
Wszystko, co musisz wiedzieć o nagłówku HTTP X-Robots-Tag
Opublikowany: 2022-12-19Optymalizacja wyszukiwarek, w najbardziej podstawowym znaczeniu, opiera się przede wszystkim na jednej rzeczy: robotach wyszukiwarek przeszukujących i indeksujących Twoją witrynę.
Ale prawie każda witryna będzie zawierać strony, których nie chcesz uwzględniać w tej eksploracji.
Na przykład, czy naprawdę chcesz, aby Twoja polityka prywatności lub wewnętrzne strony wyszukiwania pojawiały się w wynikach Google?
W najlepszym przypadku nie przyczyniają się one do aktywnego kierowania ruchu do Twojej witryny, aw najgorszym przypadku mogą przekierowywać ruch z ważniejszych stron.
Na szczęście Google pozwala webmasterom informować roboty wyszukiwarek, które strony i treści mają indeksować, a które ignorować. Można to zrobić na kilka sposobów, z których najczęstszym jest użycie pliku robots.txt lub metatagu robots.
Mamy doskonałe i szczegółowe wyjaśnienie tajników pliku robots.txt, które zdecydowanie powinieneś przeczytać.
Ale mówiąc ogólnie, jest to zwykły plik tekstowy, który znajduje się w katalogu głównym Twojej witryny i jest zgodny z protokołem Robots Exclusion Protocol (REP).
Plik robots.txt dostarcza robotom indeksującym instrukcje dotyczące całej witryny, podczas gdy meta tagi robots zawierają wskazówki dotyczące konkretnych stron.
Niektóre metatagi robotów, które możesz zastosować, obejmują index , który mówi wyszukiwarkom, aby dodały stronę do swojego indeksu; noindex , który mówi mu, aby nie dodawać strony do indeksu ani nie umieszczać jej w wynikach wyszukiwania; follow , który instruuje wyszukiwarkę, aby podążała za linkami na stronie; nofollow , który mówi mu, aby nie podążał za linkami i całą gamą innych.
Zarówno plik robots.txt, jak i meta tagi robots są przydatnymi narzędziami, które warto mieć w swoim zestawie narzędzi, ale jest też inny sposób nakazania robotom wyszukiwarek noindex lub nofollow: X-Robots-Tag .
Co to jest tag X-Robots?
X-Robots-Tag to kolejny sposób kontrolowania sposobu przeszukiwania i indeksowania stron internetowych przez pająki. W ramach odpowiedzi nagłówka HTTP na adres URL kontroluje indeksowanie całej strony, a także określonych elementów na tej stronie.
Podczas gdy używanie metatagów robots jest dość proste, X-Robots-Tag jest nieco bardziej skomplikowany.
Ale to oczywiście rodzi pytanie:
Kiedy należy używać X-Robots-Tag?
Według Google „Każda dyrektywa, której można użyć w metatagu robots, może być również określona jako X-Robots-Tag”.
Chociaż możesz ustawić dyrektywy związane z plikiem robots.txt w nagłówkach odpowiedzi HTTP zarówno z tagiem meta robots, jak i tagiem X-Robots, istnieją pewne sytuacje, w których chciałbyś użyć X-Robots-Tag – dwóch najczęstszych być kiedy:
- Chcesz kontrolować sposób przeszukiwania i indeksowania plików innych niż HTML.
- Chcesz wyświetlać dyrektywy w całej witrynie, a nie na poziomie strony.
Na przykład, jeśli chcesz zablokować indeksowanie określonego obrazu lub filmu – metoda odpowiedzi HTTP ułatwia to.
Nagłówek X-Robots-Tag jest również przydatny, ponieważ umożliwia łączenie wielu tagów w odpowiedzi HTTP lub użycie listy dyrektyw rozdzielonych przecinkami w celu określenia dyrektyw.
Może nie chcesz, aby określona strona była zapisywana w pamięci podręcznej i chcesz, aby była niedostępna po określonej dacie. Możesz użyć kombinacji tagów „noarchive” i „unavailable_after”, aby poinstruować roboty wyszukiwarek, aby postępowały zgodnie z tymi instrukcjami.
Zasadniczo siła tagu X-Robots-Tag polega na tym, że jest on znacznie bardziej elastyczny niż metatag robots.
Zaletą korzystania z X-Robots-Tag z odpowiedziami HTTP jest to, że pozwala on używać wyrażeń regularnych do wykonywania dyrektyw indeksowania w formacie innym niż HTML, a także stosować parametry na większym, globalnym poziomie.
Aby ułatwić zrozumienie różnicy między tymi dyrektywami, warto podzielić je według typu. To znaczy, czy są to dyrektywy robota czy dyrektywy indeksatora?
Oto przydatna ściągawka wyjaśniająca:
| Dyrektywy gąsienicowe | Dyrektywy indeksujące |
| Robots.txt – używa dyrektyw agenta użytkownika, allow, disallow i sitemap, aby określić, gdzie boty wyszukiwarek na stronie mogą indeksować, a gdzie nie. | Tag Meta Robots – pozwala określić i uniemożliwić wyszukiwarkom wyświetlanie określonych stron w witrynie w wynikach wyszukiwania. Nofollow – pozwala określić linki, które nie powinny przekazywać autorytetu ani PageRank. X-Robots-tag – pozwala kontrolować sposób indeksowania określonych typów plików. |
Gdzie umieścić tag X-Robots?
Załóżmy, że chcesz zablokować określone typy plików. Idealnym podejściem byłoby dodanie X-Robots-Tag do konfiguracji Apache lub pliku .htaccess.

X-Robots-Tag można dodać do odpowiedzi HTTP witryny w konfiguracji serwera Apache za pośrednictwem pliku .htaccess.
Rzeczywiste przykłady i zastosowania X-Robots-Tag
W teorii brzmi to świetnie, ale jak to wygląda w prawdziwym świecie? Spójrzmy.
Powiedzmy, że chcieliśmy, aby wyszukiwarki nie indeksowały typów plików .pdf. Ta konfiguracja na serwerach Apache wyglądałaby mniej więcej tak:
<Files ~ "\.pdf$"> Header set X-Robots-Tag "noindex, nofollow" </Files>
W Nginx wyglądałoby to tak:
location ~* \.pdf$ {
add_header X-Robots-Tag "noindex, nofollow";
}Teraz spójrzmy na inny scenariusz. Powiedzmy, że chcemy użyć X-Robots-Tag do zablokowania indeksowania plików graficznych, takich jak .jpg, .gif, .png itp. Możesz to zrobić za pomocą X-Robots-Tag, który wyglądałby jak poniżej:
<Pliki ~ "\.(png|jpe?g|gif)$"> Zestaw nagłówków X-Robots-Tag "noindex" </Pliki>
Należy pamiętać, że zrozumienie działania tych dyrektyw i wpływu, jaki wywierają na siebie nawzajem, ma kluczowe znaczenie.
Na przykład, co się stanie, jeśli zarówno tag X-Robots-Tag, jak i metatag robots zostaną zlokalizowane, gdy robot indeksujący wykryje adres URL?
Jeśli ten adres URL zostanie zablokowany w pliku robots.txt, niektórych dyrektyw dotyczących indeksowania i udostępniania nie można wykryć i nie będą one przestrzegane.
Jeśli dyrektywy mają być przestrzegane, nie można zabronić indeksowania zawierających je adresów URL.
Sprawdź tag X-Robots
Istnieje kilka różnych metod, których można użyć do sprawdzenia obecności X-Robots-Tag na stronie.
Najprostszym sposobem sprawdzenia jest zainstalowanie rozszerzenia przeglądarki, które poda informacje X-Robots-Tag o adresie URL.
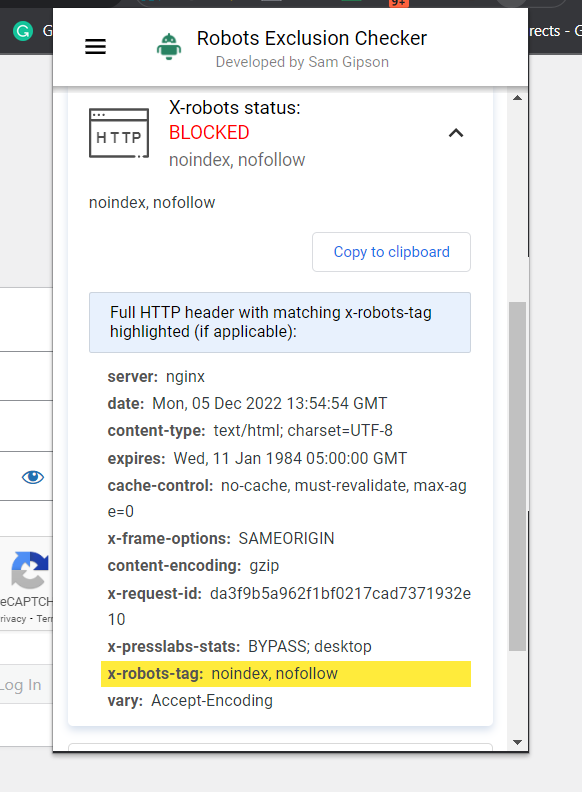 Zrzut ekranu programu Robots Exclusion Checker, grudzień 2022 r
Zrzut ekranu programu Robots Exclusion Checker, grudzień 2022 rInną wtyczką, której możesz użyć na przykład do określenia, czy używany jest X-Robots-Tag, jest wtyczka Web Developer.
Klikając wtyczkę w przeglądarce i przechodząc do „Wyświetl nagłówki odpowiedzi”, możesz zobaczyć różne używane nagłówki HTTP.

Inną metodą, której można użyć do skalowania w celu zlokalizowania problemów na stronach internetowych z milionem stron, jest Screaming Frog.
Po uruchomieniu witryny przez Screaming Frog możesz przejść do kolumny „X-Robots-Tag”.
Dzięki temu dowiesz się, które sekcje witryny używają tagu, wraz z jakimi konkretnymi dyrektywami.
 Zrzut ekranu raportu Screaming Frog. X-Robot-Tag, grudzień 2022 r
Zrzut ekranu raportu Screaming Frog. X-Robot-Tag, grudzień 2022 rKorzystanie z tagów X-Robots w Twojej witrynie
Zrozumienie i kontrolowanie interakcji wyszukiwarek z Twoją witryną jest podstawą optymalizacji pod kątem wyszukiwarek. A X-Robots-Tag to potężne narzędzie, którego możesz użyć właśnie do tego.
Tylko pamiętaj: nie jest to pozbawione niebezpieczeństw. Bardzo łatwo jest popełnić błąd i zdeindeksować całą witrynę.
To powiedziawszy, jeśli czytasz ten artykuł, prawdopodobnie nie jesteś początkującym SEO. Tak długo, jak używasz go mądrze, nie spiesz się i sprawdzaj swoją pracę, X-Robots-Tag będzie przydatnym dodatkiem do twojego arsenału.
Więcej zasobów:
- Google zapewnia witrynom większą kontrolę nad indeksowaniem dzięki nowemu tagowi robotów
- 6 typowych problemów z plikiem Robots.txt i sposobów ich naprawy
- Zaawansowane techniczne SEO: kompletny przewodnik
Obraz wyróżniony: Song_about_summer/Shutterstock