
X-Robots-Tag HTTP Başlığı Hakkında Bilmeniz Gereken Her Şey
Yayınlanan: 2022-12-19Arama motoru optimizasyonu, en temel anlamıyla, her şeyden önce bir şeye dayanır: Sitenizi tarayan ve dizine ekleyen arama motoru örümcekleri.
Ancak neredeyse her web sitesinde, bu keşfe dahil etmek istemediğiniz sayfalar olacaktır.
Örneğin, gizlilik politikanızın veya dahili arama sayfalarınızın Google sonuçlarında görünmesini gerçekten istiyor musunuz?
En iyi senaryoda, bunlar sitenize aktif olarak trafik çekmek için hiçbir şey yapmıyor ve en kötü durumda, trafiği daha önemli sayfalardan yönlendiriyor olabilir.
Neyse ki Google, web yöneticilerinin arama motoru botlarına hangi sayfaların ve içeriğin taranacağını ve nelerin göz ardı edileceğini söylemesine izin veriyor. Bunu yapmanın birkaç yolu vardır; en yaygın olanı bir robots.txt dosyası veya meta robots etiketi kullanmaktır.
Kesinlikle okumanız gereken robots.txt dosyasının tüm ayrıntılarıyla ilgili mükemmel ve ayrıntılı bir açıklamamız var.
Ancak üst düzey terimlerle, web sitenizin kök dizininde yaşayan ve Robotları Hariç Tutma Protokolünü (REP) izleyen bir düz metin dosyasıdır.
Robots.txt, tarayıcılara sitenin tamamı hakkında talimatlar sağlarken, meta robots etiketleri belirli sayfalar için talimatlar içerir.
Kullanabileceğiniz bazı meta robot etiketleri arasında, arama motorlarına sayfayı dizinlerine eklemelerini söyleyen index ; dizine bir sayfa eklememesini veya arama sonuçlarına dahil etmemesini söyleyen noindex ; bir arama motoruna bir sayfadaki bağlantıları takip etmesi talimatını veren takip edin; nofollow , ona bağlantıları takip etmemesini söyler ve bir sürü başka şey.
Hem robots.txt hem de meta robots etiketleri araç kutunuzda tutmak için yararlı araçlardır, ancak arama motoru botlarına noindex veya nofollow yapma talimatı vermenin başka bir yolu da vardır: X-Robots-Tag .
X-Robots-Etiketi Nedir?
X-Robots-Tag, web sayfalarınızın örümcekler tarafından nasıl tarandığını ve indekslendiğini kontrol etmenin başka bir yoludur. Bir URL'ye verilen HTTP başlık yanıtının bir parçası olarak, o sayfadaki belirli öğelerin yanı sıra tüm sayfa için indekslemeyi denetler.
Ve meta robot etiketlerini kullanmak oldukça basitken, X-Robots-Tag biraz daha karmaşıktır.
Ancak bu, elbette şu soruyu gündeme getiriyor:
X-Robots-Tag'ı Ne Zaman Kullanmalısınız?
Google'a göre, "Bir robots meta etiketinde kullanılabilen herhangi bir yönerge, X-Robots-Tag olarak da belirtilebilir."
Hem meta robots etiketi hem de X-Robots Etiketi ile bir HTTP yanıtının başlıklarında robots.txt ile ilgili yönergeler ayarlayabilirken, X-Robots-Tag'ı kullanmak isteyeceğiniz belirli durumlar vardır - en yaygın ikisi olmak ne zaman:
- HTML olmayan dosyalarınızın nasıl tarandığını ve dizine eklendiğini kontrol etmek istiyorsunuz.
- Yönergeleri sayfa düzeyinde yerine site genelinde sunmak istiyorsunuz.
Örneğin, belirli bir görüntünün veya videonun taranmasını engellemek istiyorsanız, HTTP yanıt yöntemi bunu kolaylaştırır.
X-Robots-Tag başlığı, bir HTTP yanıtı içinde birden çok etiketi birleştirmenize veya yönergeleri belirtmek için virgülle ayrılmış bir yönerge listesi kullanmanıza izin verdiği için de kullanışlıdır.
Belki de belirli bir sayfanın önbelleğe alınmasını istemiyorsunuz ve belirli bir tarihten sonra kullanılamaması istiyorsunuz. Arama motoru botlarına bu talimatları izleme talimatı vermek için "noarchive" ve "unavailable_after" etiketlerinin bir kombinasyonunu kullanabilirsiniz.
Temel olarak, X-Robots-Tag'in gücü, meta robots etiketinden çok daha esnek olmasıdır.
HTTP yanıtları ile bir X-Robots-Tag kullanmanın avantajı, normal ifadeleri kullanarak HTML dışı tarama yönergelerini yürütmenize ve ayrıca parametreleri daha geniş, küresel bir düzeyde uygulamanıza izin vermesidir.
Bu direktifler arasındaki farkı anlamanıza yardımcı olması için türlerine göre kategorize etmek faydalı olacaktır. Yani, tarayıcı yönergeleri mi yoksa indeksleyici yönergeleri mi?
İşte açıklamak için kullanışlı bir hile sayfası:
| Paletli Direktifler | Dizin Oluşturucu Yönergeleri |
| Robots.txt – site içi arama motoru botlarının nerede tarama yapmasına izin verilip verilmediğini belirtmek için kullanıcı aracısı, allow, disallow ve sitemap yönergelerini kullanır. | Meta Robots etiketi – arama motorlarının bir sitedeki belirli sayfaları arama sonuçlarında göstermesini belirtmenize ve engellemenize olanak tanır. Nofollow – yetki veya PageRank'e geçmemesi gereken bağlantıları belirtmenize olanak tanır. X-Robots-tag – belirtilen dosya türlerinin nasıl indeksleneceğini kontrol etmenizi sağlar. |
X-Robots-Etiketini Nereye Koyuyorsunuz?
Belirli dosya türlerini engellemek istediğinizi varsayalım. İdeal bir yaklaşım, X-Robots-Tag'ı bir Apache yapılandırmasına veya bir .htaccess dosyasına eklemek olacaktır.

X-Robots-Tag, bir sitenin HTTP yanıtlarına .htaccess dosyası aracılığıyla bir Apache sunucu yapılandırmasında eklenebilir.
X-Robots-Tag'in Gerçek Dünyadan Örnekleri ve Kullanımları
Yani teoride kulağa harika geliyor, ama gerçek dünyada nasıl görünüyor? Hadi bir bakalım.
Diyelim ki arama motorlarının .pdf dosya türlerini dizine eklememesini istedik. Apache sunucularındaki bu yapılandırma aşağıdaki gibi görünür:
<Files ~ "\.pdf$"> Header set X-Robots-Tag "noindex, nofollow" </Files>
Nginx'te aşağıdaki gibi görünecektir:
location ~* \.pdf$ {
add_header X-Robots-Tag "noindex, nofollow";
}Şimdi farklı bir senaryoya bakalım. .jpg, .gif, .png gibi görüntü dosyalarının dizine eklenmesini engellemek için X-Robots-Tag kullanmak istediğimizi varsayalım. Bunu, aşağıdaki gibi görünen bir X-Robots-Tag ile yapabilirsiniz:
<Dosyalar ~ "\.(png|jpe?g|gif)$"> Başlık seti X-Robots-Tag "noindex" </Dosyalar>
Lütfen bu direktiflerin nasıl çalıştığını ve birbirleri üzerindeki etkilerini anlamanın çok önemli olduğunu unutmayın.
Örneğin, paletli botlar bir URL keşfettiğinde hem X-Robots-Tag hem de bir meta robots etiketi bulunursa ne olur?
Bu URL, robots.txt dosyasından engellenirse, belirli dizine ekleme ve sunma yönergeleri keşfedilemez ve bunlara uyulmaz.
Yönergelere uyulacaksa, bunları içeren URL'lerin taranmasına izin verilemez.
X-Robots-Etiketini Kontrol Edin
Sitede bir X-Robots-Tag olup olmadığını kontrol etmek için kullanılabilecek birkaç farklı yöntem vardır.
Kontrol etmenin en kolay yolu, size URL hakkında X-Robots-Tag bilgilerini söyleyecek bir tarayıcı uzantısı yüklemektir.
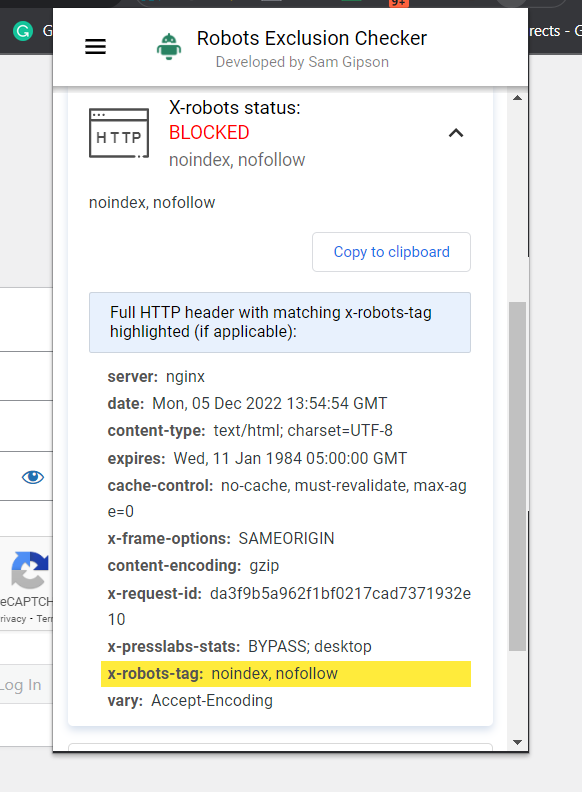 Robots Exclusion Checker'ın ekran görüntüsü, Aralık 2022
Robots Exclusion Checker'ın ekran görüntüsü, Aralık 2022Örneğin, bir X-Robots-Tag kullanılıp kullanılmadığını belirlemek için kullanabileceğiniz başka bir eklenti, Web Developer eklentisidir.
Tarayıcınızda eklentiye tıklayarak ve "Yanıt Başlıklarını Görüntüle"ye giderek, kullanılmakta olan çeşitli HTTP başlıklarını görebilirsiniz.

Bir milyon sayfalık web sitelerindeki sorunları tespit etmek için ölçeklendirme için kullanılabilecek bir başka yöntem de Screaming Frog'dur.
Screaming Frog aracılığıyla bir site çalıştırdıktan sonra, "X-Robots-Tag" sütununa gidebilirsiniz.
Bu size, sitenin hangi bölümlerinin etiketi ve hangi özel direktifleri kullandığını gösterecektir.
 Screaming Frog Report'un ekran görüntüsü. X-Robot-Tag, Aralık 2022
Screaming Frog Report'un ekran görüntüsü. X-Robot-Tag, Aralık 2022Sitenizde X-Robots-Tags Kullanımı
Arama motorlarının web sitenizle nasıl etkileşime girdiğini anlamak ve kontrol etmek, arama motoru optimizasyonunun temel taşıdır. Ve X-Robots-Tag, tam da bunu yapmak için kullanabileceğiniz güçlü bir araçtır.
Sadece farkında olun: Tehlikeleri de yok değil. Bir hata yapmak ve tüm sitenizin dizini kaldırmak çok kolaydır.
Bununla birlikte, bu parçayı okuyorsanız, muhtemelen bir SEO acemi değilsiniz. Akıllıca kullandığınız, zaman ayırdığınız ve çalışmalarınızı kontrol ettiğiniz sürece, X-Robots-Tag'in cephaneliğinize faydalı bir katkı olduğunu göreceksiniz.
Daha fazla kaynak:
- Google, Yeni Robotlar Etiketiyle Sitelere Daha Fazla Dizinleme Kontrolü Veriyor
- 6 Yaygın Robots.txt Sorunu ve Nasıl Düzeltilir
- Gelişmiş Teknik SEO: Eksiksiz Bir Kılavuz
Öne Çıkan Görsel: Song_about_summer/Shutterstock