
Tudo o que você precisa saber sobre o cabeçalho HTTP X-Robots-Tag
Publicados: 2022-12-19A otimização do mecanismo de pesquisa, em seu sentido mais básico, depende de uma coisa acima de todas as outras: aranhas do mecanismo de pesquisa rastreando e indexando seu site.
Mas quase todos os sites terão páginas que você não deseja incluir nessa exploração.
Por exemplo, você realmente deseja que sua política de privacidade ou páginas de pesquisa interna apareçam nos resultados do Google?
Na melhor das hipóteses, eles não estão fazendo nada para direcionar o tráfego para seu site ativamente e, na pior das hipóteses, podem estar desviando o tráfego de páginas mais importantes.
Felizmente, o Google permite que os webmasters digam aos bots dos mecanismos de pesquisa quais páginas e conteúdo rastrear e o que ignorar. Existem várias maneiras de fazer isso, sendo a mais comum usar um arquivo robots.txt ou a tag meta robots.
Temos uma explicação excelente e detalhada dos prós e contras do robots.txt, que você definitivamente deveria ler.
Mas, em termos de alto nível, é um arquivo de texto simples que fica na raiz do seu site e segue o Protocolo de Exclusão de Robôs (REP).
Robots.txt fornece aos rastreadores instruções sobre o site como um todo, enquanto meta tags de robôs incluem instruções para páginas específicas.
Algumas tags meta robots que você pode usar incluem index , que informa aos mecanismos de pesquisa para adicionar a página ao índice; noindex , que informa para não adicionar uma página ao índice ou incluí-la nos resultados da pesquisa; follow , que instrui um mecanismo de pesquisa a seguir os links em uma página; nofollow , que diz para não seguir links e uma série de outros.
As tags robots.txt e meta robots são ferramentas úteis para manter em sua caixa de ferramentas, mas também há outra maneira de instruir os bots do mecanismo de pesquisa a noindex ou nofollow: o X-Robots-Tag .
O que é o X-Robots-Tag?
O X-Robots-Tag é outra maneira de você controlar como suas páginas da Web são rastreadas e indexadas por aranhas. Como parte da resposta do cabeçalho HTTP a um URL, ele controla a indexação de uma página inteira, bem como os elementos específicos dessa página.
E enquanto o uso de tags meta robots é bastante simples, o X-Robots-Tag é um pouco mais complicado.
Mas isso, é claro, levanta a questão:
Quando você deve usar o X-Robots-Tag?
De acordo com o Google, “Qualquer diretiva que pode ser usada em uma meta tag de robôs também pode ser especificada como uma X-Robots-Tag”.
Embora você possa definir diretivas relacionadas ao robots.txt nos cabeçalhos de uma resposta HTTP com a tag meta robots e a tag X-Robots, há certas situações em que você gostaria de usar a tag X-Robots - as duas mais comuns sendo quando:
- Você deseja controlar como seus arquivos não HTML estão sendo rastreados e indexados.
- Você deseja servir diretivas em todo o site em vez de no nível da página.
Por exemplo, se você deseja impedir que uma imagem ou vídeo específico seja rastreado, o método de resposta HTTP facilita isso.
O cabeçalho X-Robots-Tag também é útil porque permite combinar várias tags em uma resposta HTTP ou usar uma lista de diretivas separadas por vírgula para especificar diretivas.
Talvez você não queira que uma determinada página seja armazenada em cache e queira que ela fique indisponível após uma determinada data. Você pode usar uma combinação de tags “noarchive” e “unavailable_after” para instruir os bots dos mecanismos de pesquisa a seguir essas instruções.
Essencialmente, o poder do X-Robots-Tag é que ele é muito mais flexível do que o tag meta robots.
A vantagem de usar um X-Robots-Tag com respostas HTTP é que ele permite que você use expressões regulares para executar diretivas de rastreamento em não-HTML, bem como aplicar parâmetros em um nível global maior.
Para ajudá-lo a entender a diferença entre essas diretivas, é útil categorizá-las por tipo. Ou seja, são diretivas de rastreador ou diretivas de indexador?
Aqui está uma folha de dicas útil para explicar:
| Diretivas do rastreador | Diretivas do indexador |
| Robots.txt – usa o agente do usuário, permite, não permite e diretivas de mapa do site para especificar onde os bots do mecanismo de pesquisa no site podem rastrear e onde não podem rastrear. | Tag Meta Robots – permite especificar e impedir que os mecanismos de pesquisa exibam páginas específicas em um site nos resultados da pesquisa. Nofollow – permite especificar links que não devem passar autoridade ou PageRank. X-Robots-tag – permite controlar como os tipos de arquivo especificados são indexados. |
Onde você coloca o X-Robots-Tag?
Digamos que você queira bloquear tipos de arquivo específicos. Uma abordagem ideal seria adicionar o X-Robots-Tag a uma configuração do Apache ou a um arquivo .htaccess.

O X-Robots-Tag pode ser adicionado às respostas HTTP de um site em uma configuração de servidor Apache via arquivo .htaccess.
Exemplos do mundo real e usos do X-Robots-Tag
Isso parece ótimo em teoria, mas como é no mundo real? Vamos dar uma olhada.
Digamos que queremos que os mecanismos de pesquisa não indexem tipos de arquivo .pdf. Essa configuração nos servidores Apache seria algo como abaixo:
<Files ~ "\.pdf$"> Header set X-Robots-Tag "noindex, nofollow" </Files>
No Nginx, ficaria como abaixo:
location ~* \.pdf$ {
add_header X-Robots-Tag "noindex, nofollow";
}Agora, vamos ver um cenário diferente. Digamos que queremos usar o X-Robots-Tag para impedir que arquivos de imagem, como .jpg, .gif, .png, etc., sejam indexados. Você poderia fazer isso com um X-Robots-Tag que se pareceria com o abaixo:
<Arquivos ~ "\.(png|jpe?g|gif)$"> Conjunto de cabeçalho X-Robots-Tag "noindex" </Arquivos>
Observe que entender como essas diretivas funcionam e o impacto que elas têm umas sobre as outras é crucial.
Por exemplo, o que acontece se o X-Robots-Tag e uma tag meta robots forem localizados quando os bots rastreadores descobrirem um URL?
Se esse URL estiver bloqueado no robots.txt, determinadas diretivas de indexação e veiculação não poderão ser descobertas e não serão seguidas.
Se as diretivas devem ser seguidas, os URLs que as contêm não podem ser impedidos de rastrear.
Verifique se há um X-Robots-Tag
Existem alguns métodos diferentes que podem ser usados para verificar se há um X-Robots-Tag no site.
A maneira mais fácil de verificar é instalar uma extensão do navegador que fornecerá informações do X-Robots-Tag sobre o URL.
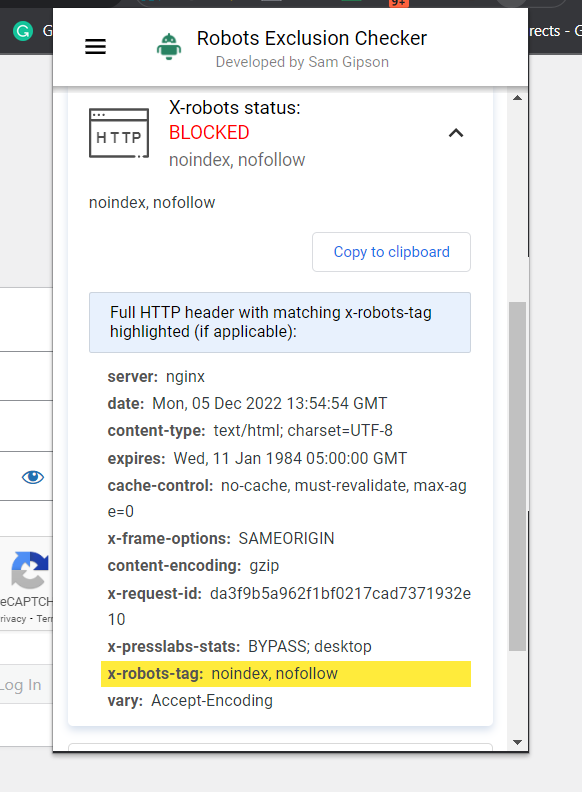 Captura de tela do verificador de exclusão de robôs, dezembro de 2022
Captura de tela do verificador de exclusão de robôs, dezembro de 2022Outro plugin que você pode usar para determinar se um X-Robots-Tag está sendo usado, por exemplo, é o plugin Web Developer.
Ao clicar no plug-in em seu navegador e navegar até “Exibir cabeçalhos de resposta”, você pode ver os vários cabeçalhos HTTP sendo usados.

Outro método que pode ser usado para dimensionar a fim de identificar problemas em sites com um milhão de páginas é o Screaming Frog.
Depois de executar um site por meio do Screaming Frog, você pode navegar até a coluna “X-Robots-Tag”.
Isso mostrará quais seções do site estão usando a tag, junto com quais diretivas específicas.
 Captura de tela do Screaming Frog Report. X-Robot-Tag, dezembro de 2022
Captura de tela do Screaming Frog Report. X-Robot-Tag, dezembro de 2022Usando X-Robots-Tags em seu site
Compreender e controlar como os mecanismos de pesquisa interagem com seu site é a base da otimização de mecanismos de pesquisa. E o X-Robots-Tag é uma ferramenta poderosa que você pode usar para fazer exatamente isso.
Esteja ciente: não é isento de perigos. É muito fácil cometer um erro e desindexar todo o seu site.
Dito isso, se você está lendo este artigo, provavelmente não é um iniciante em SEO. Contanto que você o use com sabedoria, tome seu tempo e verifique seu trabalho, você descobrirá que o X-Robots-Tag é uma adição útil ao seu arsenal.
Mais recursos:
- Google dá aos sites mais controle de indexação com a nova tag Robots
- 6 problemas comuns do Robots.txt e como corrigi-los
- SEO técnico avançado: um guia completo
Imagem em destaque: Song_about_summer/Shutterstock