
关于 X-Robots-Tag HTTP 标头你需要知道的一切
已发表: 2022-12-19搜索引擎优化,从最基本的意义上讲,首先依赖于一件事:搜索引擎蜘蛛爬行并为您的网站编制索引。
但是几乎每个网站都会有一些您不想包含在此探索中的页面。
例如,您真的希望您的隐私政策或内部搜索页面显示在 Google 结果中吗?
在最好的情况下,这些不会主动为您的网站带来流量,而在最坏的情况下,它们可能会从更重要的页面转移流量。
幸运的是,谷歌允许网站管理员告诉搜索引擎机器人要抓取哪些页面和内容以及忽略什么。 有几种方法可以做到这一点,最常见的是使用 robots.txt 文件或 meta robots 标签。
我们对 robots.txt 的来龙去脉有出色而详细的解释,您绝对应该阅读。
但在高级术语中,它是一个纯文本文件,位于您网站的根目录中并遵循机器人排除协议 (REP)。
Robots.txt 为爬虫提供有关整个站点的说明,而元机器人标签包含特定页面的说明。
您可能使用的一些元机器人标签包括index ,它告诉搜索引擎将页面添加到它们的索引中; noindex ,告诉它不要将页面添加到索引或将其包含在搜索结果中; follow ,指示搜索引擎跟踪页面上的链接; nofollow ,告诉它不要跟踪链接,以及其他一大堆。
robots.txt 和元机器人标签都是保存在您的工具箱中的有用工具,但还有另一种方法可以指示搜索引擎机器人使用 noindex 或 nofollow: X-Robots-Tag 。
什么是 X-Robots-Tag?
X-Robots-Tag 是您控制网页如何被蜘蛛抓取和索引的另一种方式。 作为对 URL 的 HTTP 标头响应的一部分,它控制整个页面的索引以及该页面上的特定元素。
虽然使用元机器人标签相当简单,但 X-Robots-Tag 有点复杂。
但这当然提出了一个问题:
什么时候应该使用 X-Robots-Tag?
根据 Google 的说法,“任何可以在机器人元标记中使用的指令也可以指定为 X-Robots-Tag。”
虽然您可以使用 meta robots 标签和 X-Robots 标签在 HTTP 响应的标头中设置与 robots.txt 相关的指令,但在某些情况下您会希望使用 X-Robots-Tag – 两种最常见的当:
- 您想要控制非 HTML 文件的抓取和索引方式。
- 您希望在整个站点范围内而不是在页面级别上提供指令。
例如,如果您想要阻止特定图像或视频被抓取——HTTP 响应方法可以让这变得简单。
X-Robots-Tag 标头也很有用,因为它允许您在 HTTP 响应中组合多个标记或使用逗号分隔的指令列表来指定指令。
也许您不希望缓存某个页面并希望它在某个日期后不可用。 您可以结合使用“noarchive”和“unavailable_after”标签来指示搜索引擎机器人遵循这些说明。
从本质上讲,X-Robots-Tag 的强大之处在于它比元机器人标签灵活得多。
将X-Robots-Tag与 HTTP 响应一起使用的优势在于,它允许您使用正则表达式在非 HTML 上执行爬网指令,以及在更大的全局级别上应用参数。
为了帮助您理解这些指令之间的区别,按类型对它们进行分类会很有帮助。 也就是说,它们是爬虫指令还是索引器指令?
这是一个方便的备忘单来解释:
| 爬虫指令 | 索引器指令 |
| Robots.txt – 使用用户代理、允许、禁止和站点地图指令来指定允许和不允许现场搜索引擎机器人爬行的位置。 | Meta Robots 标签– 允许您指定和阻止搜索引擎在搜索结果中显示站点上的特定页面。 Nofollow – 允许您指定不应传递权限或 PageRank 的链接。 X-Robots-tag – 允许您控制指定文件类型的索引方式。 |
你把 X-Robots-Tag 放在哪里?
假设您要阻止特定的文件类型。 理想的方法是将 X-Robots-Tag 添加到 Apache 配置或 .htaccess 文件中。
X-Robots-Tag 可以通过 .htaccess 文件添加到 Apache 服务器配置中站点的 HTTP 响应。
X-Robots-Tag 的真实示例和使用
所以这在理论上听起来不错,但在现实世界中它是什么样子的呢? 让我们来看看。

假设我们希望搜索引擎不索引 .pdf 文件类型。 Apache 服务器上的此配置如下所示:
<Files ~ "\.pdf$"> Header set X-Robots-Tag "noindex, nofollow" </Files>
在 Nginx 中,它看起来像下面这样:
location ~* \.pdf$ {
add_header X-Robots-Tag "noindex, nofollow";
}现在,让我们看一个不同的场景。 假设我们想使用 X-Robots-Tag 来阻止图像文件(例如 .jpg、.gif、.png 等)被编入索引。 您可以使用如下所示的 X-Robots-Tag 来执行此操作:
<文件 ~ "\.(png|jpe?g|gif)$"> 标头集 X-Robots-Tag“noindex” </文件>
请注意,了解这些指令的工作原理及其相互影响至关重要。
例如,当爬虫机器人发现一个 URL 时,如果同时找到 X-Robots-Tag 和元机器人标签会发生什么?
如果该 URL 被 robots.txt 阻止,则无法发现某些索引和服务指令,也不会遵循这些指令。
如果要遵循指令,则不能禁止抓取包含这些指令的 URL。
检查 X-Robots-Tag
有几种不同的方法可用于检查站点上的 X-Robots-Tag。
最简单的检查方法是安装浏览器扩展程序,它会告诉您有关 URL 的 X-Robots-Tag 信息。
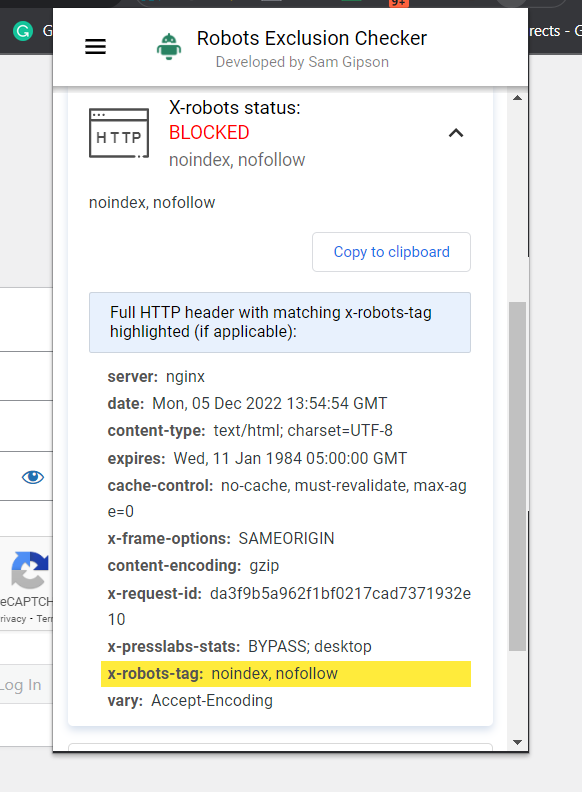 机器人排除检查器的屏幕截图,2022 年 12 月
机器人排除检查器的屏幕截图,2022 年 12 月另一个可用于确定是否正在使用 X-Robots-Tag 的插件是 Web Developer 插件。
通过单击浏览器中的插件并导航到“查看响应标头”,您可以看到正在使用的各种 HTTP 标头。

另一种可用于缩放以查明具有一百万页的网站上的问题的方法是 Screaming Frog。
通过 Screaming Frog 运行站点后,您可以导航到“X-Robots-Tag”列。
这将向您显示网站的哪些部分正在使用该标签,以及哪些特定指令。
 尖叫青蛙报告截图。 X-Robot-Tag,2022 年 12 月
尖叫青蛙报告截图。 X-Robot-Tag,2022 年 12 月在您的网站上使用 X-Robots-Tags
了解和控制搜索引擎如何与您的网站交互是搜索引擎优化的基石。 X-Robots-Tag 是一个强大的工具,您可以使用它来做到这一点。
请注意:这并非没有危险。 很容易犯错并取消整个网站的索引。
也就是说,如果您正在阅读这篇文章,您可能不是 SEO 初学者。 只要您明智地使用它,慢慢来检查您的工作,您就会发现 X-Robots-Tag 是您武器库中的有用补充。
更多资源:
- 谷歌通过新的机器人标签为网站提供更多的索引控制
- 6 个常见的 Robots.txt 问题及解决方法
- 高级技术 SEO:完整指南
特色图片:Song_about_summer/Shutterstock