
Tranziția de la Excel la Python: Funcții esențiale pentru analiza datelor SEO
Publicat: 2022-12-02Învățarea codificării, fie cu Python, JavaScript sau alt limbaj de programare, are o serie întreagă de beneficii, inclusiv capacitatea de a lucra cu seturi de date mai mari și de a automatiza sarcini repetitive.
Dar, în ciuda beneficiilor, mulți profesioniști SEO nu au făcut încă tranziția - și înțeleg perfect de ce! Nu este o abilitate esențială pentru SEO și suntem cu toții oameni ocupați.
Dacă ești presat de timp și știi deja cum să îndeplinești o sarcină în Excel sau Google Sheets, atunci schimbarea tact poate fi ca și cum ai reinventa roata.
Când am început să codez, inițial am folosit Python doar pentru sarcini pe care nu le-am putut realiza în Excel – și au durat câțiva ani pentru a ajunge la punctul în care este alegerea mea de facto pentru procesarea datelor.
Privind în urmă, sunt incredibil de bucuros că am persistat, dar uneori a fost o experiență frustrantă, cu multe ore petrecute scanând firele pe Stack Overflow.
Această postare este concepută pentru a scuti alți profesioniști SEO de aceeași soartă.
În cadrul acestuia, vom acoperi echivalentele Python ale formulelor și funcțiilor Excel cele mai frecvent utilizate pentru analiza datelor SEO – toate acestea sunt disponibile într-un blocnotes Google Colab legat în rezumat.
Mai exact, veți învăța echivalentele:
- LEN.
- Eliminați duplicatele.
- Text la coloane.
- CĂUTARE/GĂSIȚI.
- ÎNLĂNŢUI.
- Găsiți și înlocuiți.
- STÂNGA/MIJLOCUL/DREAPTA.
- DACĂ.
- IFS.
- CĂUTARE V.
- COUNTIF/SUMIF/AVERAGEIF.
- Tabele pivot.
În mod uimitor, pentru a realiza toate acestea, vom folosi în primul rând o bibliotecă singulară – Pandas – cu puțin ajutor în anumite locuri de la fratele său mai mare, NumPy.
Cerințe preliminare
De dragul conciziei, există câteva lucruri pe care nu le vom acoperi astăzi, inclusiv:
- Instalarea Python.
- Pandas de bază, cum ar fi importarea fișierelor CSV, filtrarea și previzualizarea cadrelor de date.
Dacă nu sunteți sigur despre oricare dintre acestea, atunci ghidul lui Hamlet despre analiza datelor Python pentru SEO este amorsa perfectă.
Acum, fără alte prelungiri, să intrăm.
LEN
LEN oferă o contorizare a numărului de caractere dintr-un șir de text.
În special pentru SEO, un caz obișnuit de utilizare este măsurarea lungimii etichetelor de titlu sau meta descrierilor pentru a determina dacă acestea vor fi trunchiate în rezultatele căutării.
În Excel, dacă am dori să numărăm a doua celulă a coloanei A, am introduce:
=LEN(A2)
 Captură de ecran din Microsoft Excel, noiembrie 2022
Captură de ecran din Microsoft Excel, noiembrie 2022
Python nu este prea diferit, deoarece ne putem baza pe funcția len încorporată, care poate fi combinată cu loc[] al lui Pandas pentru a accesa un anumit rând de date dintr-o coloană:
len(df['Titlu'].loc[0])
În acest exemplu, obținem lungimea primului rând din coloana „Titlu” a cadrului de date.

- Captură de ecran a VS Code, noiembrie 2022
Totuși, găsirea lungimii unei celule nu este atât de utilă pentru SEO. În mod normal, am dori să aplicăm o funcție unei întregi coloane!
În Excel, acest lucru ar fi realizat prin selectarea celulei formulei din colțul din dreapta jos și fie trăgând-o în jos, fie făcând dublu clic.
Când lucrăm cu un cadru de date Pandas, putem folosi str.len pentru a calcula lungimea rândurilor dintr-o serie, apoi stocăm rezultatele într-o nouă coloană:
df['Lungime'] = df['Titlu'].str.len()
Str.len este o operație „vectorizată”, care este concepută pentru a fi aplicată simultan unei serii de valori. Vom folosi aceste operațiuni pe scară largă pe parcursul acestui articol, deoarece aproape universal ajung să fie mai rapide decât o buclă.
O altă aplicație comună a LEN este să o combinați cu SUBSTITUTE pentru a număra numărul de cuvinte dintr-o celulă:
=LEN(TRIM(A2))-LEN(SUBSTITUT(A2," ",""))+1
În Pandas, putem realiza acest lucru combinând funcțiile str.split și str.len împreună:
df['Nu. Cuvinte'] = df['Titlu'].str.split().str.len()
Vom acoperi str.split mai în detaliu mai târziu, dar, în esență, ceea ce facem este să ne împărțim datele pe baza spațiilor albe din șir, apoi să numărăm numărul de părți componente.
 Captură de ecran din VS Code, noiembrie 2022
Captură de ecran din VS Code, noiembrie 2022
Eliminarea duplicatelor
Funcția „Eliminați duplicatele” din Excel oferă o modalitate ușoară de a elimina valorile duplicate dintr-un set de date, fie prin ștergerea completă a rândurilor duplicate (când sunt selectate toate coloanele), fie prin eliminarea rândurilor cu aceleași valori în anumite coloane.
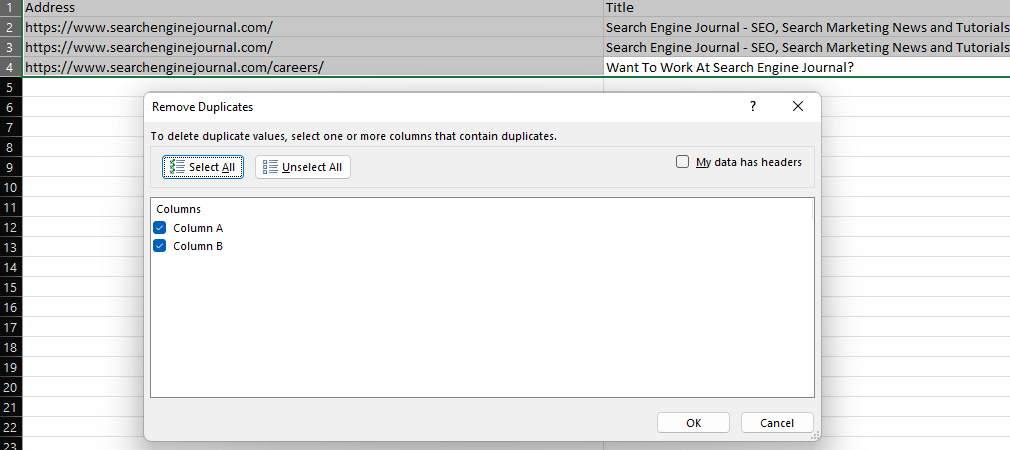 Captură de ecran din Microsoft Excel, noiembrie 2022
Captură de ecran din Microsoft Excel, noiembrie 2022
În Pandas, această funcționalitate este oferită de drop_duplicates.
Pentru a elimina rândurile duplicate într-un tip de cadru de date:
df.drop_duplicates(inplace=True)
Pentru a elimina rânduri bazate pe duplicate într-o singură coloană, includeți parametrul subsetului:
df.drop_duplicates(subset='coloană', inplace=True)
Sau specificați mai multe coloane într-o listă:
df.drop_duplicates(subset=['coloană','coloană2'], inplace=True)
O adăugare de mai sus care merită menționată este prezența parametrului inplace. Includerea inplace=True ne permite să suprascriem cadrul de date existent fără a fi nevoie să creăm unul nou.
Există, desigur, momente în care dorim să ne păstrăm datele brute. În acest caz, putem aloca cadrul de date deduplicat unei variabile diferite:
df2 = df.drop_duplicates(subset='coloană')
Text în coloane
Un alt element esențial de zi cu zi, funcția „text în coloane” poate fi folosită pentru a împărți un șir de text pe baza unui delimitator, cum ar fi o bară oblică, virgulă sau spațiu alb.
De exemplu, împărțirea unei adrese URL în domeniul său și subfolderele individuale.
 Captură de ecran din Microsoft Excel, noiembrie 2022
Captură de ecran din Microsoft Excel, noiembrie 2022
Când avem de-a face cu un cadru de date, putem folosi funcția str.split, care creează o listă pentru fiecare intrare dintr-o serie. Aceasta poate fi convertită în mai multe coloane setând parametrul de extindere la True:
df['URL'].str.split(pat='/', expand=True)
 Captură de ecran din VS Code, noiembrie 2022
Captură de ecran din VS Code, noiembrie 2022
După cum se întâmplă adesea, adresele URL din imaginea de mai sus au fost împărțite în coloane inconsistente, deoarece nu prezintă același număr de dosare.
Acest lucru poate face lucrurile dificile atunci când dorim să ne salvăm datele într-un cadru de date existent.
Specificarea parametrului n limitează numărul de împărțiri, permițându-ne să creăm un anumit număr de coloane:
df[['Domeniu', 'Folder1', 'Folder2', 'Folder3']] = df['URL'].str.split(pat='/', expand=True, n=3)
O altă opțiune este să utilizați pop pentru a vă elimina coloana din cadrul de date, pentru a efectua împărțirea și apoi adăugați-o din nou cu funcția de unire:
df = df.join(df.pop('Split').str.split(pat='/', expand=True))Duplicarea adresei URL într-o nouă coloană înainte de împărțire ne permite să păstrăm adresa URL completă. Putem apoi redenumi noile coloane:🐆
df['Split'] = df['URL']
df = df.join(df.pop('Split').str.split(pat='/', expand=True))
df.rename(coloane = {0:'Domeniu', 1:'Folder1', 2:'Folder2', 3:'Folder3', 4:'Parameter'}, inplace=True) 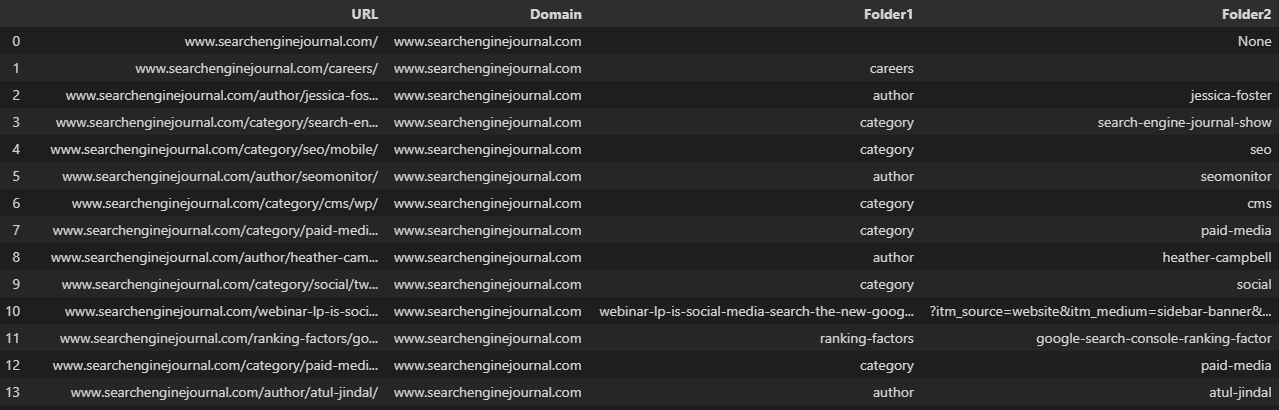 Captură de ecran din VS Code, noiembrie 2022
Captură de ecran din VS Code, noiembrie 2022
ÎNLĂNŢUI
Funcția CONCAT permite utilizatorilor să combine mai multe șiruri de text, cum ar fi atunci când generează o listă de cuvinte cheie adăugând diferiți modificatori.
În acest caz, adăugăm „bărbați” și spații albe la lista de tipuri de produse a coloanei A:
=CONCAT($F$1," ",A2)

- Captură de ecran din Microsoft Excel, noiembrie 2022
Presupunând că avem de-a face cu șiruri de caractere, același lucru se poate realiza în Python folosind operatorul aritmetic:
df['Combinat] = 'bărbați' + '' + df['Cuvânt cheie']
Sau specificați mai multe coloane de date:
df['Combinat'] = df['Subdomeniu'] + df['URL']
 Captură de ecran din VS Code, noiembrie 2022
Captură de ecran din VS Code, noiembrie 2022
Pandas are o funcție concat dedicată, dar aceasta este mai utilă atunci când încercați să combinați mai multe cadre de date cu aceleași coloane.
De exemplu, dacă am avut mai multe exporturi din instrumentul nostru preferat de analiză a linkurilor:
df = pd.read_csv('data.csv')
df2 = pd.read_csv('data2.csv')
df3 = pd.read_csv('data3.csv')
dflist = [df, df2, df3]
df = pd.concat(dflist, ignore_index=True)CĂUTARE/GAȚI
Formulele SEARCH și FIND oferă o modalitate de a localiza un subșir într-un șir de text.
Aceste comenzi sunt în mod obișnuit combinate cu ISNUMBER pentru a crea o coloană booleană care ajută la filtrarea unui set de date, ceea ce poate fi extrem de util atunci când efectuați sarcini precum analiza fișierului jurnal, așa cum este explicat în acest ghid. De exemplu:
=ISNUMĂR(CĂUTARE(„căutați acest lucru”, A2)
 Captură de ecran din Microsoft Excel, noiembrie 2022
Captură de ecran din Microsoft Excel, noiembrie 2022
Diferența dintre SEARCH și FIND este că găsirea face distincție între majuscule și minuscule.
Funcția Pandas echivalentă, str.contains, face distincția implicită între majuscule și minuscule:
df['Jurnal'] = df['URL'].str.contains('motor', na=False)Insensibilitatea majusculelor poate fi activată prin setarea parametrului casei la Fals:
df['Journal'] = df['URL'].str.contains('motor', case=False, na=False)În oricare dintre scenarii, includerea na=False va împiedica returnarea valorilor nule în coloana booleană.
Un avantaj enorm al folosirii Pandas aici este că, spre deosebire de Excel, regex este suportat nativ de această funcție - așa cum este în foile Google prin REGEXMATCH.
Înlănțuiți mai multe subșiruri folosind caracterul pipe, cunoscut și sub numele de operator OR:
df['Jurnal'] = df['URL'].str.contains('motor|căutare', na=False)Găsiți și înlocuiți
Funcția Excel „Găsiți și înlocuiți” oferă o modalitate ușoară de a înlocui individual sau în bloc un subșir cu altul.
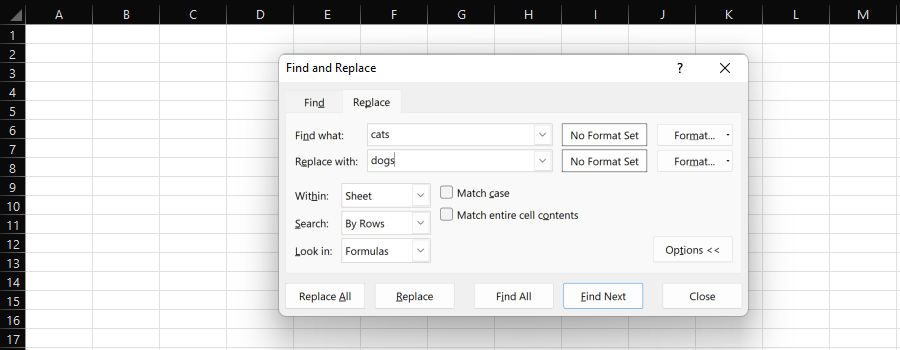 Captură de ecran din Microsoft Excel, noiembrie 2022
Captură de ecran din Microsoft Excel, noiembrie 2022
Când procesăm date pentru SEO, este cel mai probabil să selectăm o întreagă coloană și „Înlocuiește-le pe toate”.
Formula SUBSTITUTE oferă o altă opțiune aici și este utilă dacă nu doriți să suprascrieți coloana existentă.
De exemplu, putem schimba protocolul unui URL din HTTP în HTTPS sau îl putem elimina prin înlocuirea cu nimic.
Când lucrăm cu cadre de date în Python, putem folosi str.replace:
df['URL'] = df['URL'].str.replace('http://', 'https://')Sau:
df['URL'] = df['URL'].str.replace('http://', '') # înlocuiți cu nimicDin nou, spre deosebire de Excel, regex poate fi folosit - ca și cu REGEXREPLACE din Foi de calcul Google:
df['URL'] = df['URL'].str.replace('http://|https://', '')Alternativ, dacă doriți să înlocuiți mai multe subșiruri cu valori diferite, puteți utiliza metoda de înlocuire a lui Python și puteți furniza o listă.
Acest lucru vă împiedică să înlănțuiți mai multe funcții str.replace:
df['URL'] = df['URL'].replace(['http://', 'https://'], ['https://www.', 'https://www.' ], regex=Adevărat)
STÂNGA/MIJLOCUL/DREAPTA
Extragerea unui subșir în Excel necesită utilizarea funcțiilor LEFT, MID sau RIGHT, în funcție de locul în care se află subșirul într-o celulă.

Să presupunem că vrem să extragem domeniul rădăcină și subdomeniul dintr-o adresă URL:
=MID(A2,GĂUTĂ(":",A2,4)+3,GĂSĂ("/",A2,9)-GĂSĂ(":",A2,4)-3) 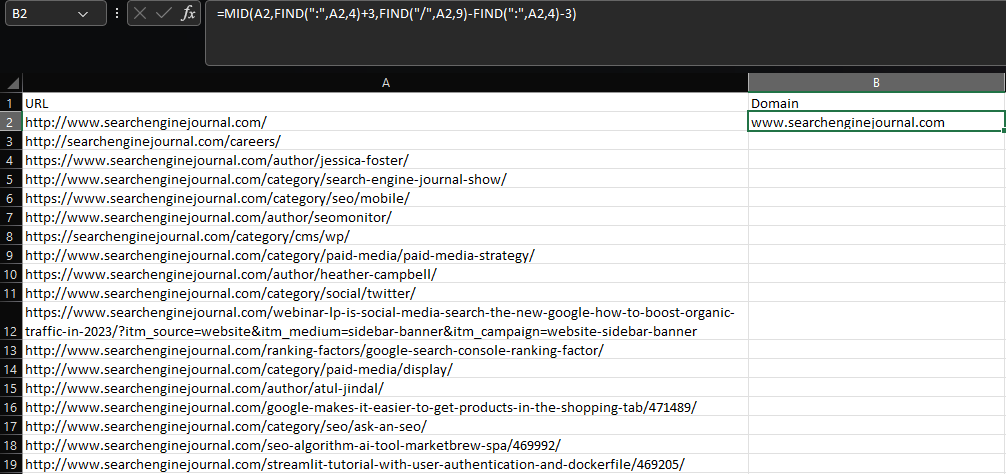 Captură de ecran din Microsoft Excel, noiembrie 2022
Captură de ecran din Microsoft Excel, noiembrie 2022
Folosind o combinație de funcții MID și multiple FIND, această formulă este cel puțin urâtă, iar lucrurile se înrăutățesc mult pentru extracții mai complexe.
Din nou, Google Sheets face acest lucru mai bine decât Excel, deoarece are REGEXEXTRACT.
Ce păcat că atunci când îl alimentezi cu seturi de date mai mari, se topește mai repede decât un Babybel pe un calorifer fierbinte.
Din fericire, Pandas oferă str.extract, care funcționează într-un mod similar:
df['Domeniu'] = df['URL'].str.extract('.*\://?([^\/]+)')  Captură de ecran din VS Code, noiembrie 2022
Captură de ecran din VS Code, noiembrie 2022
Combinați cu fillna pentru a preveni valorile nule, așa cum ați proceda în Excel cu IFERROR:
df['Domeniu'] = df['URL'].str.extract('.*\://?([^\/]+)').fillna('-')Dacă
Instrucțiunile IF vă permit să returnați valori diferite, în funcție de îndeplinirea sau nu a unei condiții.
Pentru a exemplifica, să presupunem că vrem să creăm o etichetă pentru cuvintele cheie care se clasifică în primele trei poziții.
 Captură de ecran din Microsoft Excel, noiembrie 2022
Captură de ecran din Microsoft Excel, noiembrie 2022
În loc să folosim Pandas în acest caz, ne putem baza pe NumPy și pe funcția where (nu uitați să importați NumPy, dacă nu ați făcut-o deja):
df['Top 3'] = np.where(df['Pozition'] <= 3, 'Top 3', 'Nut Top 3')
Mai multe condiții pot fi utilizate pentru aceeași evaluare prin utilizarea operatorilor AND/OR și includerea criteriilor individuale între paranteze rotunde:
df['Top 3'] = np.where((df['Pozition'] <= 3) & (df['Top 3'] != 0), 'Top 3', 'Nut Top 3')
În cele de mai sus, returnăm „Top 3” pentru orice cuvinte cheie cu o clasare mai mică sau egală cu trei, excluzând orice cuvinte cheie care se clasifică în poziția zero.
IFS
Uneori, în loc să specificați mai multe condiții pentru aceeași evaluare, este posibil să doriți mai multe condiții care returnează valori diferite.
În acest caz, cea mai bună soluție este utilizarea IFS:
=IFS(B2<=3, „Top 3”, B2<=10, „Top 10”, B2<=20, „Top 20”)
 Captură de ecran din Microsoft Excel, noiembrie 2022
Captură de ecran din Microsoft Excel, noiembrie 2022
Din nou, NumPy ne oferă cea mai bună soluție atunci când lucrăm cu cadre de date, prin funcția de selectare.
Cu select, putem crea o listă de condiții, opțiuni și o valoare opțională pentru atunci când toate condițiile sunt false:
condiții = [df['Poziție'] <= 3, df['Poziție'] <= 10, df['Poziție'] <=20] opțiuni = [„Top 3”, „Top 10”, „Top 20”] df['Rank'] = np.select(condiții, opțiuni, 'Nu este Top 20')
De asemenea, este posibil să existe mai multe condiții pentru fiecare dintre evaluări.
Să presupunem că lucrăm cu un comerciant cu amănuntul de comerț electronic cu pagini de listare a produselor (PLP) și pagini de afișare a produselor (PDP) și dorim să etichetăm tipul de pagini de marcă clasate în primele 10 rezultate.
Cea mai ușoară soluție aici este să căutați modele URL specifice, cum ar fi un subdosar sau o extensie, dar ce se întâmplă dacă concurenții au modele similare?
În acest scenariu, am putea face ceva de genul acesta:
condiții = [(df['URL'].str.contains('/category/')) & (df['Brand Rank'] > 0),
(df['URL'].str.contains('/product/')) & (df['Brand Rank'] > 0),
(~df['URL'].str.contains('/product/')) & (~df['URL'].str.contains('/category/')) & (df['Brand Rank'] > 0)]
alegeri = ['PLP', 'PDP', 'Other']
df['Tipul paginii de marcă'] = np.select(condiții, opțiuni, Nici unul)Mai sus, folosim str.contains pentru a evalua dacă o adresă URL din primele 10 se potrivește sau nu cu modelul mărcii noastre, apoi folosim coloana „Clasarea mărcii” pentru a exclude orice concurență.
În acest exemplu, semnul tilde (~) indică o potrivire negativă. Cu alte cuvinte, spunem că vrem ca fiecare adresă URL a mărcii care nu se potrivește cu modelul „PDP” sau „PLP” să corespundă criteriilor pentru „Altul”.
În cele din urmă, None este inclus deoarece dorim ca rezultatele non-brand să returneze o valoare nulă.
 Captură de ecran din VS Code, noiembrie 2022
Captură de ecran din VS Code, noiembrie 2022
CĂUTARE V
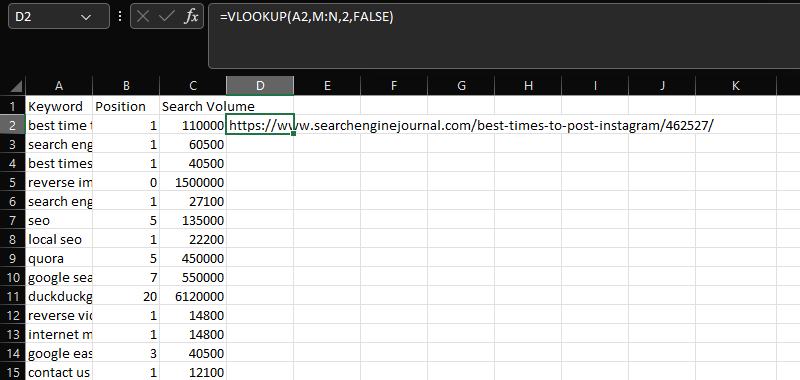
VLOOKUP este un instrument esențial pentru unirea a două seturi de date distincte pe o coloană comună.
În acest caz, adăugarea adreselor URL din coloana N la datele de cuvinte cheie, poziție și volumul de căutare din coloanele AC, folosind coloana „Cuvânt cheie” comun:
=CĂUTAREV(A2,M:N,2,FALSE)
 Captură de ecran din Microsoft Excel, noiembrie 2022
Captură de ecran din Microsoft Excel, noiembrie 2022
Pentru a face ceva similar cu Pandas, putem folosi merge.
Replicând funcționalitatea unei îmbinări SQL, merge este o funcție incredibil de puternică care acceptă o varietate de tipuri diferite de îmbinare.
În scopurile noastre, dorim să folosim o îmbinare stângă, care va menține primul nostru cadru de date și va îmbina doar valorile care se potrivesc din cel de-al doilea cadru de date:
mergeddf = df.merge(df2, how='left', on='Keyword')
Un avantaj suplimentar al efectuării unei îmbinări peste o CĂUTARE V, este că nu trebuie să aveți datele partajate în prima coloană a celui de-al doilea set de date, ca și în cazul XLOOKUP mai nou.
De asemenea, va extrage mai multe rânduri de date, mai degrabă decât prima potrivire în găsiri.
O problemă comună atunci când utilizați funcția este duplicarea coloanelor nedorite. Acest lucru se întâmplă atunci când există mai multe coloane partajate, dar încercați să faceți potrivire folosind una.
Pentru a preveni acest lucru - și pentru a îmbunătăți acuratețea potrivirilor dvs. - puteți specifica o listă de coloane:
mergeddf = df.merge(df2, how='left', on=['Keyword', 'Search Volume'])
În anumite scenarii, este posibil să doriți în mod activ ca aceste coloane să fie incluse. De exemplu, atunci când încercați să îmbinați mai multe rapoarte lunare de clasare:
mergeddf = df.merge(df2, on='Cuvânt cheie', cum='stânga', sufixe=('', '_october'))\
.merge(df3, on='Cuvânt cheie', cum='stânga', sufixe=('', '_septembrie'))Fragmentul de cod de mai sus execută două îmbinări pentru a uni trei cadre de date cu aceleași coloane – care sunt clasamentele noastre pentru noiembrie, octombrie și septembrie.
Etichetând lunile în parametrii sufixului, ajungem la un cadru de date mult mai curat, care afișează clar luna, spre deosebire de valorile implicite ale _x și _y văzute în exemplul anterior.
 Captură de ecran din VS Code, noiembrie 2022
Captură de ecran din VS Code, noiembrie 2022
COUNTIF/SUMIF/AVERAGEIF
În Excel, dacă doriți să efectuați o funcție statistică bazată pe o condiție, este posibil să utilizați fie COUNTIF, SUMIF, fie AVERAGEIF.
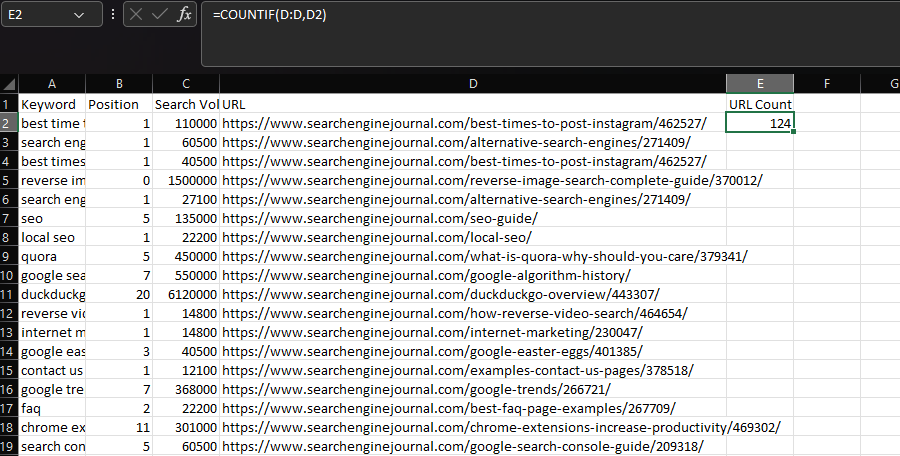
În mod obișnuit, COUNTIF este folosit pentru a determina de câte ori apare un anumit șir într-un set de date, cum ar fi o adresă URL.
Putem realiza acest lucru declarând coloana „URL” ca interval, apoi adresa URL dintr-o celulă individuală ca criteriu:
=COUNTIF(D:D,D2)
 Captură de ecran din Microsoft Excel, noiembrie 2022
Captură de ecran din Microsoft Excel, noiembrie 2022
În Pandas, putem obține același rezultat folosind funcția groupby:
df.groupby('URL')['URL'].count()  Captură de ecran din VS Code, noiembrie 2022
Captură de ecran din VS Code, noiembrie 2022
Aici, coloana declarată între paranteze rotunde indică grupurile individuale, iar coloana listată între paranteze drepte este locul în care se realizează agregarea (adică, numărarea).
Totuși, rezultatul pe care îl primim nu este perfect pentru acest caz de utilizare, deoarece consolidează datele.
În mod obișnuit, atunci când folosim Excel, am avea numărul de adrese URL inline în setul nostru de date. Apoi îl putem folosi pentru a filtra la cele mai frecvente adrese URL listate.
Pentru a face acest lucru, utilizați transform și stocați rezultatul într-o coloană:
df['Număr URL'] = df.groupby('URL')['URL'].transform('count')  Captură de ecran din VS Code, noiembrie 2022
Captură de ecran din VS Code, noiembrie 2022
De asemenea, puteți aplica funcții personalizate la grupuri de date utilizând o funcție lambda (anonimă):
df['Google Count'] = df.groupby(['URL'])['URL'].transform(lambda x: x[x.str.contains('google')].count())În exemplele noastre până acum, am folosit aceeași coloană pentru gruparea și agregarea noastră, dar nu este necesar. În mod similar cu COUNTIFS/SUMIFS/AVERAGEIFS în Excel, este posibil să grupați folosind o coloană, apoi să aplicați funcția noastră statistică la alta.
Revenind la exemplul anterior al paginii cu rezultate ale motorului de căutare (SERP), este posibil să dorim să numărăm toate PDP-urile de clasare pe o bază de cuvânt cheie și să returnăm acest număr alături de datele noastre existente:
df['PDP Count'] = df.groupby(['Keyword'])['URL'].transform(lambda x: x[x.str.contains('/product/|/prd/|/pd/' )].numara())  Captură de ecran din VS Code, noiembrie 2022
Captură de ecran din VS Code, noiembrie 2022Care, în limbajul Excel, ar arăta cam așa:
=SUM(COUNTIFS(A:A,[@Keyword],D:D,{"*/product/*","*/prd/*","*/pd/*"}))
Tabele pivot
Nu în ultimul rând, dar nu în ultimul rând, este timpul să vorbim despre tabelele pivot.
În Excel, un tabel pivot este probabil primul nostru port de apel dacă dorim să rezumam un set de date mare.
De exemplu, atunci când lucrăm cu date de clasare, este posibil să dorim să identificăm care adrese URL apar cel mai frecvent și poziția lor medie în clasament.
 Captură de ecran din Microsoft Excel, noiembrie 2022
Captură de ecran din Microsoft Excel, noiembrie 2022
Din nou, Pandas are propriile sale tabele pivot echivalente - dar dacă tot ce doriți este un număr de valori unice într-o coloană, acest lucru poate fi realizat folosind funcția value_counts:
count = df['URL'].value_counts()
Folosirea groupby este, de asemenea, o opțiune.
Mai devreme în articol, efectuarea unui groupby care ne-a agregat datele nu a fost ceea ce ne-am dorit – dar este exact ceea ce este necesar aici:
grupate = df.groupby('URL').agg(
url_frequency=('Cuvânt cheie', 'număr'),
avg_position=('Poziție', 'medie'),
)
grouped.reset_index(inplace=True)  Captură de ecran din VS Code, noiembrie 2022
Captură de ecran din VS Code, noiembrie 2022
Două funcții agregate au fost aplicate în exemplul de mai sus, dar acestea ar putea fi ușor extinse și sunt disponibile 13 tipuri diferite.
Există, desigur, momente când vrem să folosim tabelul pivot, cum ar fi atunci când efectuăm operații multidimensionale.
Pentru a ilustra ce înseamnă acest lucru, să reutilizam grupările de clasare pe care le-am făcut folosind declarații condiționate și să încercăm să afișăm de câte ori o adresă URL se clasează în fiecare grup.
ranking_groupings = df.groupby(['URL', 'Grouping']).agg(
url_frequency=('Cuvânt cheie', 'număr'),
)  Captură de ecran din VS Code, noiembrie 2022
Captură de ecran din VS Code, noiembrie 2022
Acesta nu este cel mai bun format de utilizat, deoarece au fost create mai multe rânduri pentru fiecare adresă URL.
În schimb, putem folosi tabelul pivot, care va afișa datele în diferite coloane:
pivot = pd.pivot_table(df, index=['URL'], columns=['Gruparea'], aggfunc='dimensiune', fill_value=0, )
 Captură de ecran din VS Code, noiembrie 2022
Captură de ecran din VS Code, noiembrie 2022
Gânduri finale
Fie că sunteți în căutarea inspirației pentru a începe să învățați Python, fie că îl utilizați deja în fluxurile dvs. de lucru SEO, sper că exemplele de mai sus vă vor ajuta în călătoria dvs.
După cum am promis, puteți găsi aici un blocnotes Google Colab cu toate fragmentele de cod.
De fapt, abia am zgâriat suprafața a ceea ce este posibil, dar înțelegerea elementelor de bază ale analizei datelor Python vă va oferi o bază solidă pe care să vă construiți.
Mai multe resurse:
- Încercați aceste instrumente și metode pentru a exporta rezultatele căutării Google în Excel
- 12 puncte de date SEO esențiale pentru orice site web
- SEO tehnic avansat: un ghid complet
Imagine prezentată: mapo_japan/Shutterstock