
الانتقال من Excel إلى Python: الوظائف الأساسية لتحليل بيانات تحسين محركات البحث
نشرت: 2022-12-02يتمتع تعلم البرمجة ، سواء باستخدام Python أو JavaScript أو أي لغة برمجة أخرى ، بمجموعة كاملة من الفوائد ، بما في ذلك القدرة على العمل مع مجموعات بيانات أكبر وأتمتة المهام المتكررة.
ولكن على الرغم من الفوائد ، فإن العديد من محترفي تحسين محركات البحث لم يجروا الانتقال بعد - وأنا أفهم تمامًا السبب! إنها ليست مهارة أساسية لتحسين محركات البحث ، ونحن جميعًا مشغولون.
إذا كنت مضغوطًا للوقت ، وكنت تعرف بالفعل كيفية إنجاز مهمة داخل Excel أو Google Sheets ، فإن تغيير المسار قد يبدو وكأنه إعادة اختراع العجلة.
عندما بدأت الترميز لأول مرة ، استخدمت Python في البداية فقط للمهام التي لم أتمكن من إنجازها في Excel - واستغرق الأمر عدة سنوات للوصول إلى النقطة التي أصبح فيها خياري الفعلي لمعالجة البيانات.
إذا نظرنا إلى الوراء ، فأنا سعيد للغاية لأنني استمريت ، ولكن في بعض الأحيان كانت تجربة محبطة ، حيث قضيت عدة ساعات في مسح المواضيع على Stack Overflow.
تم تصميم هذا المنشور لتجنيب محترفي تحسين محركات البحث الآخرين نفس المصير.
بداخله ، سنغطي معادلات Python لصيغ وميزات Excel الأكثر استخدامًا لتحليل بيانات تحسين محركات البحث - وكلها متوفرة في دفتر ملاحظات Google Colab المرتبط في الملخص.
على وجه التحديد ، ستتعلم معادلات:
- لين.
- إسقاط التكرارات.
- نص إلى أعمدة.
- البحث / البحث.
- سلسل.
- البحث والاستبدال.
- يسار / منتصف / يمين.
- إذا.
- IFS.
- VLOOKUP.
- COUNTIF / SUMIF / AVERAGEIF.
- الجداول المحورية.
بشكل مثير للدهشة ، لتحقيق كل هذا ، سنستخدم بشكل أساسي مكتبة فردية - Pandas - مع القليل من المساعدة في الأماكن من شقيقها الأكبر ، NumPy.
المتطلبات الأساسية
من أجل الإيجاز ، هناك بعض الأشياء التي لن نغطيها اليوم ، بما في ذلك:
- تثبيت بايثون.
- الباندا الأساسية ، مثل استيراد ملفات CSV والتصفية ومعاينة إطارات البيانات.
إذا لم تكن متأكدًا من أي شيء من هذا ، فإن دليل هاملت حول تحليل بيانات بايثون لتحسين محركات البحث هو الدليل المثالي.
الآن ، دون مزيد من اللغط ، دعنا نقفز.
لين
يوفر LEN عددًا من عدد الأحرف داخل سلسلة نصية.
بالنسبة إلى مُحسّنات محرّكات البحث على وجه التحديد ، تتمثل إحدى حالات الاستخدام الشائعة في قياس طول علامات العنوان أو الأوصاف التعريفية لتحديد ما إذا كان سيتم اقتطاعها في نتائج البحث.
في Excel ، إذا أردنا حساب الخلية الثانية من العمود A ، فسندخل:
= LEN (A2)
 لقطة شاشة من Microsoft Excel ، نوفمبر 2022
لقطة شاشة من Microsoft Excel ، نوفمبر 2022
لا تختلف Python كثيرًا ، حيث يمكننا الاعتماد على وظيفة len المضمنة ، والتي يمكن دمجها مع Pandas 'loc [] للوصول إلى صف معين من البيانات داخل عمود:
len (df ['Title']. loc [0])
في هذا المثال ، نحصل على طول الصف الأول في عمود "العنوان" في إطار البيانات الخاص بنا.

- لقطة شاشة لـ VS Code ، نوفمبر 2022
ومع ذلك ، فإن العثور على طول الخلية ليس مفيدًا لتحسين محركات البحث. في العادة ، نرغب في تطبيق دالة على عمود بأكمله!
في Excel ، يمكن تحقيق ذلك عن طريق تحديد خلية الصيغة في الزاوية اليمنى السفلية وإما سحبها لأسفل أو النقر المزدوج.
عند العمل باستخدام إطار بيانات Pandas ، يمكننا استخدام str.len لحساب طول الصفوف داخل سلسلة ، ثم تخزين النتائج في عمود جديد:
df ['Length'] = df ['Title']. str.len ()
Str.len هي عملية "متجهية" ، تم تصميمها ليتم تطبيقها بشكل متزامن على سلسلة من القيم. سنستخدم هذه العمليات على نطاق واسع خلال هذه المقالة ، حيث ينتهي الأمر بها عالميًا تقريبًا لتكون أسرع من التكرار الحلقي.
تطبيق شائع آخر لـ LEN هو دمجه مع SUBSTITUTE لحساب عدد الكلمات في خلية:
= LEN (TRIM (A2)) - LEN (SUBSTITUTE (A2، "" "")) + 1
في Pandas ، يمكننا تحقيق ذلك من خلال الجمع بين وظائف str.split و str.len معًا:
df ['لا. الكلمات '] = df [' Title ']. str.split (). str.len ()
سنغطي str.split بمزيد من التفصيل لاحقًا ، لكن ما نقوم به بشكل أساسي هو تقسيم بياناتنا بناءً على المسافات البيضاء داخل السلسلة ، ثم حساب عدد الأجزاء المكونة.
 لقطة شاشة من VS Code ، نوفمبر 2022
لقطة شاشة من VS Code ، نوفمبر 2022
إسقاط التكرارات
توفر ميزة "إزالة التكرارات" في Excel طريقة سهلة لإزالة القيم المكررة داخل مجموعة البيانات ، إما عن طريق حذف الصفوف المكررة تمامًا (عند تحديد جميع الأعمدة) أو إزالة الصفوف التي لها نفس القيم في أعمدة معينة.
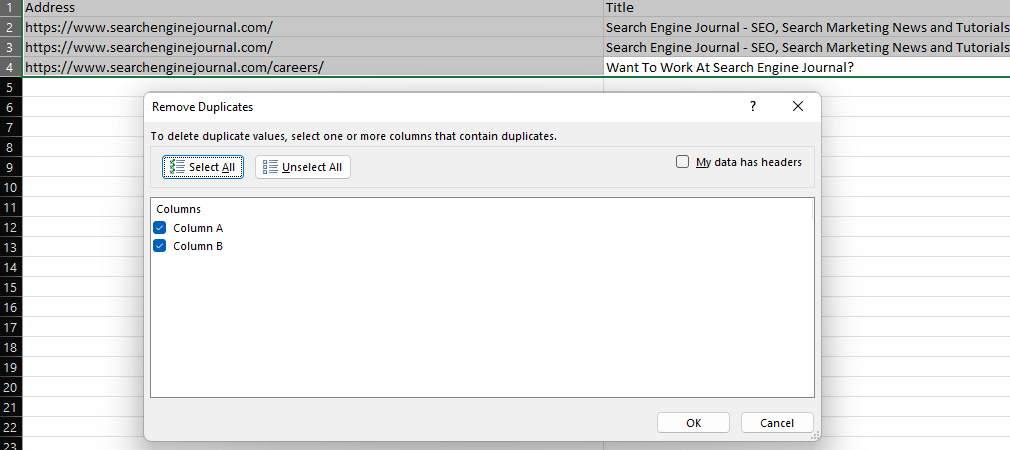 لقطة شاشة من Microsoft Excel ، نوفمبر 2022
لقطة شاشة من Microsoft Excel ، نوفمبر 2022
في Pandas ، يتم توفير هذه الوظيفة عن طريق drop_duplicates.
لإفلات صفوف مكررة في نوع إطار البيانات:
df.drop_duplicates (inplace = True)
لإسقاط صفوف بناءً على التكرارات داخل عمود فردي ، قم بتضمين معلمة المجموعة الفرعية:
df.drop_duplicates (مجموعة فرعية = 'عمود' ، inplace = True)
أو حدد عدة أعمدة في القائمة:
df.drop_duplicates (مجموعة فرعية = ['عمود'، 'عمود 2']، inplace = True)
هناك إضافة واحدة أعلاه تستحق الاستدعاء وهي وجود المعلمة inplace. بما في ذلك inplace = True يسمح لنا بالكتابة فوق إطار البيانات الحالي لدينا دون الحاجة إلى إنشاء واحد جديد.
هناك ، بالطبع ، أوقات نريد فيها الحفاظ على بياناتنا الأولية. في هذه الحالة ، يمكننا تخصيص إطار البيانات الذي تم حذفه إلى متغير مختلف:
df2 = df.drop_duplicates (مجموعة فرعية = "عمود")
نص إلى أعمدة
يمكن استخدام ميزة "نص إلى أعمدة" الأساسية الأخرى اليومية ، لتقسيم سلسلة نصية بناءً على محدد ، مثل الشرطة المائلة أو الفاصلة أو المسافة البيضاء.
كمثال ، تقسيم عنوان URL إلى مجاله والمجلدات الفرعية الفردية.
 لقطة شاشة من Microsoft Excel ، نوفمبر 2022
لقطة شاشة من Microsoft Excel ، نوفمبر 2022
عند التعامل مع إطار بيانات ، يمكننا استخدام الدالة str.split ، والتي تنشئ قائمة لكل إدخال داخل سلسلة. يمكن تحويل هذا إلى عدة أعمدة عن طريق تعيين معلمة التوسيع إلى صواب:
df ['URL']. str.split (pat = '/' ، قم بتوسيع = صحيح)
 لقطة شاشة من VS Code ، نوفمبر 2022
لقطة شاشة من VS Code ، نوفمبر 2022
كما هو الحال غالبًا ، تم تقسيم عناوين URL الموجودة في الصورة أعلاه إلى أعمدة غير متسقة ، لأنها لا تحتوي على نفس عدد المجلدات.
هذا يمكن أن يجعل الأمور صعبة عندما نريد حفظ بياناتنا داخل إطار بيانات موجود.
تحديد المعلمة n يحد من عدد الانقسامات ، مما يسمح لنا بإنشاء عدد محدد من الأعمدة:
df [['المجال'، 'Folder1'، 'Folder2'، 'Folder3']] = df ['URL']. str.split (pat = '/'، expand = True، n = 3)
هناك خيار آخر وهو استخدام pop لإزالة العمود من إطار البيانات ، وإجراء التقسيم ، ثم إعادة إضافته باستخدام وظيفة الصلة:
df = df.join (df.pop ('Split'). str.split (pat = '/' ، قم بتوسيع = True))يسمح لنا تكرار عنوان URL إلى عمود جديد قبل الانقسام بالحفاظ على عنوان URL الكامل. يمكننا بعد ذلك إعادة تسمية الأعمدة الجديدة: 🐆
df ['Split'] = df ['URL']
df = df.join (df.pop ('Split'). str.split (pat = '/' ، قم بتوسيع = True))
df.rename (الأعمدة = {0: "المجال" ، 1: "Folder1" ، 2: "Folder2" ، 3: "Folder3" ، 4: "Parameter"} ، inplace = True) 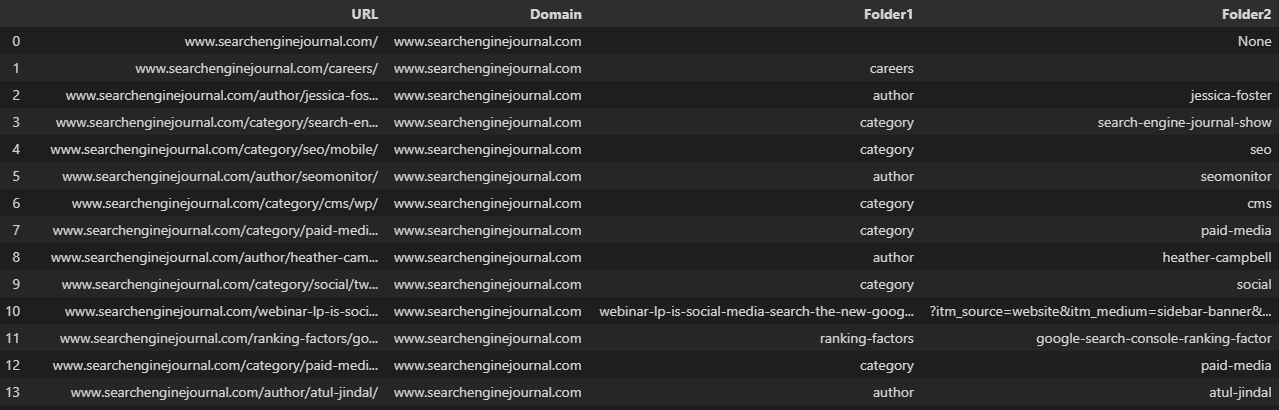 لقطة شاشة من VS Code ، نوفمبر 2022
لقطة شاشة من VS Code ، نوفمبر 2022
سلسل
تسمح وظيفة CONCAT للمستخدمين بدمج سلاسل نصية متعددة ، كما هو الحال عند إنشاء قائمة بالكلمات الرئيسية عن طريق إضافة مُعدِّلات مختلفة.
في هذه الحالة ، نضيف "رجالي" ومسافة بيضاء إلى قائمة أنواع المنتجات في العمود "أ":
= CONCAT ($ F $ 1، ""، A2)

- لقطة شاشة من Microsoft Excel ، نوفمبر 2022
بافتراض أننا نتعامل مع سلاسل ، يمكن تحقيق الشيء نفسه في بايثون باستخدام المعامل الحسابي:
df ['Combined] =' mens '+' '+ df [' Keyword ']
أو حدد عدة أعمدة من البيانات:
df ['Combined'] = df ['Subdomain'] + df ['URL']
 لقطة شاشة من VS Code ، نوفمبر 2022
لقطة شاشة من VS Code ، نوفمبر 2022
يحتوي Pandas على وظيفة concat مخصصة ، ولكن هذا أكثر فائدة عند محاولة دمج إطارات بيانات متعددة مع نفس الأعمدة.
على سبيل المثال ، إذا كان لدينا عمليات تصدير متعددة من أداة تحليل الارتباط المفضلة لدينا:
df = pd.read_csv ("data.csv")
df2 = pd.read_csv ('data2.csv')
df3 = pd.read_csv ("data3.csv")
dflist = [df، df2، df3]
df = pd.concat (dflist ، ignore_index = صحيح)البحث / البحث
توفر الصيغتان SEARCH و FIND طريقة لتحديد موقع سلسلة فرعية داخل سلسلة نصية.
يتم دمج هذه الأوامر بشكل شائع مع ISNUMBER لإنشاء عمود منطقي يساعد في تصفية مجموعة البيانات ، والتي يمكن أن تكون مفيدة للغاية عند تنفيذ مهام مثل تحليل ملف السجل ، كما هو موضح في هذا الدليل. على سبيل المثال:
= ISNUMBER (SEARCH ("searchthis"، A2)  لقطة شاشة من Microsoft Excel ، نوفمبر 2022
لقطة شاشة من Microsoft Excel ، نوفمبر 2022
الفرق بين SEARCH و FIND هو أن الاكتشاف حساس لحالة الأحرف.
دالة Pandas المكافئة ، str.contains ، حساسة لحالة الأحرف بشكل افتراضي:
df ['Journal'] = df ['URL']. str.contains ('engine'، na = False)يمكن تمكين الحساسية لحالة الأحرف عن طريق تعيين معلمة الحالة على False:
df ['Journal'] = df ['URL']. str.contains ('المحرك' ، الحالة = خطأ ، na = خطأ)في أي من السيناريوهين ، سيؤدي تضمين na = False إلى منع إرجاع القيم الخالية داخل العمود المنطقي.
تتمثل إحدى الميزات الهائلة لاستخدام Pandas هنا في أنه ، على عكس Excel ، يتم دعم regex أصلاً بواسطة هذه الوظيفة - كما هو الحال في أوراق Google عبر REGEXMATCH.
ربط سلاسل فرعية متعددة معًا باستخدام حرف الأنبوب ، المعروف أيضًا باسم عامل التشغيل OR:
df ['Journal'] = df ['URL']. str.contains ('محرك | بحث'، na = خطأ)البحث والاستبدال
توفر ميزة "البحث والاستبدال" في Excel طريقة سهلة للاستبدال الفردي أو الجماعي لسلسلة فرعية بأخرى.
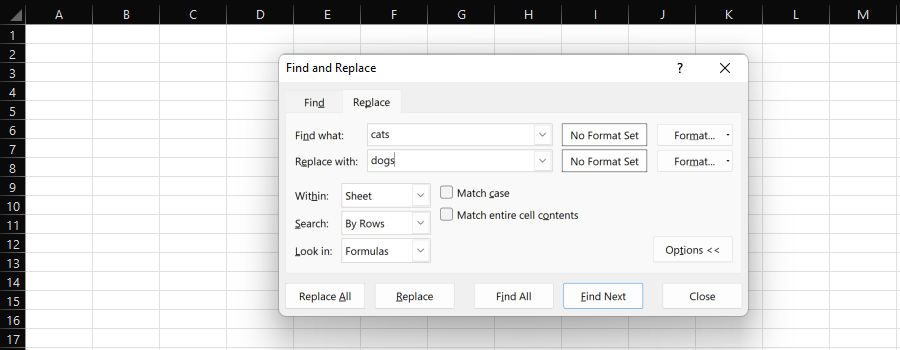 لقطة شاشة من Microsoft Excel ، نوفمبر 2022
لقطة شاشة من Microsoft Excel ، نوفمبر 2022
عند معالجة البيانات من أجل تحسين محركات البحث ، من المرجح أن نختار عمودًا كاملاً و "استبدال الكل".
توفر صيغة SUBSTITUTE خيارًا آخر هنا وهي مفيدة إذا كنت لا تريد الكتابة فوق العمود الموجود.
على سبيل المثال ، يمكننا تغيير بروتوكول عنوان URL من HTTP إلى HTTPS ، أو إزالته عن طريق استبداله بلا شيء.
عند العمل مع إطارات البيانات في بايثون ، يمكننا استخدام str.replace:
df ['URL'] = df ['URL'] .str.replace ('http: //'، 'https: //')أو:
df ['URL'] = df ['URL'] .str.replace ('http: //'، '') # استبدل بلا شيءمرة أخرى ، على عكس Excel ، يمكن استخدام regex - كما هو الحال مع جداول بيانات Google REGEXREPLACE:

df ['URL'] = df ['URL'] .str.replace ('http: // | https: //'، '')بدلاً من ذلك ، إذا كنت تريد استبدال سلاسل فرعية متعددة بقيم مختلفة ، فيمكنك استخدام طريقة استبدال Python وتقديم قائمة.
هذا يمنعك من الاضطرار إلى ربط وظائف str.replace متعددة:
df ['URL'] = df ['URL'] .replace (['http: //'، 'https: //']، ['https: // www.'، 'https: // www.' ] ، regex = صحيح)
يسار / منتصف / يمين
يتطلب استخراج سلسلة فرعية داخل Excel استخدام وظائف LEFT أو MID أو RIGHT ، اعتمادًا على مكان وجود السلسلة الفرعية داخل الخلية.
لنفترض أننا نريد استخراج المجال الجذر والمجال الفرعي من عنوان URL:
= MID (A2، FIND (":"، A2،4) + 3، FIND ("/"، A2،9) -FIND (":"، A2،4) -3) 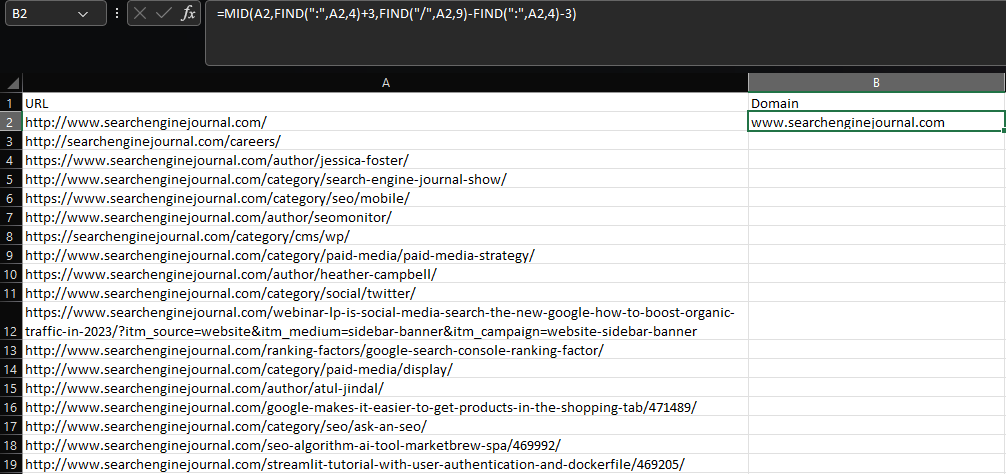 لقطة شاشة من Microsoft Excel ، نوفمبر 2022
لقطة شاشة من Microsoft Excel ، نوفمبر 2022
باستخدام مزيج من وظائف MID و FIND المتعددة ، فإن هذه الصيغة قبيحة ، على أقل تقدير - والأشياء تزداد سوءًا بالنسبة لعمليات الاستخراج الأكثر تعقيدًا.
مرة أخرى ، تقوم Google Sheets بعمل ذلك بشكل أفضل من Excel ، لأنها تحتوي على REGEXEXTRACT.
يا له من عار أنه عندما تغذيها بمجموعات بيانات أكبر ، فإنها تذوب أسرع من Babybel على المبرد الساخن.
لحسن الحظ ، تقدم Pandas ميزة str.extract ، والتي تعمل بطريقة مماثلة:
df ['المجال'] = df ['URL'] .str.extract ('. * \: //؟ ([^ \ /] +)')  لقطة شاشة من VS Code ، نوفمبر 2022
لقطة شاشة من VS Code ، نوفمبر 2022
ادمجها مع fillna لمنع القيم الفارغة ، كما تفعل في Excel مع IFERROR:
df ['المجال'] = df ['URL'] .str.extract ('. * \: //؟ ([^ \ /] +)') .fillna ('-')إذا
تسمح لك عبارات IF بإرجاع قيم مختلفة ، اعتمادًا على ما إذا كان الشرط قد تم استيفائه أم لا.
للتوضيح ، افترض أننا نريد إنشاء تصنيف للكلمات الرئيسية التي يتم ترتيبها ضمن المراكز الثلاثة الأولى.
 لقطة شاشة من Microsoft Excel ، نوفمبر 2022
لقطة شاشة من Microsoft Excel ، نوفمبر 2022
بدلاً من استخدام Pandas في هذه الحالة ، يمكننا الاعتماد على NumPy ووظيفة where (تذكر استيراد NumPy ، إذا لم تكن قد قمت بذلك بالفعل):
df ['Top 3'] = np.where (df ['Position'] <= 3، 'Top 3'، 'Not Top 3')
يمكن استخدام شروط متعددة لنفس التقييم باستخدام عوامل التشغيل AND / OR ، وإرفاق المعايير الفردية داخل أقواس مستديرة:
df ['Top 3'] = np.where ((df ['Position'] <= 3) & (df ['Position']! = 0)، 'Top 3'، 'Not Top 3')
في ما سبق ، نعرض "أفضل 3" لأي كلمات رئيسية ذات ترتيب أقل من أو يساوي ثلاثة ، باستثناء أي ترتيب للكلمات الرئيسية في الموضع صفر.
IFS
في بعض الأحيان ، بدلاً من تحديد شروط متعددة لنفس التقييم ، قد ترغب في شروط متعددة تُرجع قيمًا مختلفة.
في هذه الحالة ، أفضل حل هو استخدام IFS:
= IFS (B2 <= 3 ، "أعلى 3" ، B2 <= 10 ، "أعلى 10" ، B2 <= 20 ، "أفضل 20")
 لقطة شاشة من Microsoft Excel ، نوفمبر 2022
لقطة شاشة من Microsoft Excel ، نوفمبر 2022
مرة أخرى ، يوفر لنا NumPy أفضل حل عند العمل مع إطارات البيانات ، عبر وظيفة التحديد الخاصة به.
باستخدام select ، يمكننا إنشاء قائمة بالشروط والخيارات وقيمة اختيارية عندما تكون جميع الشروط خاطئة:
الشروط = [df ['Position'] <= 3، df ['Position'] <= 10، df ['Position'] <= 20] الاختيارات = ['أهم 3' ، 'أفضل 10' ، 'أفضل 20'] df ['Rank'] = np.select (شروط ، اختيارات ، "ليست أفضل 20")
من الممكن أيضًا أن يكون لديك شروط متعددة لكل تقييم.
لنفترض أننا نعمل مع بائع تجزئة للتجارة الإلكترونية مع صفحات قائمة المنتجات (PLPs) وصفحات عرض المنتج (PDPs) ، ونريد تصنيف نوع الصفحات ذات العلامات التجارية في الترتيب ضمن أفضل 10 نتائج.
أسهل حل هنا هو البحث عن أنماط عناوين URL محددة ، مثل مجلد فرعي أو ملحق ، ولكن ماذا لو كان لدى المنافسين أنماط متشابهة؟
في هذا السيناريو ، يمكننا أن نفعل شيئًا كالتالي:
الشروط = [(df ['URL']. str.contains ('/ category /')) & (df ['Brand Rank']> 0) ،
(df ['URL']. str.contains ('/ product /')) & (df ['Brand Rank']> 0) ،
(~ df ['URL']. str.contains ('/ product /')) & (~ df ['URL']. str.contains ('/ category /')) & (df ['Brand Rank'] > 0)]
الاختيارات = ['PLP' ، 'PDP' ، 'أخرى']
df ['نوع صفحة العلامة التجارية'] = np.select (الشروط ، الاختيارات ، بلا)أعلاه ، نحن نستخدم str.contains لتقييم ما إذا كان عنوان URL في العشرة الأوائل يطابق نمط علامتنا التجارية أم لا ، ثم نستخدم عمود "تصنيف العلامة التجارية" لاستبعاد أي منافسين.
في هذا المثال ، تشير علامة التلدة (~) إلى تطابق سلبي. بعبارة أخرى ، نقول إننا نريد أن يتطابق عنوان URL لكل علامة تجارية لا يتطابق مع نمط "PDP" أو "PLP" مع معايير "أخرى".
أخيرًا ، لا يتم تضمين أي شيء لأننا نريد أن تُرجع النتائج غير المتعلقة بالعلامة التجارية قيمة فارغة.
 لقطة شاشة من VS Code ، نوفمبر 2022
لقطة شاشة من VS Code ، نوفمبر 2022
VLOOKUP
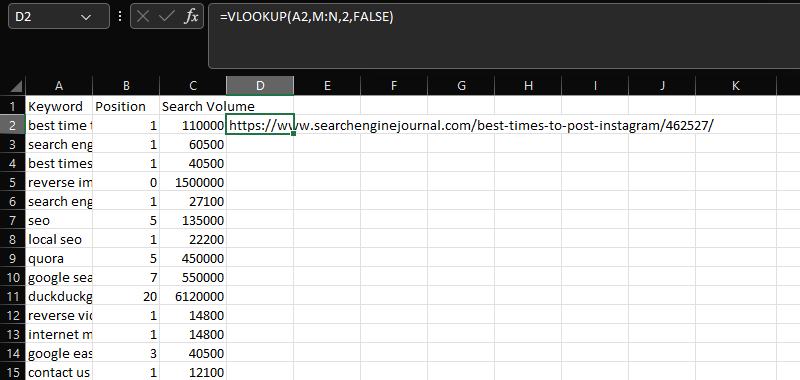
تعد VLOOKUP أداة أساسية للجمع بين مجموعتي بيانات مختلفتين معًا في عمود مشترك.
في هذه الحالة ، إضافة عناوين URL داخل العمود N إلى بيانات الكلمة الرئيسية والموضع وحجم البحث في الأعمدة AC ، باستخدام عمود "Keyword" المشترك:
= VLOOKUP (A2، M: N، 2، FALSE)
 لقطة شاشة من Microsoft Excel ، نوفمبر 2022
لقطة شاشة من Microsoft Excel ، نوفمبر 2022
للقيام بشيء مشابه مع Pandas ، يمكننا استخدام الدمج.
تكرار وظيفة ضم SQL ، يعد الدمج وظيفة قوية بشكل لا يصدق تدعم مجموعة متنوعة من أنواع الصلة المختلفة.
لأغراضنا ، نريد استخدام صلة يسرى ، والتي ستحافظ على إطار البيانات الأول لدينا وتندمج فقط في القيم المطابقة من إطار البيانات الثاني لدينا:
mergeddf = df.merge (df2، how = 'left'، on = 'Keyword')
إحدى الميزات الإضافية لإجراء الدمج عبر VLOOKUP ، هي أنك لست مضطرًا إلى مشاركة البيانات في العمود الأول من مجموعة البيانات الثانية ، كما هو الحال مع XLOOKUP الأحدث.
وسيسحب أيضًا صفوفًا متعددة من البيانات بدلاً من المطابقة الأولى في الاكتشافات.
إحدى المشكلات الشائعة عند استخدام الوظيفة هي تكرار الأعمدة غير المرغوب فيها. يحدث هذا عند وجود عدة أعمدة مشتركة ، لكنك تحاول المطابقة باستخدام واحد.
لمنع هذا - وتحسين دقة التطابقات - يمكنك تحديد قائمة الأعمدة:
mergeddf = df.merge (df2، how = 'left'، on = ['Keyword'، 'Search Volume'])
في سيناريوهات معينة ، قد ترغب بنشاط في تضمين هذه الأعمدة. على سبيل المثال ، عند محاولة دمج عدة تقارير تصنيف شهرية:
mergeddf = df.merge (df2، on = 'Keyword'، how = 'left'، اللاحقة = (''، '_october')) \
.merge (df3، on = 'Keyword'، how = 'left'، اللاحقة = (''، '_september'))ينفذ مقتطف الشفرة أعلاه عمليتي دمج لربط ثلاثة إطارات بيانات مع الأعمدة نفسها - وهي تصنيفاتنا لشهر نوفمبر وأكتوبر وسبتمبر.
من خلال تسمية الأشهر داخل معلمات اللاحقة ، ننتهي بإطار بيانات أكثر وضوحًا يعرض الشهر بوضوح ، على عكس القيم الافتراضية لـ _x و _y التي رأيناها في المثال السابق.
 لقطة شاشة من VS Code ، نوفمبر 2022
لقطة شاشة من VS Code ، نوفمبر 2022
COUNTIF / SUMIF / AVERAGEIF
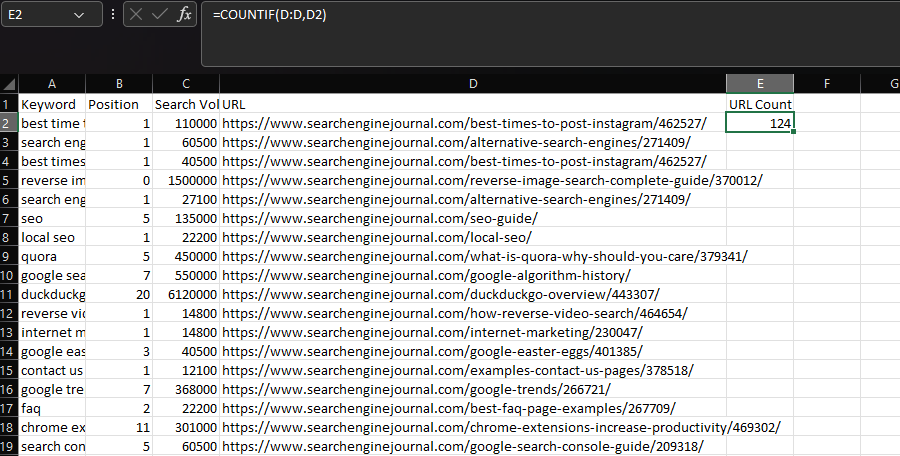
في Excel ، إذا كنت تريد إجراء دالة إحصائية بناءً على شرط ، فمن المحتمل أن تستخدم COUNTIF أو SUMIF أو AVERAGEIF.
بشكل عام ، يتم استخدام COUNTIF لتحديد عدد المرات التي تظهر فيها سلسلة معينة ضمن مجموعة بيانات ، مثل عنوان URL.
يمكننا تحقيق ذلك من خلال إعلان عمود "URL" على أنه النطاق الخاص بنا ، ثم عنوان URL داخل خلية فردية كمعاييرنا:
= COUNTIF (D: D، D2)
 لقطة شاشة من Microsoft Excel ، نوفمبر 2022
لقطة شاشة من Microsoft Excel ، نوفمبر 2022
في Pandas ، يمكننا تحقيق نفس النتيجة باستخدام وظيفة groupby:
df.groupby ('URL') ['URL']. count ()  لقطة شاشة من VS Code ، نوفمبر 2022
لقطة شاشة من VS Code ، نوفمبر 2022
هنا ، يشير العمود المعلن داخل الأقواس المستديرة إلى المجموعات الفردية ، والعمود المدرج بين الأقواس المربعة هو المكان الذي يتم فيه التجميع (أي العد).
ومع ذلك ، فإن المخرجات التي نتلقاها ليست مثالية لحالة الاستخدام هذه ، لأنها مدمجة للبيانات.
عادةً ، عند استخدام Excel ، سيكون لدينا عدد عناوين URL المضمنة في مجموعة البيانات الخاصة بنا. ثم يمكننا استخدامه للتصفية إلى أكثر عناوين URL المدرجة بشكل متكرر.
للقيام بذلك ، استخدم التحويل وقم بتخزين الإخراج في عمود:
df ['URL Count'] = df.groupby ('URL') ['URL']. تحويل ('عدد')  لقطة شاشة من VS Code ، نوفمبر 2022
لقطة شاشة من VS Code ، نوفمبر 2022
يمكنك أيضًا تطبيق وظائف مخصصة على مجموعات من البيانات باستخدام دالة lambda (مجهول):
df ['Google Count'] = df.groupby (['URL']) ['URL']. تحويل (lambda x: x [x.str.contains ('google')]. count ())في الأمثلة التي لدينا حتى الآن ، كنا نستخدم نفس العمود للتجميع والتجميعات الخاصة بنا ، لكننا لسنا مضطرين لذلك. على غرار COUNTIFS / SUMIFS / AVERAGEIFS في Excel ، من الممكن التجميع باستخدام عمود واحد ، ثم تطبيق وظيفتنا الإحصائية على عمود آخر.
بالعودة إلى مثال صفحة نتائج محرك البحث السابقة (SERP) ، قد نرغب في حساب كل PDPs المرتبة على أساس كل كلمة رئيسية وإرجاع هذا الرقم إلى جانب البيانات الموجودة لدينا:
df ['PDP Count'] = df.groupby (['Keyword']) ['URL']. تحويل (lambda x: x [x.str.contains ('/ product / | / prd / | / pd /' )].عدد())  لقطة شاشة من VS Code ، نوفمبر 2022
لقطة شاشة من VS Code ، نوفمبر 2022والذي سيبدو في لغة Excel مثل هذا:
= SUM (COUNTIFS (A: A، [@ Keyword]، D: D، {"* / product / *"، "* / prd / *"، "* / pd / *"}))
الجداول المحورية
أخيرًا وليس آخرًا ، حان الوقت للتحدث عن الجداول المحورية.
في Excel ، من المحتمل أن يكون الجدول المحوري هو أول منفذ للاتصال إذا أردنا تلخيص مجموعة بيانات كبيرة.
على سبيل المثال ، عند العمل مع بيانات الترتيب ، قد نرغب في تحديد عناوين URL التي تظهر بشكل متكرر ومتوسط ترتيبها.
 لقطة شاشة من Microsoft Excel ، نوفمبر 2022
لقطة شاشة من Microsoft Excel ، نوفمبر 2022
مرة أخرى ، لدى Pandas جداول محورية مكافئة - ولكن إذا كان كل ما تريده هو عدد القيم الفريدة داخل عمود ، فيمكن تحقيق ذلك باستخدام دالة value_counts:
count = df ['URL']. value_counts ()
يعد استخدام groupby أيضًا خيارًا.
في وقت سابق من المقالة ، لم يكن إجراء مجموعة جمعت بياناتنا هو ما أردناه - ولكنه بالضبط ما هو مطلوب هنا:
مجمعة = df.groupby ('URL'). agg (
url_frequency = ('Keyword'، 'count')،
avg_position = ('Position'، 'mean')،
)
grouped.reset_index (inplace = True)  لقطة شاشة من VS Code ، نوفمبر 2022
لقطة شاشة من VS Code ، نوفمبر 2022
تم تطبيق وظيفتين مجمعتين في المثال أعلاه ، ولكن يمكن توسيع ذلك بسهولة ، ويتوفر 13 نوعًا مختلفًا.
هناك ، بالطبع ، أوقات نريد فيها استخدام pivot_table ، كما هو الحال عند إجراء عمليات متعددة الأبعاد.
لتوضيح ما يعنيه هذا ، دعنا نعيد استخدام مجموعات الترتيب التي أنشأناها باستخدام العبارات الشرطية ونحاول عرض عدد مرات ترتيب عنوان URL داخل كل مجموعة.
rating_groupings = df.groupby (['URL'، 'Grouping']). agg (
url_frequency = ('Keyword'، 'count')،
)  لقطة شاشة من VS Code ، نوفمبر 2022
لقطة شاشة من VS Code ، نوفمبر 2022
هذا ليس أفضل تنسيق للاستخدام ، حيث تم إنشاء صفوف متعددة لكل عنوان URL.
بدلاً من ذلك ، يمكننا استخدام pivot_table ، والذي سيعرض البيانات في أعمدة مختلفة:
المحور = pd.pivot_table (df ، الفهرس = ['URL'] ، أعمدة = ["تجميع"] ، aggfunc = 'الحجم' ، fill_value = 0 ، )
 لقطة شاشة من VS Code ، نوفمبر 2022
لقطة شاشة من VS Code ، نوفمبر 2022
افكار اخيرة
سواء كنت تبحث عن مصدر إلهام لبدء تعلم Python ، أو كنت تستفيد منها بالفعل في سير عمل تحسين محركات البحث لديك ، آمل أن تساعدك الأمثلة المذكورة أعلاه في رحلتك.
كما هو موعود ، يمكنك العثور على دفتر ملاحظات Google Colab به جميع مقتطفات التعليمات البرمجية هنا.
في الحقيقة ، بالكاد خدشنا سطح ما هو ممكن ، لكن فهم أساسيات تحليل بيانات Python سيمنحك قاعدة صلبة يمكن البناء عليها.
المزيد من الموارد:
- جرب هذه الأدوات والطرق لتصدير نتائج بحث Google إلى Excel
- 12 نقطة بيانات أساسية لتحسين محركات البحث لأي موقع ويب
- مُحسنات محركات البحث الفنية المتقدمة: دليل كامل
الصورة المميزة: mapo_japan / Shutterstock