
Dlaczego logi serwera są ważne dla SEO
Opublikowany: 2022-01-11Większość operatorów serwisów nie zdaje sobie sprawy z wagi logów serwera WWW. Nie rejestrują, a tym bardziej nie analizują logów serwera swojej witryny. W szczególności duże marki nie wykorzystują analizy dzienników serwera i bezpowrotnie tracą niezarejestrowane dane dziennika serwera.
Organizacje, które decydują się na analizę dzienników serwera w ramach swoich bieżących działań SEO, często przodują w wyszukiwarce Google. Jeśli Twoja witryna składa się ze 100 000 stron lub więcej i chcesz dowiedzieć się, w jaki sposób i dlaczego logi serwera stanowią ogromną szansę na rozwój, czytaj dalej.
Dlaczego logi serwera są ważne
Za każdym razem, gdy bot żąda adresu URL hostowanego na serwerze sieciowym, automatycznie tworzony jest wpis w dzienniku odzwierciedlający informacje wymieniane w tym procesie. W przypadku dłuższego okresu logi serwera odzwierciedlają historię otrzymanych żądań i zwróconych odpowiedzi.
Informacje przechowywane w plikach dziennika serwera zazwyczaj obejmują adres IP klienta, datę i godzinę żądania, żądany adres URL strony, kod odpowiedzi HTTP, ilość obsługiwanych bajtów, a także agenta użytkownika i stronę odsyłającą.
Podczas gdy logi serwera są tworzone za każdym razem, gdy żądana jest strona internetowa, w tym żądania przeglądarki użytkownika, optymalizacja pod kątem wyszukiwarek koncentruje się wyłącznie na wykorzystaniu danych dziennika serwera botów. Jest to istotne w odniesieniu do rozważań prawnych dotyczących ram ochrony danych, takich jak RODO/CCPA/DSGVO. Ponieważ żadne dane użytkownika nie są nigdy dołączane do celów SEO, surowa, anonimowa analiza dzienników serwera internetowego pozostaje nieobciążona innymi potencjalnie obowiązującymi przepisami prawnymi.
Warto wspomnieć, że do pewnego stopnia podobne spostrzeżenia są możliwe na podstawie statystyk indeksowania Google Search Console. Jednak te próbki mają ograniczoną objętość i zakres czasowy. W przeciwieństwie do Google Search Console, którego dane odzwierciedlają tylko ostatnie kilka miesięcy, to wyłącznie pliki dziennika serwera zapewniają jasny, duży obraz przedstawiający długoterminowe trendy SEO.
Cenne dane w logach serwera
Za każdym razem, gdy bot żąda strony hostowanej na serwerze, tworzona jest instancja dziennika rejestrująca liczbę punktów danych, w tym:
- Adres IP żądającego klienta.
- Dokładny czas żądania, często oparty na wewnętrznym zegarze serwera.
- Żądany adres URL.
- W żądaniu użyto protokołu HTTP.
- Zwrócony kod statusu odpowiedzi (np. 200, 301, 404, 500 lub inny).
- Ciąg agenta użytkownika z żądającej jednostki (np. nazwa bota wyszukiwarki, taka jak Googlebot/2.1).
Typowy przykładowy rekord dziennika serwera może wyglądać tak:
150.174.193.196 - - [15/Dec/2021:11:25:14 +0100] "GET /index.html HTTP/1.0" 200 1050 "-" "Googlebot/2.1 (+http://www.google.com/bot.html)" "www.example.ai"
W tym przykładzie:
-
150.174.193.196to IP podmiotu wnioskującego.
-
[15/Dec/2021:11:25:14 +0100]to strefa czasowa oraz czas żądania.
-
"GET /index.html HTTP/1.0"to używana metoda HTTP (GET), żądany plik (index.html) i używana wersja protokołu HTTP.
-
200to zwrócona odpowiedź kodu statusu HTTP serwera.
-
1050to rozmiar odpowiedzi serwera w bajtach.
-
"Googlebot/2.1 (+http://www.google.com/bot.html)"to klient użytkownika podmiotu żądającego.
-
"www.example.ai"to odsyłający adres URL.
Jak korzystać z logów serwera
Z punktu widzenia SEO istnieją trzy główne powody, dla których logi serwera WWW zapewniają niezrównany wgląd:
- Pomoc w filtrowaniu niepożądanego ruchu botów bez znaczenia dla SEO z pożądanego ruchu botów wyszukiwarek pochodzącego z legalnych botów, takich jak Googlebot, Bingbot lub YandexBot.
- Zapewnienie wglądu w SEO na temat priorytetów indeksowania, a tym samym umożliwienie zespołowi SEO aktywnego dostosowywania i dostrajania zarządzania budżetem indeksowania.
- Umożliwienie monitorowania i udostępnianie historii odpowiedzi serwera wysyłanych do wyszukiwarek.
Fałszywe boty wyszukiwarek mogą być uciążliwe, ale rzadko wpływają na strony internetowe. Istnieje wielu wyspecjalizowanych dostawców usług, takich jak Cloudflare i AWS Shield, którzy mogą pomóc w zarządzaniu niepożądanym ruchem botów. W procesie analizy dzienników serwera WWW fałszywe boty wyszukiwarek odgrywają podrzędną rolę.
Aby dokładnie określić, które części witryny mają priorytet, inne niż główne wyszukiwarki, ruch botów musi zostać odfiltrowany podczas przeprowadzania analizy logów. W zależności od rynków docelowych można skupić się na botach wyszukiwarek, takich jak Google, Apple, Bing, Yandex lub inne.
Szczególnie w przypadku witryn, w których aktualność treści jest kluczowa, częstotliwość ponownego indeksowania tych witryn może mieć krytyczny wpływ na ich przydatność dla użytkowników. Innymi słowy, jeśli zmiany treści nie zostaną wyłapane wystarczająco szybko, sygnały dotyczące doświadczenia użytkownika i rankingi bezpłatnych wyników wyszukiwania prawdopodobnie nie osiągną pełnego potencjału.

Chociaż Google jest skłonny indeksować wszystkie dostępne informacje i regularnie ponownie indeksować znane wzorce adresów URL, jego zasoby indeksowania nie są nieograniczone. Dlatego w przypadku dużych witryn składających się z setek tysięcy stron docelowych cykle ponownego indeksowania zależą od algorytmów alokacji priorytetów indeksowania Google.
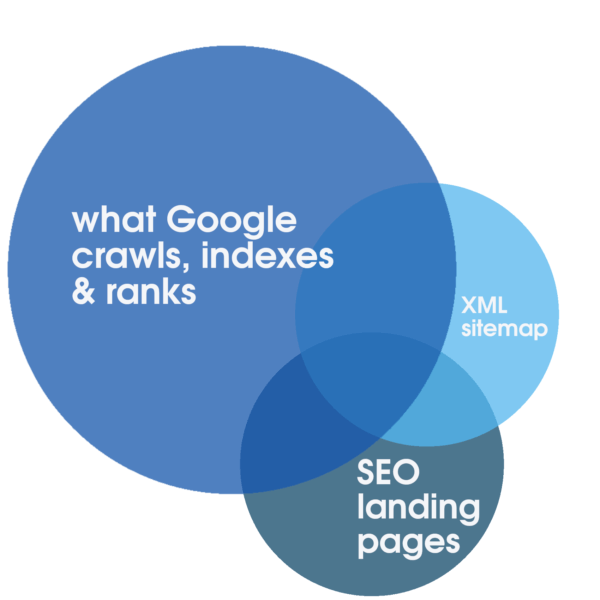
Ta alokacja może być pozytywnie stymulowana dzięki niezawodnym, wysoce responsywnym usługom internetowym, zoptymalizowanym specjalnie pod kątem szybkości działania. Same te kroki sprzyjają SEO. Jednak tylko analizując pełne dzienniki serwera, które obejmują dłuższy okres czasu, można określić stopień pokrywania się całkowitej liczby wszystkich możliwych do zindeksowania stron docelowych, czyli zazwyczaj mniejszej liczby odpowiednich, zoptymalizowanych i indeksowalnych stron docelowych SEO reprezentowanych w mapa witryny i to, co Google regularnie traktuje priorytetowo do przeszukiwania, indeksowania i rankingu.
Taka analiza logów jako integralna część audytu technicznego SEO i jedyna metoda na wykrycie stopnia marnotrawstwa crawl budget. Niezależnie od tego, czy filtrowanie indeksowane, strony zastępcze lub strony z ubogą zawartością, otwarty serwer pomostowy lub inne przestarzałe części witryny nadal pogarszają indeksowanie i ostatecznie rankingi. W pewnych okolicznościach, takich jak planowana migracja, to właśnie spostrzeżenia uzyskane podczas audytu SEO, w tym analizy dzienników serwera, często decydują o sukcesie lub porażce migracji.
Dodatkowo analiza logów oferuje dla dużych witryn krytycznych wgląd w SEO. Może dostarczyć odpowiedzi na pytanie, ile czasu potrzebuje Google na ponowne zindeksowanie całej witryny . Jeśli ta odpowiedź jest zdecydowanie długa — miesiące lub dłużej — może być uzasadnione podjęcie działań w celu upewnienia się, że indeksowalne strony docelowe SEO są indeksowane. W przeciwnym razie istnieje duże ryzyko, że jakiekolwiek ulepszenia SEO w witrynie pozostaną niezauważone przez wyszukiwarki przez potencjalne miesiące po wydaniu, co z kolei jest receptą na słabe rankingi.

Odpowiedzi serwera mają kluczowe znaczenie dla doskonałej widoczności w wyszukiwarce Google. Chociaż Google Search Console zapewnia ważny wgląd w ostatnie odpowiedzi serwerów, wszelkie dane, które Google Search Console oferuje operatorom witryn, należy traktować jako reprezentatywną, ale ograniczoną próbkę. Chociaż może to być przydatne do identyfikowania rażących problemów, dzięki analizie dziennika serwera można przeanalizować i zidentyfikować wszystkie odpowiedzi HTTP, w tym wszelkie ilościowo istotne odpowiedzi inne niż 200 OK, które mogą zagrozić rankingom. Możliwe alternatywne odpowiedzi mogą wskazywać na problemy z wydajnością (np. zaplanowany przestój 503 Usługa niedostępna), jeśli są nadmierne.

Od czego zacząć
Pomimo potencjału, jaki ma do zaoferowania analiza logów serwera, większość operatorów witryn nie wykorzystuje przedstawionych możliwości. Logi serwera albo nie są w ogóle rejestrowane, albo są regularnie nadpisywane lub niekompletne. Zdecydowana większość witryn internetowych nie przechowuje danych dziennika serwera przez jakikolwiek znaczący okres czasu. To dobra wiadomość dla wszystkich operatorów, którzy, w przeciwieństwie do swoich konkurentów, chcą zbierać i wykorzystywać pliki dzienników serwera do optymalizacji pod kątem wyszukiwarek.
Planując gromadzenie danych z dziennika serwera, warto zwrócić uwagę, które pola danych muszą być przynajmniej zachowane w plikach dziennika serwera, aby można było z nich korzystać. Poniższą listę można uznać za wskazówkę:
- zdalny adres IP podmiotu wnioskującego.
- ciąg agenta użytkownika żądającej jednostki.
- schemat żądania (np. było żądanie HTTP dla http, https, wss lub czegoś innego).
- nazwa hosta żądania (np. dla której poddomeny lub domeny było żądanie HTTP).
- ścieżka żądania, często jest to ścieżka pliku na serwerze jako względny adres URL.
- parametry żądania, które mogą być częścią ścieżki żądania.
- czas żądania, w tym datę, godzinę i strefę czasową.
- metoda żądania.
- kod statusu odpowiedzi http.
- czasy odpowiedzi.
Jeśli ścieżka żądania jest względnym adresem URL, pola, które są często pomijane w plikach dziennika serwera, to zapis nazwy hosta i schematu żądania. Dlatego ważne jest, aby sprawdzić w dziale IT, czy ścieżka żądania jest względnym adresem URL, aby nazwa hosta i schemat były również zapisywane w plikach dziennika serwera. Prostym obejściem jest zapisanie całego adresu URL żądania w jednym polu, które zawiera schemat, nazwę hosta, ścieżkę i parametry w jednym ciągu.
Podczas gromadzenia plików dzienników serwera, ważne jest również, aby uwzględnić dzienniki pochodzące z sieci CDN i innych usług stron trzecich, z których może korzystać witryna. Skontaktuj się z tymi usługami innych firm, aby dowiedzieć się, jak regularnie wyodrębniać i zapisywać pliki dziennika.
Pokonywanie przeszkód w analizie logów serwera
Często stawia się dwie główne przeszkody, aby przeciwdziałać pilnej potrzebie przechowywania danych dziennika serwera: koszty i kwestie prawne. Chociaż oba czynniki są ostatecznie determinowane przez indywidualne okoliczności, takie jak budżet i jurysdykcja, żaden z nich nie musi stanowić poważnej przeszkody.
Przechowywanie w chmurze może być opcją długoterminową, a fizyczne przechowywanie sprzętu również prawdopodobnie ograniczy koszty. Przy cenach detalicznych około 20 TB dysków twardych poniżej 600 USD, koszt sprzętu jest znikomy. Biorąc pod uwagę, że cena sprzętu do przechowywania danych spadała od lat, ostatecznie jest mało prawdopodobne, aby koszt przechowywania stanowił poważne wyzwanie dla rejestrowania logów serwera.
Dodatkowo pojawi się koszt związany z oprogramowaniem do analizy logów lub dostawcą audytu SEO świadczącym usługę. Chociaż koszty te należy uwzględnić w budżecie, ponownie łatwo je uzasadnić w świetle korzyści, jakie oferuje analiza logów serwera.
Chociaż ten artykuł ma na celu przedstawienie nieodłącznych korzyści płynących z analizy dzienników serwera dla SEO, nie należy go traktować jako zalecenia prawnego. Takiej porady prawnej może udzielić wyłącznie wykwalifikowany prawnik w kontekście ram prawnych i odpowiedniej jurysdykcji. W tym kontekście może mieć zastosowanie szereg przepisów ustawowych i wykonawczych, takich jak RODO/CCPA/DSGVO. Szczególnie w przypadku działalności z UE prywatność jest poważnym problemem. Jednak w celu analizy logów serwera pod kątem SEO, wszelkie dane związane z użytkownikiem nie mają znaczenia. Wszelkie rekordy, których nie można jednoznacznie zweryfikować na podstawie adresu IP, należy zignorować.
W odniesieniu do kwestii prywatności, wszelkie dane dziennika, które nie potwierdzają i nie są potwierdzonym botem wyszukiwarki, nie mogą być używane, a zamiast tego mogą zostać usunięte lub zanonimizowane po określonym czasie w oparciu o odpowiednie zalecenia prawne. To wypróbowane i przetestowane podejście jest regularnie stosowane przez niektórych największych operatorów witryn internetowych.
Kiedy zacząć
Pozostaje główne pytanie, kiedy rozpocząć zbieranie danych dziennika serwera. Odpowiedź jest teraz!
Dane dziennika serwera mogą być stosowane w sensowny sposób i prowadzić do praktycznych porad, jeśli są dostępne w wystarczającej ilości. Masa krytyczna przydatności dzienników serwera do audytów SEO zwykle waha się od sześciu do trzydziestu sześciu miesięcy, w zależności od tego, jak duża jest strona internetowa i jej sygnały priorytetyzacji indeksowania.
Należy pamiętać, że niezarejestrowanych dzienników serwera nie można uzyskać na późniejszym etapie. Jest szansa, że wszelkie podjęte dzisiaj wysiłki mające na celu zachowanie i zachowanie logów serwera przyniosą owoce już w następnym roku. W związku z tym zbieranie danych dziennika serwera musi rozpocząć się jak najwcześniej i trwać nieprzerwanie tak długo, jak witryna działa i ma na celu dobre wyniki w wynikach wyszukiwania organicznego.
Opinie wyrażone w tym artykule są opiniami gościa i niekoniecznie Search Engine Land. Lista autorów personelu znajduje się tutaj.