
Kesalahan Tipe I Dan Tipe II Dalam Pengujian A/B Dan Cara Menghindarinya
Diterbitkan: 2020-12-04Pengujian A/B melibatkan pemisahan lalu lintas masuk secara acak di situs web Anda di antara beberapa variasi laman web tertentu untuk mengukur mana yang berdampak positif pada metrik penting Anda. Cukup langsung, bukan? Yah, tidak begitu banyak. Meskipun pengujian A/B mungkin terdengar sederhana, sains dan matematika di balik operasinya dan penghitungan hasilnya bisa menjadi sangat rumit.
Statistik adalah landasan pengujian A/B, dan menghitung probabilitas adalah dasar statistik. Oleh karena itu, Anda tidak akan pernah bisa 100% yakin akan keakuratan hasil yang Anda terima atau mengurangi risiko hingga 0%. Sebaliknya, Anda hanya dapat meningkatkan kemungkinan hasil tes menjadi benar. Tetapi sebagai pemilik pengujian, Anda tidak perlu repot tentang hal ini karena alat Anda harus menanganinya.
Bahkan setelah mengikuti semua langkah penting, laporan hasil pengujian Anda mungkin diselewengkan oleh kesalahan yang tanpa disadari menyusup ke dalam proses. Dikenal sebagai kesalahan Tipe I dan Tipe II, ini pada dasarnya mengarah pada kesimpulan tes yang salah dan/atau pernyataan pemenang dan pecundang yang salah. Hal ini menyebabkan salah tafsir laporan hasil pengujian, yang pada akhirnya menyesatkan seluruh program pengoptimalan Anda dan dapat membebani Anda dengan konversi dan bahkan pendapatan.

Mari kita lihat lebih dekat apa sebenarnya yang kami maksud dengan kesalahan Tipe I dan Tipe II, konsekuensinya, dan bagaimana Anda dapat menghindarinya.
Apa sajakah kesalahan yang menyusup ke dalam hasil pengujian A/B Anda?
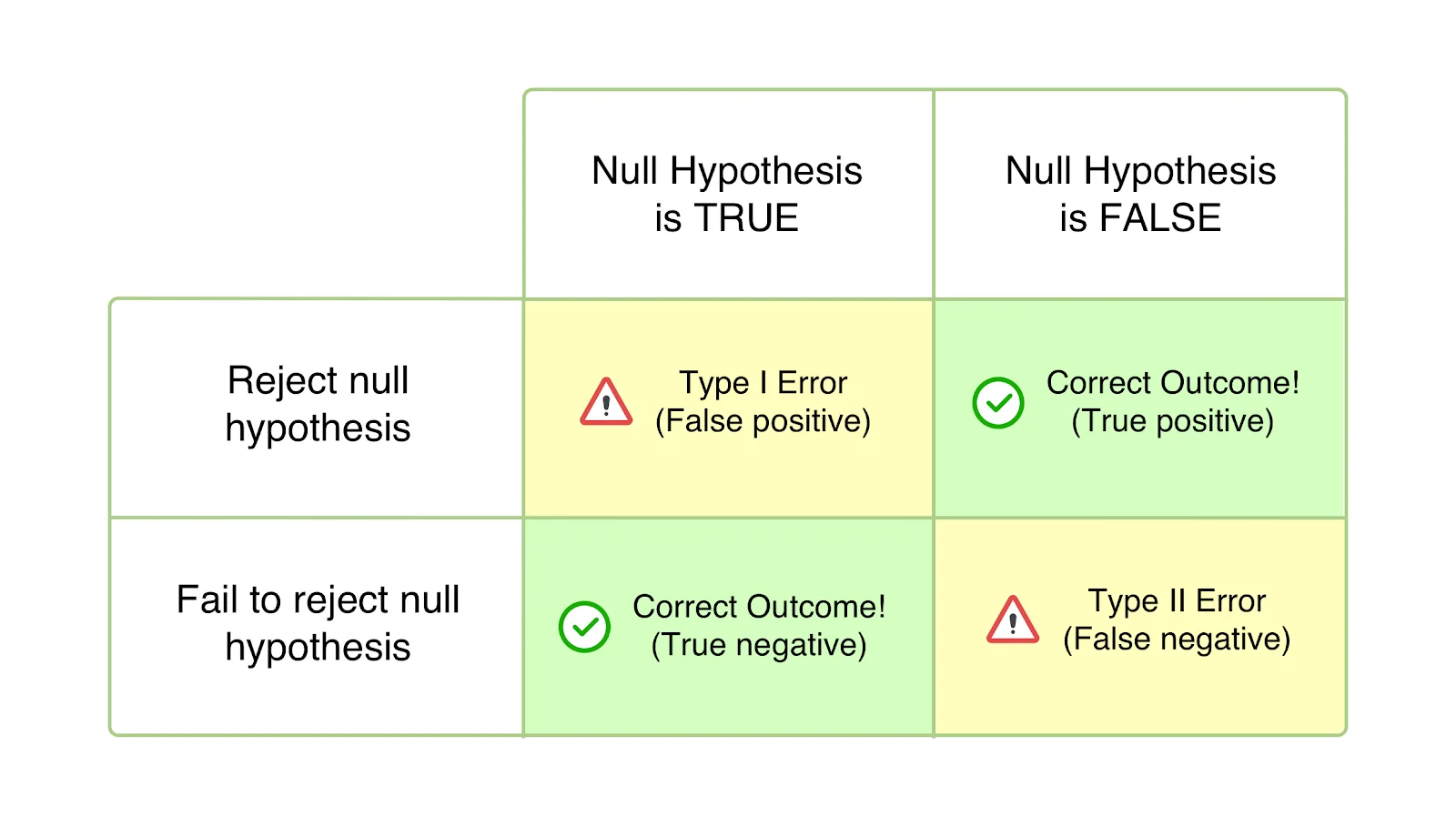
Kesalahan tipe I
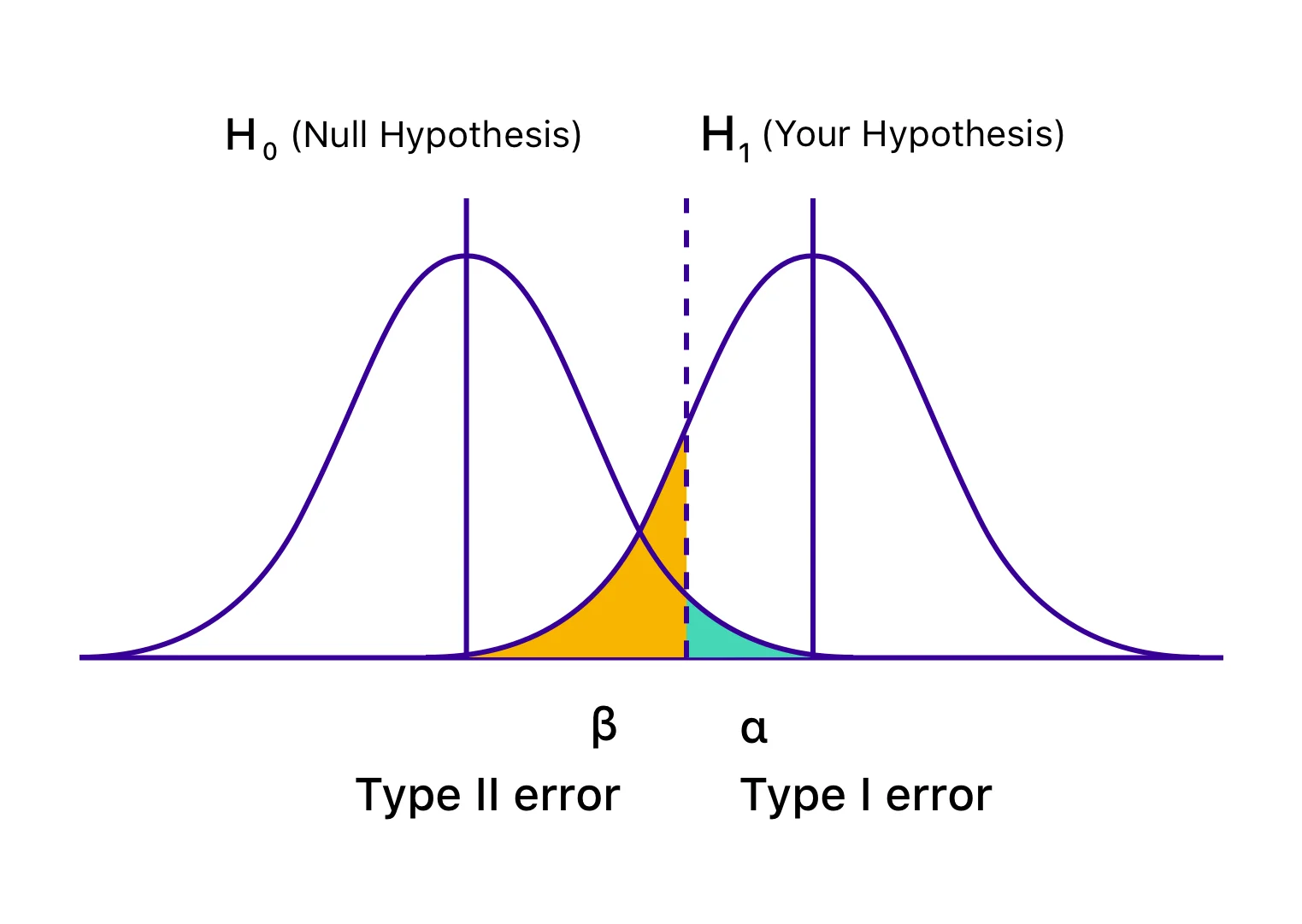
Juga dikenal sebagai kesalahan Alfa (α) atau positif palsu, dalam kasus kesalahan Tipe I, pengujian Anda tampaknya berhasil, dan variasi Anda tampaknya menyebabkan dampak (lebih baik atau lebih buruk) pada tujuan yang ditentukan untuk pengujian. Namun, peningkatan atau penurunan tersebut, pada kenyataannya, hanya sementara dan tidak akan bertahan lama setelah Anda menerapkan versi pemenang secara universal dan mengukur dampaknya selama periode yang signifikan. Itu terjadi ketika Anda menyimpulkan tes Anda sebelum mencapai signifikansi statistik atau kriteria yang telah ditentukan sebelumnya dan terburu-buru menolak hipotesis nol Anda dan menerima variasi pemenang. Hipotesis nol menyatakan bahwa perubahan tersebut tidak akan berdampak pada metrik/sasaran yang diberikan. Dan dalam kasus kesalahan Tipe I, hipotesis nol benar tetapi ditolak karena kesimpulan pengujian yang terlalu dini atau salah perhitungan kriteria kesimpulan.
Probabilitas membuat kesalahan Tipe I dilambangkan dengan 'α' dan berkorelasi dengan tingkat kepercayaan, di mana Anda memutuskan untuk menyimpulkan pengujian Anda. Ini berarti bahwa jika Anda menyimpulkan tes Anda pada tingkat kepercayaan 95%, Anda menerima bahwa ada kemungkinan 5% untuk mendapatkan hasil yang salah. Demikian pula, jika tingkat kepercayaan itu adalah 99%, kemungkinan hasil tes yang salah adalah 1%. Anda dapat menyebutnya sebagai nasib buruk belaka, tetapi jika Anda mengalami kesalahan bahkan setelah menyelesaikan pengujian Anda pada tingkat kepercayaan 95%, itu berarti bahwa suatu peristiwa dengan probabilitas hanya 5% telah terjadi.
Mari kita asumsikan, Anda menyusun hipotesis bahwa menggeser CTA halaman arahan Anda ke paro atas akan menyebabkan peningkatan jumlah pendaftaran. Hipotesis nol di sini adalah bahwa tidak akan ada dampak perubahan penempatan CTA pada jumlah pendaftaran yang diterima. Setelah tes dimulai, Anda tergoda untuk mengintip hasilnya dan melihat peningkatan 45% dalam pendaftaran yang dihasilkan oleh variasi dalam seminggu. Anda yakin bahwa kontrasnya jauh lebih baik dan akhirnya menyimpulkan pengujian, menolak hipotesis nol, dan menerapkan variasi secara universal—hanya untuk menyadari bahwa itu tidak lagi memiliki dampak yang serupa tetapi malah tidak berdampak sama sekali. Satu-satunya penjelasan adalah bahwa laporan hasil pengujian Anda telah dimiringkan oleh kesalahan Tipe I.
Bagaimana menghindari kesalahan tipe I
Meskipun Anda tidak dapat sepenuhnya menghilangkan kemungkinan mengalami kesalahan Tipe I, Anda tentu dapat menguranginya. Untuk itu, pastikan Anda menyimpulkan tes Anda hanya setelah mereka mencapai tingkat kepercayaan yang cukup tinggi. Tingkat kepercayaan 95% dianggap ideal, dan itulah yang harus Anda capai. Bahkan setelah mencapai tingkat kepercayaan 95%, hasil tes Anda mungkin diubah oleh kesalahan Tipe I (seperti yang dibahas di atas). Oleh karena itu, Anda juga perlu memastikan bahwa Anda menjalankan tes Anda cukup lama untuk menjamin bahwa ukuran sampel yang baik telah diuji, sehingga meningkatkan kredibilitas hasil tes Anda.
Anda dapat menggunakan kalkulator durasi pengujian A/B VWO untuk menentukan periode ideal saat Anda harus menjalankan pengujian tertentu. Demikian pula, Anda juga dapat menghitung ukuran sampel pengujian A/B untuk memastikan Anda menyimpulkan pengujian hanya ketika Anda memiliki peluang terendah untuk berakhir dengan hasil yang tidak benar.
Mesin statistik bertenaga model Bayesian VWO, SmartStats, membantu Anda mengurangi kemungkinan menemukan kesalahan Tipe 1.
Kesalahan tipe II
Juga dikenal sebagai kesalahan Beta (β) atau negatif palsu, dalam kasus kesalahan Tipe II, tes tertentu tampaknya tidak meyakinkan atau tidak berhasil, dengan hipotesis nol tampak benar. Pada kenyataannya, variasi tersebut berdampak pada tujuan yang diinginkan, tetapi hasilnya gagal ditampilkan, dan bukti mendukung hipotesis nol. Oleh karena itu, Anda akhirnya (secara salah) menerima hipotesis nol dan menolak hipotesis dan variasi Anda.
Kesalahan tipe II biasanya menyebabkan pengabaian dan keputusasaan tes tetapi, dalam kasus terburuk, kurangnya motivasi untuk mengejar peta jalan CRO karena seseorang cenderung mengabaikan upaya, dengan asumsi itu tidak berdampak.
'β' menunjukkan kemungkinan membuat kesalahan Tipe II. Probabilitas tidak mengalami kesalahan Tipe II dilambangkan dengan 1 – , bergantung pada kekuatan statistik pengujian. Semakin tinggi kekuatan statistik pengujian Anda, semakin rendah kemungkinan menemukan kesalahan Tipe II. Jika Anda menjalankan tes dengan kekuatan statistik 90%, hanya ada kemungkinan 10% bahwa Anda akan mendapatkan hasil negatif palsu.

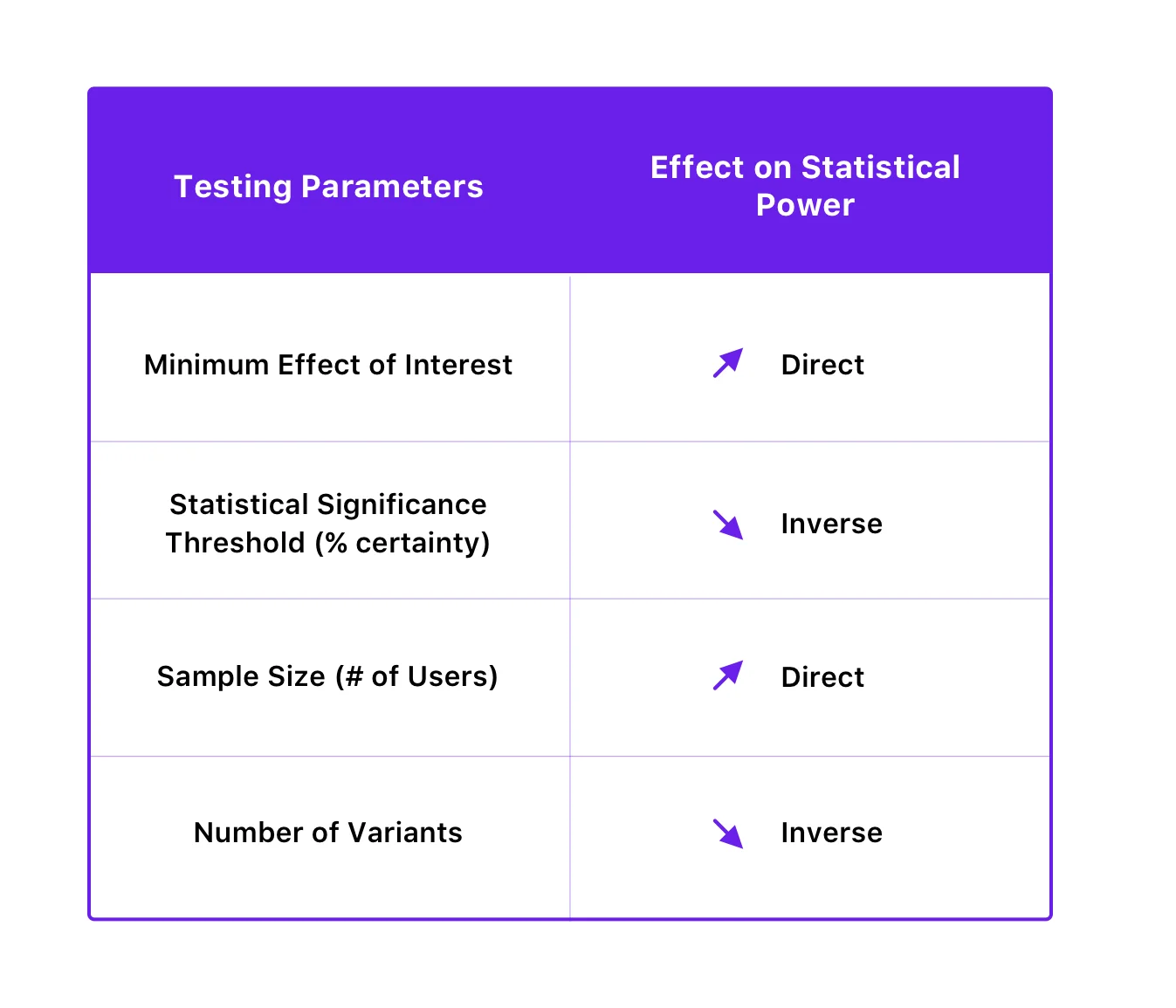
Kekuatan statistik suatu tes bergantung pada ambang signifikansi statistik, ukuran sampel, ukuran efek minimum yang diinginkan, dan bahkan jumlah variasi tes.
Inilah cara mereka terkait:
Mari kita asumsikan bahwa Anda berhipotesis bahwa menambahkan lencana keamanan pada halaman pembayaran Anda akan membantu Anda mengurangi persentase drop-off pada tahap itu. Anda membuat variasi halaman pembayaran dengan lencana keamanan dan menjalankan pengujian Anda, hanya untuk mengintip hasilnya 10 hari setelah dimulainya. Setelah melihat tidak ada perubahan dalam jumlah konversi atau drop-off, Anda memutuskan untuk mengakhiri pengujian dan menyatakan hipotesis nol sebagai benar. Tidak yakin dengan hasil pengujian, Anda memutuskan untuk menjalankan ulang pengujian—hanya kali ini Anda membiarkannya berjalan lebih lama. Akibatnya, Anda melihat peningkatan yang signifikan dalam sasaran konversi Anda kali ini. Apa yang terjadi pertama kali adalah Anda mengalami kesalahan Tipe II dengan menyelesaikan tes sebelum waktu yang diperlukan.
Bagaimana menghindari kesalahan tipe II
Dengan meningkatkan kekuatan statistik pengujian Anda, Anda dapat menghindari kesalahan Tipe II. Anda dapat melakukan ini dengan meningkatkan ukuran sampel dan mengurangi jumlah varian. Menariknya, meningkatkan kekuatan statistik untuk mengurangi kemungkinan kesalahan Tipe II juga dapat dicapai dengan mengurangi ambang signifikansi statistik, tetapi, pada gilirannya, meningkatkan kemungkinan kesalahan Tipe I. Namun, karena mengurangi kemungkinan kesalahan Tipe I biasanya lebih diutamakan daripada menghindari kesalahan Tipe II (karena konsekuensinya bisa lebih parah), disarankan untuk tidak mengganggu ambang batas signifikansi statistik demi meningkatkan daya.
VWO SmartStats – cara Bayesian yang lebih cerdas untuk pengambilan keputusan bisnis
Idealnya, sebagai pemilik tes, statistik bukanlah sesuatu yang harus Anda fokuskan karena pencarian Anda bukanlah untuk menemukan kebenaran dengan eksperimen Anda—motif Anda adalah membuat keputusan bisnis yang lebih baik yang menghasilkan pendapatan lebih tinggi untuk Anda. Jadi, yang penting adalah bekerja dengan alat yang membantu Anda membuat pilihan yang lebih baik dan lebih cerdas—tanpa harus masuk ke detail statistik.
Sesuai dengan model statistik inferensial Frequentist, kesimpulan tes sepenuhnya bergantung pada pencapaian signifikansi statistik. Jika Anda mengakhiri tes sebelum mencapai signifikansi statistik, kemungkinan besar Anda akan mendapatkan hasil positif palsu (kesalahan Tipe I).
Mesin statistik bertenaga model Bayesian VWO, SmartStats, menghitung probabilitas bahwa variasi ini akan mengalahkan kontrol serta potensi kerugian yang mungkin Anda timbulkan saat menerapkannya. VWO menunjukkan kepada Anda kemungkinan kerugian yang terkait dengan penerapan variasi sehingga Anda dapat membuat pilihan yang tepat.
Potensi kerugian ini juga membantu untuk memutuskan kapan harus menyimpulkan tes tertentu. Setelah pengujian selesai, variasi dinyatakan sebagai pemenang hanya jika potensi kerugian dari variasi tersebut di bawah ambang batas tertentu. Ambang ini ditentukan dengan mempertimbangkan tingkat konversi versi kontrol, jumlah pengunjung yang menjadi bagian dari pengujian, dan nilai konstan.
VWO SmartStats tidak hanya mengurangi waktu pengujian Anda hingga 50%—karena Anda tidak bergantung pada pencapaian waktu dan ukuran sampel yang ditentukan untuk menyelesaikan pengujian Anda—tetapi, juga memberi Anda kontrol lebih besar atas eksperimen Anda. Ini memberi Anda probabilitas yang jelas yang membantu Anda membuat keputusan berdasarkan jenis tes yang Anda jalankan. Misalnya, jika Anda menguji perubahan berdampak rendah seperti mengubah warna tombol, mungkin probabilitas 90% cukup baik untuk menyebut variasi sebagai pemenang. Atau, jika Anda menguji sesuatu pada langkah terakhir corong, Anda mungkin ingin menunggu hingga probabilitas 99%. Dengan demikian, Anda berada dalam posisi untuk meningkatkan kecepatan pengujian dengan menyelesaikan pengujian berdampak rendah lebih cepat dan memprioritaskan pengujian berdampak tinggi dalam peta jalan Anda.
Model statistik berbasis Frequentist hanya akan memberi Anda kemungkinan melihat perbedaan variasi dengan mengasumsikan bahwa itu adalah tes A/A. Pendekatan ini, bagaimanapun, mengasumsikan bahwa Anda melakukan perhitungan pengujian hanya setelah Anda memperoleh ukuran sampel yang cukup. VWO SmartStats tidak membuat asumsi apa pun, melainkan memberdayakan Anda untuk membuat keputusan bisnis yang lebih cerdas dengan mengurangi kemungkinan terjadinya kesalahan Tipe I dan Tipe II. Ini karena ini memperkirakan kemungkinan variasi mengalahkan kontrol, dengan seberapa banyak, bersama dengan potensi kerugian terkait, yang memungkinkan Anda untuk terus memantau metrik ini saat pengujian berjalan.
Karena bertujuan untuk kepastian mutlak sangat sulit dengan statistik, Anda tidak dapat menghilangkan kemungkinan hasil tes Anda tidak miring karena kesalahan. Namun, dengan memilih alat yang kuat seperti VWO, Anda dapat menurunkan kemungkinan membuat kesalahan atau mengurangi risiko yang terkait dengan kesalahan ini ke tingkat yang dapat diterima. Untuk memahami lebih lanjut tentang bagaimana tepatnya VWO dapat mencegah Anda menjadi mangsa kesalahan seperti itu, cobalah uji coba gratis VWO atau minta demo oleh salah satu pakar pengoptimalan kami.
