
Transizione da Excel a Python: funzioni essenziali per l'analisi dei dati SEO
Pubblicato: 2022-12-02Imparare a programmare, sia con Python, JavaScript o un altro linguaggio di programmazione, ha tutta una serie di vantaggi, inclusa la capacità di lavorare con set di dati più grandi e automatizzare le attività ripetitive.
Ma nonostante i vantaggi, molti professionisti SEO devono ancora effettuare la transizione e capisco perfettamente perché! Non è un'abilità essenziale per il SEO e siamo tutti persone impegnate.
Se hai poco tempo e sai già come eseguire un'attività all'interno di Excel o Fogli Google, cambiare virata può sembrare come reinventare la ruota.
Quando ho iniziato a programmare per la prima volta, inizialmente ho utilizzato Python solo per attività che non potevo eseguire in Excel e ci sono voluti diversi anni per arrivare al punto in cui è la mia scelta di fatto per l'elaborazione dei dati.
Guardando indietro, sono incredibilmente contento di aver insistito, ma a volte è stata un'esperienza frustrante, con molte ore trascorse a scansionare i thread su Stack Overflow.
Questo post è progettato per risparmiare ad altri professionisti SEO la stessa sorte.
Al suo interno, tratteremo gli equivalenti Python delle formule e delle funzionalità di Excel più comunemente utilizzate per l'analisi dei dati SEO, tutte disponibili all'interno di un taccuino di Google Colab collegato nel riepilogo.
In particolare, imparerai gli equivalenti di:
- LEN.
- Elimina i duplicati.
- Testo in colonne.
- CERCA/TROVA.
- CONCATENARE.
- Trova e sostituisci.
- SINISTRA/MEDIO/DESTRA.
- SE.
- IFS.
- CERCA.VERT.
- CONTA.SE/SOMMA.SE/MEDIA.SE.
- Tabelle pivot.
Sorprendentemente, per realizzare tutto questo, utilizzeremo principalmente una singola libreria - Pandas - con un piccolo aiuto in alcuni punti dal suo fratello maggiore, NumPy.
Prerequisiti
Per brevità, ci sono alcune cose che non tratteremo oggi, tra cui:
- Installazione di Python.
- Panda di base, come l'importazione di CSV, il filtraggio e l'anteprima dei dataframe.
Se non sei sicuro di tutto ciò, la guida di Amleto sull'analisi dei dati di Python per la SEO è l'introduzione perfetta.
Ora, senza ulteriori indugi, entriamo.
LEN
LEN fornisce un conteggio del numero di caratteri all'interno di una stringa di testo.
Per la SEO in particolare, un caso d'uso comune è misurare la lunghezza dei tag del titolo o delle meta descrizioni per determinare se verranno troncati nei risultati di ricerca.
All'interno di Excel, se volessimo contare la seconda cella della colonna A, inseriremmo:
=LUNGHEZZA(A2)
 Screenshot da Microsoft Excel, novembre 2022
Screenshot da Microsoft Excel, novembre 2022
Python non è molto dissimile, poiché possiamo fare affidamento sulla funzione len incorporata, che può essere combinata con loc[] di Pandas per accedere a una specifica riga di dati all'interno di una colonna:
len(df['Titolo'].loc[0])
In questo esempio, otteniamo la lunghezza della prima riga nella colonna "Title" del nostro dataframe.

- Screenshot di VS Code, novembre 2022
Tuttavia, trovare la lunghezza di una cella non è così utile per la SEO. Normalmente, vorremmo applicare una funzione a un'intera colonna!
In Excel, ciò si ottiene selezionando la cella della formula nell'angolo in basso a destra e trascinandola verso il basso o facendo doppio clic.
Quando lavoriamo con un dataframe Pandas, possiamo usare str.len per calcolare la lunghezza delle righe all'interno di una serie, quindi archiviare i risultati in una nuova colonna:
df['Lunghezza'] = df['Titolo'].str.len()
Str.len è un'operazione 'vettorizzata', progettata per essere applicata simultaneamente a una serie di valori. Useremo ampiamente queste operazioni in questo articolo, poiché quasi universalmente finiscono per essere più veloci di un ciclo.
Un'altra applicazione comune di LEN è combinarla con SUBSTITUTE per contare il numero di parole in una cella:
=LUNGHEZZA(TRIM(A2))-LUNGHEZZA(SOSTITUZIONE(A2," ",""))+1
In Pandas, possiamo ottenere questo risultato combinando insieme le funzioni str.split e str.len:
df['No. Parole'] = df['Titolo'].str.split().str.len()
Tratteremo str.split in modo più dettagliato in seguito, ma essenzialmente, quello che stiamo facendo è dividere i nostri dati in base agli spazi bianchi all'interno della stringa, quindi contare il numero di parti componenti.
 Screenshot da VS Code, novembre 2022
Screenshot da VS Code, novembre 2022
Eliminazione di duplicati
La funzione "Rimuovi duplicati" di Excel fornisce un modo semplice per rimuovere i valori duplicati all'interno di un set di dati, eliminando le righe completamente duplicate (quando tutte le colonne sono selezionate) o rimuovendo le righe con gli stessi valori in colonne specifiche.
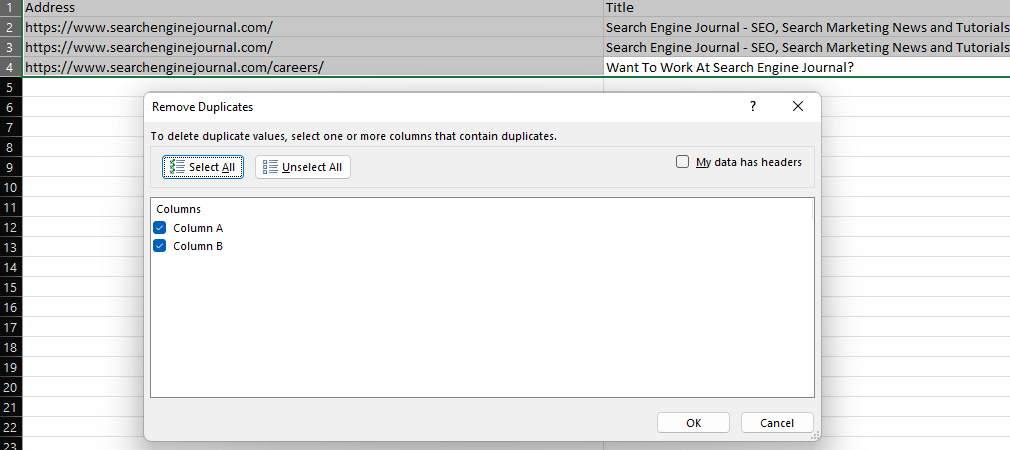 Screenshot da Microsoft Excel, novembre 2022
Screenshot da Microsoft Excel, novembre 2022
In Pandas, questa funzionalità è fornita da drop_duplicates.
Per eliminare le righe duplicate all'interno di un tipo di frame di dati:
df.drop_duplicates(inplace=True)
Per eliminare le righe in base ai duplicati all'interno di una singola colonna, includi il parametro subset:
df.drop_duplicates(subset='colonna', inplace=True)
Oppure specifica più colonne all'interno di un elenco:
df.drop_duplicates(subset=['column','column2'], inplace=True)
Un'aggiunta sopra che vale la pena richiamare è la presenza del parametro inplace. L'inclusione di inplace=True ci consente di sovrascrivere il nostro dataframe esistente senza doverne creare uno nuovo.
Ci sono, ovviamente, momenti in cui vogliamo preservare i nostri dati grezzi. In questo caso, possiamo assegnare il nostro dataframe deduplicato a una variabile diversa:
df2 = df.drop_duplicates(sottoinsieme='colonna')
Testo in colonne
Un altro elemento essenziale di tutti i giorni, la funzione "testo in colonne" può essere utilizzata per dividere una stringa di testo in base a un delimitatore, come una barra, una virgola o uno spazio bianco.
Ad esempio, suddividere un URL nel suo dominio e nelle singole sottocartelle.
 Screenshot da Microsoft Excel, novembre 2022
Screenshot da Microsoft Excel, novembre 2022
Quando abbiamo a che fare con un dataframe, possiamo usare la funzione str.split, che crea un elenco per ogni voce all'interno di una serie. Questo può essere convertito in più colonne impostando il parametro expand su True:
df['URL'].str.split(pat='/', expand=True)
 Screenshot da VS Code, novembre 2022
Screenshot da VS Code, novembre 2022
Come spesso accade, i nostri URL nell'immagine sopra sono stati suddivisi in colonne incoerenti, perché non presentano lo stesso numero di cartelle.
Questo può rendere le cose complicate quando vogliamo salvare i nostri dati all'interno di un dataframe esistente.
La specifica del parametro n limita il numero di suddivisioni, consentendoci di creare un numero specifico di colonne:
df[['Dominio', 'Cartella1', 'Cartella2', 'Cartella3']] = df['URL'].str.split(pat='/', expand=True, n=3)
Un'altra opzione è utilizzare pop per rimuovere la colonna dal dataframe, eseguire la divisione e quindi aggiungerla nuovamente con la funzione join:
df = df.join(df.pop('Split').str.split(pat='/', expand=True))La duplicazione dell'URL in una nuova colonna prima della divisione ci consente di conservare l'URL completo. Possiamo quindi rinominare le nuove colonne:🐆
df['Dividi'] = df['URL']
df = df.join(df.pop('Split').str.split(pat='/', expand=True))
df.rename(colonne = {0:'Dominio', 1:'Cartella1', 2:'Cartella2', 3:'Cartella3', 4:'Parametro'}, inplace=True) 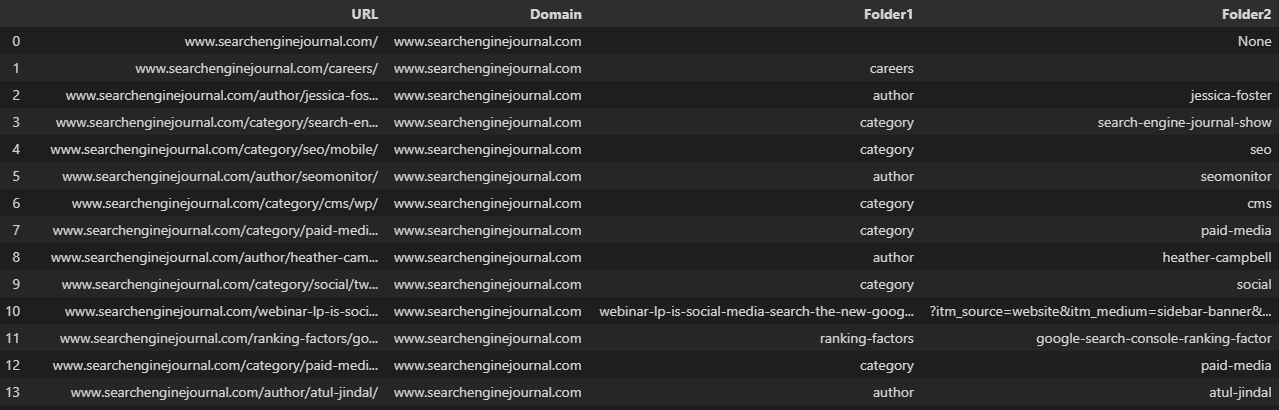 Screenshot da VS Code, novembre 2022
Screenshot da VS Code, novembre 2022
CONCATENARE
La funzione CONCAT consente agli utenti di combinare più stringhe di testo, ad esempio quando si genera un elenco di parole chiave aggiungendo diversi modificatori.
In questo caso, stiamo aggiungendo "mens" e spazi bianchi all'elenco dei tipi di prodotto della colonna A:
=CONC.($F$1," ",A2)

- Screenshot da Microsoft Excel, novembre 2022
Supponendo che abbiamo a che fare con stringhe, lo stesso può essere ottenuto in Python usando l'operatore aritmetico:
df['Combinato] = 'mens' + ' ' + df['Parola chiave']
Oppure specifica più colonne di dati:
df['Combinato'] = df['Sottodominio'] + df['URL']
 Screenshot da VS Code, novembre 2022
Screenshot da VS Code, novembre 2022
Pandas ha una funzione concat dedicata, ma questa è più utile quando si tenta di combinare più dataframe con le stesse colonne.
Ad esempio, se avessimo più esportazioni dal nostro strumento di analisi dei link preferito:
df = pd.read_csv('data.csv')
df2 = pd.read_csv('data2.csv')
df3 = pd.read_csv('data3.csv')
dflist = [df, df2, df3]
df = pd.concat(dflist, ignore_index=True)CERCA/TROVA
Le formule SEARCH e FIND forniscono un modo per localizzare una sottostringa all'interno di una stringa di testo.
Questi comandi sono comunemente combinati con ISNUMBER per creare una colonna booleana che aiuta a filtrare un set di dati, che può essere estremamente utile quando si eseguono attività come l'analisi dei file di registro, come spiegato in questa guida. Per esempio:
=VAL.NUMERO(CERCA("cerca questo",A2)  Screenshot da Microsoft Excel, novembre 2022
Screenshot da Microsoft Excel, novembre 2022
La differenza tra SEARCH e FIND è che find fa distinzione tra maiuscole e minuscole.
La funzione Pandas equivalente, str.contains, fa distinzione tra maiuscole e minuscole per impostazione predefinita:
df['Journal'] = df['URL'].str.contains('engine', na=False)La distinzione tra maiuscole e minuscole può essere abilitata impostando il parametro case su False:
df['Journal'] = df['URL'].str.contains('engine', case=False, na=False)In entrambi gli scenari, l'inclusione di na=False impedirà la restituzione di valori null all'interno della colonna booleana.
Un enorme vantaggio dell'utilizzo di Panda qui è che, a differenza di Excel, le espressioni regolari sono supportate nativamente da questa funzione, come nei fogli di Google tramite REGEXMATCH.
Concatena più sottostringhe utilizzando il carattere pipe, noto anche come operatore OR:
df['Journal'] = df['URL'].str.contains('engine|search', na=False)Trova e sostituisci
La funzione "Trova e sostituisci" di Excel fornisce un modo semplice per sostituire individualmente o in blocco una sottostringa con un'altra.
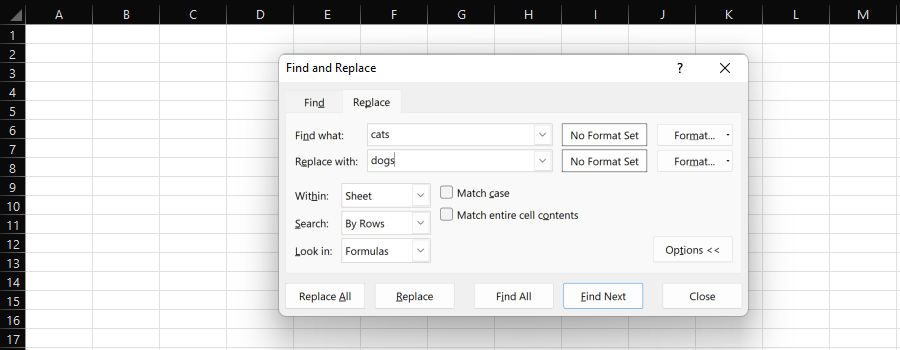 Screenshot da Microsoft Excel, novembre 2022
Screenshot da Microsoft Excel, novembre 2022
Durante l'elaborazione dei dati per la SEO, è molto probabile che selezioniamo un'intera colonna e "Sostituisci tutto".
La formula SUBSTITUTE fornisce un'altra opzione qui ed è utile se non si desidera sovrascrivere la colonna esistente.
Ad esempio, possiamo cambiare il protocollo di un URL da HTTP a HTTPS, oppure rimuoverlo sostituendolo con niente.
Quando lavoriamo con i dataframe in Python, possiamo usare str.replace:
df['URL'] = df['URL'].str.replace('http://', 'https://')O:
df['URL'] = df['URL'].str.replace('http://', '') # sostituisci con nienteAncora una volta, a differenza di Excel, è possibile utilizzare espressioni regolari, come con REGEXREPLACE di Fogli Google:
df['URL'] = df['URL'].str.replace('http://|https://', '')In alternativa, se desideri sostituire più sottostringhe con valori diversi, puoi utilizzare il metodo di sostituzione di Python e fornire un elenco.
Questo ti impedisce di dover concatenare più funzioni str.replace:
df['URL'] = df['URL'].replace(['http://', ' https://'], ['https://www.', 'https://www.' ], espressione regolare=Vero)
SINISTRA/MEDIO/DESTRA
L'estrazione di una sottostringa all'interno di Excel richiede l'utilizzo delle funzioni LEFT, MID o RIGHT, a seconda di dove si trova la sottostringa all'interno di una cella.

Supponiamo di voler estrarre il dominio principale e il sottodominio da un URL:
=MID(A2,TROVA(":",A2,4)+3,TROVA("/",A2,9)-TROVA(":",A2,4)-3) 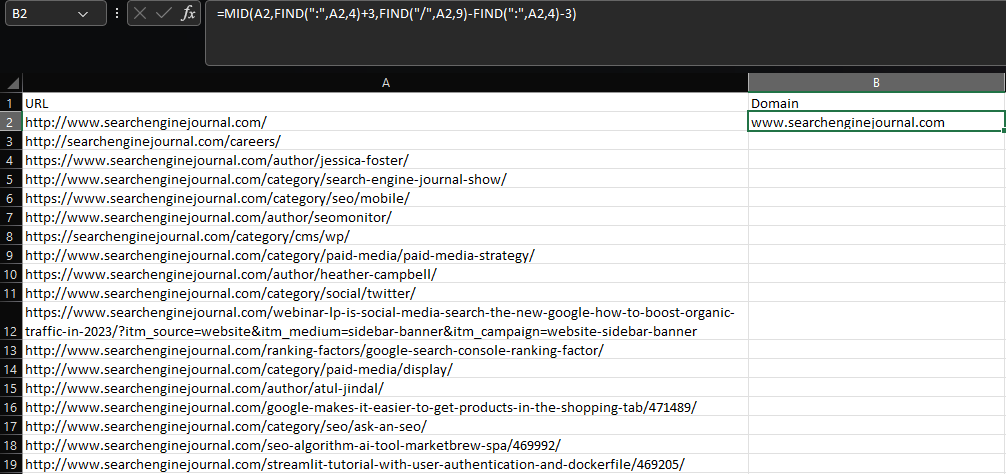 Screenshot da Microsoft Excel, novembre 2022
Screenshot da Microsoft Excel, novembre 2022
Utilizzando una combinazione di MID e molteplici funzioni FIND, questa formula è a dir poco brutta e le cose peggiorano molto per estrazioni più complesse.
Ancora una volta, Google Sheets lo fa meglio di Excel, perché ha REGEXEXTRACT.
Che peccato che quando gli dai da mangiare set di dati più grandi, si scioglie più velocemente di un Babybel su un termosifone caldo.
Per fortuna, Pandas offre str.extract, che funziona in modo simile:
df['Dominio'] = df['URL'].str.extract('.*\://?([^\/]+)')  Screenshot da VS Code, novembre 2022
Screenshot da VS Code, novembre 2022
Combina con fillna per evitare valori nulli, come faresti in Excel con IFERROR:
df['Dominio'] = df['URL'].str.extract('.*\://?([^\/]+)').fillna('-')Se
Le istruzioni IF consentono di restituire valori diversi, a seconda che una condizione sia soddisfatta o meno.
Per illustrare, supponiamo di voler creare un'etichetta per le parole chiave che si posizionano nelle prime tre posizioni.
 Screenshot da Microsoft Excel, novembre 2022
Screenshot da Microsoft Excel, novembre 2022
Piuttosto che usare Pandas in questo caso, possiamo appoggiarci a NumPy e alla funzione where (ricordati di importare NumPy, se non l'hai già fatto):
df['Primi 3'] = np.where(df['Posizione'] <= 3, 'Primi 3', 'Non Primi 3')
È possibile utilizzare più condizioni per la stessa valutazione utilizzando gli operatori AND/OR e racchiudendo i singoli criteri tra parentesi tonde:
df['Primi 3'] = np.where((df['Posizione'] <= 3) & (df['Posizione'] != 0), 'Primi 3', 'Non Primi 3')
In quanto sopra, restituiamo "Top 3" per tutte le parole chiave con un ranking inferiore o uguale a tre, escluse le parole chiave che si posizionano nella posizione zero.
IFS
A volte, invece di specificare più condizioni per la stessa valutazione, potresti volere più condizioni che restituiscono valori diversi.
In questo caso, la soluzione migliore è utilizzare IFS:
=IFS(B2<=3,"Primi 3",B2<=10,"Primi 10",B2<=20,"Primi 20")
 Screenshot da Microsoft Excel, novembre 2022
Screenshot da Microsoft Excel, novembre 2022
Ancora una volta, NumPy ci fornisce la migliore soluzione quando si lavora con i dataframe, tramite la sua funzione di selezione.
Con select, possiamo creare un elenco di condizioni, scelte e un valore facoltativo per quando tutte le condizioni sono false:
condizioni = [df['Posizione'] <= 3, df['Posizione'] <= 10, df['Posizione'] <=20] scelte = ['Primi 3', 'Primi 10', 'Primi 20'] df['Rank'] = np.select(condizioni, scelte, 'Non Top 20')
È anche possibile avere più condizioni per ciascuna delle valutazioni.
Supponiamo che stiamo lavorando con un rivenditore di e-commerce con pagine di elenco dei prodotti (PLP) e pagine di visualizzazione dei prodotti (PDP) e vogliamo etichettare il tipo di pagine con marchio che si classificano tra i primi 10 risultati.
La soluzione più semplice qui è cercare pattern URL specifici, come una sottocartella o un'estensione, ma cosa succede se i concorrenti hanno pattern simili?
In questo scenario, potremmo fare qualcosa del genere:
condizioni = [(df['URL'].str.contains('/category/')) & (df['Brand Rank'] > 0),
(df['URL'].str.contains('/product/')) & (df['Brand Rank'] > 0),
(~df['URL'].str.contains('/product/')) & (~df['URL'].str.contains('/category/')) & (df['Brand Rank'] > 0)]
scelte = ['PLP', 'PDP', 'Altro']
df['Brand Page Type'] = np.select(condizioni, scelte, Nessuna)Sopra, utilizziamo str.contains per valutare se un URL tra i primi 10 corrisponde o meno al pattern del nostro brand, quindi utilizziamo la colonna "Brand Rank" per escludere eventuali concorrenti.
In questo esempio, il segno tilde (~) indica una corrispondenza negativa. In altre parole, stiamo dicendo che vogliamo che ogni URL di marca che non corrisponde al pattern di "PDP" o "PLP" corrisponda ai criteri di "Altro".
Infine, None è incluso perché vogliamo che i risultati non relativi al brand restituiscano un valore nullo.
 Screenshot da VS Code, novembre 2022
Screenshot da VS Code, novembre 2022
CERCA.VERT
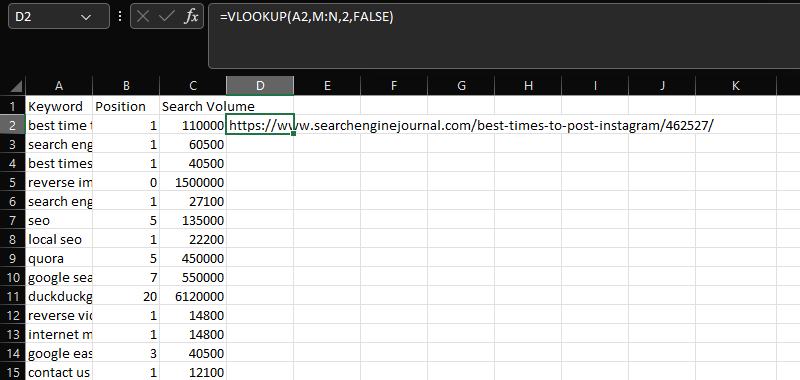
VLOOKUP è uno strumento essenziale per unire due set di dati distinti su una colonna comune.
In questo caso, aggiungendo gli URL all'interno della colonna N ai dati relativi a parola chiave, posizione e volume di ricerca nelle colonne AC, utilizzando la colonna "Parola chiave" condivisa:
=CERCA.VERT(A2;M:N;2;FALSO)
 Screenshot da Microsoft Excel, novembre 2022
Screenshot da Microsoft Excel, novembre 2022
Per fare qualcosa di simile con Panda, possiamo usare merge.
Replicando la funzionalità di un join SQL, il merge è una funzione incredibilmente potente che supporta una varietà di diversi tipi di join.
Per i nostri scopi, vogliamo utilizzare un join sinistro, che manterrà il nostro primo dataframe e si unirà solo ai valori corrispondenti dal nostro secondo dataframe:
mergeddf = df.merge(df2, how='sinistra', on='Parola chiave')
Un ulteriore vantaggio dell'esecuzione di un'unione su una CERCA.VERT è che non è necessario disporre dei dati condivisi nella prima colonna del secondo set di dati, come con il nuovo XLOOKUP.
Estrarrà anche più righe di dati anziché la prima corrispondenza nei risultati.
Un problema comune quando si utilizza la funzione è la duplicazione delle colonne indesiderate. Ciò si verifica quando esistono più colonne condivise, ma si tenta di creare una corrispondenza utilizzandone una.
Per evitare ciò e migliorare la precisione delle tue corrispondenze, puoi specificare un elenco di colonne:
mergeddf = df.merge(df2, how='left', on=['Parola chiave', 'Volume di ricerca'])
In alcuni scenari, potresti voler includere attivamente queste colonne. Ad esempio, quando si tenta di unire più rapporti di classifica mensili:
mergeddf = df.merge(df2, on='Keyword', how='left', suffixes=('', '_october'))\
.merge(df3, on='Parola chiave', how='sinistra', suffissi=('', '_settembre'))Il suddetto frammento di codice esegue due unioni per unire tre dataframe con le stesse colonne, che sono le nostre classifiche per novembre, ottobre e settembre.
Etichettando i mesi all'interno dei parametri del suffisso, otteniamo un dataframe molto più pulito che mostra chiaramente il mese, al contrario dei valori predefiniti di _x e _y visti nell'esempio precedente.
 Screenshot da VS Code, novembre 2022
Screenshot da VS Code, novembre 2022
CONTA.SE/SOMMA.SE/MEDIA.SE
In Excel, se si desidera eseguire una funzione statistica basata su una condizione, è probabile che si utilizzi CONTA.SE, SOMMA.SE o MEDIA.SE.
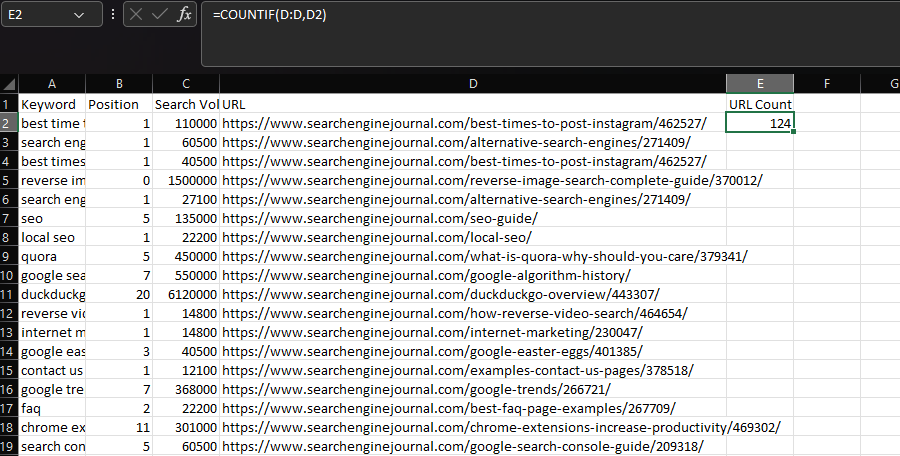
In genere, COUNTIF viene utilizzato per determinare quante volte una stringa specifica viene visualizzata all'interno di un set di dati, ad esempio un URL.
Possiamo farlo dichiarando la colonna "URL" come nostro intervallo, quindi l'URL all'interno di una singola cella come nostro criterio:
=CONTA.SE(D:D;D2)
 Screenshot da Microsoft Excel, novembre 2022
Screenshot da Microsoft Excel, novembre 2022
In Pandas, possiamo ottenere lo stesso risultato utilizzando la funzione groupby:
df.groupby('URL')['URL'].count()  Screenshot da VS Code, novembre 2022
Screenshot da VS Code, novembre 2022
Qui, la colonna dichiarata tra parentesi tonde indica i singoli gruppi, e la colonna elencata tra parentesi quadre è dove viene eseguita l'aggregazione (cioè il conteggio).
L'output che stiamo ricevendo non è perfetto per questo caso d'uso, però, perché ha consolidato i dati.
In genere, quando si utilizza Excel, avremmo il conteggio degli URL in linea all'interno del nostro set di dati. Quindi possiamo usarlo per filtrare gli URL elencati più di frequente.
Per fare ciò, usa transform e memorizza l'output in una colonna:
df['URL'] = df.groupby('URL')['URL'].transform('count')  Screenshot da VS Code, novembre 2022
Screenshot da VS Code, novembre 2022
Puoi anche applicare funzioni personalizzate a gruppi di dati utilizzando una funzione lambda (anonima):
df['Google Count'] = df.groupby(['URL'])['URL'].transform(lambda x: x[x.str.contains('google')].count())Nei nostri esempi finora, abbiamo utilizzato la stessa colonna per il nostro raggruppamento e le nostre aggregazioni, ma non è necessario. Analogamente a COUNTIFS/SOMMA.IF/AVERAGEIFS in Excel, è possibile raggruppare utilizzando una colonna, quindi applicare la nostra funzione statistica a un'altra.
Tornando all'esempio precedente della pagina dei risultati del motore di ricerca (SERP), potremmo voler contare tutti i PDP di ranking in base alla parola chiave e restituire questo numero insieme ai nostri dati esistenti:
df['PDP Count'] = df.groupby(['Keyword'])['URL'].transform(lambda x: x[x.str.contains('/product/|/prd/|/pd/' )].contare())  Screenshot da VS Code, novembre 2022
Screenshot da VS Code, novembre 2022Che nel gergo di Excel, sarebbe simile a questo:
=SOMMA(COUNTIFS(A:A,[@Keyword],D:D,{"*/prodotto/*","*/prd/*","*/pd/*"}))
Tabelle pivot
Ultimo, ma non meno importante, è il momento di parlare delle tabelle pivot.
In Excel, è probabile che una tabella pivot sia il nostro primo punto di riferimento se vogliamo riassumere un set di dati di grandi dimensioni.
Ad esempio, quando lavoriamo con i dati di ranking, potremmo voler identificare quali URL appaiono più frequentemente e la loro posizione media nel ranking.
 Screenshot da Microsoft Excel, novembre 2022
Screenshot da Microsoft Excel, novembre 2022
Ancora una volta, Pandas ha le proprie tabelle pivot equivalenti, ma se tutto ciò che desideri è un conteggio di valori univoci all'interno di una colonna, questo può essere ottenuto utilizzando la funzione value_counts:
conteggio = df['URL'].value_counts()
Anche l'uso di groupby è un'opzione.
In precedenza nell'articolo, l'esecuzione di un groupby che aggregava i nostri dati non era ciò che volevamo, ma è esattamente ciò che è richiesto qui:
raggruppato = df.groupby('URL').agg(
url_frequency=('Parola chiave', 'conteggio'),
avg_position=('Posizione', 'media'),
)
grouped.reset_index(inplace=True)  Screenshot da VS Code, novembre 2022
Screenshot da VS Code, novembre 2022
Nell'esempio sopra sono state applicate due funzioni di aggregazione, ma questo potrebbe essere facilmente ampliato e sono disponibili 13 tipi diversi.
Ci sono, ovviamente, momenti in cui vogliamo usare pivot_table, come quando eseguiamo operazioni multidimensionali.
Per illustrare cosa significa, riutilizziamo i raggruppamenti di ranking che abbiamo creato utilizzando istruzioni condizionali e proviamo a visualizzare il numero di volte in cui un URL si posiziona all'interno di ciascun gruppo.
ranking_groupings = df.groupby(['URL', 'Raggruppamento']).agg(
url_frequency=('Parola chiave', 'conteggio'),
)  Screenshot da VS Code, novembre 2022
Screenshot da VS Code, novembre 2022
Questo non è il formato migliore da utilizzare, poiché sono state create più righe per ogni URL.
Invece, possiamo usare pivot_table, che visualizzerà i dati in diverse colonne:
pivot = pd.pivot_table(df, indice=['URL'], colonne=['Raggruppamento'], aggfunc='dimensione', fill_value=0, )
 Screenshot da VS Code, novembre 2022
Screenshot da VS Code, novembre 2022
Pensieri finali
Sia che tu stia cercando ispirazione per iniziare a imparare Python, o che lo stia già sfruttando nei tuoi flussi di lavoro SEO, spero che gli esempi precedenti ti aiutino nel tuo viaggio.
Come promesso, puoi trovare un taccuino Google Colab con tutti i frammenti di codice qui.
In verità, abbiamo appena scalfito la superficie di ciò che è possibile, ma comprendere le basi dell'analisi dei dati di Python ti darà una solida base su cui costruire.
Altre risorse:
- Prova questi strumenti e metodi per esportare i risultati della ricerca di Google in Excel
- 12 punti dati SEO essenziali per qualsiasi sito web
- SEO tecnico avanzato: una guida completa
Immagine in primo piano: mapo_japan/Shutterstock