
Transisi Dari Excel Ke Python: Fungsi Penting Untuk Analisis Data SEO
Diterbitkan: 2022-12-02Mempelajari kode, baik dengan Python, JavaScript, atau bahasa pemrograman lain, memiliki banyak manfaat, termasuk kemampuan untuk bekerja dengan kumpulan data yang lebih besar dan mengotomatiskan tugas berulang.
Namun terlepas dari manfaatnya, banyak profesional SEO yang belum melakukan transisi – dan saya sangat mengerti mengapa! Ini bukan keterampilan penting untuk SEO, dan kita semua orang sibuk.
Jika Anda terdesak waktu, dan Anda sudah tahu cara menyelesaikan tugas dalam Excel atau Google Sheets, mengubah taktik bisa terasa seperti menemukan kembali roda.
Ketika saya pertama kali memulai pengkodean, saya awalnya hanya menggunakan Python untuk tugas-tugas yang tidak dapat saya selesaikan di Excel – dan butuh beberapa tahun untuk sampai ke titik di mana itu adalah pilihan de facto saya untuk pemrosesan data.
Melihat ke belakang, saya sangat senang saya bertahan, tetapi terkadang itu adalah pengalaman yang membuat frustrasi, dengan menghabiskan banyak waktu untuk memindai utas di Stack Overflow.
Posting ini dirancang untuk menghindarkan profesional SEO lainnya dari nasib yang sama.
Di dalamnya, kami akan membahas persamaan Python dari rumus dan fitur Excel yang paling umum digunakan untuk analisis data SEO – semuanya tersedia dalam notebook Google Colab yang ditautkan dalam ringkasan.
Secara khusus, Anda akan mempelajari persamaan dari:
- LEN.
- Jatuhkan Duplikat.
- Teks ke Kolom.
- CARI / TEMUKAN.
- MENGGABUNGKAN.
- Temukan dan ganti.
- KIRI/TENGAH/KANAN.
- JIKA.
- JIKA.
- VLOOKUP.
- COUNTIF/SUMIF/AVERAGEIF.
- Tabel pivot.
Hebatnya, untuk mencapai semua ini, kami terutama akan menggunakan perpustakaan tunggal – Pandas – dengan sedikit bantuan dari kakaknya, NumPy.
Prasyarat
Demi singkatnya, ada beberapa hal yang tidak akan kami bahas hari ini, termasuk:
- Menginstal Python.
- Panda Dasar, seperti mengimpor CSV, memfilter, dan mempratinjau kerangka data.
Jika Anda tidak yakin tentang semua ini, maka panduan Hamlet tentang analisis data Python untuk SEO adalah primer yang sempurna.
Sekarang, tanpa basa-basi lagi, mari kita masuk.
LEN
LEN memberikan hitungan jumlah karakter dalam string teks.
Khusus untuk SEO, kasus penggunaan umum adalah mengukur panjang tag judul atau deskripsi meta untuk menentukan apakah akan terpotong dalam hasil pencarian.
Di dalam Excel, jika kami ingin menghitung sel kedua kolom A, kami akan memasukkan:
=LEN(A2)
 Cuplikan layar dari Microsoft Excel, November 2022
Cuplikan layar dari Microsoft Excel, November 2022
Python tidak terlalu berbeda, karena kita dapat mengandalkan fungsi len bawaan, yang dapat digabungkan dengan loc[] Pandas untuk mengakses baris data tertentu dalam kolom:
len(df['Judul'].loc[0])
Dalam contoh ini, kita mendapatkan panjang baris pertama di kolom "Judul" dari kerangka data kita.

- Tangkapan layar VS Code, November 2022
Namun, menemukan panjang sel tidak begitu berguna untuk SEO. Biasanya, kami ingin menerapkan fungsi ke seluruh kolom!
Di Excel, ini akan dicapai dengan memilih sel rumus di pojok kanan bawah dan menyeretnya ke bawah atau mengklik dua kali.
Saat bekerja dengan kerangka data Pandas, kita dapat menggunakan str.len untuk menghitung panjang baris dalam sebuah rangkaian, lalu menyimpan hasilnya di kolom baru:
df['Panjang'] = df['Judul'].str.len()
Str.len adalah operasi 'vektorisasi', yang dirancang untuk diterapkan secara bersamaan ke serangkaian nilai. Kami akan menggunakan operasi ini secara ekstensif di seluruh artikel ini, karena operasi ini hampir secara universal berakhir lebih cepat daripada satu putaran.
Aplikasi umum lain dari LEN adalah menggabungkannya dengan SUBSTITUTE untuk menghitung jumlah kata dalam sel:
=LEN(TRIM(A2))-LEN(GANTI(A2," ",""))+1
Di Pandas, kita dapat mencapainya dengan menggabungkan fungsi str.split dan str.len secara bersamaan:
df['Tidak. Kata'] = df['Judul'].str.split().str.len()
Kami akan membahas str.split lebih detail nanti, tetapi pada dasarnya, yang kami lakukan adalah membagi data kami berdasarkan spasi putih di dalam string, lalu menghitung jumlah bagian komponen.
 Tangkapan layar dari VS Code, November 2022
Tangkapan layar dari VS Code, November 2022
Menjatuhkan Duplikat
Fitur 'Hapus Duplikat' Excel menyediakan cara mudah untuk menghapus nilai duplikat dalam kumpulan data, baik dengan menghapus seluruh baris duplikat (ketika semua kolom dipilih) atau menghapus baris dengan nilai yang sama di kolom tertentu.
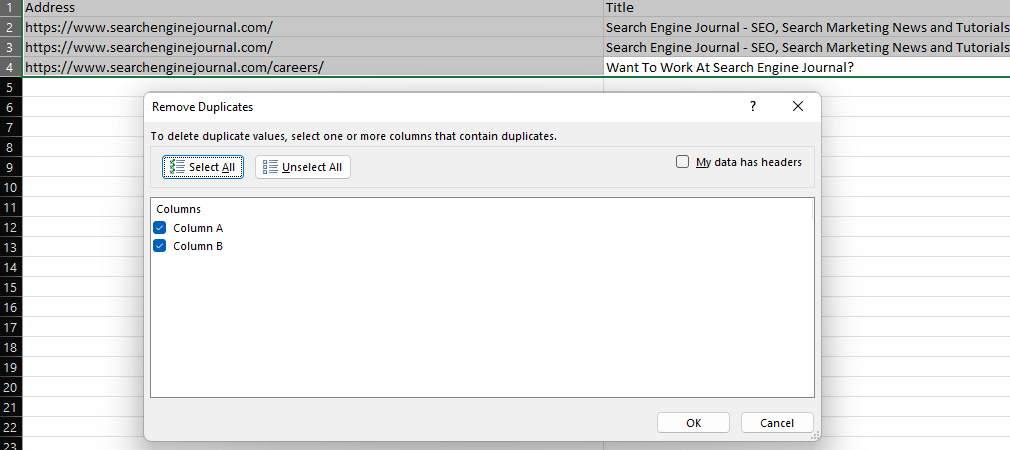 Cuplikan layar dari Microsoft Excel, November 2022
Cuplikan layar dari Microsoft Excel, November 2022
Di Pandas, fungsi ini disediakan oleh drop_duplicates.
Untuk menghapus baris duplikat dalam tipe kerangka data:
df.drop_duplicates(inplace=True)
Untuk menjatuhkan baris berdasarkan duplikat dalam kolom tunggal, sertakan parameter subset:
df.drop_duplicates(subset='column', inplace=True)
Atau tentukan beberapa kolom dalam daftar:
df.drop_duplicates(subset=['column','column2'], inplace=True)
Satu tambahan di atas yang perlu disebutkan adalah adanya parameter inplace. Termasuk inplace=True memungkinkan kita untuk menimpa kerangka data yang ada tanpa perlu membuat yang baru.
Tentu saja ada saatnya kita ingin menyimpan data mentah kita. Dalam hal ini, kami dapat menetapkan kerangka data deduped kami ke variabel yang berbeda:
df2 = df.drop_duplikat(subset='kolom')
Teks Ke Kolom
Hal penting sehari-hari lainnya, fitur 'teks ke kolom' dapat digunakan untuk memisahkan string teks berdasarkan pembatas, seperti garis miring, koma, atau spasi putih.
Sebagai contoh, membagi URL menjadi domain dan subfolder individualnya.
 Cuplikan layar dari Microsoft Excel, November 2022
Cuplikan layar dari Microsoft Excel, November 2022
Saat berurusan dengan kerangka data, kita dapat menggunakan fungsi str.split, yang membuat daftar untuk setiap entri dalam suatu rangkaian. Ini dapat diubah menjadi beberapa kolom dengan menyetel parameter perluasan ke True:
df['URL'].str.split(pat='/', perluas=True)
 Tangkapan layar dari VS Code, November 2022
Tangkapan layar dari VS Code, November 2022
Seperti yang sering terjadi, URL kami pada gambar di atas telah dipecah menjadi kolom yang tidak konsisten, karena tidak menampilkan jumlah folder yang sama.
Hal ini dapat mempersulit saat kita ingin menyimpan data kita dalam kerangka data yang ada.
Menentukan parameter n membatasi jumlah pemisahan, memungkinkan kita membuat sejumlah kolom tertentu:
df[['Domain', 'Folder1', 'Folder2', 'Folder3']] = df['URL'].str.split(pat='/', expand=True, n=3)
Pilihan lainnya adalah menggunakan pop untuk menghapus kolom Anda dari bingkai data, melakukan pemisahan, lalu menambahkannya kembali dengan fungsi gabungan:
df = df.join(df.pop('Split').str.split(pat='/', expand=True))Menduplikasi URL ke kolom baru sebelum pemisahan memungkinkan kami mempertahankan URL lengkap. Kami kemudian dapat mengganti nama kolom baru: 🐆
df['Pisahkan'] = df['URL']
df = df.join(df.pop('Split').str.split(pat='/', expand=True))
df.rename(kolom = {0:'Domain', 1:'Folder1', 2:'Folder2', 3:'Folder3', 4:'Parameter'}, inplace=True) 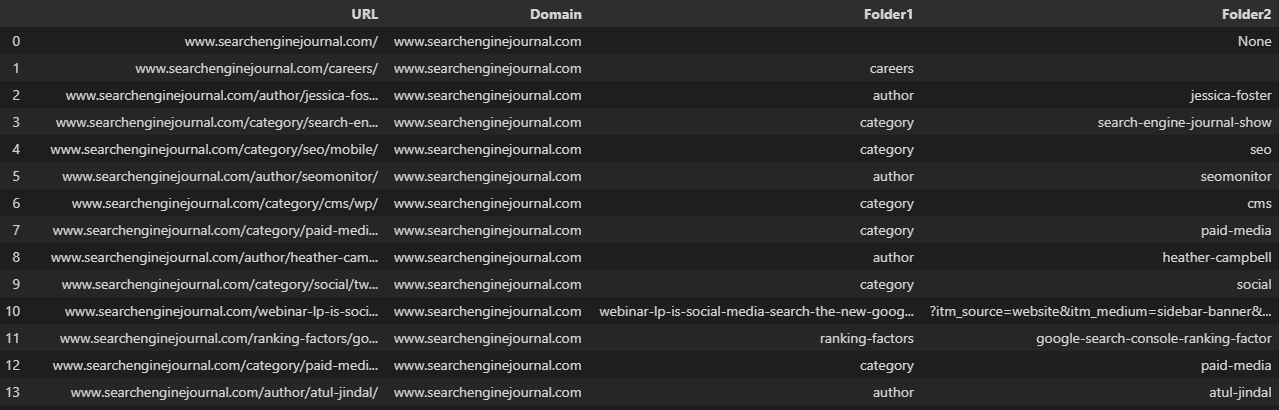 Tangkapan layar dari VS Code, November 2022
Tangkapan layar dari VS Code, November 2022
MENGGABUNGKAN
Fungsi CONCAT memungkinkan pengguna menggabungkan beberapa string teks, seperti saat membuat daftar kata kunci dengan menambahkan pengubah yang berbeda.
Dalam hal ini, kami menambahkan "mens" dan spasi ke daftar jenis produk kolom A:
=CONCAT($F$1," ",A2)

- Cuplikan layar dari Microsoft Excel, November 2022
Dengan asumsi kita berurusan dengan string, hal yang sama dapat dicapai dengan Python menggunakan operator aritmatika:
df['Gabungan] = 'pria' + ' ' + df['Kata kunci']
Atau tentukan beberapa kolom data:
df['Gabungan'] = df['Subdomain'] + df['URL']
 Tangkapan layar dari VS Code, November 2022
Tangkapan layar dari VS Code, November 2022
Panda memiliki fungsi concat khusus, tetapi ini lebih berguna saat mencoba menggabungkan beberapa kerangka data dengan kolom yang sama.
Misalnya, jika kami memiliki beberapa ekspor dari alat analisis tautan favorit kami:
df = pd.baca_csv('data.csv')
df2 = pd.read_csv('data2.csv')
df3 = pd.baca_csv('data3.csv')
dflist = [df, df2, df3]
df = pd.concat(dflist, abaikan_index=True)CARI / TEMUKAN
Rumus SEARCH dan FIND menyediakan cara untuk menemukan substring dalam string teks.
Perintah ini biasanya digabungkan dengan ISNUMBER untuk membuat kolom Boolean yang membantu memfilter kumpulan data, yang bisa sangat membantu saat melakukan tugas seperti analisis file log, seperti yang dijelaskan dalam panduan ini. Misalnya:
=ISNUMBER(SEARCH("cariini",A2)  Cuplikan layar dari Microsoft Excel, November 2022
Cuplikan layar dari Microsoft Excel, November 2022
Perbedaan antara SEARCH dan FIND adalah find bersifat case-sensitive.
Fungsi Pandas yang setara, str.contains, peka terhadap huruf besar-kecil secara default:
df['Journal'] = df['URL'].str.contains('engine', na=False)Ketidakpekaan huruf besar/kecil dapat diaktifkan dengan menyetel parameter huruf besar/kecil ke False:
df['Journal'] = df['URL'].str.contains('engine', case=False, na=False)Dalam skenario mana pun, menyertakan na=False akan mencegah nilai null dikembalikan dalam kolom Boolean.
Salah satu keuntungan besar menggunakan Panda di sini adalah, tidak seperti Excel, regex secara alami didukung oleh fungsi ini – seperti yang ada di lembar Google melalui REGEXMATCH.
Rangkai beberapa substring dengan menggunakan karakter pipa, juga dikenal sebagai operator OR:
df['Journal'] = df['URL'].str.contains('engine|search', na=False)Temukan dan ganti
Fitur "Temukan dan Ganti" Excel menyediakan cara mudah untuk mengganti satu substring dengan yang lain secara individual atau massal.
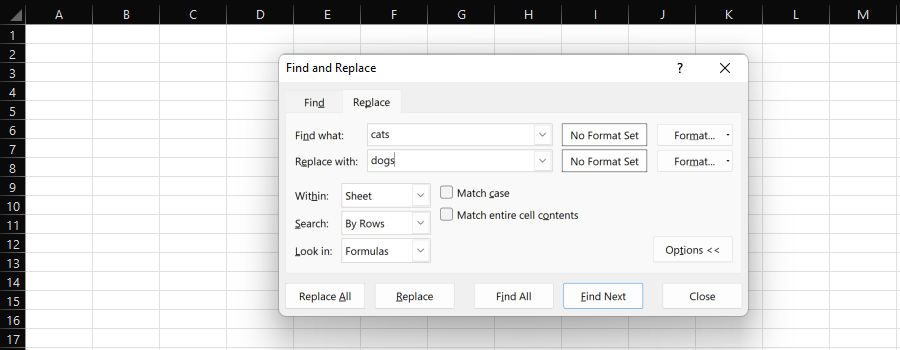 Cuplikan layar dari Microsoft Excel, November 2022
Cuplikan layar dari Microsoft Excel, November 2022
Saat memproses data untuk SEO, kami kemungkinan besar akan memilih seluruh kolom dan "Ganti Semua".
Rumus SUBSTITUTE menyediakan opsi lain di sini dan berguna jika Anda tidak ingin menimpa kolom yang sudah ada.
Sebagai contoh, kita dapat mengubah protokol URL dari HTTP ke HTTPS, atau menghapusnya dengan menggantinya dengan nol.
Saat bekerja dengan kerangka data dengan Python, kita bisa menggunakan str.replace:
df['URL'] = df['URL'].str.replace('http://', 'https://')Atau:
df['URL'] = df['URL'].str.replace('http://', '') # ganti dengan tidak adaSekali lagi, tidak seperti Excel, regex dapat digunakan – seperti dengan REGEXREPLACE Google Sheets:
df['URL'] = df['URL'].str.replace('http://|https://', '')Atau, jika Anda ingin mengganti banyak substring dengan nilai yang berbeda, Anda dapat menggunakan metode ganti Python dan memberikan daftar.
Ini mencegah Anda dari keharusan menghubungkan beberapa fungsi str.replace:
df['URL'] = df['URL'].replace(['http://', ' https://'], ['https://www.', 'https://www.' ], regex=Benar)
KIRI/TENGAH/KANAN
Mengekstrak substring di dalam Excel memerlukan penggunaan fungsi LEFT, MID, atau RIGHT, tergantung di mana substring berada di dalam sel.

Katakanlah kita ingin mengekstrak domain root dan subdomain dari URL:
=MID(A2,CARI(":",A2,4)+3,CARI("/",A2,9)-CARI(":",A2,4)-3) 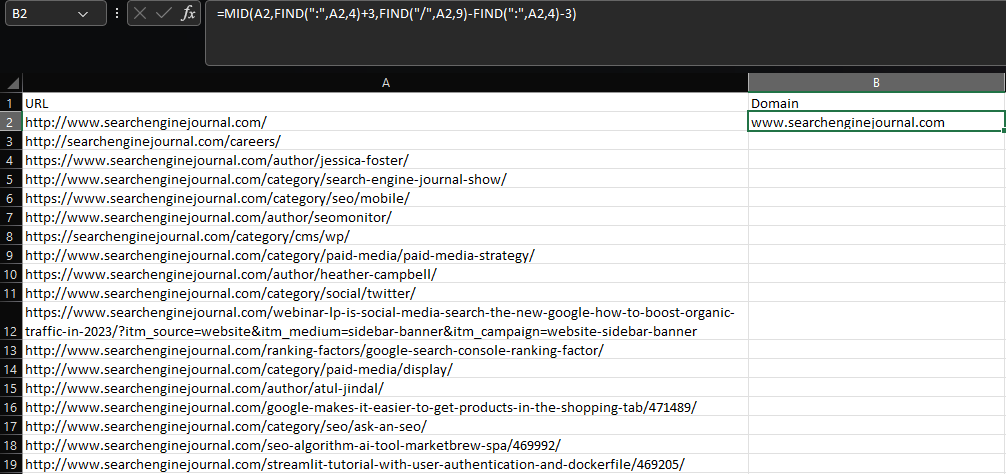 Cuplikan layar dari Microsoft Excel, November 2022
Cuplikan layar dari Microsoft Excel, November 2022
Menggunakan kombinasi MID dan beberapa fungsi FIND, formula ini jelek, untuk sedikitnya – dan hal-hal menjadi jauh lebih buruk untuk ekstraksi yang lebih kompleks.
Sekali lagi, Google Sheets melakukannya lebih baik daripada Excel, karena memiliki REGEXEXTRACT.
Sayang sekali ketika Anda memberinya kumpulan data yang lebih besar, itu meleleh lebih cepat daripada Babybel di radiator panas.
Untungnya, Pandas menawarkan str.extract, yang bekerja dengan cara serupa:
df['Domain'] = df['URL'].str.extract('.*\://?([^\/]+)')  Tangkapan layar dari VS Code, November 2022
Tangkapan layar dari VS Code, November 2022
Kombinasikan dengan fillna untuk mencegah nilai nol, seperti yang Anda lakukan di Excel dengan IFERROR:
df['Domain'] = df['URL'].str.extract('.*\://?([^\/]+)').fillna('-')Jika
Pernyataan IF memungkinkan Anda mengembalikan nilai yang berbeda, bergantung pada terpenuhi atau tidaknya suatu kondisi.
Sebagai ilustrasi, misalkan kita ingin membuat label untuk kata kunci yang berperingkat dalam tiga posisi teratas.
 Cuplikan layar dari Microsoft Excel, November 2022
Cuplikan layar dari Microsoft Excel, November 2022
Daripada menggunakan Pandas dalam contoh ini, kita dapat mengandalkan NumPy dan fungsi where (ingat untuk mengimpor NumPy, jika Anda belum melakukannya):
df['Top 3'] = np.where(df['Position'] <= 3, 'Top 3', 'Not Top 3')
Beberapa ketentuan dapat digunakan untuk evaluasi yang sama dengan menggunakan operator AND/OR, dan menyertakan kriteria individu dalam tanda kurung bulat:
df['Top 3'] = np.where((df['Position'] <= 3) & (df['Position'] != 0), 'Top 3', 'Not Top 3')
Di atas, kami mengembalikan "Top 3" untuk kata kunci apa pun dengan peringkat kurang dari atau sama dengan tiga, tidak termasuk peringkat kata kunci apa pun di posisi nol.
JIKA
Terkadang, daripada menentukan beberapa ketentuan untuk evaluasi yang sama, Anda mungkin menginginkan beberapa ketentuan yang mengembalikan nilai berbeda.
Dalam hal ini, solusi terbaik adalah menggunakan IFS:
=IFS(B2<=3,"3 Teratas",B2<=10,"10 Teratas",B2<=20,"20 Teratas")
 Cuplikan layar dari Microsoft Excel, November 2022
Cuplikan layar dari Microsoft Excel, November 2022
Sekali lagi, NumPy memberi kami solusi terbaik saat bekerja dengan kerangka data, melalui fungsi pilihnya.
Dengan pilih, kita dapat membuat daftar kondisi, pilihan, dan nilai opsional ketika semua kondisi salah:
kondisi = [df['Posisi'] <= 3, df['Posisi'] <= 10, df['Posisi'] <=20] pilihan = ['Top 3', 'Top 10', 'Top 20'] df['Rank'] = np.select(kondisi, pilihan, 'Bukan Top 20')
Dimungkinkan juga untuk memiliki beberapa ketentuan untuk setiap evaluasi.
Katakanlah kita sedang bekerja dengan pengecer e-niaga dengan halaman cantuman produk (PLP) dan halaman tampilan produk (PDP), dan kami ingin memberi label jenis peringkat halaman bermerek dalam 10 hasil teratas.
Solusi termudah di sini adalah mencari pola URL tertentu, seperti subfolder atau ekstensi, tetapi bagaimana jika pesaing memiliki pola serupa?
Dalam skenario ini, kita dapat melakukan sesuatu seperti ini:
kondisi = [(df['URL'].str.berisi('/kategori/')) & (df['Peringkat Merek'] > 0),
(df['URL'].str.contains('/produk/')) & (df['Peringkat Merek'] > 0),
(~df['URL'].str.contains('/product/')) & (~df['URL'].str.contains('/category/')) & (df['Brand Rank'] > 0)]
pilihan = ['PLP', 'PDP', 'Lainnya']
df['Brand Page Type'] = np.select(kondisi, pilihan, Tidak ada)Di atas, kami menggunakan str.contains untuk mengevaluasi apakah URL di 10 besar cocok atau tidak dengan pola merek kami, kemudian menggunakan kolom "Peringkat Merek" untuk mengecualikan pesaing.
Dalam contoh ini, tanda tilde (~) menunjukkan kecocokan negatif. Dengan kata lain, kami ingin setiap URL merek yang tidak cocok dengan pola "PDP" atau "PLP" cocok dengan kriteria untuk 'Lainnya'.
Terakhir, Tidak ada yang disertakan karena kami ingin hasil non-merek mengembalikan nilai nol.
 Tangkapan layar dari VS Code, November 2022
Tangkapan layar dari VS Code, November 2022
VLOOKUP
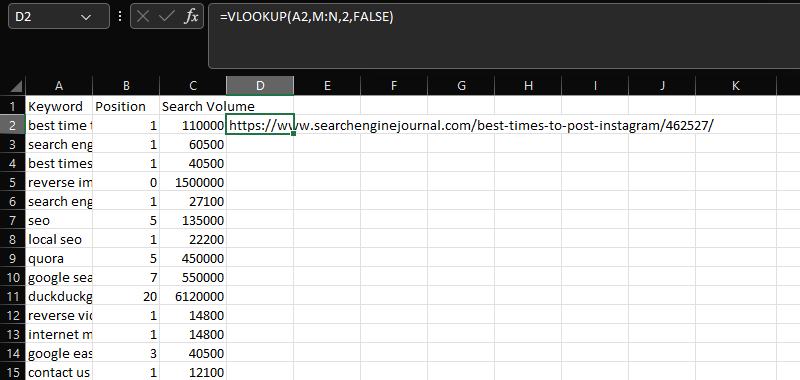
VLOOKUP adalah alat penting untuk menggabungkan dua kumpulan data berbeda pada kolom umum.
Dalam hal ini, tambahkan URL dalam kolom N ke data kata kunci, posisi, dan volume pencarian di kolom AC, menggunakan kolom "Kata Kunci" bersama:
=VLOOKUP(A2,M:N,2,FALSE)
 Cuplikan layar dari Microsoft Excel, November 2022
Cuplikan layar dari Microsoft Excel, November 2022
Untuk melakukan sesuatu yang mirip dengan Panda, kita bisa menggunakan penggabungan.
Mereplikasi fungsi gabungan SQL, penggabungan adalah fungsi yang sangat kuat yang mendukung berbagai jenis gabungan yang berbeda.
Untuk tujuan kami, kami ingin menggunakan gabungan kiri, yang akan mempertahankan kerangka data pertama kami dan hanya menggabungkan nilai yang cocok dari kerangka data kedua kami:
mergeddf = df.merge(df2, how='left', on='Keyword')
Satu keuntungan tambahan dari melakukan penggabungan melalui VLOOKUP, adalah Anda tidak harus memiliki data bersama di kolom pertama dari kumpulan data kedua, seperti pada XLOOKUP yang lebih baru.
Itu juga akan menarik banyak baris data daripada kecocokan pertama dalam penemuan.
Salah satu masalah umum saat menggunakan fungsi ini adalah kolom yang tidak diinginkan digandakan. Hal ini terjadi ketika ada beberapa kolom bersama, tetapi Anda berusaha untuk mencocokkan menggunakan satu.
Untuk mencegah hal ini – dan meningkatkan keakuratan kecocokan Anda – Anda dapat menentukan daftar kolom:
mergeddf = df.merge(df2, how='left', on=['Keyword', 'Search Volume'])
Dalam skenario tertentu, Anda mungkin secara aktif ingin kolom ini disertakan. Misalnya, saat mencoba menggabungkan beberapa laporan peringkat bulanan:
mergeddf = df.merge(df2, on='Keyword', how='left', suffixes=('', '_october'))\
.merge(df3, on='Keyword', how='left', suffixes=('', '_september'))Cuplikan kode di atas menjalankan dua penggabungan untuk menggabungkan tiga kerangka data dengan kolom yang sama – yang merupakan peringkat kami untuk November, Oktober, dan September.
Dengan memberi label bulan dalam parameter akhiran, kita berakhir dengan kerangka data yang jauh lebih bersih yang menampilkan bulan dengan jelas, berlawanan dengan default _x dan _y yang terlihat pada contoh sebelumnya.
 Tangkapan layar dari VS Code, November 2022
Tangkapan layar dari VS Code, November 2022
COUNTIF/SUMIF/AVERAGEIF
Di Excel, jika Anda ingin menjalankan fungsi statistik berdasarkan kondisi, kemungkinan besar Anda akan menggunakan COUNTIF, SUMIF, atau AVERAGEIF.
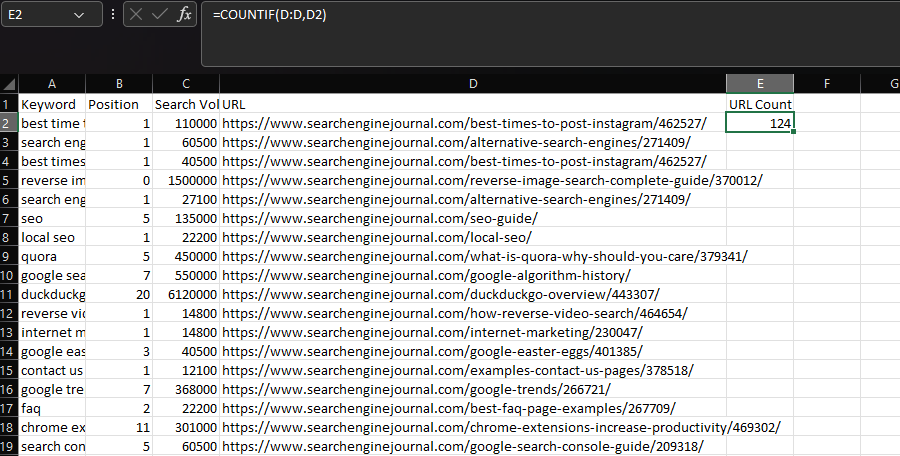
Umumnya, COUNTIF digunakan untuk menentukan berapa kali string tertentu muncul dalam kumpulan data, seperti URL.
Kami dapat melakukannya dengan mendeklarasikan kolom 'URL' sebagai rentang kami, lalu URL dalam sel individual sebagai kriteria kami:
=COUNTIF(D:D,D2)
 Cuplikan layar dari Microsoft Excel, November 2022
Cuplikan layar dari Microsoft Excel, November 2022
Di Pandas, kita dapat mencapai hasil yang sama dengan menggunakan fungsi groupby:
df.groupby('URL')['URL'].count()  Tangkapan layar dari VS Code, November 2022
Tangkapan layar dari VS Code, November 2022
Di sini, kolom yang dinyatakan dalam tanda kurung bulat menunjukkan kelompok individu, dan kolom yang tercantum dalam tanda kurung siku adalah tempat agregasi (yaitu penghitungan) dilakukan.
Keluaran yang kami terima tidak sempurna untuk kasus penggunaan ini, karena menggabungkan data.
Biasanya, saat menggunakan Excel, kami memiliki jumlah URL sebaris dalam kumpulan data kami. Kemudian kita dapat menggunakannya untuk memfilter ke URL yang paling sering dicantumkan.
Untuk melakukan ini, gunakan transformasi dan simpan hasilnya dalam kolom:
df['Jumlah URL'] = df.groupby('URL')['URL'].transform('hitung')  Tangkapan layar dari VS Code, November 2022
Tangkapan layar dari VS Code, November 2022
Anda juga dapat menerapkan fungsi kustom ke grup data dengan menggunakan fungsi lambda (anonim):
df['Google Count'] = df.groupby(['URL'])['URL'].transform(lambda x: x[x.str.contains('google')].count())Dalam contoh kami sejauh ini, kami telah menggunakan kolom yang sama untuk pengelompokan dan agregasi kami, tetapi kami tidak harus melakukannya. Sama halnya dengan COUNTIFS/SUMIFS/AVERAGEIFS di Excel, dimungkinkan untuk mengelompokkan menggunakan satu kolom, lalu menerapkan fungsi statistik kami ke kolom lainnya.
Kembali ke contoh halaman hasil mesin pencari (SERP) sebelumnya, kami mungkin ingin menghitung semua peringkat PDP per kata kunci dan mengembalikan nomor ini bersama data kami yang ada:
df['PDP Count'] = df.groupby(['Keyword'])['URL'].transform(lambda x: x[x.str.contains('/product/|/prd/|/pd/' )].menghitung())  Tangkapan layar dari VS Code, November 2022
Tangkapan layar dari VS Code, November 2022Yang dalam bahasa Excel, akan terlihat seperti ini:
=SUM(COUNTIFS(A:A,[@Kata Kunci],D:D,{"*/produk/*","*/prd/*","*/pd/*"}))
Tabel pivot
Terakhir, namun tidak kalah pentingnya, saatnya membicarakan tabel pivot.
Di Excel, tabel pivot kemungkinan akan menjadi tujuan pertama kami jika kami ingin meringkas kumpulan data yang besar.
Misalnya, saat bekerja dengan data peringkat, kami mungkin ingin mengidentifikasi URL mana yang paling sering muncul, dan posisi peringkat rata-ratanya.
 Cuplikan layar dari Microsoft Excel, November 2022
Cuplikan layar dari Microsoft Excel, November 2022
Sekali lagi, Pandas memiliki persamaan tabel pivotnya sendiri – tetapi jika yang Anda inginkan hanyalah menghitung nilai unik dalam kolom, ini dapat dicapai dengan menggunakan fungsi value_counts :
hitungan = df['URL'].value_counts()
Menggunakan groupby juga merupakan pilihan.
Di awal artikel, melakukan groupby yang menggabungkan data kita bukanlah yang kita inginkan – tetapi justru itulah yang diperlukan di sini:
dikelompokkan = df.groupby('URL').agg(
url_frequency=('Kata Kunci', 'jumlah'),
avg_position=('Posisi', 'rata-rata'),
)
dikelompokkan.reset_index(inplace=True)  Tangkapan layar dari VS Code, November 2022
Tangkapan layar dari VS Code, November 2022
Dua fungsi agregat telah diterapkan dalam contoh di atas, tetapi ini dapat dengan mudah diperluas, dan tersedia 13 jenis yang berbeda.
Tentu saja ada kalanya kita ingin menggunakan pivot_table, seperti saat melakukan operasi multidimensi.
Untuk mengilustrasikan apa artinya ini, mari gunakan kembali pengelompokan peringkat yang kita buat menggunakan pernyataan bersyarat dan coba tampilkan berapa kali peringkat URL dalam setiap grup.
ranking_groupings = df.groupby(['URL', 'Pengelompokan']).agg(
url_frequency=('Kata Kunci', 'jumlah'),
)  Tangkapan layar dari VS Code, November 2022
Tangkapan layar dari VS Code, November 2022
Ini bukan format terbaik untuk digunakan, karena beberapa baris telah dibuat untuk setiap URL.
Sebaliknya, kita dapat menggunakan pivot_table, yang akan menampilkan data dalam kolom yang berbeda:
pivot = pd.pivot_table(df, indeks=['URL'], kolom=['Pengelompokan'], aggfunc='ukuran', isi_nilai=0, )
 Tangkapan layar dari VS Code, November 2022
Tangkapan layar dari VS Code, November 2022
Pikiran Akhir
Apakah Anda sedang mencari inspirasi untuk mulai belajar Python, atau sudah memanfaatkannya dalam alur kerja SEO Anda, saya harap contoh di atas membantu Anda dalam perjalanan Anda.
Seperti yang dijanjikan, Anda dapat menemukan notebook Google Colab dengan semua cuplikan kodenya di sini.
Sebenarnya, kami baru saja menggores permukaan dari apa yang mungkin, tetapi memahami dasar-dasar analisis data Python akan memberi Anda dasar yang kuat untuk membangun.
Lebih banyak sumber daya:
- Coba Alat & Metode Ini Untuk Mengekspor Hasil Pencarian Google Ke Excel
- 12 Poin Data SEO Penting Untuk Situs Web Apa Pun
- SEO Teknis Tingkat Lanjut: Panduan Lengkap
Gambar Unggulan: mapo_japan/Shutterstock