
Semua yang Perlu Anda Ketahui Tentang Header HTTP X-Robots-Tag
Diterbitkan: 2022-12-19Optimisasi mesin pencari, dalam arti yang paling dasar, bergantung pada satu hal di atas segalanya: Spider mesin pencari merayapi dan mengindeks situs Anda.
Namun hampir setiap situs web akan memiliki halaman yang tidak ingin Anda sertakan dalam eksplorasi ini.
Misalnya, apakah Anda benar-benar ingin kebijakan privasi atau halaman pencarian internal Anda muncul di hasil Google?
Dalam skenario kasus terbaik, ini tidak melakukan apa pun untuk mengarahkan lalu lintas ke situs Anda secara aktif, dan dalam kasus terburuk, mereka dapat mengalihkan lalu lintas dari halaman yang lebih penting.
Untungnya, Google mengizinkan webmaster untuk memberi tahu bot mesin telusur halaman dan konten apa yang harus dirayapi dan apa yang harus diabaikan. Ada beberapa cara untuk melakukannya, yang paling umum menggunakan file robots.txt atau tag meta robots.
Kami memiliki penjelasan yang sangat bagus dan mendetail tentang seluk beluk robots.txt, yang harus Anda baca.
Namun dalam istilah tingkat tinggi, ini adalah file teks biasa yang berada di akar situs web Anda dan mengikuti Robots Exclusion Protocol (REP).
Robots.txt memberikan petunjuk kepada perayap tentang situs secara keseluruhan, sementara tag robot meta menyertakan petunjuk untuk laman tertentu.
Beberapa tag robot meta yang mungkin Anda gunakan termasuk index , yang memberi tahu mesin pencari untuk menambahkan halaman ke indeks mereka; noindex , yang memberitahunya untuk tidak menambahkan halaman ke indeks atau memasukkannya ke dalam hasil pencarian; follow , yang menginstruksikan mesin telusur untuk mengikuti tautan pada laman; nofollow , yang memberitahunya untuk tidak mengikuti tautan, dan banyak lainnya.
Tag robots.txt dan meta robots adalah alat yang berguna untuk disimpan di kotak alat Anda, tetapi ada juga cara lain untuk menginstruksikan bot mesin telusur ke noindex atau nofollow: X-Robots-Tag .
Apa Itu X-Robots-Tag?
X-Robots-Tag adalah cara lain bagi Anda untuk mengontrol bagaimana laman web Anda dirayapi dan diindeks oleh spider. Sebagai bagian dari respons tajuk HTTP ke URL, ini mengontrol pengindeksan untuk seluruh halaman, serta elemen spesifik pada halaman tersebut.
Dan sementara menggunakan tag robot meta cukup mudah, X-Robots-Tag sedikit lebih rumit.
Tapi ini, tentu saja, menimbulkan pertanyaan:
Kapan Anda Harus Menggunakan X-Robots-Tag?
Menurut Google, "Direktif apa pun yang dapat digunakan dalam tag meta robot juga dapat ditentukan sebagai X-Robots-Tag."
Meskipun Anda dapat menyetel arahan terkait robots.txt di header respons HTTP dengan tag meta robots dan Tag X-Robots, ada situasi tertentu di mana Anda ingin menggunakan X-Robots-Tag – dua yang paling umum sedang ketika:
- Anda ingin mengontrol bagaimana file non-HTML Anda dirayapi dan diindeks.
- Anda ingin menyajikan arahan di seluruh situs, bukan di tingkat halaman.
Misalnya, jika Anda ingin memblokir gambar atau video tertentu agar tidak dirayapi – metode tanggapan HTTP membuatnya mudah.
Header X-Robots-Tag juga berguna karena memungkinkan Anda menggabungkan beberapa tag dalam respons HTTP atau menggunakan daftar arahan yang dipisahkan koma untuk menentukan arahan.
Mungkin Anda tidak ingin halaman tertentu di-cache dan ingin halaman tersebut tidak tersedia setelah tanggal tertentu. Anda dapat menggunakan kombinasi tag “noarchive” dan “unavailable_after” untuk memerintahkan bot mesin pencari agar mengikuti petunjuk ini.
Pada dasarnya, kekuatan X-Robots-Tag adalah jauh lebih fleksibel daripada tag robot meta.
Keuntungan menggunakan X-Robots-Tag dengan respons HTTP adalah memungkinkan Anda menggunakan ekspresi reguler untuk mengeksekusi arahan perayapan pada non-HTML, serta menerapkan parameter pada tingkat global yang lebih besar.
Untuk membantu Anda memahami perbedaan antara arahan-arahan ini, ada gunanya mengategorikannya berdasarkan jenis. Yaitu, apakah itu arahan perayap atau arahan pengindeks?
Berikut lembar contekan yang berguna untuk dijelaskan:
| Arahan Perayap | Arahan Pengindeks |
| Robots.txt – menggunakan arahan agen pengguna, izinkan, larang, dan peta situs untuk menentukan di mana bot mesin pencari di situs diizinkan untuk merayapi dan tidak diizinkan untuk merayapi. | Tag Meta Robots – memungkinkan Anda untuk menentukan dan mencegah mesin pencari menampilkan halaman tertentu di situs dalam hasil pencarian. Nofollow – memungkinkan Anda menentukan tautan yang tidak boleh meneruskan otoritas atau PageRank. X-Robots-tag – memungkinkan Anda untuk mengontrol bagaimana jenis file tertentu diindeks. |
Di Mana Anda Menempatkan X-Robots-Tag?
Katakanlah Anda ingin memblokir jenis file tertentu. Pendekatan yang ideal adalah menambahkan X-Robots-Tag ke konfigurasi Apache atau file .htaccess.

X-Robots-Tag dapat ditambahkan ke respons HTTP situs dalam konfigurasi server Apache melalui file .htaccess.
Contoh Dunia Nyata Dan Penggunaan X-Robots-Tag
Kedengarannya bagus secara teori, tapi seperti apa di dunia nyata? Mari lihat.
Katakanlah kita ingin mesin telusur tidak mengindeks jenis file .pdf. Konfigurasi ini pada server Apache akan terlihat seperti di bawah ini:
<Files ~ "\.pdf$"> Header set X-Robots-Tag "noindex, nofollow" </Files>
Di Nginx, akan terlihat seperti di bawah ini:
location ~* \.pdf$ {
add_header X-Robots-Tag "noindex, nofollow";
}Sekarang, mari kita lihat skenario yang berbeda. Katakanlah kita ingin menggunakan X-Robots-Tag untuk memblokir file gambar, seperti .jpg, .gif, .png, dll., agar tidak diindeks. Anda dapat melakukannya dengan X-Robots-Tag yang akan terlihat seperti di bawah ini:
<Berkas ~ "\.(png|jpe?g|gif)$"> Set tajuk X-Robots-Tag "noindex" </File>
Harap perhatikan bahwa memahami cara kerja arahan ini dan dampaknya terhadap satu sama lain sangatlah penting.
Misalnya, apa yang terjadi jika tag X-Robots-Tag dan tag meta robots ditemukan saat bot perayap menemukan URL?
Jika URL tersebut diblokir dari robots.txt, arahan pengindeksan dan penayangan tertentu tidak dapat ditemukan dan tidak akan diikuti.
Jika arahan harus diikuti, maka URL yang berisi arahan tersebut tidak dapat dilarang untuk dirayapi.
Periksa Untuk X-Robots-Tag
Ada beberapa metode berbeda yang dapat digunakan untuk memeriksa X-Robots-Tag di situs.
Cara termudah untuk memeriksa adalah memasang ekstensi browser yang akan memberi tahu Anda informasi X-Robots-Tag tentang URL.
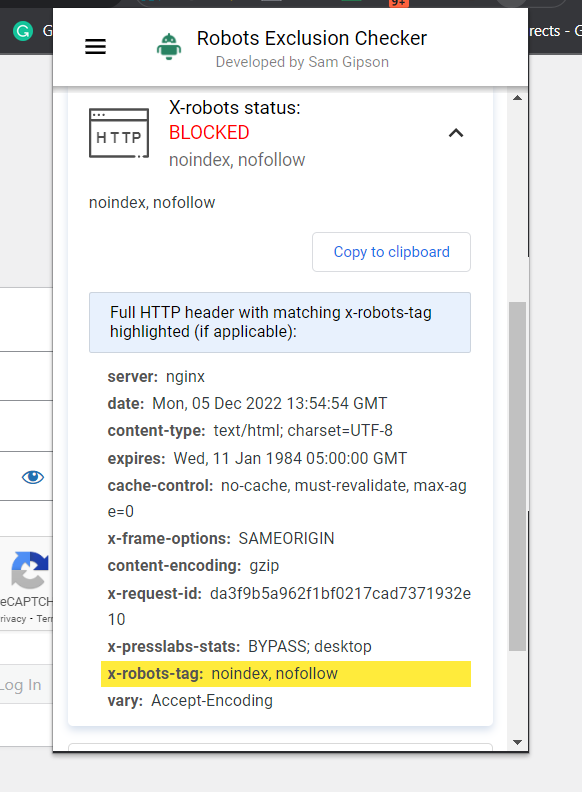 Cuplikan layar Pemeriksa Pengecualian Robot, Desember 2022
Cuplikan layar Pemeriksa Pengecualian Robot, Desember 2022Plugin lain yang dapat Anda gunakan untuk menentukan apakah X-Robots-Tag sedang digunakan, misalnya, adalah plugin Web Developer.
Dengan mengklik plugin di browser Anda dan menavigasi ke "Lihat Header Respons", Anda dapat melihat berbagai header HTTP yang digunakan.

Metode lain yang dapat digunakan untuk penskalaan untuk menunjukkan masalah pada situs web dengan sejuta halaman adalah Screaming Frog.
Setelah menjalankan situs melalui Screaming Frog, Anda dapat menavigasi ke kolom "X-Robots-Tag".
Ini akan menunjukkan kepada Anda bagian situs mana yang menggunakan tag, bersama dengan arahan khusus mana.
 Tangkapan layar Laporan Katak Menjerit. X-Robot-Tag, Desember 2022
Tangkapan layar Laporan Katak Menjerit. X-Robot-Tag, Desember 2022Menggunakan X-Robots-Tag Di Situs Anda
Memahami dan mengontrol bagaimana mesin telusur berinteraksi dengan situs web Anda adalah landasan pengoptimalan mesin telusur. Dan X-Robots-Tag adalah alat canggih yang dapat Anda gunakan untuk melakukan hal itu.
Sadarilah: Ini bukan tanpa bahayanya. Sangat mudah untuk membuat kesalahan dan mendeindeks seluruh situs Anda.
Yang mengatakan, jika Anda membaca artikel ini, Anda mungkin bukan seorang pemula SEO. Selama Anda menggunakannya dengan bijak, luangkan waktu Anda dan periksa pekerjaan Anda, Anda akan menemukan X-Robots-Tag sebagai tambahan yang berguna untuk gudang senjata Anda.
Sumber Daya Lainnya:
- Google Memberikan Situs Lebih Banyak Kontrol Pengindeksan Dengan Tag Robot Baru
- 6 Masalah Umum Robots.txt & Dan Cara Memperbaikinya
- SEO Teknis Tingkat Lanjut: Panduan Lengkap
Gambar Unggulan: Song_about_summer/Shutterstock