
Transición de Excel a Python: funciones esenciales para el análisis de datos de SEO
Publicado: 2022-12-02Aprender a codificar, ya sea con Python, JavaScript u otro lenguaje de programación, tiene una gran cantidad de beneficios, incluida la capacidad de trabajar con conjuntos de datos más grandes y automatizar tareas repetitivas.
Pero a pesar de los beneficios, muchos profesionales de SEO aún no han hecho la transición, ¡y entiendo completamente por qué! No es una habilidad esencial para SEO, y todos somos personas ocupadas.
Si tiene poco tiempo y ya sabe cómo realizar una tarea en Excel o en Hojas de cálculo de Google, cambiar de táctica puede ser como reinventar la rueda.
Cuando comencé a codificar, inicialmente solo usaba Python para tareas que no podía realizar en Excel, y me llevó varios años llegar al punto en que es mi elección de facto para el procesamiento de datos.
Mirando hacia atrás, estoy increíblemente contento de haber persistido, pero a veces fue una experiencia frustrante, con muchas horas dedicadas a escanear hilos en Stack Overflow.
Esta publicación está diseñada para ahorrarles a otros profesionales de SEO el mismo destino.
Dentro de él, cubriremos los equivalentes de Python de las fórmulas y funciones de Excel más utilizadas para el análisis de datos de SEO, todas las cuales están disponibles en un cuaderno de Google Colab vinculado en el resumen.
Específicamente, aprenderá los equivalentes de:
- LEN.
- Soltar duplicados.
- Texto a columnas.
- BUSCAR/ENCONTRAR.
- CONCATENAR.
- Encontrar y reemplazar.
- IZQUIERDA/MEDIO/DERECHA.
- SI.
- IFS.
- BUSCARV.
- CONTAR.SI/SUMAR.SI/PROMEDIO.SI.
- Tablas dinamicas.
Sorprendentemente, para lograr todo esto, usaremos principalmente una biblioteca singular, Pandas, con un poco de ayuda en algunos lugares de su hermano mayor, NumPy.
requisitos previos
En aras de la brevedad, hay algunas cosas que no cubriremos hoy, que incluyen:
- Instalación de Python.
- Pandas básicos, como importar CSV, filtrar y obtener una vista previa de los marcos de datos.
Si no está seguro de nada de esto, entonces la guía de Hamlet sobre el análisis de datos de Python para SEO es la introducción perfecta.
Ahora, sin más preámbulos, entremos.
LARGO
LEN proporciona un recuento del número de caracteres dentro de una cadena de texto.
Específicamente para SEO, un caso de uso común es medir la longitud de las etiquetas de título o las metadescripciones para determinar si se truncarán en los resultados de búsqueda.
Dentro de Excel, si quisiéramos contar la segunda celda de la columna A, ingresaríamos:
=LARGO(A2)
 Captura de pantalla de Microsoft Excel, noviembre de 2022
Captura de pantalla de Microsoft Excel, noviembre de 2022
Python no es muy diferente, ya que podemos confiar en la función len incorporada, que se puede combinar con loc[] de Pandas para acceder a una fila específica de datos dentro de una columna:
len(df['Título'].loc[0])
En este ejemplo, obtenemos la longitud de la primera fila en la columna "Título" de nuestro marco de datos.

- Captura de pantalla de VS Code, noviembre de 2022
Sin embargo, encontrar la longitud de una celda no es tan útil para SEO. ¡Normalmente, nos gustaría aplicar una función a una columna completa!
En Excel, esto se lograría seleccionando la celda de fórmula en la esquina inferior derecha y arrastrándola hacia abajo o haciendo doble clic.
Cuando trabajamos con un marco de datos de Pandas, podemos usar str.len para calcular la longitud de las filas dentro de una serie y luego almacenar los resultados en una nueva columna:
df['Longitud'] = df['Título'].str.len()
Str.len es una operación 'vectorizada', que está diseñada para aplicarse simultáneamente a una serie de valores. Usaremos estas operaciones ampliamente a lo largo de este artículo, ya que casi universalmente terminan siendo más rápidas que un bucle.
Otra aplicación común de LEN es combinarlo con SUBSTITUTE para contar el número de palabras en una celda:
=LARGO(RECORTAR(A2))-LARGO(SUSTITUIR(A2," ",""))+1
En Pandas, podemos lograr esto combinando las funciones str.split y str.len juntas:
df['No. Palabras'] = df['Título'].str.split().str.len()
Cubriremos str.split con más detalle más adelante, pero esencialmente, lo que estamos haciendo es dividir nuestros datos en función de los espacios en blanco dentro de la cadena y luego contar el número de componentes.
 Captura de pantalla de VS Code, noviembre de 2022
Captura de pantalla de VS Code, noviembre de 2022
Descartar duplicados
La función 'Eliminar duplicados' de Excel proporciona una manera fácil de eliminar valores duplicados dentro de un conjunto de datos, ya sea eliminando filas duplicadas por completo (cuando se seleccionan todas las columnas) o eliminando filas con los mismos valores en columnas específicas.
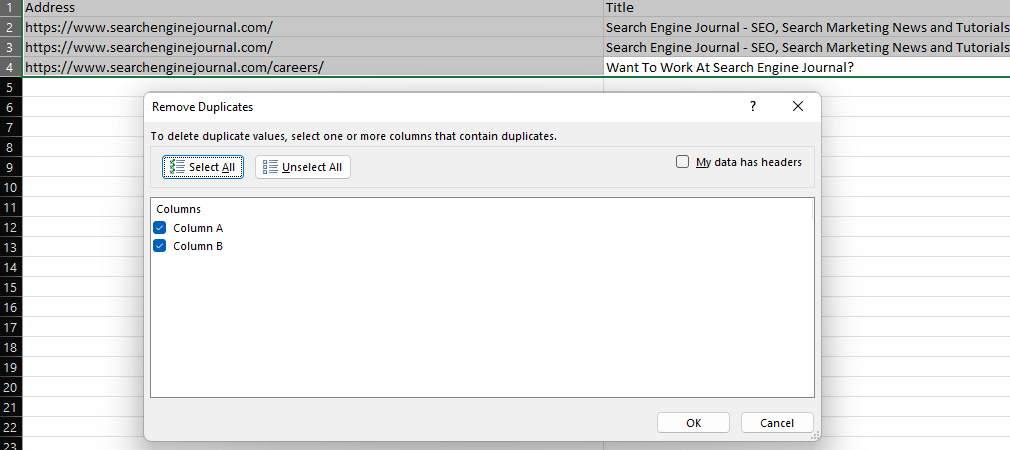 Captura de pantalla de Microsoft Excel, noviembre de 2022
Captura de pantalla de Microsoft Excel, noviembre de 2022
En Pandas, drop_duplicates proporciona esta funcionalidad.
Para soltar filas duplicadas dentro de un tipo de marco de datos:
df.drop_duplicates(inplace=True)
Para colocar filas basadas en duplicados dentro de una columna singular, incluya el parámetro de subconjunto:
df.drop_duplicates(subconjunto='columna', inplace=True)
O especifique varias columnas dentro de una lista:
df.drop_duplicates(subconjunto=['columna','columna2'], en el lugar=Verdadero)
Una adición anterior que vale la pena mencionar es la presencia del parámetro inplace. Incluir inplace=True nos permite sobrescribir nuestro marco de datos existente sin necesidad de crear uno nuevo.
Por supuesto, hay ocasiones en las que queremos conservar nuestros datos sin procesar. En este caso, podemos asignar nuestro dataframe deduplicado a una variable diferente:
df2 = df.drop_duplicates(subconjunto='columna')
Texto a columnas
Otra característica esencial de todos los días, la función 'texto a columnas' se puede usar para dividir una cadena de texto en función de un delimitador, como una barra inclinada, una coma o un espacio en blanco.
Como ejemplo, dividir una URL en su dominio y subcarpetas individuales.
 Captura de pantalla de Microsoft Excel, noviembre de 2022
Captura de pantalla de Microsoft Excel, noviembre de 2022
Cuando se trata de un marco de datos, podemos usar la función str.split, que crea una lista para cada entrada dentro de una serie. Esto se puede convertir en varias columnas configurando el parámetro de expansión en True:
df['URL'].str.split(pat='/', expand=True)
 Captura de pantalla de VS Code, noviembre de 2022
Captura de pantalla de VS Code, noviembre de 2022
Como suele ser el caso, nuestras URL en la imagen de arriba se han dividido en columnas inconsistentes, porque no cuentan con la misma cantidad de carpetas.
Esto puede complicar las cosas cuando queremos guardar nuestros datos dentro de un marco de datos existente.
Especificar el parámetro n limita el número de divisiones, permitiéndonos crear un número específico de columnas:
df[['Dominio', 'Carpeta1', 'Carpeta2', 'Carpeta3']] = df['URL'].str.split(pat='/', expand=True, n=3)
Otra opción es usar pop para eliminar su columna del marco de datos, realizar la división y luego volver a agregarla con la función de unión:
df = df.join(df.pop('Split').str.split(pat='/', expand=True))Duplicar la URL en una nueva columna antes de la división nos permite conservar la URL completa. Luego podemos cambiar el nombre de las nuevas columnas: 🐆
df['Dividir'] = df['URL']
df = df.join(df.pop('Split').str.split(pat='/', expand=True))
df.rename(columnas = {0:'Dominio', 1:'Carpeta1', 2:'Carpeta2', 3:'Carpeta3', 4:'Parámetro'}, inplace=True) 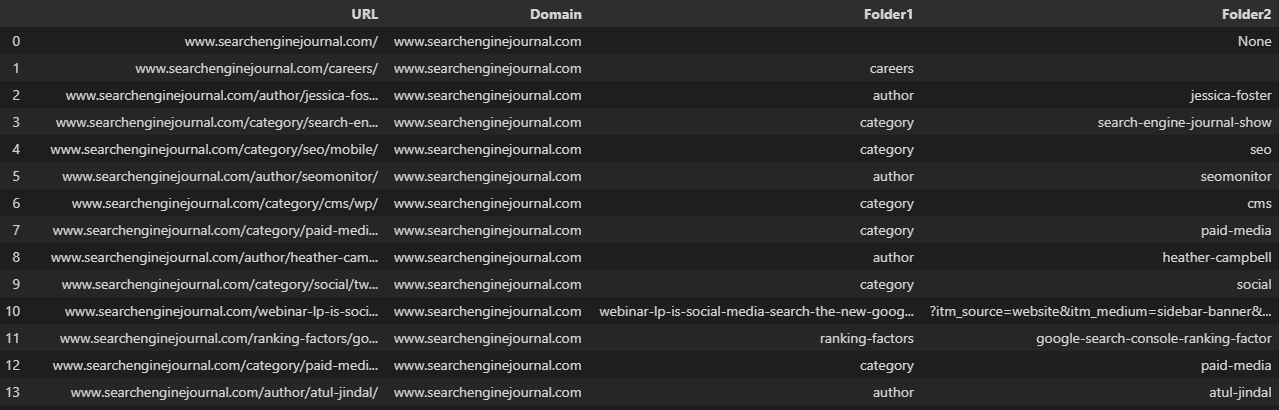 Captura de pantalla de VS Code, noviembre de 2022
Captura de pantalla de VS Code, noviembre de 2022
CONCATENAR
La función CONCAT permite a los usuarios combinar múltiples cadenas de texto, como cuando se genera una lista de palabras clave agregando diferentes modificadores.
En este caso, estamos agregando "mens" y espacios en blanco a la lista de tipos de productos de la columna A:
=CONCAT ($F$1," ",A2)

- Captura de pantalla de Microsoft Excel, noviembre de 2022
Suponiendo que estamos tratando con cadenas, se puede lograr lo mismo en Python usando el operador aritmético:
df['Combinado] = 'mens' + ' ' + df['Palabra clave']
O especifique varias columnas de datos:
df['Combinado'] = df['Subdominio'] + df['URL']
 Captura de pantalla de VS Code, noviembre de 2022
Captura de pantalla de VS Code, noviembre de 2022
Pandas tiene una función concat dedicada, pero esto es más útil cuando se intenta combinar varios marcos de datos con las mismas columnas.
Por ejemplo, si tuviéramos múltiples exportaciones de nuestra herramienta de análisis de enlaces favorita:
df = pd.read_csv('datos.csv')
df2 = pd.read_csv('datos2.csv')
df3 = pd.read_csv('datos3.csv')
lista_df = [df, df2, df3]
df = pd.concat(dflist, ignore_index=True)BUSCAR/ENCONTRAR
Las fórmulas SEARCH y FIND proporcionan una forma de ubicar una subcadena dentro de una cadena de texto.
Estos comandos se combinan comúnmente con ISNUMBER para crear una columna booleana que ayuda a filtrar un conjunto de datos, lo que puede ser extremadamente útil al realizar tareas como el análisis de archivos de registro, como se explica en esta guía. P.ej:
=ESNUMERO(BUSCAR("buscaresto",A2)  Captura de pantalla de Microsoft Excel, noviembre de 2022
Captura de pantalla de Microsoft Excel, noviembre de 2022
La diferencia entre SEARCH y FIND es que find distingue entre mayúsculas y minúsculas.
La función equivalente de Pandas, str.contains, distingue entre mayúsculas y minúsculas de forma predeterminada:
df['Diario'] = df['URL'].str.contains('motor', na=Falso)La insensibilidad a mayúsculas y minúsculas se puede habilitar configurando el parámetro de mayúsculas y minúsculas en Falso:
df['Diario'] = df['URL'].str.contains('motor', case=Falso, na=Falso)En cualquier escenario, incluir na=False evitará que se devuelvan valores nulos dentro de la columna booleana.
Una gran ventaja de usar Pandas aquí es que, a diferencia de Excel, regex es compatible de forma nativa con esta función, como lo es en las hojas de Google a través de REGEXMATCH.
Encadene varias subcadenas usando el carácter de barra vertical, también conocido como el operador OR:
df['Diario'] = df['URL'].str.contains('motor|búsqueda', na=Falso)Encontrar y reemplazar
La función "Buscar y reemplazar" de Excel proporciona una manera fácil de reemplazar de forma individual o masiva una subcadena por otra.
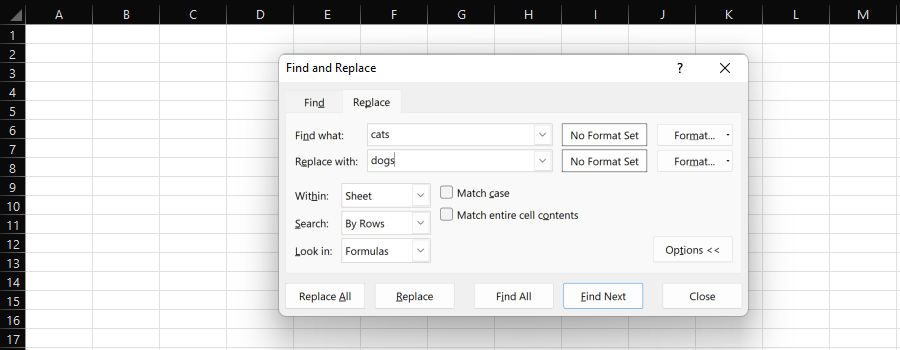 Captura de pantalla de Microsoft Excel, noviembre de 2022
Captura de pantalla de Microsoft Excel, noviembre de 2022
Al procesar datos para SEO, lo más probable es que seleccionemos una columna completa y "Reemplazar todo".
La fórmula SUSTITUIR proporciona aquí otra opción y es útil si no desea sobrescribir la columna existente.
Como ejemplo, podemos cambiar el protocolo de una URL de HTTP a HTTPS, o eliminarlo reemplazándolo con nada.
Cuando trabajamos con marcos de datos en Python, podemos usar str.replace:
df['URL'] = df['URL'].str.replace('http://', 'https://')O:
df['URL'] = df['URL'].str.replace('http://', '') # reemplazar sin nadaNuevamente, a diferencia de Excel, se pueden usar expresiones regulares, como con REGEXREPLACE de Google Sheets:
df['URL'] = df['URL'].str.replace('http://|https://', '')Alternativamente, si desea reemplazar varias subcadenas con diferentes valores, puede usar el método de reemplazo de Python y proporcionar una lista.
Esto le evita tener que encadenar múltiples funciones str.replace:
df['URL'] = df['URL'].replace(['http://', ' https://'], ['https://www.', 'https://www.' ], expresión regular = Verdadero)
IZQUIERDA/MEDIO/DERECHA
La extracción de una subcadena dentro de Excel requiere el uso de las funciones IZQUIERDA, MEDIA o DERECHA, dependiendo de dónde se encuentre la subcadena dentro de una celda.

Digamos que queremos extraer el dominio raíz y el subdominio de una URL:
=MEDIO(A2,ENCONTRAR(":",A2,4)+3,ENCONTRAR("/",A2,9)-ENCONTRAR(":",A2,4)-3) 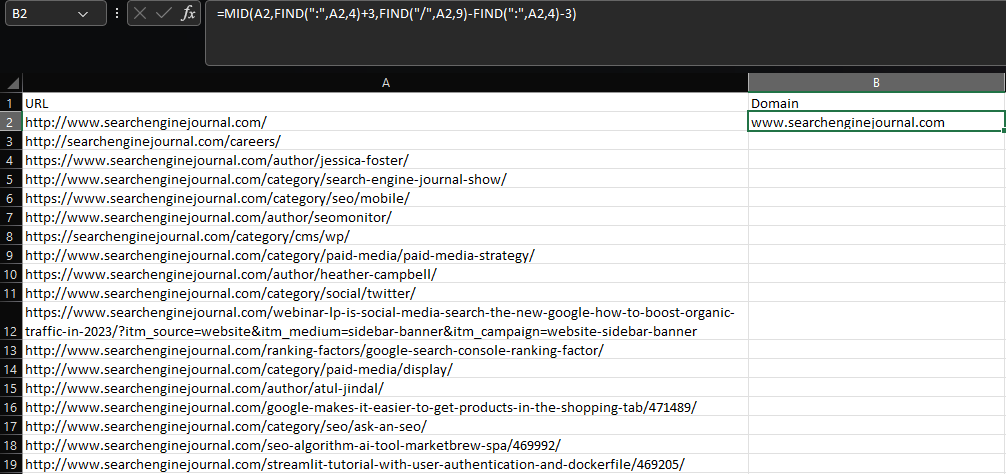 Captura de pantalla de Microsoft Excel, noviembre de 2022
Captura de pantalla de Microsoft Excel, noviembre de 2022
Usando una combinación de MID y múltiples funciones FIND, esta fórmula es fea, por decir lo menos, y las cosas empeoran mucho para extracciones más complejas.
Nuevamente, Google Sheets hace esto mejor que Excel, porque tiene REGEXEXTRACT.
Qué pena que cuando lo alimentas con conjuntos de datos más grandes, se derrite más rápido que un Babybel en un radiador caliente.
Afortunadamente, Pandas ofrece str.extract, que funciona de manera similar:
df['Dominio'] = df['URL'].str.extract('.*\://?([^\/]+)')  Captura de pantalla de VS Code, noviembre de 2022
Captura de pantalla de VS Code, noviembre de 2022
Combine con fillna para evitar valores nulos, como lo haría en Excel con IFERROR:
df['Dominio'] = df['URL'].str.extract('.*\://?([^\/]+)').fillna('-')Si
Las declaraciones IF le permiten devolver diferentes valores, dependiendo de si se cumple o no una condición.
Para ilustrar, supongamos que queremos crear una etiqueta para las palabras clave que se clasifican dentro de las tres primeras posiciones.
 Captura de pantalla de Microsoft Excel, noviembre de 2022
Captura de pantalla de Microsoft Excel, noviembre de 2022
En lugar de usar Pandas en este caso, podemos apoyarnos en NumPy y la función where (recuerde importar NumPy, si aún no lo ha hecho):
df['Top 3'] = np.where(df['Posición'] <= 3, 'Top 3', 'No Top 3')
Se pueden usar varias condiciones para la misma evaluación usando los operadores AND/OR y encerrando los criterios individuales entre corchetes:
df['Top 3'] = np.where((df['Position'] <= 3) & (df['Position'] != 0), 'Top 3', 'No Top 3')
En lo anterior, estamos devolviendo "Top 3" para cualquier palabra clave con una clasificación menor o igual a tres, excluyendo cualquier palabra clave clasificada en la posición cero.
IFS
A veces, en lugar de especificar varias condiciones para la misma evaluación, es posible que desee varias condiciones que devuelvan valores diferentes.
En este caso, la mejor solución es utilizar IFS:
=IFS(B2<=3,"Top 3",B2<=10,"Top 10",B2<=20,"Top 20")
 Captura de pantalla de Microsoft Excel, noviembre de 2022
Captura de pantalla de Microsoft Excel, noviembre de 2022
Nuevamente, NumPy nos brinda la mejor solución cuando trabajamos con marcos de datos, a través de su función de selección.
Con select, podemos crear una lista de condiciones, opciones y un valor opcional para cuando todas las condiciones son falsas:
condiciones = [df['Posición'] <= 3, df['Posición'] <= 10, df['Posición'] <=20] opciones = ['Top 3', 'Top 10', 'Top 20'] df['Rank'] = np.select(condiciones, elecciones, 'No Top 20')
También es posible tener múltiples condiciones para cada una de las evaluaciones.
Supongamos que estamos trabajando con un minorista de comercio electrónico con páginas de listado de productos (PLP) y páginas de visualización de productos (PDP), y queremos etiquetar el tipo de páginas de marca clasificadas dentro de los 10 primeros resultados.
La solución más fácil aquí es buscar patrones de URL específicos, como una subcarpeta o una extensión, pero ¿qué pasa si los competidores tienen patrones similares?
En este escenario, podríamos hacer algo como esto:
condiciones = [(df['URL'].str.contains('/category/')) & (df['Brand Rank'] > 0),
(df['URL'].str.contains('/producto/')) & (df['Ranking de marca'] > 0),
(~df['URL'].str.contains('/producto/')) & (~df['URL'].str.contains('/categoría/')) & (df['Ranking de marca'] > 0)]
opciones = ['PLP', 'PDP', 'Otro']
df['Tipo de página de marca'] = np.select(condiciones, opciones, Ninguno)Arriba, estamos usando str.contains para evaluar si una URL en el top 10 coincide o no con el patrón de nuestra marca, luego usamos la columna "Ranking de la marca" para excluir a cualquier competidor.
En este ejemplo, el signo de tilde (~) indica una coincidencia negativa. En otras palabras, estamos diciendo que queremos que cada URL de marca que no coincida con el patrón de "PDP" o "PLP" coincida con los criterios de 'Otro'.
Por último, Ninguno se incluye porque queremos que los resultados sin marca devuelvan un valor nulo.
 Captura de pantalla de VS Code, noviembre de 2022
Captura de pantalla de VS Code, noviembre de 2022
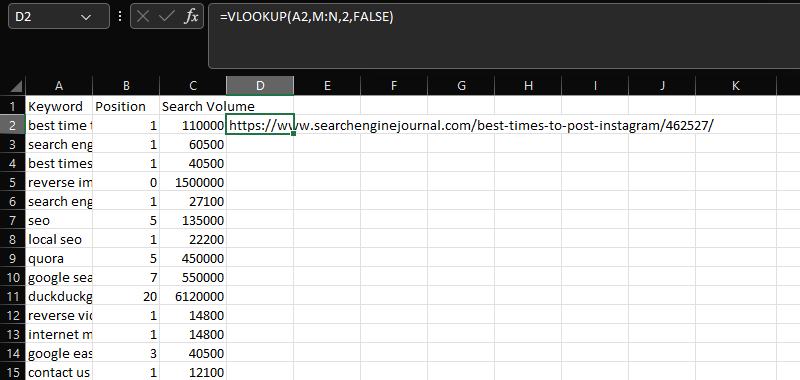
BUSCARV
BUSCARV es una herramienta esencial para unir dos conjuntos de datos distintos en una columna común.
En este caso, agregando las URL dentro de la columna N a los datos de volumen de búsqueda, posición y palabra clave en las columnas AC, usando la columna compartida "Palabra clave":
=BUSCARV(A2,M:N,2,FALSO)
 Captura de pantalla de Microsoft Excel, noviembre de 2022
Captura de pantalla de Microsoft Excel, noviembre de 2022
Para hacer algo similar con Pandas, podemos usar merge.
Al replicar la funcionalidad de una unión SQL, la fusión es una función increíblemente poderosa que admite una variedad de tipos de unión diferentes.
Para nuestros propósitos, queremos usar una combinación izquierda, que mantendrá nuestro primer marco de datos y solo fusionará los valores coincidentes de nuestro segundo marco de datos:
mergeddf = df.merge(df2, how='left', on='Keyword')
Una ventaja adicional de realizar una combinación sobre una BUSCARV es que no es necesario tener los datos compartidos en la primera columna del segundo conjunto de datos, como con la BUSCARX más reciente.
También extraerá varias filas de datos en lugar de la primera coincidencia en los hallazgos.
Un problema común al usar la función es que se dupliquen las columnas no deseadas. Esto ocurre cuando existen varias columnas compartidas, pero intenta hacer coincidir usando una.
Para evitar esto, y mejorar la precisión de sus coincidencias, puede especificar una lista de columnas:
mergeddf = df.merge(df2, how='left', on=['Keyword', 'Search Volume'])
En ciertos escenarios, es posible que desee activamente que se incluyan estas columnas. Por ejemplo, al intentar fusionar varios informes de clasificación mensuales:
mergeddf = df.merge(df2, on='Palabra clave', how='izquierda', sufijos=('', '_octubre'))\
.merge(df3, on='Palabra clave', how='izquierda', sufijos=('', '_septiembre'))El fragmento de código anterior ejecuta dos fusiones para unir tres marcos de datos con las mismas columnas, que son nuestras clasificaciones para noviembre, octubre y septiembre.
Al etiquetar los meses dentro de los parámetros de sufijo, terminamos con un marco de datos mucho más limpio que muestra claramente el mes, a diferencia de los valores predeterminados de _x e _y que se ven en el ejemplo anterior.
 Captura de pantalla de VS Code, noviembre de 2022
Captura de pantalla de VS Code, noviembre de 2022
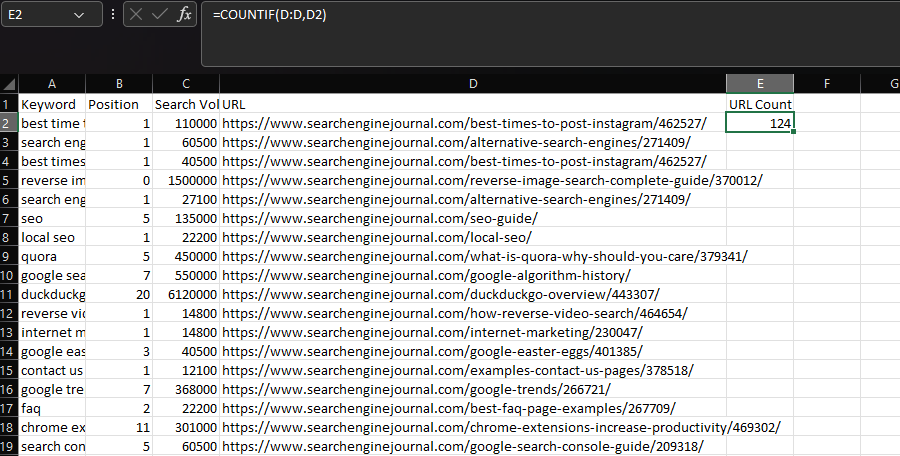
CONTAR.SI/SUMAR.SI/PROMEDIO.SI
En Excel, si desea realizar una función estadística basada en una condición, es probable que use CONTAR.SI, SUMAR.SI o PROMEDIO.SI.
Comúnmente, COUNTIF se usa para determinar cuántas veces aparece una cadena específica dentro de un conjunto de datos, como una URL.
Podemos lograr esto declarando la columna 'URL' como nuestro rango, luego la URL dentro de una celda individual como nuestro criterio:
=CONTAR.SI(D:D,D2)
 Captura de pantalla de Microsoft Excel, noviembre de 2022
Captura de pantalla de Microsoft Excel, noviembre de 2022
En Pandas, podemos lograr el mismo resultado usando la función groupby:
df.groupby('URL')['URL'].count()  Captura de pantalla de VS Code, noviembre de 2022
Captura de pantalla de VS Code, noviembre de 2022
Aquí, la columna declarada entre corchetes indica los grupos individuales, y la columna listada entre corchetes es donde se realiza la agregación (es decir, el conteo).
Sin embargo, el resultado que recibimos no es perfecto para este caso de uso, porque se consolidan los datos.
Por lo general, al usar Excel, tendríamos el recuento de URL en línea dentro de nuestro conjunto de datos. Luego, podemos usarlo para filtrar las URL enumeradas con más frecuencia.
Para hacer esto, use transform y almacene la salida en una columna:
df['Recuento de URL'] = df.groupby('URL')['URL'].transform('recuento')  Captura de pantalla de VS Code, noviembre de 2022
Captura de pantalla de VS Code, noviembre de 2022
También puede aplicar funciones personalizadas a grupos de datos mediante una función lambda (anónima):
df['Google Count'] = df.groupby(['URL'])['URL'].transform(lambda x: x[x.str.contains('google')].count())En nuestros ejemplos hasta ahora, hemos estado usando la misma columna para nuestras agrupaciones y agregaciones, pero no es necesario. De manera similar a COUNTIFS/SUMIFS/AVERAGEIFS en Excel, es posible agrupar usando una columna y luego aplicar nuestra función estadística a otra.
Volviendo al ejemplo anterior de la página de resultados del motor de búsqueda (SERP), es posible que deseemos contar todos los PDP clasificados por palabra clave y devolver este número junto con nuestros datos existentes:
df['PDP Count'] = df.groupby(['Keyword'])['URL'].transform(lambda x: x[x.str.contains('/product/|/prd/|/pd/' )].contar())  Captura de pantalla de VS Code, noviembre de 2022
Captura de pantalla de VS Code, noviembre de 2022Que en el lenguaje de Excel, se vería así:
=SUMA(CONTAR.SI(A:A,[@Palabra clave],D:D,{"*/producto/*","*/prd/*","*/pd/*"}))
Tablas dinamicas
Por último, pero no menos importante, es hora de hablar de tablas dinámicas.
En Excel, es probable que una tabla dinámica sea nuestro primer puerto de escala si queremos resumir un gran conjunto de datos.
Por ejemplo, cuando trabajamos con datos de clasificación, es posible que queramos identificar qué URL aparecen con más frecuencia y su posición promedio en la clasificación.
 Captura de pantalla de Microsoft Excel, noviembre de 2022
Captura de pantalla de Microsoft Excel, noviembre de 2022
Nuevamente, Pandas tiene su propio equivalente de tablas dinámicas, pero si todo lo que desea es un recuento de valores únicos dentro de una columna, esto se puede lograr utilizando la función value_counts:
cuenta = df['URL'].value_counts()
Usar groupby también es una opción.
Anteriormente en el artículo, realizar un groupby que agregara nuestros datos no era lo que queríamos, pero es precisamente lo que se requiere aquí:
agrupados = df.groupby('URL').agg(
url_frequency=('Palabra clave', 'recuento'),
avg_position=('Posición', 'media'),
)
agrupado.reset_index(inplace=True)  Captura de pantalla de VS Code, noviembre de 2022
Captura de pantalla de VS Code, noviembre de 2022
Se han aplicado dos funciones agregadas en el ejemplo anterior, pero esto podría expandirse fácilmente, y hay 13 tipos diferentes disponibles.
Hay, por supuesto, momentos en los que queremos usar pivot_table, como cuando realizamos operaciones multidimensionales.
Para ilustrar lo que esto significa, reutilicemos las agrupaciones de clasificación que hicimos usando declaraciones condicionales e intentemos mostrar la cantidad de veces que una URL se clasifica dentro de cada grupo.
ranking_agrupaciones = df.groupby(['URL', 'Agrupación']).agg(
url_frequency=('Palabra clave', 'recuento'),
)  Captura de pantalla de VS Code, noviembre de 2022
Captura de pantalla de VS Code, noviembre de 2022
Este no es el mejor formato para usar, ya que se han creado varias filas para cada URL.
En su lugar, podemos usar pivot_table, que mostrará los datos en diferentes columnas:
pivote = pd.pivot_table(df, índice=['URL'], columnas=['Agrupación'], aggfunc='tamaño', valor_relleno=0, )
 Captura de pantalla de VS Code, noviembre de 2022
Captura de pantalla de VS Code, noviembre de 2022
Pensamientos finales
Ya sea que esté buscando inspiración para comenzar a aprender Python o que ya lo esté aprovechando en sus flujos de trabajo de SEO, espero que los ejemplos anteriores lo ayuden en su viaje.
Como se prometió, puede encontrar un cuaderno de Google Colab con todos los fragmentos de código aquí.
En verdad, apenas hemos arañado la superficie de lo que es posible, pero comprender los conceptos básicos del análisis de datos de Python le dará una base sólida sobre la cual construir.
Más recursos:
- Pruebe estas herramientas y métodos para exportar resultados de búsqueda de Google a Excel
- 12 puntos de datos SEO esenciales para cualquier sitio web
- SEO técnico avanzado: una guía completa
Imagen destacada: mapo_japan/Shutterstock