
从 Excel 过渡到 Python:SEO 数据分析的基本功能
已发表: 2022-12-02学习编码,无论是使用 Python、JavaScript 还是其他编程语言,都有很多好处,包括能够处理更大的数据集和自动执行重复性任务。
但是尽管有这些好处,许多 SEO 专业人士还没有进行过渡——我完全理解为什么! 这不是 SEO 的必备技能,我们都是忙碌的人。
如果您时间紧迫,并且您已经知道如何在 Excel 或 Google 表格中完成一项任务,那么改变策略就像重新发明轮子一样。
当我第一次开始编码时,我最初只使用 Python 来完成我无法在 Excel 中完成的任务——并且花了几年时间才成为我在数据处理方面的实际选择。
回想起来,我非常高兴我坚持了下来,但有时这是一次令人沮丧的经历,我花了很多小时在 Stack Overflow 上扫描线程。
这篇文章旨在避免其他 SEO 专业人员遭受同样的命运。
在其中,我们将介绍最常用的 Excel 公式和 SEO 数据分析功能的 Python 等价物——所有这些都可以在摘要中链接的 Google Colab 笔记本中找到。
具体来说,您将学习以下等价物:
- 伦。
- 删除重复项。
- 文本到列。
- 搜索/查找。
- 连接。
- 查找和替换。
- 左/中/右。
- 如果。
- 国际金融中心。
- VLOOKUP。
- COUNTIF/SUMIF/AVERAGEIF。
- 数据透视表。
令人惊讶的是,要完成所有这一切,我们将主要使用一个单一的库——Pandas——并在某些地方从它的老大哥 NumPy 那里得到一点帮助。
先决条件
为了简洁起见,我们今天不会介绍一些内容,包括:
- 安装 Python。
- 基本 Pandas,例如导入 CSV、过滤和预览数据帧。
如果您对此不确定,那么 Hamlet 的 SEO Python 数据分析指南是完美的入门读物。
现在,事不宜迟,让我们开始吧。
伦
LEN 提供文本字符串中字符数的计数。
具体对于 SEO,一个常见的用例是测量标题标签或元描述的长度,以确定它们是否会在搜索结果中被截断。
在 Excel 中,如果我们想计算 A 列的第二个单元格,我们将输入:
=LEN(A2)
 Microsoft Excel 的屏幕截图,2022 年 11 月
Microsoft Excel 的屏幕截图,2022 年 11 月
Python 并没有太大的不同,因为我们可以依赖内置的 len 函数,它可以与 Pandas 的 loc[] 结合使用来访问列中的特定数据行:
len(df['标题'].loc[0])
在此示例中,我们获取数据框“标题”列中第一行的长度。

- VS Code 的屏幕截图,2022 年 11 月
不过,查找单元格的长度对 SEO 没有多大用处。 通常,我们希望将一个函数应用于整个列!
在 Excel 中,这可以通过选择右下角的公式单元格并向下拖动或双击来实现。
使用 Pandas 数据框时,我们可以使用 str.len 来计算系列中行的长度,然后将结果存储在新列中:
df['长度'] = df['标题'].str.len()
Str.len 是一种“向量化”操作,旨在同时应用于一系列值。 我们将在整篇文章中广泛使用这些操作,因为它们几乎普遍比循环更快。
LEN 的另一个常见应用是将其与 SUBSTITUTE 结合使用以计算单元格中的单词数:
=LEN(TRIM(A2))-LEN(替换(A2," ",""))+1
在 Pandas 中,我们可以通过将 str.split 和 str.len 函数组合在一起来实现这一点:
df['没有。 单词'] = df['标题'].str.split().str.len()
稍后我们将更详细地介绍 str.split,但本质上,我们所做的是根据字符串中的空格拆分数据,然后计算组成部分的数量。
 VS Code 的屏幕截图,2022 年 11 月
VS Code 的屏幕截图,2022 年 11 月
删除重复项
Excel 的“删除重复项”功能提供了一种简单的方法来删除数据集中的重复值,方法是删除完全重复的行(当所有列都被选中时)或删除特定列中具有相同值的行。
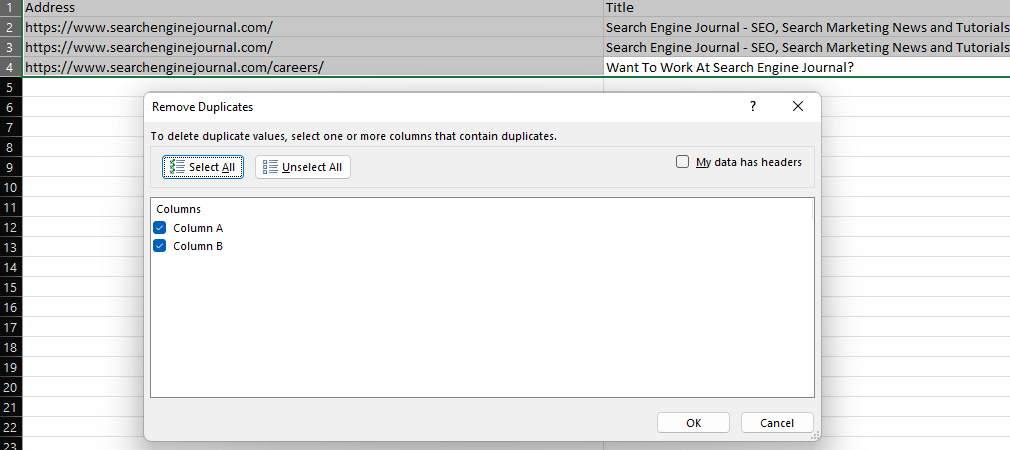 Microsoft Excel 的屏幕截图,2022 年 11 月
Microsoft Excel 的屏幕截图,2022 年 11 月
在 Pandas 中,此功能由 drop_duplicates 提供。
要删除数据框类型中的重复行:
df.drop_duplicates(就地=真)
要根据单个列中的重复项删除行,请包含 subset 参数:
df.drop_duplicates(subset='column', inplace=True)
或者在列表中指定多个列:
df.drop_duplicates(subset=['column','column2'], inplace=True)
值得一提的是 inplace 参数的存在。 包括 inplace=True 允许我们覆盖现有数据框而无需创建新数据框。
当然,有时我们希望保留原始数据。 在这种情况下,我们可以将去重数据帧分配给不同的变量:
df2 = df.drop_duplicates(子集='列')
文本到列
另一个日常必需品是“文本到列”功能,可用于根据定界符(例如斜杠、逗号或空格)拆分文本字符串。
例如,将 URL 拆分为其域和各个子文件夹。
 Microsoft Excel 的屏幕截图,2022 年 11 月
Microsoft Excel 的屏幕截图,2022 年 11 月
在处理数据帧时,我们可以使用 str.split 函数,它为系列中的每个条目创建一个列表。 这可以通过将 expand 参数设置为 True 来转换为多列:
df['URL'].str.split(pat='/', expand=True)
 VS Code 的屏幕截图,2022 年 11 月
VS Code 的屏幕截图,2022 年 11 月
通常情况下,我们上图中的 URL 被分成不一致的列,因为它们没有相同数量的文件夹。
当我们想要将数据保存在现有数据框中时,这会使事情变得棘手。
指定 n 参数限制拆分的数量,允许我们创建特定数量的列:
df[['Domain', 'Folder1', 'Folder2', 'Folder3']] = df['URL'].str.split(pat='/', expand=True, n=3)
另一种选择是使用 pop 从数据框中删除您的列,执行拆分,然后使用 join 函数重新添加它:
df = df.join(df.pop('Split').str.split(pat='/', expand=True))在拆分之前将 URL 复制到新列可以让我们保留完整的 URL。 然后我们可以重命名新列:🐆
df['拆分'] = df['URL']
df = df.join(df.pop('Split').str.split(pat='/', expand=True))
df.rename(columns = {0:'Domain', 1:'Folder1', 2:'Folder2', 3:'Folder3', 4:'Parameter'}, inplace=True) 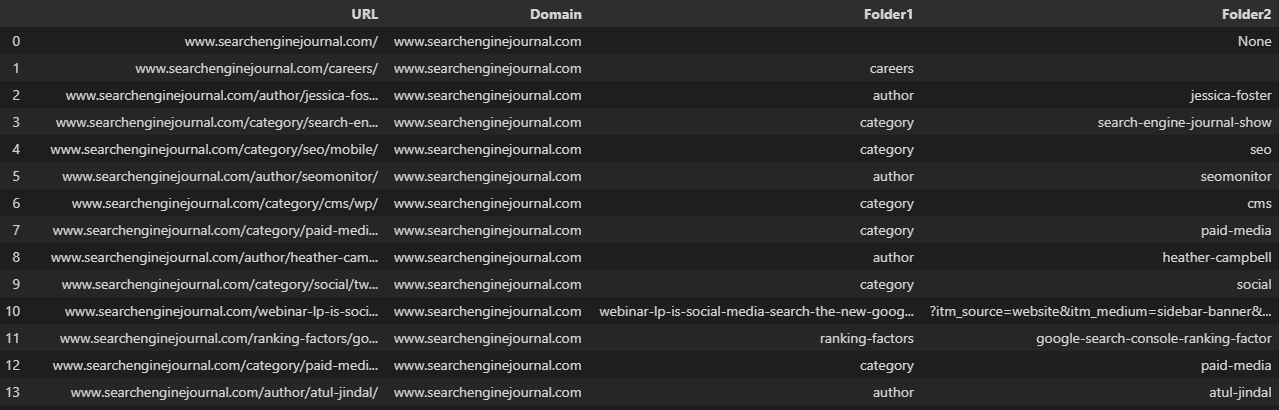 VS Code 的屏幕截图,2022 年 11 月
VS Code 的屏幕截图,2022 年 11 月
串联
CONCAT 函数允许用户组合多个文本字符串,例如在通过添加不同的修饰符生成关键字列表时。
在这种情况下,我们将“mens”和空格添加到 A 列的产品类型列表中:
=CONCAT($F$1," ",A2)

- Microsoft Excel 的屏幕截图,2022 年 11 月
假设我们正在处理字符串,同样可以在 Python 中使用算术运算符来实现:
df['组合] = 'mens' + ' ' + df['关键字']
或者指定多列数据:
df['组合'] = df['子域'] + df['URL']
 VS Code 的屏幕截图,2022 年 11 月
VS Code 的屏幕截图,2022 年 11 月
Pandas 有一个专门的 concat 函数,但这在尝试将多个数据帧与相同列组合时更有用。
例如,如果我们从我们最喜欢的链接分析工具中导出了多个:
df = pd.read_csv('data.csv')
df2 = pd.read_csv('data2.csv')
df3 = pd.read_csv('data3.csv')
dflist = [df, df2, df3]
df = pd.concat(dflist, ignore_index=True)搜索/查找
SEARCH 和 FIND 公式提供了一种在文本字符串中定位子字符串的方法。
这些命令通常与 ISNUMBER 结合使用以创建有助于过滤数据集的布尔列,这在执行日志文件分析等任务时非常有用,如本指南中所述。 例如:
=ISNUMBER(SEARCH("搜索这个",A2)  Microsoft Excel 的屏幕截图,2022 年 11 月
Microsoft Excel 的屏幕截图,2022 年 11 月
SEARCH 和 FIND 的区别在于 find 是区分大小写的。
等效的 Pandas 函数 str.contains 默认区分大小写:
df['期刊'] = df['URL'].str.contains('引擎', na=False)可以通过将 case 参数设置为 False 来启用不区分大小写:
df['Journal'] = df['URL'].str.contains('engine', case=False, na=False)在任何一种情况下,包含 na=False 都将防止在布尔列中返回空值。
在这里使用 Pandas 的一个巨大优势是,与 Excel 不同,此函数原生支持正则表达式——就像在 Google 表格中通过 REGEXMATCH 一样。
使用竖线字符(也称为 OR 运算符)将多个子字符串链接在一起:
df['Journal'] = df['URL'].str.contains('engine|search', na=False)查找和替换
Excel 的“查找和替换”功能提供了一种简单的方法,可以将一个子字符串单独或批量替换为另一个子字符串。
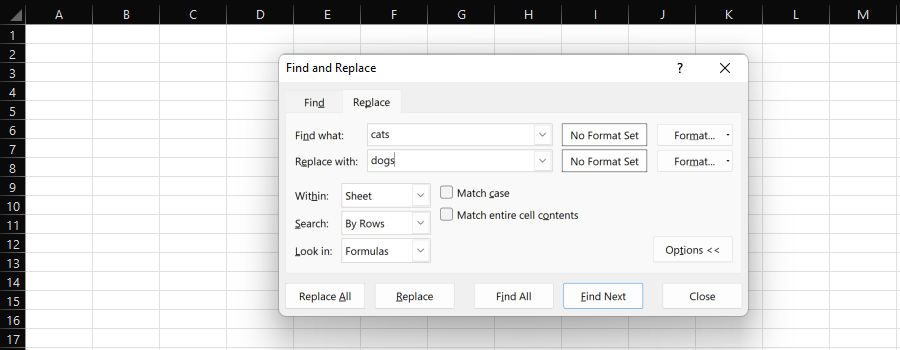 Microsoft Excel 的屏幕截图,2022 年 11 月
Microsoft Excel 的屏幕截图,2022 年 11 月
在为 SEO 处理数据时,我们最有可能选择整个列并“全部替换”。
SUBSTITUTE 公式在这里提供了另一个选项,如果您不想覆盖现有的列,它会很有用。
例如,我们可以将 URL 的协议从 HTTP 更改为 HTTPS,或者将其替换为空以将其删除。
在 Python 中处理数据帧时,我们可以使用 str.replace:
df['URL'] = df['URL'].str.replace('http://', 'https://')或者:
df['URL'] = df['URL'].str.replace('http://', '') # 什么都不替换同样,与 Excel 不同,可以使用正则表达式——就像 Google 表格的 REGEXREPLACE:
df['URL'] = df['URL'].str.replace('http://|https://', '')或者,如果要用不同的值替换多个子字符串,可以使用 Python 的 replace 方法并提供一个列表。
这使您不必链接多个 str.replace 函数:
df['URL'] = df['URL'].replace(['http://', 'https://'], ['https://www.', 'https://www.' ], 正则表达式=真)
左/中/右
在 Excel 中提取子字符串需要使用 LEFT、MID 或 RIGHT 函数,具体取决于子字符串在单元格中的位置。

假设我们要从 URL 中提取根域和子域:
=MID(A2,FIND(":",A2,4)+3,FIND("/",A2,9)-FIND(":",A2,4)-3) 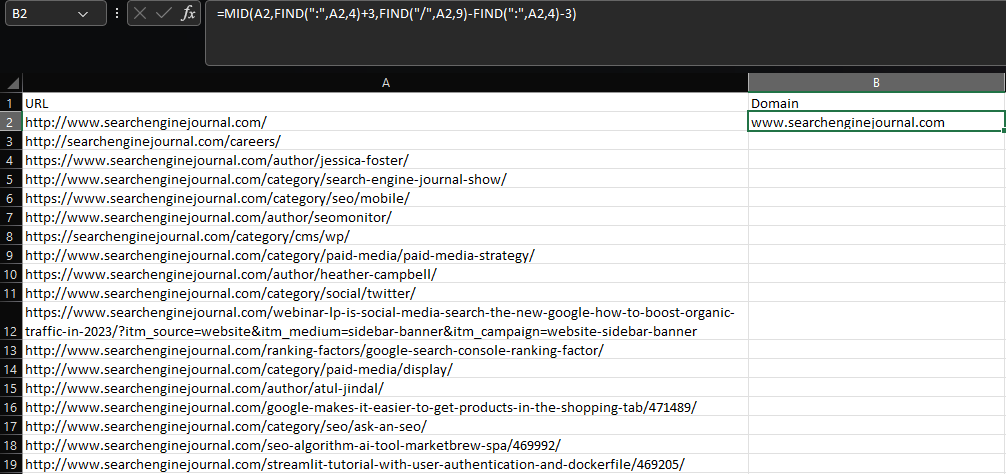 Microsoft Excel 的屏幕截图,2022 年 11 月
Microsoft Excel 的屏幕截图,2022 年 11 月
使用 MID 和多个 FIND 函数的组合,这个公式至少可以说是丑陋的——而且对于更复杂的提取,情况会变得更糟。
同样,Google 表格在这方面比 Excel 做得更好,因为它有 REGEXEXTRACT。
遗憾的是,当你给它提供更大的数据集时,它在热散热器上融化的速度比 Babybel 还快。
值得庆幸的是,Pandas 提供了 str.extract,它以类似的方式工作:
df['域'] = df['URL'].str.extract('.*\://?([^\/]+)')  VS Code 的屏幕截图,2022 年 11 月
VS Code 的屏幕截图,2022 年 11 月
与 fillna 结合使用以防止出现空值,就像在 Excel 中使用 IFERROR 一样:
df['域'] = df['URL'].str.extract('.*\://?([^\/]+)').fillna('-')如果
IF 语句允许您返回不同的值,具体取决于是否满足条件。
为了说明这一点,假设我们要为排名前三位的关键字创建一个标签。
 Microsoft Excel 的屏幕截图,2022 年 11 月
Microsoft Excel 的屏幕截图,2022 年 11 月
在这种情况下,我们可以依靠 NumPy 和 where 函数而不是使用 Pandas(如果您还没有导入 NumPy,请记住导入 NumPy):
df['Top 3'] = np.where(df['Position'] <= 3, 'Top 3', 'Not Top 3')
通过使用 AND/OR 运算符,并将各个条件括在圆括号中,可以将多个条件用于同一评估:
df['Top 3'] = np.where((df['Position'] <= 3) & (df['Position'] != 0), 'Top 3', 'Not Top 3')
在上面,我们为排名小于或等于 3 的任何关键字返回“前 3”,不包括排名为零的任何关键字。
国际金融中心
有时,您可能需要返回不同值的多个条件,而不是为同一评估指定多个条件。
在这种情况下,最好的解决方案是使用 IFS:
=IFS(B2<=3,"前 3",B2<=10,"前 10",B2<=20,"前 20")
 Microsoft Excel 的屏幕截图,2022 年 11 月
Microsoft Excel 的屏幕截图,2022 年 11 月
同样,NumPy 通过其选择功能为我们提供了处理数据帧的最佳解决方案。
使用 select,我们可以创建一个条件列表、选择列表,以及当所有条件都为 false 时的可选值:
条件 = [df['位置'] <= 3, df['位置'] <= 10, df['位置'] <=20] choices = ['前 3', '前 10', '前 20'] df['Rank'] = np.select(conditions, choices, 'Not Top 20')
也可以为每个评估设置多个条件。
假设我们正在与一家拥有产品列表页面 (PLP) 和产品展示页面 (PDP) 的电子商务零售商合作,我们希望标记排名在前 10 名结果中的品牌页面类型。
这里最简单的解决方案是寻找特定的 URL 模式,例如子文件夹或扩展名,但如果竞争对手有类似的模式怎么办?
在这种情况下,我们可以这样做:
conditions = [(df['URL'].str.contains('/category/')) & (df['Brand Rank'] > 0),
(df['URL'].str.contains('/product/')) & (df['品牌排名'] > 0),
(~df['URL'].str.contains('/product/')) & (~df['URL'].str.contains('/category/')) & (df['品牌排名'] > 0)]
选择 = ['PLP', 'PDP', '其他']
df['Brand Page Type'] = np.select(conditions, choices, None)上面,我们使用 str.contains 来评估前 10 名中的 URL 是否符合我们品牌的模式,然后使用“品牌排名”列排除任何竞争对手。
在此示例中,波浪号 (~) 表示否定匹配。 换句话说,我们是说我们希望每个与“PDP”或“PLP”模式不匹配的品牌 URL 都符合“其他”的条件。
最后,包含 None 是因为我们希望非品牌结果返回空值。
 VS Code 的屏幕截图,2022 年 11 月
VS Code 的屏幕截图,2022 年 11 月
VLOOKUP
VLOOKUP 是将两个不同数据集连接到一个公共列上的重要工具。
在这种情况下,使用共享的“关键字”列将 N 列中的 URL 添加到 AC 列中的关键字、位置和搜索量数据:
=VLOOKUP(A2,M:N,2,FALSE)
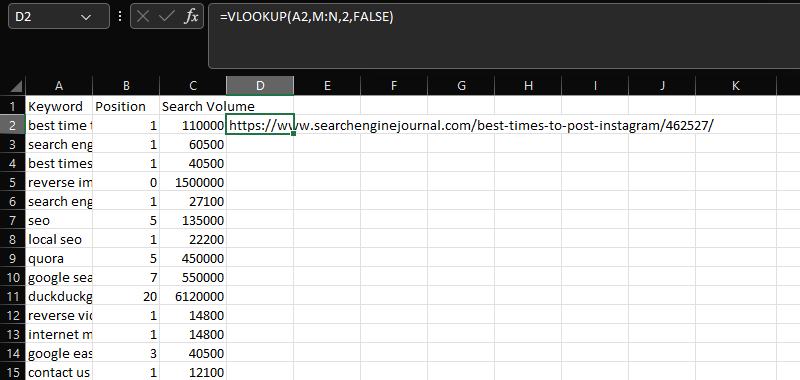 Microsoft Excel 的屏幕截图,2022 年 11 月
Microsoft Excel 的屏幕截图,2022 年 11 月
要对 Pandas 做类似的事情,我们可以使用 merge。
复制 SQL 连接的功能,合并是一个非常强大的功能,支持各种不同的连接类型。
出于我们的目的,我们想使用左连接,它将维护我们的第一个数据框,并且只合并来自第二个数据框的匹配值:
mergeddf = df.merge(df2, how='left', on='Keyword')
通过 VLOOKUP 执行合并的一个额外优势是,您不必像较新的 XLOOKUP 那样在第二个数据集的第一列中拥有共享数据。
它还将提取多行数据而不是查找中的第一个匹配项。
使用该函数时的一个常见问题是复制不需要的列。 当存在多个共享列,但您尝试使用一个进行匹配时,会发生这种情况。
为了防止这种情况——并提高匹配的准确性——你可以指定一个列列表:
mergeddf = df.merge(df2, how='left', on=['Keyword', 'Search Volume'])
在某些情况下,您可能会主动希望包含这些列。 例如,当试图合并多个月度排名报告时:
mergeddf = df.merge(df2, on='Keyword', how='left', suffixes=('', '_october'))\
.merge(df3, on='Keyword', how='left', suffixes=('', '_september'))上面的代码片段执行了两次合并,将三个具有相同列的数据框连接在一起——这是我们对 11 月、10 月和 9 月的排名。
通过在后缀参数中标记月份,我们最终得到一个清晰得多的数据框,它清楚地显示了月份,而不是前面示例中看到的默认值 _x 和 _y。
 VS Code 的屏幕截图,2022 年 11 月
VS Code 的屏幕截图,2022 年 11 月
COUNTIF/SUMIF/AVERAGEIF
在 Excel 中,如果要根据条件执行统计函数,您可能会使用 COUNTIF、SUMIF 或 AVERAGEIF。
通常,COUNTIF 用于确定特定字符串在数据集中出现的次数,例如 URL。
我们可以通过将“URL”列声明为我们的范围,然后将单个单元格中的 URL 声明为我们的条件来实现此目的:
=COUNTIF(D:D,D2)
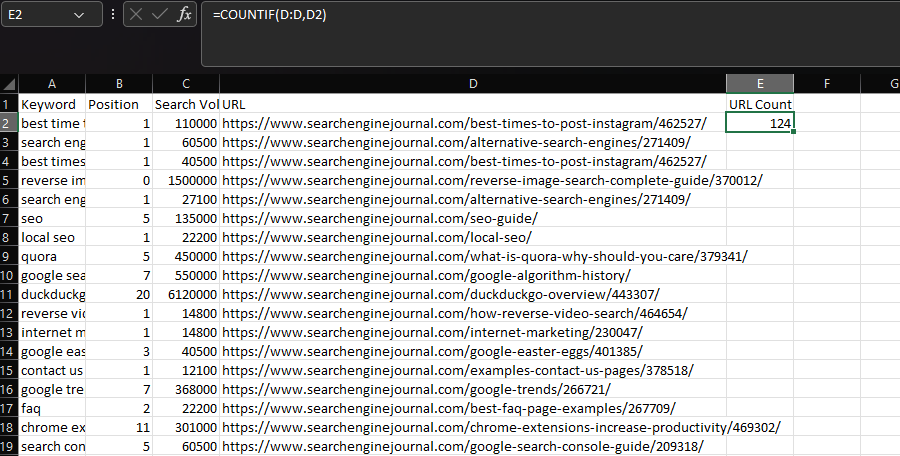 Microsoft Excel 的屏幕截图,2022 年 11 月
Microsoft Excel 的屏幕截图,2022 年 11 月
在 Pandas 中,我们可以通过使用 groupby 函数来实现相同的结果:
df.groupby('URL')['URL'].count()  VS Code 的屏幕截图,2022 年 11 月
VS Code 的屏幕截图,2022 年 11 月
此处,圆括号内声明的列表示各个组,方括号中列出的列是执行聚合(即计数)的位置。
但是,我们收到的输出对于这个用例来说并不完美,因为它整合了数据。
通常,在使用 Excel 时,我们会在数据集中内嵌 URL 计数。 然后我们可以使用它来过滤最常列出的 URL。
为此,请使用转换并将输出存储在列中:
df['URL 计数'] = df.groupby('URL')['URL'].transform('计数')  VS Code 的屏幕截图,2022 年 11 月
VS Code 的屏幕截图,2022 年 11 月
您还可以使用 lambda(匿名)函数将自定义函数应用于数据组:
df['Google Count'] = df.groupby(['URL'])['URL'].transform(lambda x: x[x.str.contains('google')].count())到目前为止,在我们的示例中,我们一直使用相同的列进行分组和聚合,但我们不必这样做。 与 Excel 中的 COUNTIFS/SUMIFS/AVERAGEIFS 类似,可以使用一列进行分组,然后将我们的统计函数应用于另一列。
回到前面的搜索引擎结果页面 (SERP) 示例,我们可能希望按关键字计算所有排名 PDP,并将此数字与我们现有的数据一起返回:
df['PDP Count'] = df.groupby(['Keyword'])['URL'].transform(lambda x: x[x.str.contains('/product/|/prd/|/pd/' )]。数数())  VS Code 的屏幕截图,2022 年 11 月
VS Code 的屏幕截图,2022 年 11 月在 Excel 中,这看起来像这样:
=SUM(COUNTIFS(A:A,[@Keyword],D:D,{"*/product/*","*/prd/*","*/pd/*"}))
数据透视表
最后但并非最不重要的一点是,是时候谈谈数据透视表了。
在 Excel 中,如果我们想要汇总大型数据集,数据透视表可能是我们的第一个停靠点。
例如,在处理排名数据时,我们可能想要确定哪些 URL 出现最频繁,以及它们的平均排名位置。
 Microsoft Excel 的屏幕截图,2022 年 11 月
Microsoft Excel 的屏幕截图,2022 年 11 月
同样,Pandas 有自己的等效数据透视表——但如果您想要的只是列中唯一值的计数,则可以使用 value_counts 函数来完成:
计数 = df['URL'].value_counts()
使用 groupby 也是一种选择。
在本文的前面,执行聚合数据的 groupby 不是我们想要的——但这正是这里所需要的:
grouped = df.groupby('URL').agg(
url_frequency=('关键字', '计数'),
avg_position=('位置', '均值'),
)
grouped.reset_index(就地=真)  VS Code 的屏幕截图,2022 年 11 月
VS Code 的屏幕截图,2022 年 11 月
上面的示例中应用了两个聚合函数,但这可以很容易地扩展,并且有 13 种不同的类型可用。
当然,有时我们确实想使用 pivot_table,例如执行多维操作时。
为了说明这意味着什么,让我们重新使用我们使用条件语句进行的排名分组,并尝试显示 URL 在每个组中的排名次数。
ranking_groupings = df.groupby(['URL', 'Grouping']).agg(
url_frequency=('关键字', '计数'),
)  VS Code 的屏幕截图,2022 年 11 月
VS Code 的屏幕截图,2022 年 11 月
这不是最好的格式,因为已为每个 URL 创建了多行。
相反,我们可以使用 pivot_table,它将在不同的列中显示数据:
pivot = pd.pivot_table(df, 索引=['网址'], columns=['分组'], aggfunc='大小', 填充值=0, )
 VS Code 的屏幕截图,2022 年 11 月
VS Code 的屏幕截图,2022 年 11 月
最后的想法
无论您是在寻找开始学习 Python 的灵感,还是已经在您的 SEO 工作流程中利用它,我都希望以上示例能帮助您一路走好。
正如承诺的那样,您可以在此处找到包含所有代码片段的 Google Colab 笔记本。
事实上,我们只是触及了可能的表面,但了解 Python 数据分析的基础知识将为您打下坚实的基础。
更多资源:
- 尝试使用这些工具和方法将 Google 搜索结果导出到 Excel
- 任何网站的 12 个基本 SEO 数据点
- 高级技术 SEO:完整指南
特色图片:mapo_japan/Shutterstock