
Pourquoi les journaux de serveur sont importants pour le référencement
Publié: 2022-01-11La majorité des opérateurs de sites Web ne sont pas conscients de l'importance des journaux de serveur Web. Ils n'enregistrent pas et encore moins n'analysent pas les logs du serveur de leur site Web. Les grandes marques, en particulier, ne parviennent pas à tirer parti de l'analyse des journaux de serveur et perdent irrémédiablement des données de journal de serveur non enregistrées.
Les organisations qui choisissent d'adopter l'analyse des journaux de serveur dans le cadre de leurs efforts de référencement en cours excellent souvent dans la recherche Google. Si votre site Web comprend 100 000 pages ou plus et que vous souhaitez savoir comment et pourquoi les journaux de serveur représentent une formidable opportunité de croissance, continuez à lire.
Pourquoi les journaux de serveur sont importants
Chaque fois qu'un bot demande une URL hébergée sur un serveur Web, une entrée d'enregistrement de journal est automatiquement créée, reflétant les informations échangées au cours du processus. Lorsqu'ils couvrent une période prolongée, les journaux du serveur deviennent représentatifs de l'historique des requêtes reçues et des réponses renvoyées.
Les informations conservées dans les fichiers journaux du serveur incluent généralement l'adresse IP du client, la date et l'heure de la demande, l'URL de la page demandée, le code de réponse HTTP, le volume d'octets servis ainsi que l'agent utilisateur et le référent.
Alors que les journaux du serveur sont créés à chaque fois qu'une page Web est demandée, y compris les demandes du navigateur de l'utilisateur, l'optimisation des moteurs de recherche se concentre exclusivement sur l'utilisation des données du journal du serveur bot. Ceci est pertinent en ce qui concerne les considérations juridiques touchant aux cadres de protection des données tels que GDPR/CCPA/DSGVO. Étant donné qu'aucune donnée d'utilisateur n'est jamais incluse à des fins de référencement, l'analyse brute et anonymisée des journaux de serveur Web n'est pas entravée par des réglementations légales autrement potentiellement applicables.
Il convient de mentionner que, dans une certaine mesure, des informations similaires sont possibles sur la base des statistiques d'exploration de la console de recherche Google. Cependant, ces échantillons sont limités en volume et en durée. Contrairement à Google Search Console, dont les données ne reflètent que les derniers mois, ce sont exclusivement les fichiers journaux du serveur qui fournissent une vue d'ensemble claire décrivant les tendances SEO à long terme.
Les précieuses données contenues dans les journaux de serveur
Chaque fois qu'un bot demande une page hébergée sur le serveur, une instance de journal est créée pour enregistrer un certain nombre de points de données, notamment :
- L'adresse IP du client demandeur.
- L'heure exacte de la demande, souvent basée sur l'horloge interne du serveur.
- L'URL demandée.
- Le HTTP a été utilisé pour la requête.
- Le code d'état de la réponse renvoyé (par exemple, 200, 301, 404, 500 ou autre).
- La chaîne de l'agent utilisateur de l'entité demandeuse (par exemple, un nom de robot de moteur de recherche comme Googlebot/2.1).
Un exemple typique d'enregistrement de journal de serveur peut ressembler à ceci :
150.174.193.196 - - [15/Dec/2021:11:25:14 +0100] "GET /index.html HTTP/1.0" 200 1050 "-" "Googlebot/2.1 (+http://www.google.com/bot.html)" "www.example.ai"
Dans cet exemple :
-
150.174.193.196est l'IP de l'entité requérante.
-
[15/Dec/2021:11:25:14 +0100]est le fuseau horaire ainsi que l'heure de la demande.
-
"GET /index.html HTTP/1.0"est la méthode HTTP utilisée (GET), le fichier demandé (index.html) et la version du protocole HTTP utilisé.
-
200est la réponse du code d'état HTTP du serveur renvoyée.
-
1050est la taille en octets de la réponse du serveur.
-
"Googlebot/2.1 (+http://www.google.com/bot.html)"est l'agent utilisateur de l'entité demandeuse.
-
"www.example.ai"est l'URL de référence.
Comment utiliser les journaux du serveur
Du point de vue du référencement, il existe trois raisons principales pour lesquelles les journaux de serveur Web fournissent des informations sans précédent :
- Aider à filtrer le trafic indésirable des bots sans importance pour le référencement du trafic souhaitable des bots des moteurs de recherche provenant de bots légitimes tels que Googlebot, Bingbot ou YandexBot.
- Fournir des informations SEO sur la priorisation du crawl et ainsi permettre à l'équipe SEO de modifier et d'affiner de manière proactive la gestion de son budget de crawl.
- Permettre de surveiller et de fournir un historique des réponses du serveur envoyées aux moteurs de recherche.
Les faux robots des moteurs de recherche peuvent être une nuisance, mais ils n'affectent que rarement les sites Web. Il existe un certain nombre de fournisseurs de services spécialisés comme Cloudflare et AWS Shield qui peuvent aider à gérer le trafic indésirable des bots. Dans le processus d'analyse des journaux de serveur Web, les faux bots des moteurs de recherche ont tendance à jouer un rôle secondaire.
Afin d'évaluer avec précision quelles parties d'un site Web sont prioritaires autres que les principaux moteurs de recherche, le trafic des bots doit être filtré lors de l'analyse des journaux. Selon les marchés ciblés, l'accent peut être mis sur les robots des moteurs de recherche comme Google, Apple, Bing, Yandex ou autres.
Surtout pour les sites Web où la fraîcheur du contenu est essentielle, la fréquence à laquelle ces sites sont réexplorés peut avoir un impact critique sur leur utilité pour les utilisateurs. En d'autres termes, si les changements de contenu ne sont pas détectés assez rapidement, les signaux de l'expérience utilisateur et les classements de recherche organiques ont peu de chances d'atteindre leur plein potentiel.

Bien que Google soit enclin à explorer toutes les informations disponibles et à réexplorer régulièrement les modèles d'URL déjà connus, ses ressources d'exploration ne sont pas illimitées. C'est pourquoi, pour les grands sites Web composés de centaines de milliers de pages de destination, les cycles de re-crawl dépendent des algorithmes d'attribution des priorités de crawl de Google.
Cette allocation peut être positivement stimulée par des services Web fiables et hautement réactifs, optimisés spécifiquement pour une expérience rapide. Ces étapes à elles seules sont propices au référencement. Cependant, ce n'est qu'en analysant les journaux de serveur complets qui couvrent une période prolongée qu'il est possible d'identifier le degré de chevauchement entre le volume total de toutes les pages de destination explorables, le nombre généralement plus petit de pages de destination SEO pertinentes, optimisées et indexables représentées dans le plan du site et ce que Google priorise régulièrement pour l'exploration, l'indexation et le classement.
Une telle analyse de journal fait partie intégrante d'un audit SEO technique et est la seule méthode pour découvrir le degré de gaspillage du budget de crawl. Et qu'il s'agisse d'un filtrage explorable, d'un espace réservé ou de pages de contenu allégées, d'un serveur de mise en scène ouvert ou d'autres parties obsolètes du site Web, cela continue d'entraver l'exploration et, en fin de compte, les classements. Dans certaines circonstances, comme une migration planifiée, ce sont spécifiquement les informations obtenues grâce à un audit SEO, y compris l'analyse des journaux de serveur, qui font souvent la différence entre le succès et l'échec de la migration.

De plus, l'analyse des journaux offre aux grands sites Web des informations SEO critiques. Il peut fournir une réponse au temps dont Google a besoin pour réexplorer l'intégralité du site Web . Si cette réponse s'avère décisivement longue - des mois ou plus - une action peut être justifiée pour s'assurer que les pages de destination SEO indexables sont explorées. Sinon, il y a un grand risque que toute amélioration du référencement du site Web passe inaperçue des moteurs de recherche pendant des mois après sa publication, ce qui à son tour est une recette pour un mauvais classement.
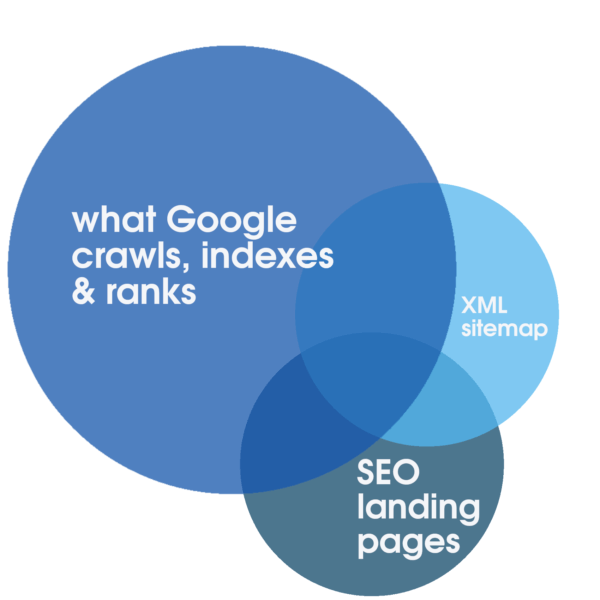
Les réponses du serveur sont essentielles pour une excellente visibilité de la recherche Google. Bien que Google Search Console offre un aperçu important des réponses récentes du serveur, toutes les données que Google Search Console offre aux opérateurs de sites Web doivent être considérées comme un échantillon représentatif, mais limité. Bien que cela puisse être utile pour identifier les problèmes flagrants, avec une analyse du journal du serveur, il est possible d'analyser et d'identifier toutes les réponses HTTP, y compris toutes les réponses non-200 OK quantitativement pertinentes qui peuvent compromettre les classements. Les réponses alternatives possibles peuvent indiquer des problèmes de performances (par exemple, 503 Service non disponible, temps d'arrêt programmé) si elles sont excessives.

Par où commencer
Malgré le potentiel que l'analyse des journaux de serveur a à offrir, la plupart des opérateurs de sites Web ne profitent pas des opportunités présentées. Les journaux du serveur ne sont pas du tout enregistrés ou sont régulièrement écrasés ou incomplets. L'écrasante majorité des sites Web ne conservent pas les données du journal du serveur pendant une période significative. C'est une bonne nouvelle pour tous les opérateurs qui souhaitent, contrairement à leurs concurrents, collecter et utiliser les fichiers journaux du serveur pour l'optimisation des moteurs de recherche.
Lors de la planification de la collecte des données du journal du serveur, il convient de noter quels champs de données au minimum doivent être conservés dans les fichiers journaux du serveur pour que les données soient utilisables. La liste suivante peut être considérée comme une ligne directrice :
- adresse IP distante de l'entité requérante.
- chaîne d'agent utilisateur de l'entité demandeuse.
- schéma de requête (par exemple, la requête HTTP était-elle pour http ou https ou wss ou autre chose).
- nom d'hôte de la requête (par exemple, pour quel sous-domaine ou domaine était la requête HTTP).
- chemin de la requête, il s'agit souvent du chemin du fichier sur le serveur sous la forme d'une URL relative.
- paramètres de demande, qui peuvent faire partie du chemin de la demande.
- l'heure de la demande, y compris la date, l'heure et le fuseau horaire.
- méthode de demande.
- code d'état http de la réponse.
- délais de réponse.
Si le chemin de la requête est une URL relative, les champs souvent négligés dans les fichiers journaux du serveur sont l'enregistrement du nom d'hôte et du schéma de la requête. C'est pourquoi il est important de vérifier auprès de votre service informatique si le chemin de la requête est une URL relative afin que le nom d'hôte et le schéma soient également enregistrés dans les fichiers journaux du serveur. Une solution de contournement simple consiste à enregistrer l'intégralité de l'URL de la demande dans un seul champ, qui inclut le schéma, le nom d'hôte, le chemin et les paramètres dans une seule chaîne.
Lors de la collecte des fichiers journaux du serveur, il est également important d'inclure les journaux provenant des CDN et d'autres services tiers que le site Web peut utiliser. Vérifiez régulièrement auprès de ces services tiers comment extraire et enregistrer les fichiers journaux.
Surmonter les obstacles à l'analyse des journaux de serveur
Souvent, deux obstacles principaux sont mis en avant pour contrer le besoin urgent de conserver les données des logs des serveurs : le coût et les préoccupations juridiques. Bien que les deux facteurs soient en fin de compte déterminés par des circonstances individuelles, telles que la budgétisation et la compétence juridique, aucun ne doit constituer un obstacle sérieux.
Le stockage dans le cloud peut être une option à long terme et le stockage matériel physique est également susceptible de limiter les coûts. Avec des prix de détail pour environ 20 To de disques durs inférieurs à 600 USD, le coût du matériel est négligeable. Étant donné que le prix du matériel de stockage est en baisse depuis des années, il est peu probable que le coût du stockage pose un défi sérieux à l'enregistrement des journaux de serveur.
De plus, il y aura un coût associé au logiciel d'analyse de journaux ou au fournisseur d'audit SEO rendant le service. Bien que ces coûts doivent être pris en compte dans le budget, une fois de plus, il est facile de justifier à la lumière des avantages offerts par l'analyse des journaux de serveur.
Bien que cet article vise à décrire les avantages inhérents à l'analyse des journaux de serveur pour le référencement, il ne doit pas être considéré comme une recommandation légale. Ces conseils juridiques ne peuvent être donnés que par un avocat qualifié dans le cadre du cadre juridique et de la juridiction compétente. Un certain nombre de lois et réglementations telles que GDPR/CCPA/DSGVO peuvent s'appliquer dans ce contexte. Surtout lorsque vous opérez depuis l'UE, la confidentialité est une préoccupation majeure. Cependant, dans le cadre d'une analyse du journal du serveur pour le référencement, toute donnée relative à l'utilisateur n'est pas pertinente. Tous les enregistrements qui ne peuvent pas être vérifiés de manière concluante sur la base de l'adresse IP doivent être ignorés.
En ce qui concerne les problèmes de confidentialité, toutes les données de journal qui ne sont pas validées et qui ne sont pas un robot de moteur de recherche confirmé ne doivent pas être utilisées et peuvent à la place être supprimées ou rendues anonymes après une période de temps définie en fonction des recommandations légales pertinentes. Cette approche éprouvée est régulièrement appliquée par certains des plus grands opérateurs de sites Web.
Quand commencer
La principale question qui reste est de savoir quand commencer à collecter les données du journal du serveur. La réponse est maintenant !
Les données du journal du serveur ne peuvent être appliquées de manière significative et conduire à des conseils exploitables que si elles sont disponibles en volume suffisant. La masse critique de l'utilité des journaux de serveur pour les audits SEO varie généralement entre six et trente-six mois, selon la taille d'un site Web et ses signaux de priorisation d'exploration.
Il est important de noter que les journaux de serveur non enregistrés ne peuvent pas être acquis ultérieurement. Il y a de fortes chances que tous les efforts entrepris aujourd'hui pour conserver et préserver les journaux des serveurs portent leurs fruits dès l'année suivante. Par conséquent, la collecte des données du journal du serveur doit commencer le plus tôt possible et se poursuivre sans interruption tant que le site Web est opérationnel et vise à bien fonctionner dans la recherche organique.
Les opinions exprimées dans cet article sont celles de l'auteur invité et pas nécessairement Search Engine Land. Les auteurs du personnel sont répertoriés ici.