
Alles, was Sie über den X-Robots-Tag-HTTP-Header wissen müssen
Veröffentlicht: 2022-12-19Suchmaschinenoptimierung stützt sich im einfachsten Sinne vor allem auf eines: Suchmaschinen-Spider, die Ihre Website crawlen und indizieren.
Aber fast jede Website wird Seiten haben, die Sie nicht in diese Untersuchung einbeziehen möchten.
Möchten Sie zum Beispiel wirklich, dass Ihre Datenschutzerklärung oder interne Suchseiten in den Google-Ergebnissen angezeigt werden?
Im besten Fall tragen diese nicht dazu bei, den Verkehr aktiv auf Ihre Website zu lenken, und im schlimmsten Fall könnten sie den Verkehr von wichtigeren Seiten umleiten.
Glücklicherweise erlaubt Google Webmastern, Suchmaschinen-Bots mitzuteilen, welche Seiten und Inhalte gecrawlt und welche ignoriert werden sollen. Es gibt mehrere Möglichkeiten, dies zu tun, am häufigsten ist die Verwendung einer robots.txt-Datei oder des Meta-Robots-Tags.
Wir haben eine ausgezeichnete und detaillierte Erklärung der Vor- und Nachteile von robots.txt, die Sie unbedingt lesen sollten.
Aber auf hoher Ebene handelt es sich um eine einfache Textdatei, die sich im Stammverzeichnis Ihrer Website befindet und dem Robots Exclusion Protocol (REP) folgt.
Robots.txt bietet Crawlern Anweisungen über die Website als Ganzes, während Meta-Roboter-Tags Anweisungen für bestimmte Seiten enthalten.
Einige Meta-Roboter-Tags, die Sie möglicherweise verwenden, umfassen index , das Suchmaschinen anweist, die Seite zu ihrem Index hinzuzufügen; noindex , das ihm mitteilt, dass eine Seite nicht zum Index hinzugefügt oder in die Suchergebnisse aufgenommen werden soll; follow , das eine Suchmaschine anweist, den Links auf einer Seite zu folgen; nofollow , das es anweist, Links nicht zu folgen, und eine ganze Reihe anderer.
Sowohl robots.txt als auch Meta-Robots-Tags sind nützliche Tools, die Sie in Ihrer Toolbox aufbewahren sollten, aber es gibt auch eine andere Möglichkeit, Suchmaschinen-Bots anzuweisen, noindex oder nofollow zu geben: das X-Robots-Tag .
Was ist das X-Robots-Tag?
Das X-Robots-Tag ist eine weitere Möglichkeit für Sie zu steuern, wie Ihre Webseiten von Spidern gecrawlt und indiziert werden. Als Teil der HTTP-Header-Antwort auf eine URL steuert es die Indizierung für eine ganze Seite sowie die spezifischen Elemente auf dieser Seite.
Und während die Verwendung von Meta-Robots-Tags ziemlich einfach ist, ist das X-Robots-Tag etwas komplizierter.
Aber das wirft natürlich die Frage auf:
Wann sollten Sie das X-Robots-Tag verwenden?
Laut Google „kann jede Anweisung, die in einem Robots-Meta-Tag verwendet werden kann, auch als X-Robots-Tag angegeben werden.“
Während Sie robots.txt-bezogene Anweisungen in den Headern einer HTTP-Antwort sowohl mit dem Meta-Robots-Tag als auch mit dem X-Robots-Tag setzen können, gibt es bestimmte Situationen, in denen Sie das X-Robots-Tag verwenden möchten – die beiden häufigsten sein wann:
- Sie möchten steuern, wie Ihre Nicht-HTML-Dateien gecrawlt und indiziert werden.
- Sie möchten Anweisungen auf der gesamten Website statt auf Seitenebene bereitstellen.
Wenn Sie beispielsweise das Crawlen eines bestimmten Bildes oder Videos blockieren möchten, ist dies mit der HTTP-Antwortmethode ganz einfach.
Der X-Robots-Tag-Header ist ebenfalls nützlich, da Sie damit mehrere Tags innerhalb einer HTTP-Antwort kombinieren oder eine durch Kommas getrennte Liste von Anweisungen verwenden können, um Anweisungen anzugeben.
Vielleicht möchten Sie nicht, dass eine bestimmte Seite zwischengespeichert wird und nach einem bestimmten Datum nicht mehr verfügbar ist. Sie können eine Kombination aus „noarchive“- und „unavailable_after“-Tags verwenden, um Suchmaschinen-Bots anzuweisen, diese Anweisungen zu befolgen.
Die Stärke des X-Robots-Tags liegt im Wesentlichen darin, dass es viel flexibler ist als das Meta-Robots-Tag.
Der Vorteil der Verwendung eines X-Robots-Tag mit HTTP-Antworten besteht darin, dass Sie mit regulären Ausdrücken Crawl-Anweisungen auf Nicht-HTML ausführen sowie Parameter auf einer größeren, globalen Ebene anwenden können.
Damit Sie den Unterschied zwischen diesen Anweisungen verstehen, ist es hilfreich, sie nach Typ zu kategorisieren. Das heißt, sind sie Crawler-Direktiven oder Indexer-Direktiven?
Hier ist ein praktischer Spickzettel zur Erklärung:
| Crawler-Richtlinien | Indexer-Richtlinien |
| Robots.txt – verwendet die User-Agent-, Allow-, Disallow- und Sitemap-Direktiven, um anzugeben, wo On-Site-Suchmaschinen-Bots crawlen dürfen und wo nicht. | Meta Robots-Tag – ermöglicht es Ihnen, Suchmaschinen festzulegen und zu verhindern, dass bestimmte Seiten einer Website in den Suchergebnissen angezeigt werden. Nofollow – ermöglicht es Ihnen, Links anzugeben, die keine Autorität oder PageRank weitergeben sollen. X-Robots-Tag – ermöglicht es Ihnen, zu steuern, wie bestimmte Dateitypen indiziert werden. |
Wo platzieren Sie das X-Robots-Tag?
Angenommen, Sie möchten bestimmte Dateitypen blockieren. Ein idealer Ansatz wäre, das X-Robots-Tag in eine Apache-Konfiguration oder eine .htaccess-Datei einzufügen.

Das X-Robots-Tag kann in einer Apache-Serverkonfiguration per .htaccess-Datei zu den HTTP-Antworten einer Seite hinzugefügt werden.
Beispiele aus der Praxis und Verwendung des X-Robots-Tags
Das klingt in der Theorie großartig, aber wie sieht es in der realen Welt aus? Lass uns einen Blick darauf werfen.
Nehmen wir an, wir wollten, dass Suchmaschinen .pdf-Dateitypen nicht indizieren. Diese Konfiguration auf Apache-Servern würde etwa wie folgt aussehen:
<Files ~ "\.pdf$"> Header set X-Robots-Tag "noindex, nofollow" </Files>
In Nginx würde es wie folgt aussehen:
location ~* \.pdf$ {
add_header X-Robots-Tag "noindex, nofollow";
}Betrachten wir nun ein anderes Szenario. Angenommen, wir möchten das X-Robots-Tag verwenden, um zu verhindern, dass Bilddateien wie .jpg, .gif, .png usw. indiziert werden. Sie könnten dies mit einem X-Robots-Tag tun, das wie folgt aussehen würde:
<Dateien ~ "\.(png|jpe?g|gif)$"> Header-Set X-Robots-Tag "noindex" </Dateien>
Bitte beachten Sie, dass es von entscheidender Bedeutung ist, zu verstehen, wie diese Richtlinien funktionieren und welche Auswirkungen sie aufeinander haben.
Was passiert beispielsweise, wenn sowohl das X-Robots-Tag als auch ein Meta-Robots-Tag gefunden werden, wenn Crawler-Bots eine URL entdecken?
Wenn diese URL von robots.txt blockiert wird, können bestimmte Indizierungs- und Serving-Anweisungen nicht erkannt werden und werden nicht befolgt.
Wenn Anweisungen befolgt werden müssen, können die URLs, die diese enthalten, nicht vom Crawlen ausgeschlossen werden.
Suchen Sie nach einem X-Robots-Tag
Es gibt verschiedene Methoden, mit denen Sie auf der Website nach einem X-Robots-Tag suchen können.
Die einfachste Möglichkeit zur Überprüfung besteht darin, eine Browsererweiterung zu installieren, die Ihnen X-Robots-Tag-Informationen über die URL mitteilt.
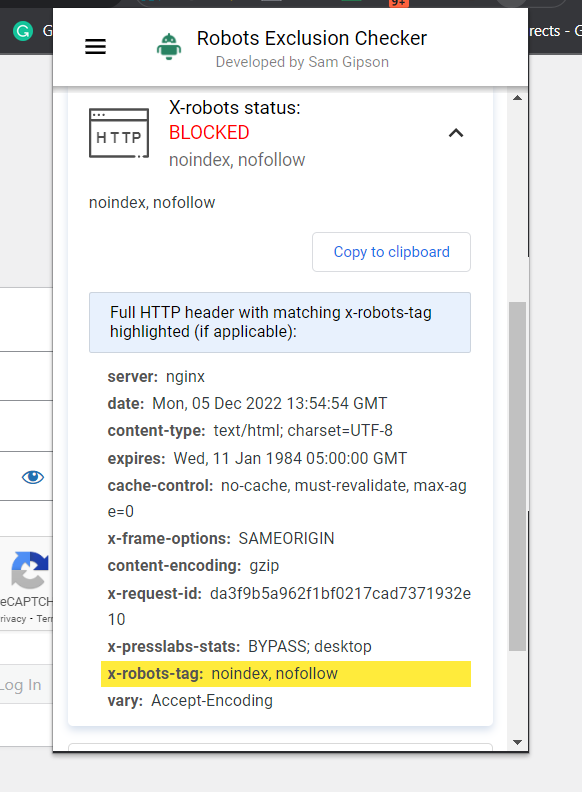 Screenshot von Robots Exclusion Checker, Dezember 2022
Screenshot von Robots Exclusion Checker, Dezember 2022Ein weiteres Plugin, mit dem Sie beispielsweise feststellen können, ob ein X-Robots-Tag verwendet wird, ist das Web Developer Plugin.
Indem Sie in Ihrem Browser auf das Plugin klicken und zu „View Response Headers“ navigieren, können Sie die verschiedenen verwendeten HTTP-Header sehen.

Eine weitere Methode, die zur Skalierung verwendet werden kann, um Probleme auf Websites mit einer Million Seiten zu lokalisieren, ist Screaming Frog.
Nachdem Sie eine Site über Screaming Frog ausgeführt haben, können Sie zur Spalte „X-Robots-Tag“ navigieren.
Dies zeigt Ihnen, welche Abschnitte der Website das Tag verwenden, zusammen mit welchen spezifischen Anweisungen.
 Screenshot des Screaming-Frog-Berichts. X-Robot-Tag, Dezember 2022
Screenshot des Screaming-Frog-Berichts. X-Robot-Tag, Dezember 2022Verwendung von X-Robots-Tags auf Ihrer Website
Das Verständnis und die Kontrolle darüber, wie Suchmaschinen mit Ihrer Website interagieren, ist der Eckpfeiler der Suchmaschinenoptimierung. Und der X-Robots-Tag ist ein mächtiges Werkzeug, mit dem Sie genau das tun können.
Seien Sie sich bewusst: Es ist nicht ohne Gefahren. Es ist sehr einfach, einen Fehler zu machen und Ihre gesamte Website zu deindexieren.
Das heißt, wenn Sie diesen Artikel lesen, sind Sie wahrscheinlich kein SEO-Anfänger. Solange Sie es mit Bedacht einsetzen, sich Zeit nehmen und Ihre Arbeit überprüfen, werden Sie feststellen, dass das X-Robots-Tag eine nützliche Ergänzung Ihres Arsenals ist.
Mehr Ressourcen:
- Google gibt Websites mit dem neuen Robots-Tag mehr Kontrolle über die Indizierung
- 6 häufige Probleme mit robots.txt und wie man sie behebt
- Technisches SEO für Fortgeschrittene: Ein vollständiger Leitfaden
Beitragsbild: Song_about_summer/Shutterstock