
Por que os logs do servidor são importantes para SEO
Publicados: 2022-01-11A maioria dos operadores de sites desconhece a importância dos logs do servidor web. Eles não gravam, muito menos analisam os logs do servidor de seu site. As grandes marcas, em particular, não conseguem capitalizar na análise de log do servidor e perdem irremediavelmente dados de log do servidor não registrados.
As organizações que optam por adotar a análise de log do servidor como parte de seus esforços contínuos de SEO geralmente se destacam na Pesquisa do Google. Se o seu site consiste em 100.000 páginas ou mais e você deseja descobrir como e por que os logs do servidor representam uma tremenda oportunidade de crescimento, continue lendo.
Por que os logs do servidor são importantes
Cada vez que um bot solicita uma URL hospedada em um servidor web, uma entrada de registro de log é criada automaticamente refletindo as informações trocadas no processo. Ao cobrir um longo período de tempo, os logs do servidor tornam-se representativos do histórico de solicitações recebidas e das respostas retornadas.
As informações retidas nos arquivos de log do servidor geralmente incluem o endereço IP do cliente, a data e a hora da solicitação, a URL da página solicitada, o código de resposta HTTP, o volume de bytes atendidos, bem como o agente do usuário e o referenciador.
Embora os logs do servidor sejam criados em cada instância que uma página da Web é solicitada, incluindo solicitações do navegador do usuário, a otimização do mecanismo de pesquisa se concentra exclusivamente no uso de dados de log do servidor de bot. Isso é relevante no que diz respeito a considerações legais relacionadas a estruturas de proteção de dados, como GDPR/CCPA/DSGVO. Como nenhum dado do usuário é incluído para fins de SEO, a análise bruta e anônima do log do servidor da Web permanece livre de regulamentos legais potencialmente aplicáveis.
Vale ressaltar que, até certo ponto, são possíveis insights semelhantes com base nas estatísticas de rastreamento do Google Search Console. No entanto, essas amostras são limitadas em volume e intervalo de tempo coberto. Ao contrário do Google Search Console, com seus dados refletindo apenas os últimos meses, são exclusivamente os arquivos de log do servidor que fornecem uma imagem clara e ampla, descrevendo as tendências de SEO de longo prazo.
Os dados valiosos nos logs do servidor
Cada vez que um bot solicita uma página hospedada no servidor, uma instância de log é criada registrando vários pontos de dados, incluindo:
- O endereço IP do cliente solicitante.
- A hora exata da solicitação, geralmente baseada no relógio interno do servidor.
- O URL que foi solicitado.
- O HTTP foi usado para a solicitação.
- O código de status de resposta retornado (por exemplo, 200, 301, 404, 500 ou outro).
- A string do agente do usuário da entidade solicitante (por exemplo, um nome de bot de mecanismo de pesquisa como Googlebot/2.1).
Um exemplo típico de registro de log do servidor pode ter esta aparência:
150.174.193.196 - - [15/Dec/2021:11:25:14 +0100] "GET /index.html HTTP/1.0" 200 1050 "-" "Googlebot/2.1 (+http://www.google.com/bot.html)" "www.example.ai"
Neste exemplo:
-
150.174.193.196é o IP da entidade solicitante.
-
[15/Dec/2021:11:25:14 +0100]é o fuso horário e a hora da solicitação.
-
"GET /index.html HTTP/1.0"é o método HTTP utilizado (GET), o arquivo solicitado (index.html) e a versão do protocolo HTTP utilizada.
-
200é a resposta do código de status HTTP do servidor retornada.
-
1050é o tamanho do byte da resposta do servidor.
-
"Googlebot/2.1 (+http://www.google.com/bot.html)"é o agente do usuário da entidade solicitante.
-
"www.example.ai"é o URL de referência.
Como usar os logs do servidor
Do ponto de vista de SEO, existem três razões principais pelas quais os logs do servidor da Web fornecem informações incomparáveis:
- Ajudar a filtrar o tráfego de bots indesejável sem significado de SEO do tráfego de bots de mecanismos de pesquisa desejável originado de bots legítimos, como Googlebot, Bingbot ou YandexBot.
- Fornecendo insights de SEO sobre a priorização de rastreamento e, assim, permitindo que a equipe de SEO tenha a oportunidade de ajustar e ajustar proativamente seu gerenciamento de orçamento de rastreamento.
- Permitindo monitorar e fornecer um histórico das respostas do servidor enviadas aos mecanismos de pesquisa.
Bots de mecanismos de pesquisa falsos podem ser um incômodo, mas raramente afetam sites. Existem vários provedores de serviços especializados, como Cloudflare e AWS Shield, que podem ajudar no gerenciamento de tráfego de bots indesejados.
Para avaliar com precisão quais partes de um site estão sendo priorizadas, além dos principais mecanismos de pesquisa, o tráfego de bots deve ser filtrado ao realizar uma análise de log. Dependendo dos mercados visados, o foco pode ser em bots de mecanismos de busca como Google, Apple, Bing, Yandex ou outros.
Especialmente para sites em que a atualização do conteúdo é fundamental, a frequência com que esses sites são rastreados novamente pode afetar criticamente sua utilidade para os usuários. Em outras palavras, se as alterações de conteúdo não forem detectadas com rapidez suficiente, é improvável que os sinais de experiência do usuário e as classificações de pesquisa orgânica atinjam todo o seu potencial.

Embora o Google esteja inclinado a rastrear todas as informações disponíveis e rastrear novamente padrões de URL já conhecidos regularmente, seus recursos de rastreamento não são ilimitados. É por isso que, para sites grandes que consistem em centenas de milhares de páginas de destino, os ciclos de novo rastreamento dependem dos algoritmos de alocação de priorização de rastreamento do Google.
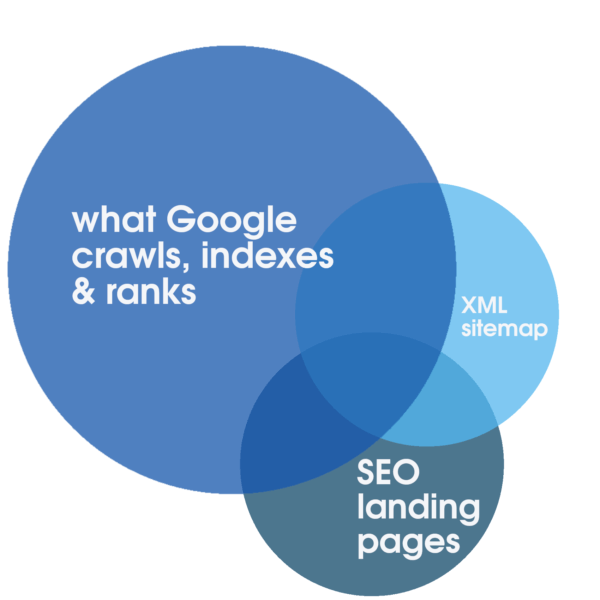
Essa alocação pode ser estimulada positivamente com serviços web confiáveis e altamente responsivos, otimizados especificamente para uma experiência rápida. Essas etapas por si só são propícias ao SEO. No entanto, somente analisando logs completos do servidor que cobrem um longo período de tempo é possível identificar o grau de sobreposição entre o volume total de todas as landing pages rastreáveis, o número tipicamente menor de landing pages SEO relevantes, otimizadas e indexáveis representadas no sitemap e o que o Google prioriza regularmente para rastreamento, indexação e classificação.
Essa análise de log é parte integrante de uma auditoria técnica de SEO e o único método para descobrir o grau de desperdício do orçamento de rastreamento. E se a filtragem rastreável, espaço reservado ou páginas de conteúdo enxutas, um servidor de teste aberto ou outras partes obsoletas do site continuam a prejudicar o rastreamento e, finalmente, as classificações. Sob certas circunstâncias, como uma migração planejada, são especificamente os insights obtidos por meio de uma auditoria de SEO, incluindo análise de log do servidor, que geralmente fazem a diferença entre o sucesso e o fracasso da migração.

Além disso, a análise de log oferece insights críticos de SEO para sites grandes. Ele pode fornecer uma resposta sobre quanto tempo o Google precisa para rastrear novamente todo o site . Se essa resposta for decisivamente longa – meses ou mais – a ação pode ser garantida para garantir que as páginas de destino de SEO indexáveis sejam rastreadas. Caso contrário, há um grande risco de que quaisquer melhorias de SEO no site passem despercebidas pelos mecanismos de pesquisa por potencialmente meses após o lançamento, o que, por sua vez, é uma receita para classificações ruins.
As respostas do servidor são essenciais para uma ótima visibilidade da Pesquisa Google. Embora o Google Search Console ofereça um vislumbre importante das respostas recentes do servidor, qualquer dado que o Google Search Console ofereça aos operadores de sites deve ser considerado uma amostra representativa, mas limitada. Embora isso possa ser útil para identificar problemas graves, com uma análise de log do servidor é possível analisar e identificar todas as respostas HTTP, incluindo quaisquer respostas não 200 OK quantitativamente relevantes que possam comprometer as classificações. As possíveis respostas alternativas podem ser indicativas de problemas de desempenho (por exemplo, tempo de inatividade programado 503 Serviço Indisponível) se forem excessivos.

Onde começar
Apesar do potencial que a análise de log do servidor tem a oferecer, a maioria dos operadores de sites não aproveita as oportunidades apresentadas. Os logs do servidor não são gravados ou substituídos regularmente ou incompletos. A esmagadora maioria dos sites não retém dados de log do servidor por um período significativo de tempo. Esta é uma boa notícia para qualquer operador disposto a, ao contrário de seus concorrentes, coletar e utilizar arquivos de log do servidor para otimização de mecanismos de pesquisa.
Ao planejar a coleta de dados de log do servidor, vale a pena observar quais campos de dados, no mínimo, devem ser retidos nos arquivos de log do servidor para que os dados possam ser usados. A lista a seguir pode ser considerada uma diretriz:
- endereço IP remoto da entidade solicitante.
- string do agente do usuário da entidade solicitante.
- esquema de solicitação (por exemplo, foi a solicitação HTTP para http ou https ou wss ou outra coisa).
- request hostname (por exemplo, para qual subdomínio ou domínio foi a solicitação HTTP).
- caminho de solicitação, geralmente esse é o caminho do arquivo no servidor como uma URL relativa.
- parâmetros de solicitação, que podem fazer parte do caminho da solicitação.
- hora da solicitação, incluindo data, hora e fuso horário.
- método de solicitação.
- código de status http de resposta.
- tempos de resposta.
Se o caminho da solicitação for uma URL relativa, os campos que geralmente são negligenciados nos arquivos de log do servidor são a gravação do nome do host e o esquema da solicitação. É por isso que é importante verificar com seu departamento de TI se o caminho da solicitação é uma URL relativa para que o nome do host e o esquema também sejam registrados nos arquivos de log do servidor. Uma solução fácil é registrar todo o URL de solicitação como um campo, que inclui o esquema, o nome do host, o caminho e os parâmetros em uma string.
Ao coletar arquivos de log do servidor, também é importante incluir logs originados de CDNs e outros serviços de terceiros que o site possa estar usando. Verifique com esses serviços de terceiros sobre como extrair e salvar os arquivos de log regularmente.
Superando obstáculos à análise de log do servidor
Muitas vezes, dois obstáculos principais são apresentados para combater a necessidade urgente de reter os dados de log do servidor: custo e preocupações legais. Embora ambos os fatores sejam determinados por circunstâncias individuais, como orçamento e jurisdição legal, nenhum deles deve representar um obstáculo sério.
O armazenamento em nuvem pode ser uma opção de longo prazo e o armazenamento de hardware físico também deve limitar o custo. Com preços de varejo para discos rígidos de aproximadamente 20 TB abaixo de US$ 600, o custo do hardware é insignificante. Dado que o preço do hardware de armazenamento está em declínio há anos, é improvável que o custo do armazenamento represente um sério desafio para a gravação de log do servidor.
Além disso, haverá um custo associado ao software de análise de log ou ao provedor de auditoria de SEO que presta o serviço. Embora esses custos devam ser incluídos no orçamento, mais uma vez é fácil justificar à luz das vantagens que a análise de log do servidor oferece.
Embora este artigo pretenda descrever os benefícios inerentes da análise de log do servidor para SEO, ele não deve ser considerado uma recomendação legal. Esse aconselhamento jurídico só pode ser prestado por um advogado qualificado no contexto do quadro jurídico e da jurisdição relevante. Várias leis e regulamentações como GDPR/CCPA/DSGVO podem ser aplicadas neste contexto. Especialmente ao operar na UE, a privacidade é uma grande preocupação. No entanto, para fins de análise de log do servidor para SEO, quaisquer dados relacionados ao usuário não são relevantes. Quaisquer registros que não possam ser verificados conclusivamente com base no endereço IP devem ser ignorados.
No que diz respeito a questões de privacidade, quaisquer dados de log que não validem e não sejam um bot de mecanismo de pesquisa confirmado não devem ser usados e, em vez disso, podem ser excluídos ou anonimizados após um período de tempo definido com base em recomendações legais relevantes. Essa abordagem testada e comprovada está sendo aplicada regularmente por alguns dos maiores operadores de sites.
Quando começar
A principal questão restante é quando começar a coletar dados de log do servidor. A resposta é agora!
Os dados de log do servidor só podem ser aplicados de maneira significativa e levar a conselhos acionáveis se estiverem disponíveis em volume suficiente. A massa crítica da utilidade dos logs do servidor para auditorias de SEO geralmente varia entre seis e trinta e seis meses, dependendo do tamanho de um site e de seus sinais de priorização de rastreamento.
É importante observar que logs de servidor não registrados não podem ser adquiridos posteriormente. As chances são de que quaisquer esforços para reter e preservar os logs do servidor iniciados hoje renderão frutos já no ano seguinte. Portanto, a coleta de dados de log do servidor deve começar o mais cedo possível e continuar ininterruptamente enquanto o site estiver em operação e tiver um bom desempenho na pesquisa orgânica.
As opiniões expressas neste artigo são do autor convidado e não necessariamente do Search Engine Land. Os autores da equipe estão listados aqui.