobei die Nullhypothese wahr zu sein scheint. In Wirklichkeit wirkt sich die Variation auf das gewünschte Ziel aus, aber die Ergebnisse zeigen sich nicht, und die Beweise sprechen für die Nullhypothese. Sie akzeptieren daher (fälschlicherweise) die Nullhypothese und lehnen Ihre Hypothese und Variation ab.
Fehler vom Typ II führen in der Regel zum Abbruch und zur Entmutigung von Tests, aber im schlimmsten Fall zu einem Mangel an Motivation, die CRO-Roadmap weiterzuverfolgen, da man dazu neigt, die Bemühungen zu missachten, weil man davon ausgeht, dass sie keine Auswirkungen haben.
'β' bezeichnet die Wahrscheinlichkeit, einen Fehler 2. Art zu machen. Die Wahrscheinlichkeit, keinen Typ-II-Fehler zu erleiden, wird mit 1 – β angegeben, abhängig von der statistischen Aussagekraft des Tests. Je höher die statistische Aussagekraft Ihres Tests ist, desto geringer ist die Wahrscheinlichkeit, dass ein Fehler 2. Art auftritt. Wenn Sie einen Test mit 90 % statistischer Aussagekraft durchführen, besteht nur eine Wahrscheinlichkeit von 10 %, dass Sie am Ende ein falsch negatives Ergebnis erhalten.

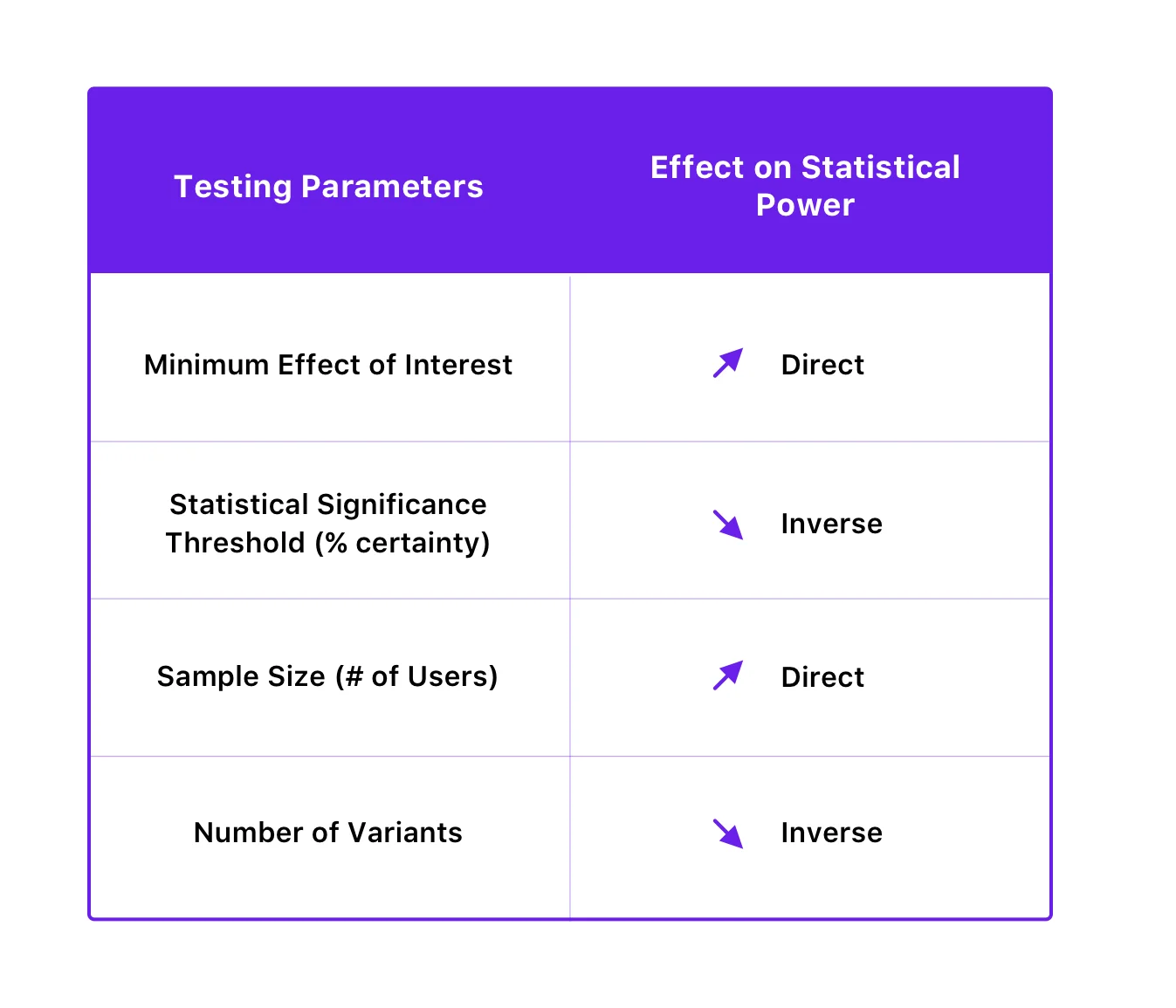
Die statistische Aussagekraft eines Tests hängt von der statistischen Signifikanzschwelle, der Stichprobengröße, der interessierenden Mindesteffektgröße und sogar von der Anzahl der Variationen des Tests ab.
So sind sie verwandt:
Nehmen wir an, Sie gehen davon aus, dass das Hinzufügen von Sicherheitskennzeichen auf Ihrer Zahlungsseite Ihnen helfen würde, den Prozentsatz der Abbrüche in diesem Stadium zu verringern. Sie erstellen eine Variante der Zahlungsseite mit den Sicherheitskennzeichen und führen Ihren Test durch, nur um 10 Tage nach dem Start einen Blick auf die Ergebnisse zu werfen. Wenn Sie keine Änderung in der Anzahl der Conversions oder Drop-offs feststellen, entscheiden Sie sich, den Test abzuschließen und die Nullhypothese für wahr zu erklären. Von den Testergebnissen nicht überzeugt, beschließen Sie, den Test erneut durchzuführen – nur lassen Sie ihn dieses Mal länger laufen. Folglich stellen Sie dieses Mal eine deutliche Verbesserung Ihres Conversion-Ziels fest. Was beim ersten Mal passiert ist, war, dass Sie auf den Typ-II-Fehler gestoßen sind, indem Sie den Test vor der erforderlichen Zeit abgeschlossen haben.
Wie man Fehler 2. Art vermeidet
Indem Sie die statistische Aussagekraft Ihrer Tests verbessern, können Sie Typ-II-Fehler vermeiden. Sie können dies tun, indem Sie Ihre Stichprobengröße erhöhen und die Anzahl der Varianten verringern. Interessanterweise kann eine Verbesserung der statistischen Aussagekraft zur Verringerung der Wahrscheinlichkeit von Fehlern 2. Art auch durch eine Verringerung der statistischen Signifikanzschwelle erreicht werden, aber es erhöht wiederum die Wahrscheinlichkeit von Fehlern 1. Art. Da jedoch die Verringerung der Wahrscheinlichkeit von Fehlern 1. Art normalerweise Vorrang vor der Vermeidung von Fehlern 2. Art hat (da deren Folgen schwerwiegender sein können), ist es ratsam, die statistische Signifikanzschwelle nicht zu beeinträchtigen, um die Trennschärfe zu verbessern.
VWO SmartStats – der intelligentere Bayes'sche Weg zur Geschäftsentscheidung
Im Idealfall sollten Sie sich als Testbesitzer nicht auf Statistiken konzentrieren, da es nicht Ihr Bestreben ist, mit Ihren Experimenten die Wahrheit zu finden – Ihr Motiv ist es, eine bessere Geschäftsentscheidung zu treffen, die Ihnen höhere Einnahmen bringt. Daher ist es wichtig, mit einem Tool zu arbeiten, das Ihnen hilft, eine bessere und klügere Wahl zu treffen – ohne dass Sie sich in die Details von Statistiken einarbeiten müssen.
Nach dem Frequentistischen Modell der Inferenzstatistik hängt der Abschluss eines Tests vollständig davon ab, ob eine statistische Signifikanz erreicht wird. Wenn Sie einen Test beenden, bevor er die statistische Signifikanz erreicht, erhalten Sie wahrscheinlich ein falsch positives Ergebnis (Fehler 1. Art).
Die auf Bayes'schen Modellen basierende Statistik-Engine von VWO, SmartStats, berechnet die Wahrscheinlichkeit, dass diese Variation die Kontrolle übertrifft, sowie den potenziellen Verlust, der Ihnen bei der Bereitstellung entstehen könnte. VWO zeigt Ihnen den möglichen Verlust, der mit dem Einsatz der Variante verbunden ist, damit Sie eine fundierte Entscheidung treffen können.
Dieser potenzielle Verlust hilft auch bei der Entscheidung, wann ein bestimmter Test abgeschlossen werden soll. Nach Abschluss des Tests wird die Variante nur dann zum Sieger erklärt, wenn der potenzielle Verlust der Variante unter einer bestimmten Schwelle liegt. Dieser Schwellenwert wird unter Berücksichtigung der Konversionsrate der Kontrollversion, der Anzahl der Besucher, die Teil des Tests waren, und eines konstanten Werts ermittelt.
VWO SmartStats reduziert nicht nur Ihre Testzeit um 50 % – da Sie sich nicht auf das Erreichen einer festgelegten Zeit und Stichprobengröße verlassen müssen, um Ihren Test abzuschließen – sondern gibt Ihnen auch mehr Kontrolle über Ihre Experimente. Es gibt Ihnen eine klare Wahrscheinlichkeit, die Ihnen hilft, Entscheidungen basierend auf der Art des Tests, den Sie durchführen, zu treffen. Wenn Sie beispielsweise eine Änderung mit geringen Auswirkungen testen, z. B. das Ändern der Schaltflächenfarbe, reicht eine Wahrscheinlichkeit von 90 % möglicherweise aus, um eine Variante als Gewinner zu bezeichnen. Oder, wenn Sie etwas im letzten Schritt des Trichters testen, möchten Sie vielleicht bis zu einer Wahrscheinlichkeit von 99 % warten. Sie sind dann in der Lage, Ihre Testgeschwindigkeit zu erhöhen, indem Sie Tests mit geringer Auswirkung schneller abschließen und Tests mit hoher Auswirkung in Ihrer Roadmap priorisieren.
Ein auf Frequentisten basierendes Statistikmodell gibt Ihnen nur die Wahrscheinlichkeit, einen Unterschied in den Variationen zu sehen, wenn Sie davon ausgehen, dass es sich um einen A/A-Test handelt. Bei diesem Ansatz wird jedoch davon ausgegangen, dass Sie die Testberechnung erst durchführen, nachdem Sie eine ausreichende Stichprobengröße erhalten haben. VWO SmartStats macht keine Annahmen, sondern ermöglicht es Ihnen, klügere Geschäftsentscheidungen zu treffen, indem es die Wahrscheinlichkeit verringert, auf Fehler vom Typ I und Typ II zu stoßen. Dies liegt daran, dass die Wahrscheinlichkeit, um wie viel die Variation die Kontrolle übertrifft, zusammen mit dem damit verbundenen potenziellen Verlust geschätzt wird, sodass Sie diese Metriken kontinuierlich überwachen können, während der Test ausgeführt wird.
Da das Streben nach absoluter Sicherheit bei Statistiken äußerst schwierig ist, können Sie nicht ausschließen, dass Ihre Testergebnisse nicht durch einen Fehler verzerrt sind. Wenn Sie sich jedoch für ein robustes Tool wie VWO entscheiden, können Sie Ihre Fehlerwahrscheinlichkeit verringern oder das mit diesen Fehlern verbundene Risiko auf ein akzeptables Maß reduzieren. Um mehr darüber zu erfahren, wie genau VWO Sie vor solchen Fehlern bewahren kann, probieren Sie die kostenlose Testversion von VWO aus oder fordern Sie eine Demo von einem unserer Optimierungsexperten an.
