
De ce contează jurnalele de server pentru SEO
Publicat: 2022-01-11Majoritatea operatorilor de site-uri web nu sunt conștienți de importanța jurnalelor de server web. Ei nu înregistrează, cu atât mai puțin analizează jurnalele de server ale site-ului lor. Mărcile mari, în special, nu reușesc să valorifice analiza jurnalului de server și pierd iremediabil datele de jurnal de server neînregistrate.
Organizațiile care aleg să adopte analiza jurnalelor de server ca parte a eforturilor lor continue de SEO excelează adesea în Căutarea Google. Dacă site-ul dvs. este format din 100.000 de pagini sau mai mult și doriți să aflați cum și de ce jurnalele de server reprezintă o oportunitate extraordinară de creștere, continuați să citiți.
De ce contează jurnalele de server
De fiecare dată când un bot solicită o adresă URL găzduită pe un server web, o înregistrare de jurnal este creată automat, reflectând informațiile schimbate în proces. Când acoperă o perioadă extinsă de timp, jurnalele serverului devin reprezentative pentru istoricul solicitărilor primite și al răspunsurilor returnate.
Informațiile păstrate în fișierele jurnal ale serverului includ, de obicei, adresa IP a clientului, data și ora solicitării, adresa URL a paginii solicitate, codul de răspuns HTTP, volumul de octeți serviți, precum și agentul utilizator și referintul.
În timp ce jurnalele de server sunt create la fiecare caz în care se solicită o pagină web, inclusiv solicitările de browser ale utilizatorilor, optimizarea motorului de căutare se concentrează exclusiv pe utilizarea datelor de jurnal ale serverului bot. Acest lucru este relevant în ceea ce privește considerentele juridice referitoare la cadrele de protecție a datelor, cum ar fi GDPR/CCPA/DSGVO. Deoarece nu sunt incluse niciodată date despre utilizator în scopuri SEO, analiza jurnalului de server web anonimizată rămâne nelimitată de reglementările legale eventual aplicabile.
Merită menționat faptul că, într-o oarecare măsură, informații similare sunt posibile pe baza statisticilor de accesare cu crawlere din Google Search Console. Cu toate acestea, aceste mostre sunt limitate în volum și interval de timp acoperit. Spre deosebire de Google Search Console, cu datele sale care reflectă doar ultimele luni, este vorba exclusiv de fișierele jurnal de server care oferă o imagine clară, de ansamblu, subliniind tendințele SEO pe termen lung.
Datele valoroase din jurnalele serverului
De fiecare dată când un bot solicită o pagină găzduită pe server, este creată o instanță de jurnal care înregistrează un număr de puncte de date, inclusiv:
- Adresa IP a clientului solicitant.
- Ora exactă a solicitării, adesea bazată pe ceasul intern al serverului.
- Adresa URL care a fost solicitată.
- HTTP a fost folosit pentru cerere.
- Codul de stare a răspunsului a fost returnat (de exemplu, 200, 301, 404, 500 sau altul).
- Șirul agentului utilizator de la entitatea solicitantă (de exemplu, un nume de robot al motorului de căutare, cum ar fi Googlebot/2.1).
O mostră tipică de înregistrare a jurnalului de server poate arăta astfel:
150.174.193.196 - - [15/Dec/2021:11:25:14 +0100] "GET /index.html HTTP/1.0" 200 1050 "-" "Googlebot/2.1 (+http://www.google.com/bot.html)" "www.example.ai"
În acest exemplu:
-
150.174.193.196este IP-ul entității solicitante.
-
[15/Dec/2021:11:25:14 +0100]este fusul orar, precum și ora solicitării.
-
"GET /index.html HTTP/1.0"este metoda HTTP utilizată (GET), fișierul solicitat (index.html) și versiunea protocolului HTTP utilizată.
-
200este răspunsul codului de stare HTTP al serverului returnat.
-
1050este dimensiunea de octeți a răspunsului serverului.
-
"Googlebot/2.1 (+http://www.google.com/bot.html)"este agentul utilizator al entității solicitante.
-
"www.example.ai"este adresa URL de referință.
Cum se utilizează jurnalele serverului
Din perspectiva SEO, există trei motive principale pentru care jurnalele de server web oferă informații de neegalat:
- Asistență la filtrarea traficului de bot nedorit fără semnificație SEO din traficul de robot de căutare dorit, care provine de la roboți legitimi, cum ar fi Googlebot, Bingbot sau YandexBot.
- Furnizarea de informații SEO cu privire la prioritizarea accesării cu crawlere și, prin urmare, oferind echipei SEO posibilitatea de a-și ajusta și perfecționa în mod proactiv gestionarea bugetului de accesare cu crawlere.
- Permiterea monitorizării și furnizarea unei evidențe a răspunsurilor serverului trimise către motoarele de căutare.
Boții falși ai motoarelor de căutare pot fi o pacoste, dar afectează doar rar site-urile web. Există o serie de furnizori de servicii specializați, cum ar fi Cloudflare și AWS Shield, care pot ajuta la gestionarea traficului de bot nedorit. În procesul de analiză a jurnalelor de server web, roboții falși ai motoarelor de căutare tind să joace un rol subordonat.
Pentru a evalua cu exactitate care părți ale unui site sunt prioritizate, altele decât motoarele de căutare majore, traficul bot trebuie să fie filtrat atunci când se efectuează o analiză de jurnal. În funcție de piețele vizate, accentul se poate pune pe roboții motoarelor de căutare precum Google, Apple, Bing, Yandex sau alții.
În special pentru site-urile web în care prospețimea conținutului este esențială, cât de frecvent acele site-uri sunt accesate din nou cu crawlere poate avea un impact critic asupra utilității acestora pentru utilizatori. Cu alte cuvinte, dacă modificările de conținut nu sunt preluate suficient de rapid, este puțin probabil ca semnalele experienței utilizatorului și clasamentele organice ale căutării să își atingă întregul potențial.

Deși Google este înclinat să acceseze cu crawlere toate informațiile disponibile și să acceseze din nou cu crawlere tiparele URL deja cunoscute în mod regulat, resursele sale de accesare cu crawlere nu sunt nelimitate. De aceea, pentru site-urile web mari care constau din sute de mii de pagini de destinație, ciclurile de re-crawler depind de algoritmii Google de alocare a priorităților de accesare cu crawlere.
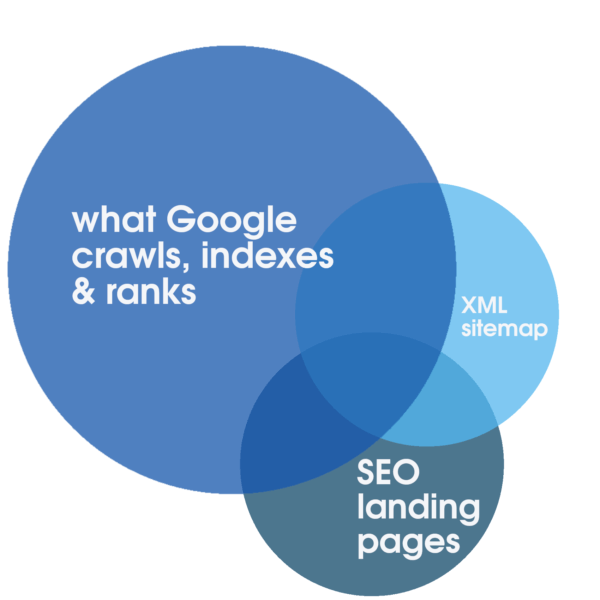
Acea alocare poate fi stimulată în mod pozitiv cu servicii web fiabile, cu un timp de funcționare extrem de receptiv, optimizate special pentru o experiență rapidă. Numai acești pași sunt propice pentru SEO. Cu toate acestea, doar analizând jurnalele de server complete care acoperă o perioadă extinsă de timp este posibil să se identifice gradul de suprapunere între volumul total al tuturor paginilor de destinație care pot fi accesate cu crawlere, numărul de obicei mai mic de pagini de destinație SEO relevante, optimizate și indexabile reprezentate în Sitemap și ceea ce Google acordă în mod regulat prioritate pentru accesare cu crawlere, indexare și clasare.
O astfel de analiză a jurnalului ca parte integrantă a unui audit tehnic SEO și singura metodă de a descoperi gradul de risipă bugetară cu crawl. Și indiferent dacă filtrarea cu crawlere, substituent sau pagini de conținut slab, un server deschis sau alte părți învechite ale site-ului web continuă să afecteze accesarea cu crawlere și, în cele din urmă, clasamentele. În anumite circumstanțe, cum ar fi o migrare planificată, informațiile obținute printr-un audit SEO, inclusiv analiza jurnalului de server, fac adesea diferența între succesul și eșecul migrării.

În plus, analiza jurnalului oferă pentru site-urile mari web informații SEO critice. Poate oferi un răspuns la cât timp are nevoie Google pentru a accesa din nou întregul site web . Dacă răspunsul se întâmplă să fie decisiv – luni sau mai mult – poate fi necesară o acțiune pentru a vă asigura că paginile de destinație SEO indexabile sunt accesate cu crawlere. În caz contrar, există un mare risc ca orice îmbunătățire SEO adusă site-ului web să treacă neobservată de motoarele de căutare, potențial luni de la lansare, ceea ce, la rândul său, este o rețetă pentru clasamente slabe.
Răspunsurile serverului sunt esențiale pentru o vizibilitate excelentă în Căutarea Google. În timp ce Google Search Console oferă o privire importantă asupra răspunsurilor recente ale serverului, orice date oferite de Google Search Console operatorilor de site-uri web trebuie considerate un eșantion reprezentativ, dar limitat. Deși acest lucru poate fi util pentru a identifica probleme grave, cu o analiză a jurnalului de server este posibil să se analizeze și să se identifice toate răspunsurile HTTP, inclusiv orice răspunsuri non-200 OK relevante cantitativ care pot pune în pericol clasamentele. Răspunsurile alternative posibile pot indica probleme de performanță (de exemplu, timp de nefuncționare programat 503 Service Unavailable) dacă sunt excesive.

De unde să începeți
În ciuda potențialului pe care îl are analiza serverului de jurnal, majoritatea operatorilor de site-uri web nu profită de oportunitățile prezentate. Jurnalele de server fie nu sunt înregistrate deloc, fie sunt suprascrise în mod regulat sau sunt incomplete. Majoritatea covârșitoare a site-urilor web nu păstrează datele de jurnal ale serverului pentru o perioadă semnificativă de timp. Aceasta este o veste bună pentru operatorii care doresc, spre deosebire de concurenții lor, să colecteze și să utilizeze fișiere jurnal ale serverului pentru optimizarea motoarelor de căutare.
Când planificați colectarea datelor de jurnal de server, este de remarcat care câmpuri de date trebuie să fie cel puțin reținute în fișierele de jurnal ale serverului pentru ca datele să fie utilizabile. Următoarea listă poate fi considerată un ghid:
- adresa IP de la distanță a entității solicitante.
- șirul de agent de utilizator al entității solicitante.
- schema de solicitare (de exemplu, a fost cererea HTTP pentru http sau https sau wss sau altceva).
- cerere nume de gazdă (de exemplu, pentru ce subdomeniu sau domeniu a fost solicitarea HTTP).
- calea cererii, adesea aceasta este calea fișierului de pe server ca URL relativă.
- parametrii de solicitare, care pot face parte din calea cererii.
- solicitați ora, inclusiv data, ora și fusul orar.
- metoda de solicitare.
- codul de stare http de răspuns.
- timpii de răspuns.
Dacă calea cererii este o adresă URL relativă, câmpurile care sunt adesea neglijate în fișierele jurnal ale serverului sunt înregistrarea numelui de gazdă și a schemei cererii. Acesta este motivul pentru care este important să verificați cu departamentul IT dacă calea solicitării este o adresă URL relativă, astfel încât numele gazdei și schema să fie înregistrate și în fișierele jurnal ale serverului. O soluție simplă este să înregistrați întreaga adresă URL a cererii ca un singur câmp, care include schema, numele gazdei, calea și parametrii într-un singur șir.
Atunci când colectați fișiere jurnal de server, este, de asemenea, important să includeți jurnalele care provin din CDN-uri și alte servicii terțe pe care site-ul le poate folosi. Consultați aceste servicii terțe despre cum să extrageți și să salvați fișierele jurnal în mod regulat.
Depășirea obstacolelor în calea analizei jurnalelor de server
Adesea, sunt prezentate două obstacole principale pentru a contracara nevoia urgentă de a păstra datele de jurnal de server: costuri și preocupări legale. Deși ambii factori sunt în cele din urmă determinați de circumstanțe individuale, cum ar fi bugetul și jurisdicția legală, niciunul nu trebuie să reprezinte un obstacol serios.
Stocarea în cloud poate fi o opțiune pe termen lung, iar stocarea hardware fizică este, de asemenea, probabil să limiteze costul. Cu prețurile de vânzare cu amănuntul pentru hard disk-uri de aproximativ 20 TB sub 600 USD, costul hardware este neglijabil. Având în vedere că prețul hardware-ului de stocare a scăzut de ani de zile, în cele din urmă costul de stocare este puțin probabil să reprezinte o provocare serioasă pentru înregistrarea jurnalelor de server.
În plus, va exista un cost asociat cu software-ul de analiză a jurnalelor sau cu furnizorul de audit SEO care prestează serviciul. Deși aceste costuri trebuie luate în considerare în buget, încă o dată este ușor de justificat în lumina avantajelor pe care le oferă analiza serverului de jurnal.
Deși acest articol are scopul de a sublinia beneficiile inerente ale analizei jurnalelor de server pentru SEO, nu ar trebui să fie considerat o recomandare legală. O astfel de consiliere juridică poate fi oferită numai de un avocat calificat în contextul cadrului legal și al jurisdicției relevante. O serie de legi și reglementări, cum ar fi GDPR/CCPA/DSGVO, se pot aplica în acest context. În special atunci când operează din UE, confidențialitatea este o preocupare majoră. Cu toate acestea, în scopul unei analize a jurnalului de server pentru SEO, orice date referitoare la utilizator nu sunt relevante. Orice înregistrări care nu pot fi verificate în mod concludent pe baza adresei IP trebuie ignorate.
În ceea ce privește problemele legate de confidențialitate, orice date de jurnal care nu validează și nu este un robot de căutare confirmat nu trebuie să fie utilizate și, în schimb, pot fi șterse sau anonimizate după o perioadă definită de timp, pe baza recomandărilor legale relevante. Această abordare încercată și testată este aplicată în mod regulat de unii dintre cei mai mari operatori de site-uri web.
Când să începeți
Întrebarea majoră rămasă este când să începeți colectarea datelor de jurnal de server. Răspunsul este acum!
Datele de jurnal de server pot fi aplicate într-un mod semnificativ și pot duce la sfaturi utile numai dacă sunt disponibile în volum suficient. Masa critică de utilitate a jurnalelor de server pentru auditurile SEO variază de obicei între șase și treizeci și șase de luni, în funcție de cât de mare este un site web și de semnalele sale de prioritizare a accesării cu crawlere.
Este important de reținut că jurnalele de server neînregistrate nu pot fi achiziționate într-o etapă ulterioară. Sunt șanse ca orice eforturi de a păstra și păstra jurnalele de server inițiate astăzi să dea roade încă din anul următor. Prin urmare, colectarea datelor de jurnal de server trebuie să înceapă cât mai curând posibil și să continue neîntrerupt atâta timp cât site-ul web funcționează și își propune să funcționeze bine în căutarea organică.
Opiniile exprimate în acest articol sunt cele ale autorului invitat și nu neapărat Search Engine Land. Autorii personalului sunt enumerați aici.