
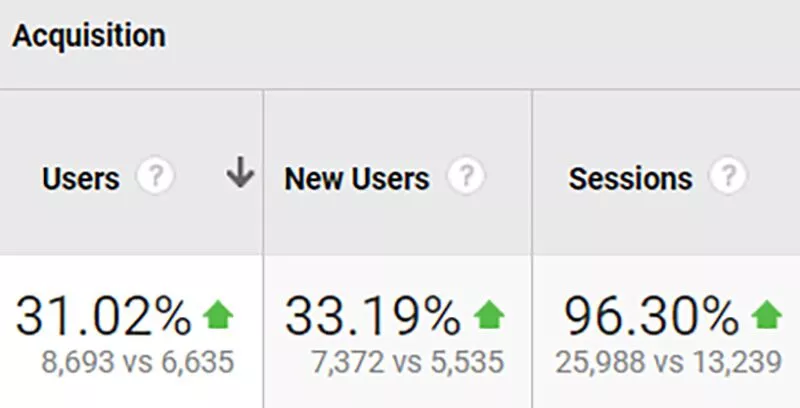
トラフィックを96%増やす方法(SEOケーススタディ)
公開: 2022-07-12ウェブサイトのサイズに関係なく、SEOキャンペーンを成功させる秘訣は、(ページ上)、リンク(ページ外)、および技術的要因です。
あなたのコンテンツはレースカーのボディのように機能し、レースの燃料のようなバックリンクを参照しています。 技術的要因は、他のすべてが最高のパフォーマンスを発揮できるようにするための要点のように機能します。
これらのいずれかを見逃した場合、あなたのウェブサイトは、トラックを降りるのに苦労しているレーシングカーのようにランク付けするのに苦労します。
このケーススタディでは、検索イニシアチブの私のチームがクライアントのオーガニックトラフィックを96%増加させるために行った正確な手順を学習します。 このケーススタディのレンズを通して、SEOの3つの柱(ページ上、ページ外、および技術的要因)の短期集中コースを受講できます。

この記事では、次の方法を学習します。
 インデックスの肥大化を修正し、サイトマップが正しく実装されていることを確認して、Googleが適切なページをクロールしてインデックスに登録しやすくすることで、クロール予算を管理します。
インデックスの肥大化を修正し、サイトマップが正しく実装されていることを確認して、Googleが適切なページをクロールしてインデックスに登録しやすくすることで、クロール予算を管理します。 - 潜在的な重複コンテンツの問題を回避するために、hreflangタグを正しく実装してください。
- 補足ブログコンテンツでロングテールキーワードをターゲットにして、キーワードの可視性を向上させ、トピックの関連性を構築します。
- バックリンクが不足しているパフォーマンスの低い重要なページを特定して、権限を構築し、ランキングを上げるのに役立てます。
戦略の詳細に入る前に、ここにWebサイトの目標と直面した主な課題に関するいくつかの重要な情報があります。
目次
- チャレンジ
- クロール予算管理
- クロール予算とは何ですか?なぜそれが重要なのですか?
- インデックスの肥大化を修正する方法
- XMLサイトマップ
- XMLサイトマップとは何ですか?なぜそれが重要なのですか?
- XMLサイトマップを作成する方法
- XMLサイトマップをGoogleに送信する方法
- hreflang属性を正しく実装する
- hreflangとは何ですか?
- なぜhreflangがSEOにとって重要なのですか?
- いつhreflang属性を実装する必要がありますか?
- HTMLを使用してhreflang属性を実装する方法
- サイトマップを使用してhreflang属性を実装する方法
- Hreflangを実装する際のベストプラクティスと一般的な落とし穴
- ブログコンテンツをサポートすることでトピックの関連性を確立する
- ロングテールキーワードのアイデアを見つける
- ブログコンテンツの作成と最適化
- 重要なページへのリンクを作成する
- リンクレポートによるAhrefsのベストを使用したリンク構築の機会の特定
- 結果
- 結論
- マットディギティ
チャレンジ
このキャンペーンの主な目的は、サイトの質の高いオーガニックトラフィックの量を増やして、リードの数を増やすことでした。
クライアントは米国を拠点とするSaaS(Software as a Service)B2B企業であり、米国などの英語圏の国々、日本、中国、韓国、フランスなど、さまざまな国を対象としたWebページを備えたクラウドソフトウェアを構築して提供しています。 。
これを念頭に置いて、主な課題の1つはインデックスの肥大化でした。 英語版のWebサイトだけでも3万を超えるクロール可能なURLがありました。これはSaaSWebサイトにはかなり過剰です。 これらのクロールバジェットの問題を修正し、クライアントがTSIに参加したときに欠落していたXMLサイトマップをアップロードすることが優先事項でした。 詳細については、以下をご覧ください…
クライアントのhreflang(コンテンツの言語とターゲットの場所についてGoogleに通知する方法)の設定が正しく実装されていませんでした。
サイトのコアランディングページは比較的よく最適化されていましたが、トラフィックを誘導するためのサポートコンテンツが不足していました。 これは、クライアントのブログがアクティブでなく、ほんの一握りの記事が公開されたためです。
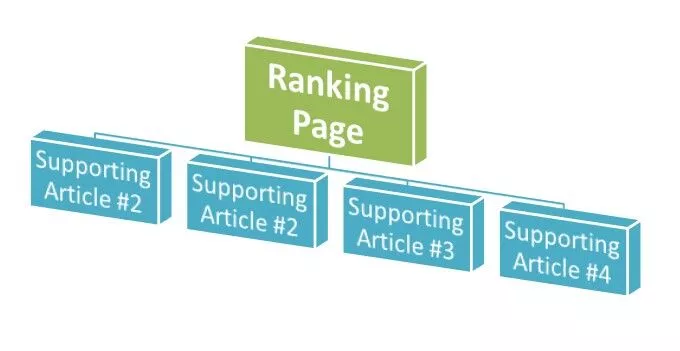
これは、ロングテールのキーワードをターゲットにするための情報ブログ記事を調査および作成することによって対処されました。 これは、ニッチ内でクライアントのトピックの関連性を構築するのに役立ち、サイトのメインページへの内部リンクの機会を提供しました。
最後のステップは、Webサイトの最も重要なページであるホームページとサービスページでのページ権限の構築に焦点を当てたリンク構築戦略で権限を構築することでした。
以下の手順に従って、自分のWebサイトでこれらの課題を克服する方法を見つけてください。
クロール予算管理
クロール予算とは何ですか?なぜそれが重要なのですか?
Googleには、ワールドワイドウェブのクロールとインデックス作成に割り当てることができる時間とリソースが限られています。 したがって、Googleは、特定のWebサイトのクロールに費やす時間に制限を設定します。これはクロール予算と呼ばれます。

クロールバジェットは、次の2つの要素によって決定されます。
 クロール容量の制限–これは、Googleが同時にウェブサイトをクロールするために使用できる接続の最大数です。 これは、Googlebotがあまりにも多くのリクエストでウェブサイトのサーバーを圧倒するのを防ぐためにあります。
クロール容量の制限–これは、Googleが同時にウェブサイトをクロールするために使用できる接続の最大数です。 これは、Googlebotがあまりにも多くのリクエストでウェブサイトのサーバーを圧倒するのを防ぐためにあります。 - クロール需要– Googleは、「他のサイトと比較した場合のサイズ、更新頻度、ページ品質、関連性」などのいくつかの要因に基づいて、Webサイトをクロールするのに必要な時間を計算します。
数十万ページの大規模なWebサイトがある場合は、最も重要なページのみがクロールされていること、つまり、重要でないURLにクロール予算を浪費していないことを確認する必要があります。
クロール予算管理とは、インデックスの肥大化の原因となる無関係なページをGoogleがクロールしないようにすることです。
インデックスの肥大化を修正する方法
インデックスの肥大化は、Googlebotが質の悪いページをクロールしすぎると発生します。 これらのページは、ユーザーにほとんどまたはまったく価値を提供しないか、複製されているか、コンテンツが薄いか、または存在しなくなっている可能性があります。
クロールされる重要でない低品質のページが多すぎると、Googleが重要なURLではなくそれらのURLのクロールに時間を費やすため、貴重なクロール予算が無駄になります。
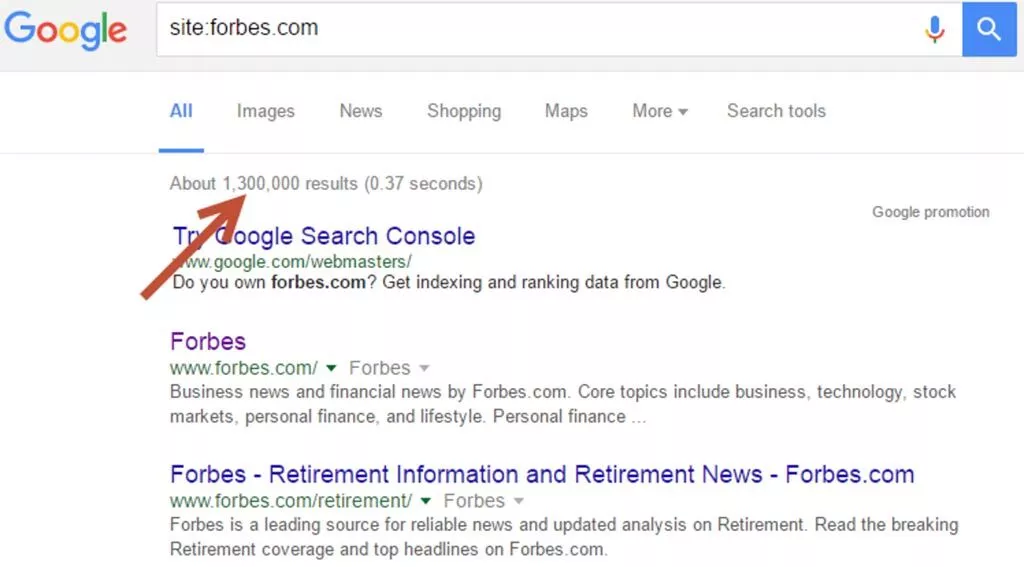
私たちのクライアントの英語サイトには、3万を超えるレガシーイベントページがインデックスに登録されていました。これらは、クライアントのニッチ内の業界イベントに関するコンテンツ、つまりイベントのチラシと日付や時刻などの重要な情報がほとんど含まれていないページでした。
インデックスの肥大化を引き起こす最も一般的な原因のいくつかと、サイト検索を使用してそれらを見つける方法を見てみましょう。
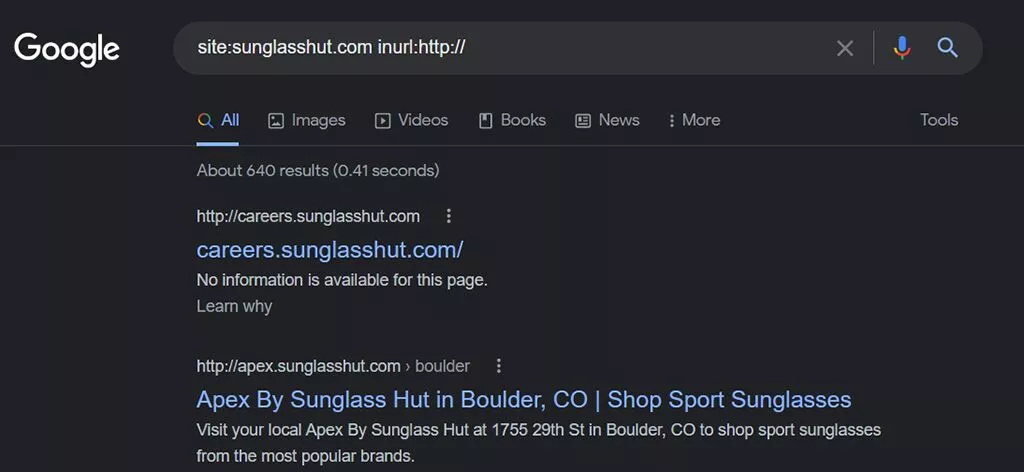
- HTTPページ–まだHTTPページのインデックスが付けられているSSL証明書を持つWebサイトは、不要な重複コンテンツを引き起こします。 Googleで次のサイト検索を使用します。
site:yourdomain.com inurl:http:// site:yourdomain.com -inurl:https://
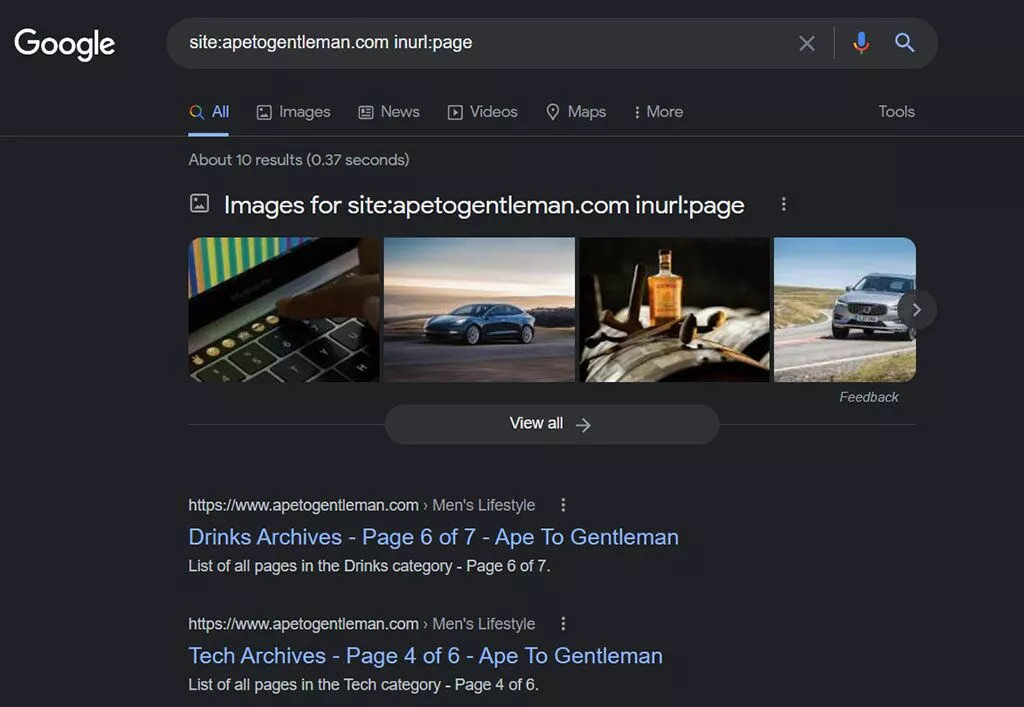
- ページ付け–同様に、ページ付けされたページ(コンテンツが複数のページに分割されている場合)は、不要な重複コンテンツを作成します。 それらを見つけるには、Googleで次のサイト検索を使用します。
site:yourdomain.com inurl:/ page / site:yourdomain.come inurl:p =
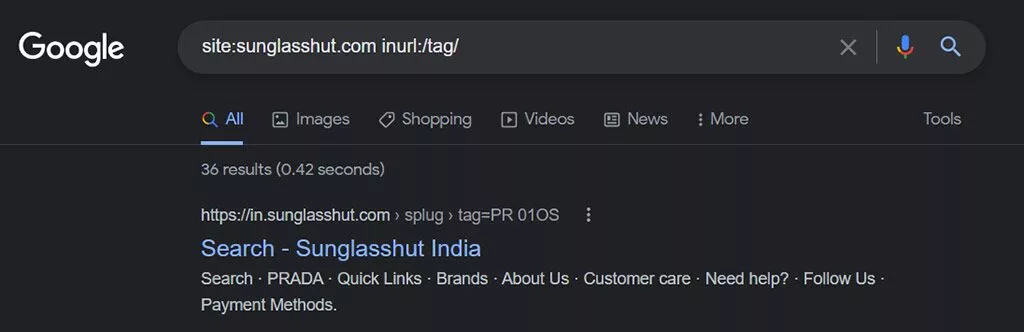
- / tag /ページ–タグページは、類似したページをグループ化できるカテゴリページのようなものです。 これらは一般的に、類似のブログ投稿、つまりexample.com/tag/sports/をグループ化するために使用されます。
次のサイト検索を使用して、サイトでインデックスに登録されている/tag/ページを見つけます。
site:yourdomain.com inurl:/ tag /
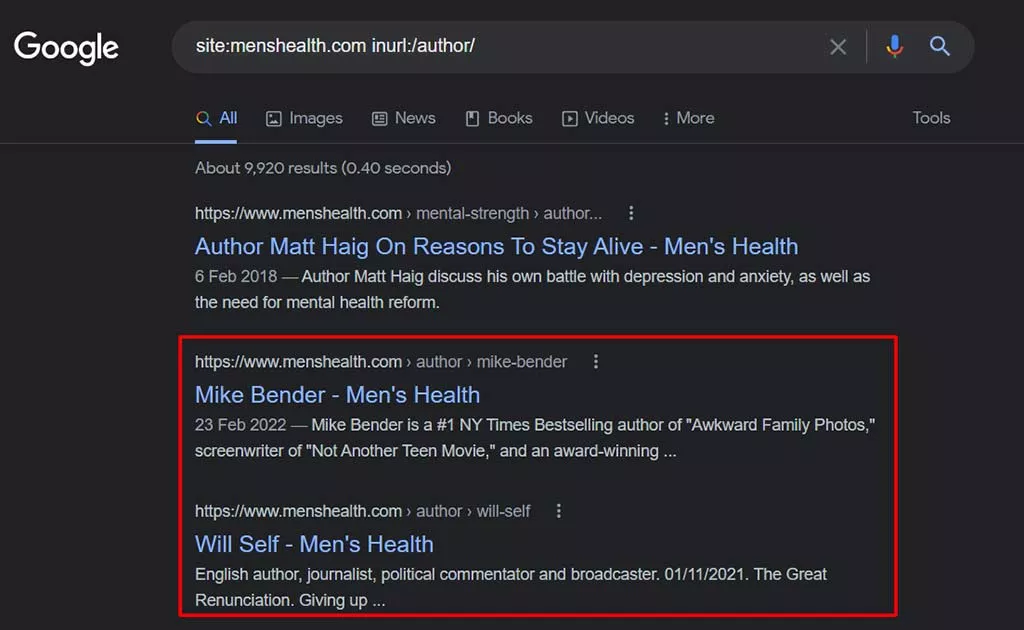
- / author /ページ–作成者ページはタグページに似ていますが、同じ作成者によって作成されたページのグループ、つまりexample.com/author/matt-diggity/である点が異なります。
Googleで次のサイト検索を使用して、不要な/author/ページを特定します。
site:yourdomain.com inurl:/ author /
- および非www。 ページ–別の一般的な原因は、www以外のページを提供するときにwwwページをクロールしてインデックスを作成することです(その逆も同様です)。 これらを見つけるには、次を使用します。
site:yourdomain.com inurl:www。 site:yourdomain.com -inurl:www。
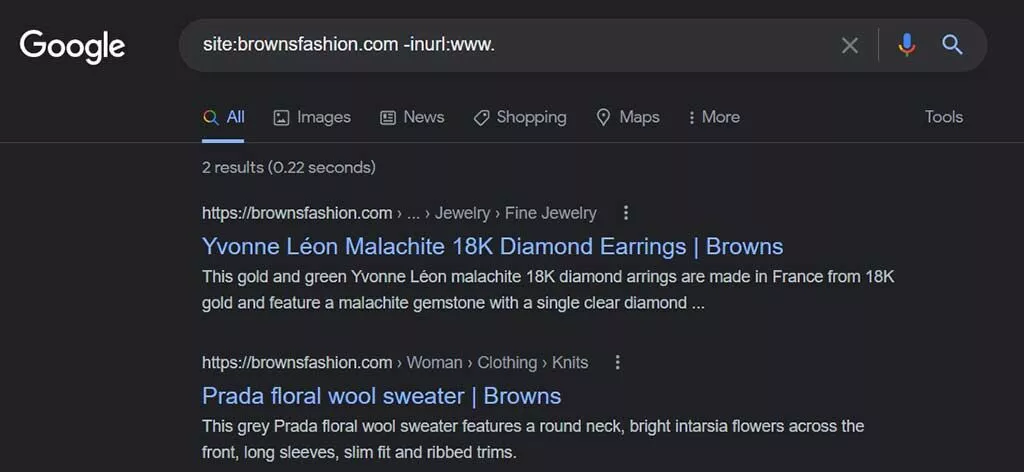
また、次の種類のページに出くわす場合があります。
- 末尾のスラッシュ–これは、すべてのURLが末尾のスラッシュ「/」で終わっているが、末尾のスラッシュがまだインデックスに登録されていないURLがある場合に問題になります。 例えば:
example.com/with-trailing-slash/ example.com/without-trailing-slash
- 重複ページ–同じコンテンツを含む複数のページがある場合(domain.com、domain.com / index.html、domain.com / homepage /など)。
- テスト/開発ページ–ステージングサイトまたは開発サイトのページはインデックスに登録しないでください。 たとえば、dev.example.comまたはdev.example.com/category/sports/です。
- その他のページ–つまり、チェックアウトページ、ありがとうページなど。
クロールするページとクロールしないページをGoogleに伝える方法はいくつかあります。
 Robots.txt – robots.txtファイルには、Googlebotがクロールに時間を費やしたくないページやリソースを指定できます。 このファイルは、Googleによるページのインデックス作成を妨げるものではないことに注意してください。このためには、noindexタグを実装する必要があります(次のポイント)。
Robots.txt – robots.txtファイルには、Googlebotがクロールに時間を費やしたくないページやリソースを指定できます。 このファイルは、Googleによるページのインデックス作成を妨げるものではないことに注意してください。このためには、noindexタグを実装する必要があります(次のポイント)。
これが私のサイトのrobots.txtファイルです。
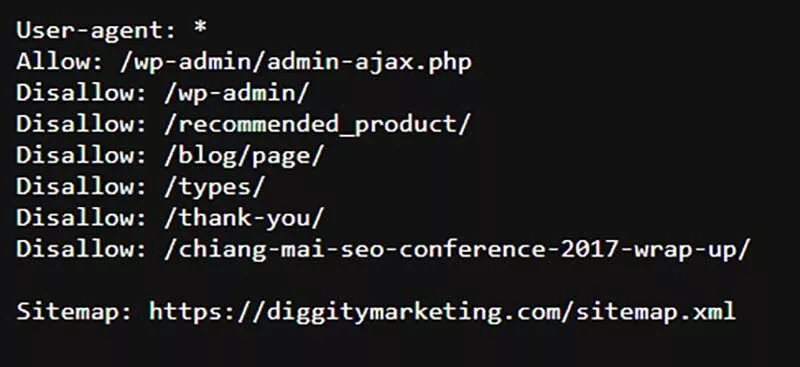
通常、robots.txtは、yourdomain.com/robots.txtにアクセスして見つけることができます。
Googleによるページのクロールをブロックするための基本的な形式は次のとおりです。
ユーザーエージェント:[ユーザーエージェント名] 禁止:[URL文字列はクロールされません]
- ユーザーエージェント–ルールに従う必要のあるロボット/クローラーの名前。これをアスタリスク(*)に置き換えて、すべてのロボットにキャッチオールルールを設定できます。
- 許可しない–これはクロールしてはならないURL文字列です。
次に例を示します。
ユーザーエージェント: * 禁止:/ author /
上記のルールは、すべてのロボットが/author/を含むURLにアクセスできないようにします。
robots.txtファイルのベストプラクティスについて詳しくは、こちらをご覧ください。
 Noindexタグ– Googleがページのインデックスを作成しないようにする場合は、インデックスを作成しないページの<head>セクション内に「noindex」メタタグを追加します。 次のようになります。
Noindexタグ– Googleがページのインデックスを作成しないようにする場合は、インデックスを作成しないページの<head>セクション内に「noindex」メタタグを追加します。 次のようになります。
<meta name = "robots" content = "noindex">
WordPress Webサイトをお持ちの場合は、YoastSEOなどのプラグインを使用してこれを簡単に行うことができます。
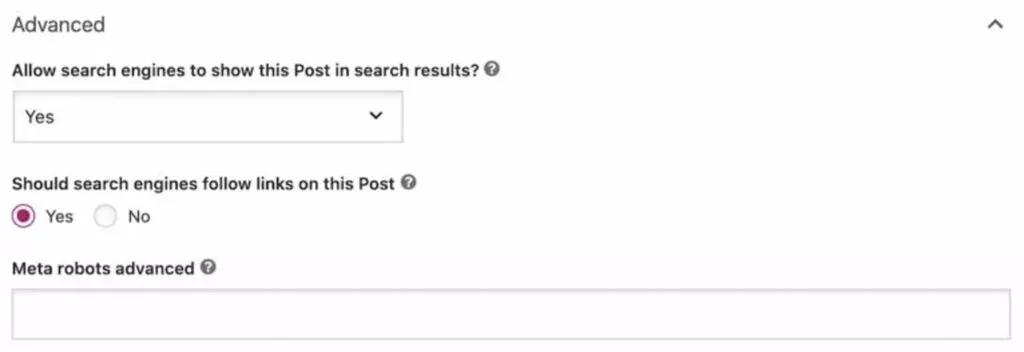
任意のページで、プラグインの[詳細設定]タブまでスクロールし、「検索エンジンがこの投稿を検索結果に表示できるようにしますか? 」を選択します。
 URL削除ツール– Google検索コンソールの削除ツールは、Googleのインデックスからページを(一時的に)削除するもう1つの方法です。 Google検索からページをすばやく削除する必要がある緊急の場合には、この方法を使用することをお勧めします。
URL削除ツール– Google検索コンソールの削除ツールは、Googleのインデックスからページを(一時的に)削除するもう1つの方法です。 Google検索からページをすばやく削除する必要がある緊急の場合には、この方法を使用することをお勧めします。
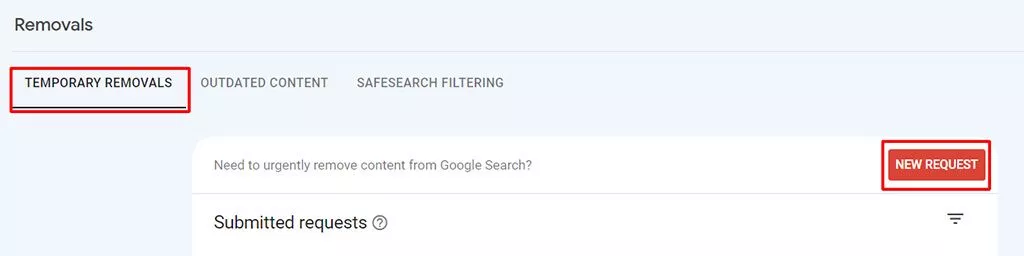
クロール予算を管理する方法について詳しくは、こちらをご覧ください。
XMLサイトマップ
robots.txtファイルは、検索エンジンのボットが特定のページにアクセスするのを防ぐために使用されますが、検索してインデックスを作成するページに関してGoogleを正しい方向に導くために必要なもう1つの重要なファイルがあります。
これがXMLサイトマップです。クライアントがたまたまウェブサイトから欠落していたものです。
XMLサイトマップとは何ですか?なぜそれが重要なのですか?
XMLサイトマップは、ExtensibleMarkupLanguageを使用したURLの「マップ」です。
その目的は、Webサイトのコンテンツ、つまりページ、ビデオ、およびその他のファイルに関する情報と、それらの間のそれぞれの関係を提供することです。

XMLサイトマップは、最も重要なページをGoogleに直接指定できるため重要です。
サイトマップの例を次に示します:https://diggitymarketing.com/sitemap.xml
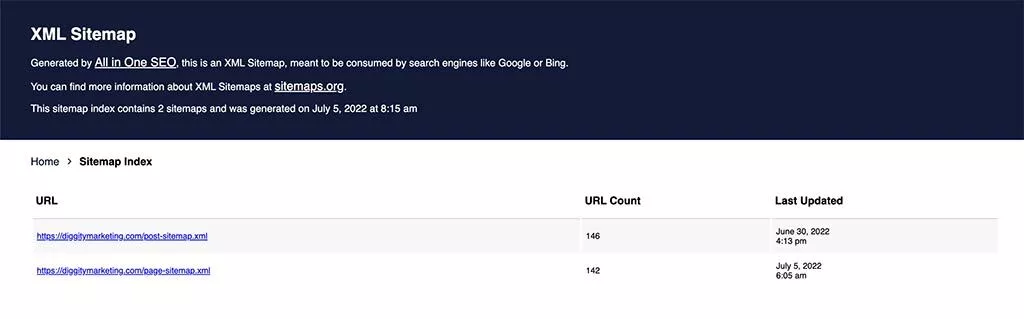
この情報を提供することで、Googleのようなクローラーは、クロールの効率を向上させ、Webページの構造を理解しやすくなります。 それをあなたのウェブサイトの目次と考えてください。
これを行うことにより、Webページがより迅速にインデックスに登録される可能性が高くなります。
基本的なXMLサイトマップの例を次に示します。
<?xml version = "1.0" encoding = "UTF-8"?>
<urlset xmlns = "http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc> https://domain.com/ </ loc>
</ url>
<url>
<loc> https://domain.com.com/blog/ </ loc>
</ url>
</ urlset>多くの場合、XMLサイトマップはYoastから自動生成されたサイトマップのようになります:https://lakewoodrestorationpro.com/page-sitemap.xml
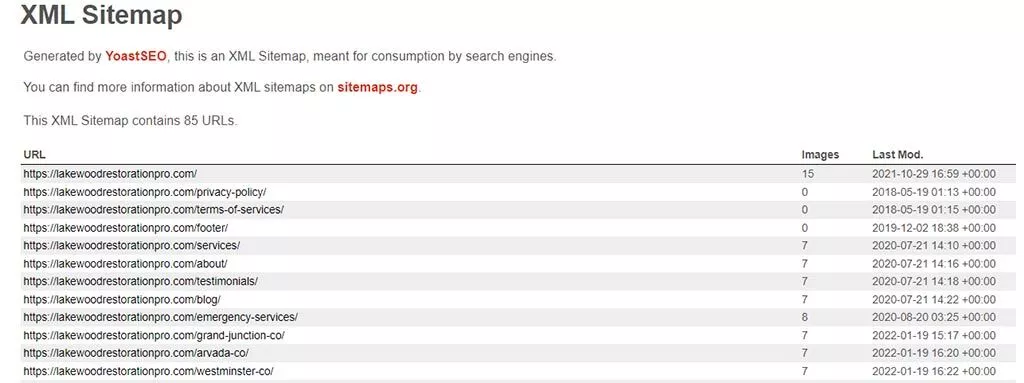
なんで? プラグイン/ツールを使用してサイトマップを生成する方が、手動でハードコーディングするよりもはるかに簡単だからです。
XMLサイトマップを作成する方法
CMSに応じて、WebサイトのXMLサイトマップを作成する方法はたくさんあります。
- Shopify、Wix、Squarespace –すべて自動的にサイトマップを作成します(com / sitemap.xmlからアクセスできます)–残念ながら、これらはすべて編集できないため、非常に制限があります。
- WordPress – WordPress.org Webサイトのサイトマップを作成するには、Yoastのようなプラグインを使用することをお勧めします–無料で本当に使いやすいです。
- WordPressダッシュボードにログインし、[プラグイン]>[新規追加]に移動します
- 「 YoastSEO 」を検索し、 [今すぐインストール]を押します
- 次にアクティブ化

 YoastSEO >一般>機能に移動します
YoastSEO >一般>機能に移動します

 「XMLサイトマップ」オプションが「オン」に設定されていることを確認します
「XMLサイトマップ」オプションが「オン」に設定されていることを確認します

これで、サイトマップが自動的に生成され、com/sitemap.xmlまたはyourdomain.com/sitemap_index.xmlで利用できるようになります。
- CMSなし/任意のWebサイト(Screaming Frog) –他のWebサイトの場合、ScreamingFrogなどのサイトクローラーを使用してXMLサイトマップを生成できます。 サイトのページ数が500ページ未満の場合は、無料バージョンを使用できます。それ以外の場合は、有料バージョンにアップグレードする必要があります。
- ScreamingFrogのSEOスパイダーをインストールして開いたら、スパイダーモードが選択されていることを確認します。
- ドメインを入力し、[開始]をクリックします。

- ツールはページをクロールし、このような進行状況バーを表示します。 繰り返しになりますが、URLは500に制限されているため、サイトにさらにページがある場合は、ライセンスを購入する必要があります。

- サイトがクロールされたら、上部のメニューバーで[サイトマップ]>[XMLサイトマップ]に移動します。

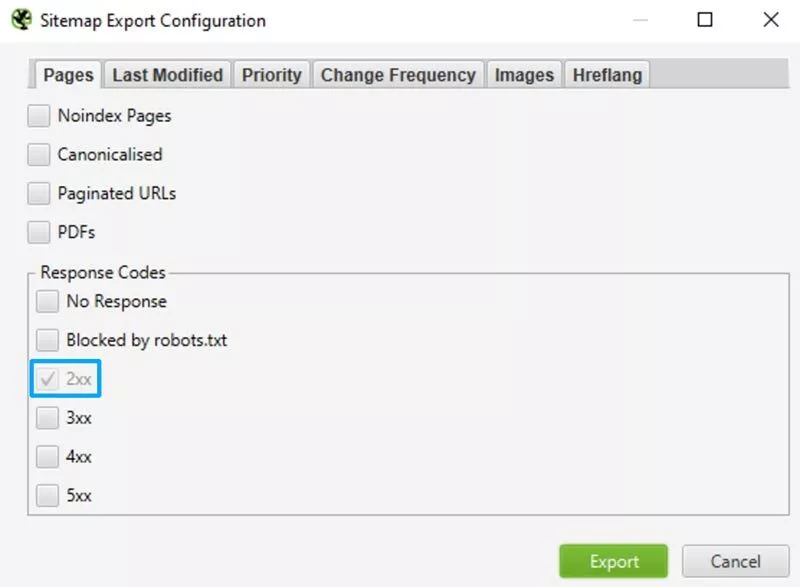
- 2xx応答コードが選択されていることを確認してください。 サイトにPDFが含まれている場合は、それらが重要で関連性がある場合にのみPDFを含めてください。
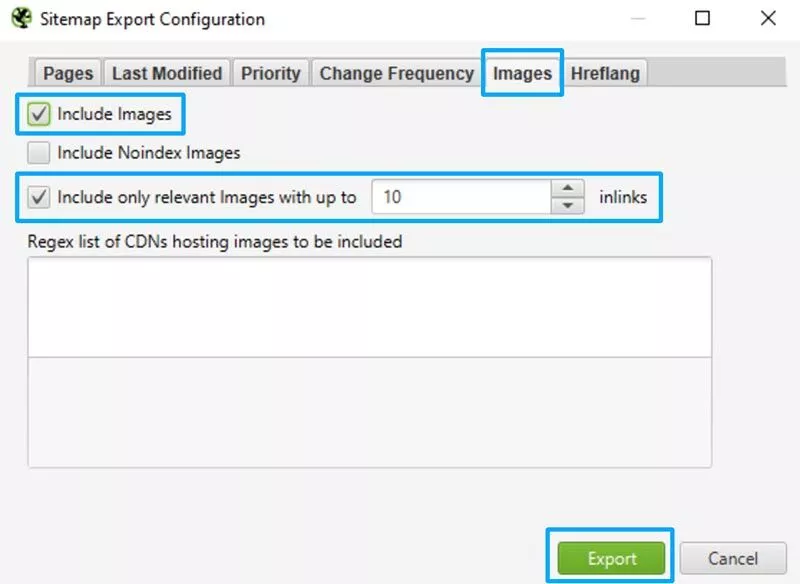
 [画像]タブに移動し、[画像を含める]を選択します。 3番目のボックス(最大10個のリンクを持つ関連画像のみを含める)が自動的にチェックされます。 [エクスポート]をクリックします。
[画像]タブに移動し、[画像を含める]を選択します。 3番目のボックス(最大10個のリンクを持つ関連画像のみを含める)が自動的にチェックされます。 [エクスポート]をクリックします。
ファイルに「サイトマップ」という名前を付けて、.xml形式で保存します。
XML-Sitemaps.comのようなXMLサイトマップジェネレーターもあります。ここで行う必要があるのは次のとおりです。
- ドメインを入力して[開始]をクリックします。

- ツールはページをクロールし、このような進行状況バーを表示します。 繰り返しになりますが、URLは500に制限されているため、サイトにさらにページがある場合は、有料バージョンにアップグレードする必要があります。
- 完了したら、[サイトマップの詳細を表示]をクリックします。
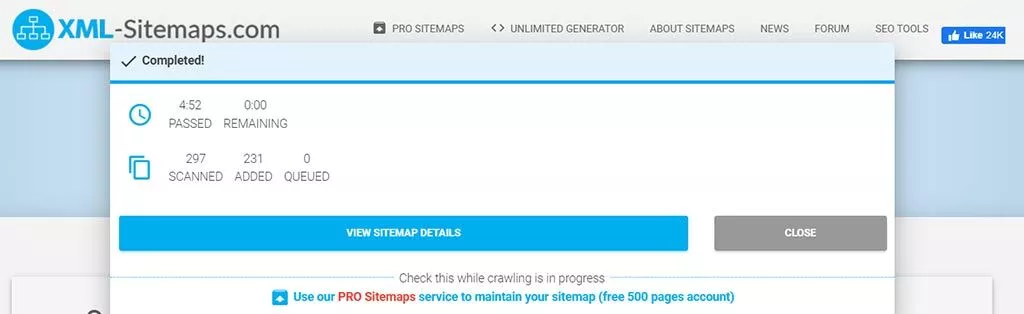
- 次に、[ XML SITEMAPファイルをダウンロード]をクリックして、生成されたサイトマップをダウンロードできます。
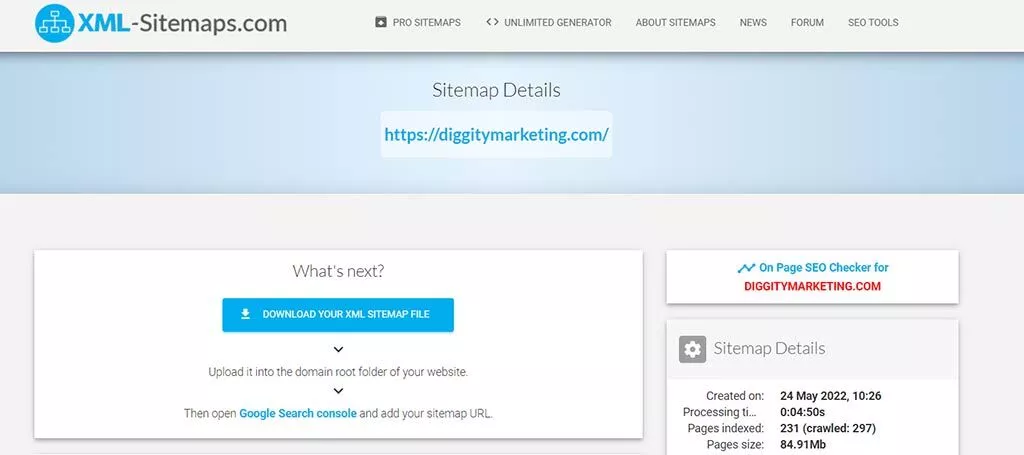
- [完全なXMLサイトマップを表示]をクリックして、生成されたファイルを新しいタブでプレビューすることもできます:https://www.xml-sitemaps.com/download/diggitymarketing.com-29b52add/sitemap.xml?view=1
上記のメソッドについて注意すべきことの1つは、それらに含めたくないURLまたはページが含まれている可能性があることです。 たとえば、Screaming Frogのようなクローラーには、ページ付けされたページや/ tag /、/ author /ページが含まれる場合があります。これは、上記で学習したように、インデックスの肥大化を引き起こします。 したがって、生成されたファイルを確認し、適切なページのみが存在することを確認することをお勧めします。
XMLサイトマップを手動でコーディングするオプションもあります。これは、ページ数が非常に少ない小さなWebサイトには問題ありませんが、大規模なサイトにはおそらく最も効率的ではありません。
選択する方法に関係なく、 domain.com / sitemap.xmlからアクセスできるように、sitemap.xmlファイルをpublic_htmlディレクトリにアップロードすることを忘れないでください。
XMLサイトマップをGoogleに送信する方法
XMLサイトマップをGoogleに送信するには、Google検索コンソールに移動して[サイトマップ]をクリックし、サイトマップの場所(つまり、「sitemap.xml」)を入力して、[送信]をクリックします。
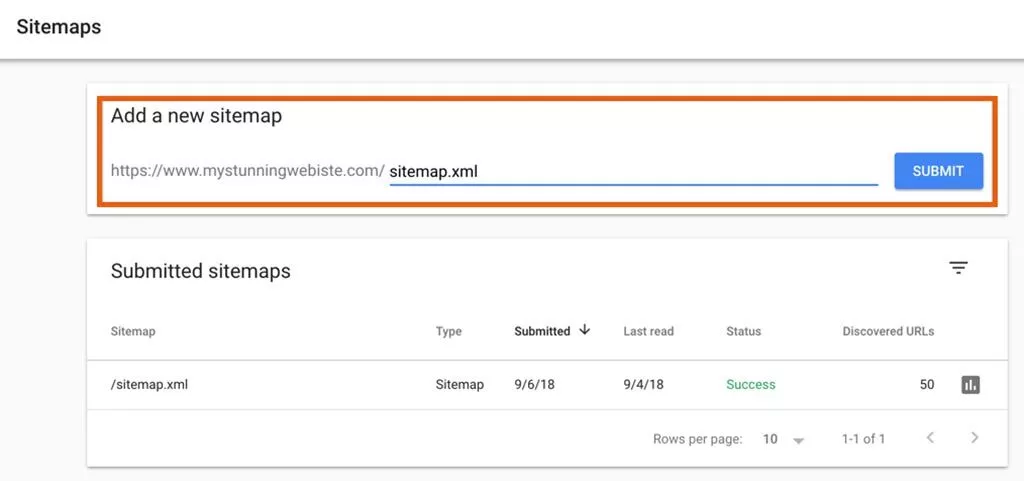
それでおしまい!
次のディレクティブを使用して、robots.txtファイル内にXMLサイトマップへのリンクを追加することも忘れないでください。
サイトマップ:http://www.example.com/sitemap.xml
複数のサイトマップがある場合は、別のディレクティブを追加するだけで、次のようになります。
サイトマップ:http://www.example.com/sitemap-1.xml サイトマップ:http://www.example.com/sitemap-2.xml サイトマップ:http://www.example.com/sitemap-3.xml
この最後のステップにより、Google(および他のクローラー)がサイトマップを見つけて重要なページをクロールするのがさらに簡単になります。
Yoastのような多くのプラグインは、このプロセスを自動化し、サイトマップをrobots.txtファイルに自動的に追加します。
hreflang属性を正しく実装する
hreflang属性を正しく実装することは、経験豊富なWeb開発者、SEO、およびリスクを理解している人だけが行うべき高度な手法です。 ただし、Webサイトのコンテンツが複数の言語で利用できる場合は、hreflang属性が特に重要です。

これを正しく設定すると、基本的に英語のWebサイトをさまざまな言語に複製して、ターゲットの場所全体でトラフィックとキーワードの可視性を最大化できます。
さて、皆さん全員がさまざまな言語に翻訳する必要のあるWebサイトを持っているわけではないことを私は知っています。 心配しないでください。これを機能させるためにできることがまだあります。
アメリカをターゲットにしたアメリカ英語のウェブサイトがあるとすると、イギリス、カナダ、オーストラリアのバージョンのサイト(翻訳はほとんど必要ありません)を作成して、これらの地域内のトラフィックを簡単に増やすことができます。 これを行う方法の例を見つけるために読んでください。
hreflangとは何ですか?
Hreflangは、ローカライズされたバージョンのWebページについてGoogleに通知するために使用されるHTML属性(またはタグ)です。 この属性を使用して、コンテンツの言語とターゲットの場所を指定できます。
なぜhreflangがSEOにとって重要なのですか?

Hreflangsは、Googleなどの検索エンジンが、ユーザーの場所や優先言語に基づいて最も関連性の高いバージョンのWebページを提供するのに役立つため、SEOにとって重要です。 これにより、ユーザーがWebサイトを離れて、好みの言語でより関連性の高い結果を見つける可能性が最小限に抑えられるため、Webサイトのユーザーエクスペリエンスが向上します。
hreflangタグを正しく実装すると、重複コンテンツの問題を防ぐという追加の利点があります。 イギリス人とアメリカ人の読者のためにそれぞれ書かれた2つのWebページがあると想像してください。
- https://www.domain.com/uk/hreflang/ –イギリス英語で書かれています(つまり、「optimise」と「£」)
- https://www.domain.com/us/hreflang/ –上記と同じ記事ですが、アメリカ英語で書かれています(つまり、「optimize」と「$」)
これらのページはほとんど同じですが、Googleはそれらを重複と見なし、インデックスで1つのページを他のページよりも優先する場合があります。
したがって、hreflangタグを実装すると、それらの間の関係を強調するのに役立ちます。つまり、これらのページのコンテンツは類似しているが、どちらも異なるオーディエンス向けに最適化されていることをGoogleに伝えています。

これは、英語を話す多くの場所をターゲットにするために、基本的にWebサイトを(最小限の翻訳で)「複製」することにより、これをうまく利用している実際のサイトの例です。
- https://www.electricteeth.com/ –アメリカのSERPをターゲットに
- https://www.electricteeth.com/uk/ –英国のSERPを対象
- https://www.electricteeth.com/ca/ –カナダのSERPを対象
- https://www.electricteeth.com/au/ –オーストラリアのSERPをターゲット
いつhreflang属性を実装する必要がありますか?
次の場合は、hreflang属性を実装する必要があります。
- Webページのメインコンテンツは単一の言語であり、テンプレートの一部のみを翻訳します。 たとえば、Webサイトが英語であり、ページのメニューバーとフッター情報のみを他の言語に翻訳する場合です。
- コンテンツに地域のバリエーションがある場合(つまり、英語で書かれたコンテンツですが、米国や英国などのさまざまな地域を対象としています)。
- ウェブサイト全体が完全に複数の言語に翻訳されている場合。 たとえば、サイトのすべてのページに英語版とフランス語版があります。
- Webサイトを上記の構成のいずれかに拡張する場合(必要です)。
HTMLを使用してhreflang属性を実装する方法
hreflang属性を実装する最も一般的で最も簡単な方法は、HTMLステートメントを使用することです。
Webページの<head>セクションに次のコード行を追加するだけです。
<link rel = "alternate" hreflang = "xy" href = "https://domain.com/alternate-page" />
WordPress Webサイトの場合、header.phpファイルを更新することでhreflangタグを追加できます。 このファイルにアクセスするには、 [外観]> [テーマエディター]に移動するか、ファイル転送プロトコル(FTP)を使用します。
ファイルを開いたら、同じコード行を<head>セクションに追加できます。
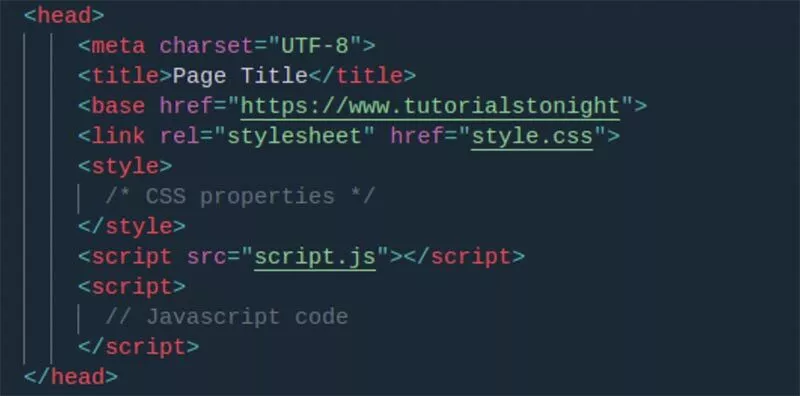
これを分解してみましょう:
- link rel =“ alternate” –これは、タグ内のリンクが、コードを追加したページの代替バージョンであることをGoogleに通知します。
- hreflang =“ xy” –これは、それが代替バージョンである理由をGoogleに通知します。つまり、コンテンツが別の言語であり、「x」がその言語で、「y」がターゲットロケールです。
- 「x」:2文字のISO639-1言語コード
- 「y」:特定のロケールのスピーカーをターゲットにする場合に使用する2文字のISO 3166-1 alpha-2リージョンコード。つまり、イギリス英語を話す人には「 engb 」、アメリカ英語を話す人には「en- us 」 。
- href =“ https://example.com/alternate-page” –これはGoogleにページの代替バージョンのURLを通知します。
次の2つのページを使用して例をもう一度見てみましょう。
- イギリス英語:https://www.domain.com/uk/hreflang/
- アメリカ英語:https://www.domain.com/us/hreflang/
これらのページの正しいhreflang実装には、各ページの<head>セクションに次のコードを追加することが含まれます。
<link rel = "alternate" hreflang = "en-gb" href = "https://www.domain.com/uk/hreflang/" /> <link rel = "alternate" hreflang = "en-us" href = "https://www.domain.com/us/hreflang/" />
この方法は上記の設定には十分簡単に思えますが、後でページをデンマーク語とフランス語に翻訳することを選択した場合はどうなりますか?
各ページに目を通し、コードを追加する必要があります。
<link rel = "alternate" hreflang = "da-dk" href = "https://www.domain.com/dk/hreflang/" /> <link rel = "alternate" hreflang = "fr-fr" href = "https://www.domain.com/fr/hreflang/" />
この例の最終結果は、それぞれが独自の言語を持つ4つの固有のページがあることです。 これらの4つのページのそれぞれには、それぞれの<head>セクションに4つのhreflang属性がすべてあります。
Insert HeadersやFootersなどのプラグインを使用して、このプロセスを簡単にすることができます。 ただし、これは高度な手順であり、経験豊富なWeb開発者とリスクを理解している人だけがこれを自分で実装することをお勧めします。 これを実装するためのサポートが必要な場合は、検索イニシアチブまでご連絡ください。
サイトマップを使用してhreflang属性を実装する方法
hreflang属性を実装する別の方法は、XMLサイトマップを使用することです。
この方法は少し注意が必要ですが、Eruditeのhreflangサイトマップツールを使用してhreflangサイトマップマークアップを自動的に生成することで、処理を高速化できるのは素晴らしいことです。
ただし、その方法と理由について詳しく知りたい場合は、以下をお読みください。
サイトマップを使用してコンテンツのさまざまなバリエーションを指定するには、次のことを行う必要があります。
- <loc>要素を追加して、単一のURLを指定します。
- 次に、コンテンツの代替バージョンごとに子<xhtml:link>属性を追加します。
これが2つのURLの例でどのように見えるかを見てみましょう。
- イギリス英語:https://www.domain.com/uk/hreflang/

- アメリカ英語:https://www.domain.com/us/hreflang/
<url> <loc> https://www.domain.com/uk/hreflang/ </ loc> <xhtml:link rel = "alternate" hreflang = "en-uk" href = "https://www.domain.com/uk/hreflang/" /> <xhtml:link rel = "alternate" hreflang = "en-us" href = "https://www.domain.com/us/hreflang//" /> </ url> <url> <loc> https://www.domain.com/us/hreflang/ </ loc> <xhtml:link rel = "alternate" hreflang = "en-us" href = "https://www.domain.com/us/hreflang//" /> <xhtml:link rel = "alternate" hreflang = "en-uk" href = "https://www.domain.com/uk/hreflang/" /> </ url>
これはHTMLだけを使用するよりも複雑に見えるかもしれませんが、同じコンテンツの複数のバージョンが異なる言語である大規模なWebサイトがある場合は、各URLに変更を実装する代わりに、XMLサイトマップを更新するだけで済みます。
詳細については、hreflangの実装に関する詳細なガイドをご覧ください。
Hreflangを実装する際のベストプラクティスと一般的な落とし穴
選択する方法に関係なく、hreflangを実装するときに避けるべきいくつかのベストプラクティスと一般的な落とし穴を次に示します。
- Hreflangは双方向です。つまり、ページA(イギリス英語)からページB(アメリカ英語)にhreflangを追加する場合は、ページB(アメリカ英語)からページA(イギリス英語)にhreflangを追加する必要があります。
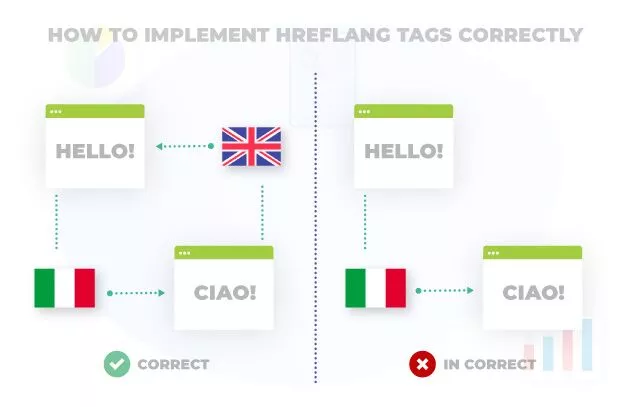
そうしないと、Googleはタグを無視します。
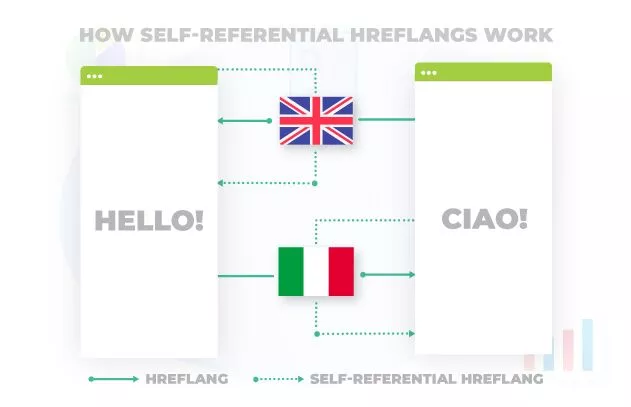
- 翻訳されたバリエーションに加えて、ページ自体を参照することを常に忘れないでください。 したがって、ページB(アメリカ英語)を指すページA(イギリス英語)に加えて、それ自体を参照するページA(イギリス英語)からのhreflangも追加する必要があります。
- 有効な言語とロケールを使用していることを確認してください
- domain.com/uk/hreflang/またはdomain.com/uk/hreflang/の代わりに、常に完全なURL、つまりhttps://www.domain.com/uk/hreflang/を使用してください
- 「x-default」タグ(ここでの「x」はプレースホルダーではないことに注意してください。これは使用する必要のある構文です)を使用して、適切な他の言語バリアントがない場合に表示するページを指定します。 これがどのように見えるかです:
<link rel = "alternate" hreflang = "x-default" href = "https://www.domain.com/uk/hreflang" />
この場合、ユーザーに表示されるデフォルトのページはhttps://www.domain.com/uk/hreflang/です。
hreflang属性を実装する方法の詳細については、Googleのこの詳細ガイドをご覧ください。
ブログコンテンツをサポートすることでトピックの関連性を確立する
あなたが釣り道具を販売しているウェブサイトを持っているなら、あなたはおそらくあなたが熟練した漁師であることをグーグル(そしてあなたの読者)に知ってもらいたいでしょう。
これを行う1つの方法は、ニッチ内で専門知識を紹介し、トピックの関連性を構築できるサポートブログコンテンツを作成することです。 また、プライマリページでターゲットとするコアキーワードほど競争力のないロングテールキーワードをターゲットにするという追加の利点もあります。

たとえば、特定の機器の使用方法に関するガイドを作成したり、釣り全般に関する究極のガイドを作成したりすることができます。
彼らのブログセクションは長い間触れられていなかったので、これは私たちのクライアントが見逃していたものです。
ロングテールキーワードのアイデアを見つける
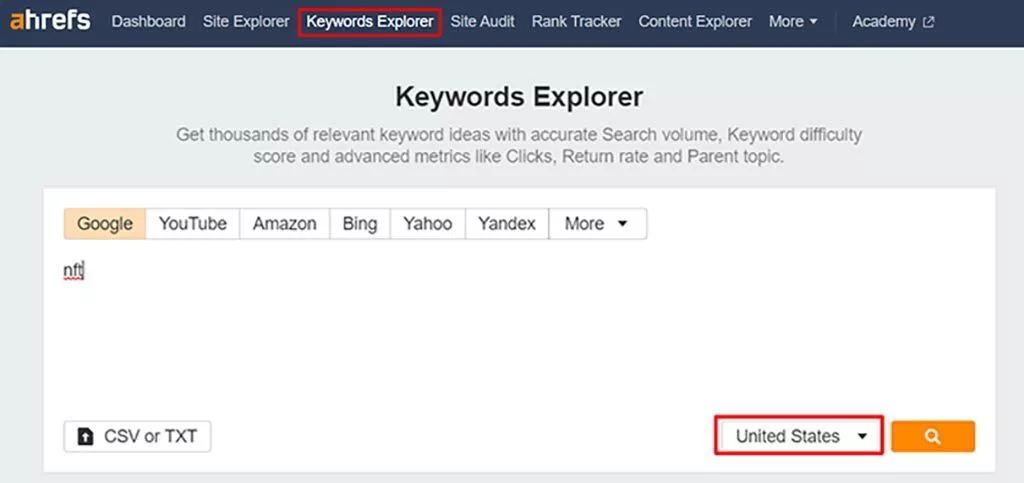
ロングテールキーワードを見つけるための優れた方法は、Ahrefsのキーワードエクスプローラーツールを使用することです。
- キーワードエクスプローラーにニッチに関連する幅広い検索用語を入力し、ターゲットの場所を選択して、虫眼鏡をクリックします。
- 下にスクロールして、さまざまなタイプのキーワードのアイデアを提供する次のオプションのいずれか(またはすべて)をクリックします。
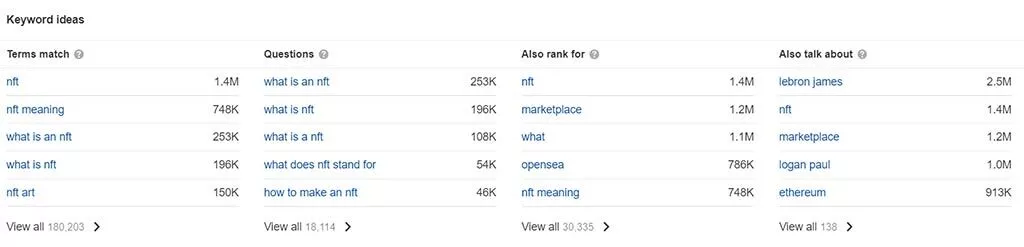
- 用語の一致–これにより、元のキーワード検索のすべての用語を含むすべての関連キーワードが表示されます。
- 質問–これらは質問として表現された検索クエリです–ブログ投稿内で回答したいロングテールキーワードに最適です。
- また、ランク付け–このレポートには、元のクエリの上位10ページのランキングページが他にどの検索用語にもランク付けされているかが表示されます。
- また、話してください–このレポートは、元のクエリの上位ページで頻繁に言及されている他のキーワードやフレーズを示します。
この例では、「質問」レポートを使用して、検索者がNFTについて尋ねている可能性のある潜在的なトピックを特定しました。
ランク付けが比較的簡単なロングテールキーワードを見つけるには、キーワードリストを次のようにフィルタリングします。
- 「用語/親トピック」フィルターを使用して、特定のフレーズや単語に基づいてキーワードのリストを絞り込みます。
- キーワードの難易度を最大に設定します。たとえば、リンクやトピックの権限がほとんどまたはまったくない新しいサイトがある場合は、KDを最大10に設定できます。より確立された信頼できるサイトの場合は、さらに高くすることができます。
- ロングテールキーワードはより具体的であるため、より多くの単語を含む傾向があるため、最小単語数を設定します
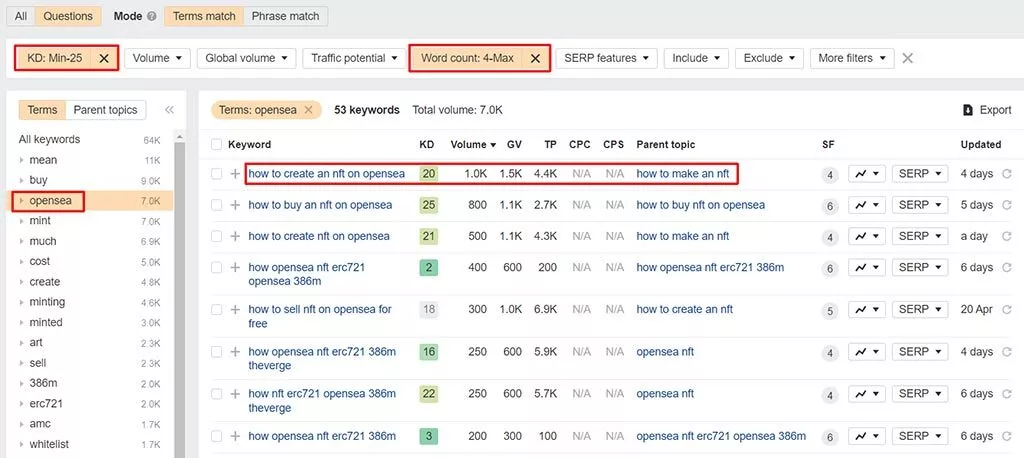
- ロングテールキーワードのセット(つまり、「外洋でnftを作成する方法」)を特定したら、用語をターゲットとするコンテンツの作成に進むことができます(詳細は以下を参照)。 たとえば、この質問に詳細に答えるためにブログ記事を書くことができます。
- よりロングテールのキーワードを見つけるには、サブトピックのステップ1から3に従います。つまり、キーワードエクスプローラーツールを使用して「openseanft」を検索します。
あなたのニッチに関連するこれらのロングテールキーワードで、あなたはグーグルの目の中であなたのウェブサイトの話題の権威を固めています。
ブログコンテンツの作成と最適化
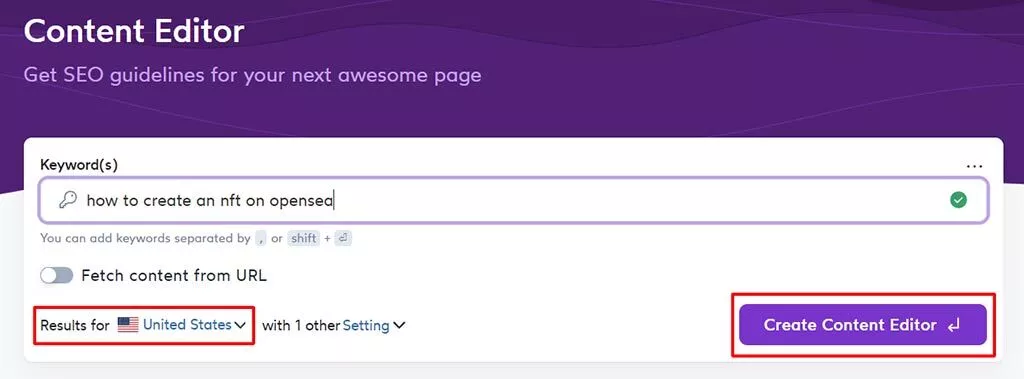
ブログコンテンツの作成に関しては、Surferのコンテンツエディターツールを使用することを強くお勧めします。
- Surferドラフトを作成する–検索バーにターゲットにするプライマリキーワードを入力し、ターゲットの場所(この場合は「米国」)を選択して、「コンテンツエディターの作成」をクリックします。
次に、次のようなページが表示されます。
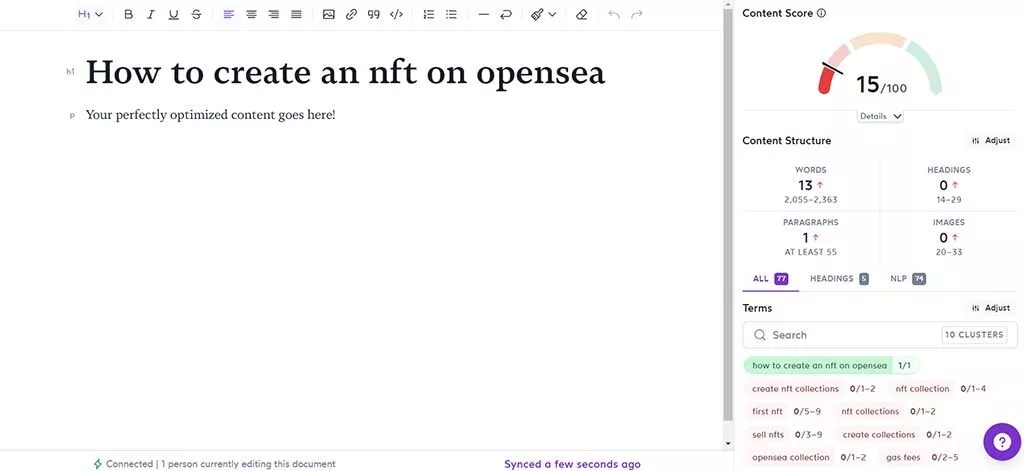
ツールが行ったことは、長さ、見出しの数、段落の数、画像の数、そして最も重要なことに、キーワードのトップランクのページのコンテンツ内で使用される一般的なフレーズとキーワードを分析することです。
- 左側にテキストエディタが表示されます。ここにコンテンツを書き込むことができます。
- 右側には、SurferSEOの分析結果が表示されます。 コンテンツの長さや、含める見出しや画像の数に関する提案を提供します。 また、選択したキーワードの上位の競合他社に基づいて、メインコンテンツ内に特定のフレーズまたはキーワードを含める必要がある回数に関するガイドも提供されます。
- 競合他社をチェックする–記事を書き始める前に、上位の競合ページのコンテンツを見て、記事の見出しの構造とコンテンツプランを確認する必要があります。 これを行うには、「BRIEF」をクリックしてから、競合他社のリストを開きます。
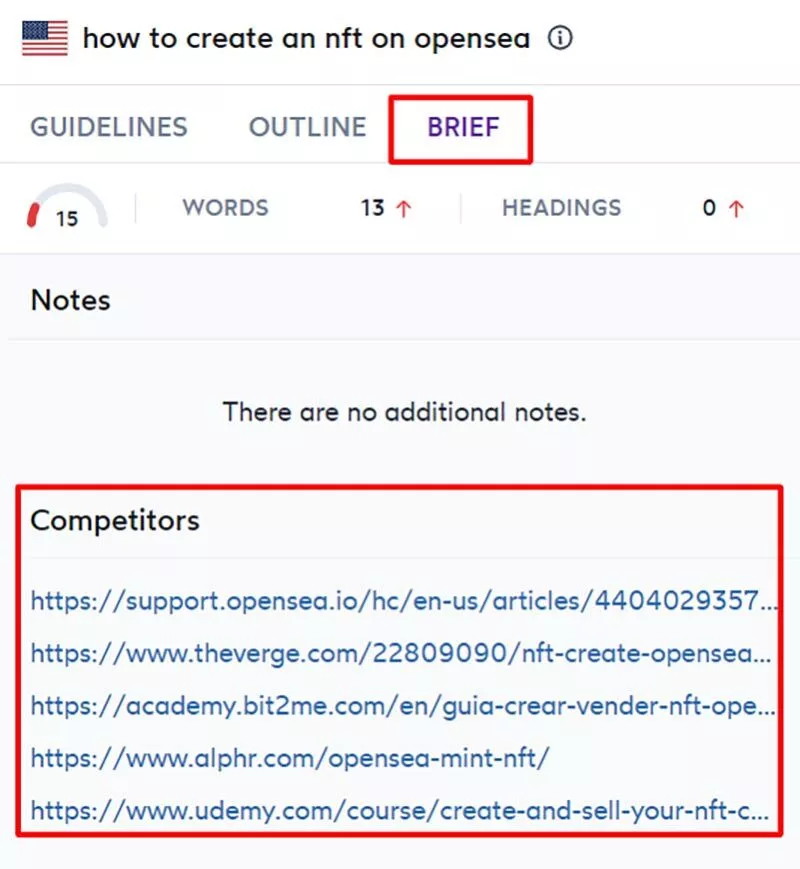
以下に細心の注意を払ってください:
- 彼らがカバーするトピック/見出し–それらにはFAQが含まれていますか?
- 追加のコンテンツ–画像、ビデオ、またはその他の形式のリッチコンテンツが含まれていますか?
- 記事のトーンとスタイル–コンテンツはリストまたはテキストのブロックに分割されていますか?
- スコアに焦点を当てないでください–コンテンツを追加すると、ページが競合他社にどのように対抗するかに応じて、コンテンツスコアが増加(または減少)します。 100の満点に達する必要はないことに注意してください(80を超えるものはすべて良いと見なされます)。主な目標は、そのような記事に期待される主なトピックを確実にカバーし、内容があなたの聴衆を魅了する方法で書かれています。
- 内部リンクを忘れないでください–ブログ投稿を書くときは、内部リンク戦略について考えてください。 これは、ブログ投稿を通じてWebサイトにアクセスする訪問者を、最も重要なランディングページに誘導するための強力な方法です。
ページを相互リンクする方法の詳細については、このビデオをチェックしてください。
重要なページへのリンクを作成する
クライアントが最初に参加したときにクライアントのバックリンクプロファイルについて気づいたことの1つは、重要なサービスページの多くに、それらを指すバックリンクがほとんどまたはまったくないため、それらのページのランク付けが妨げられていたことです。
上記に基づいてリンク構築戦略を形成する方法を説明します。
リンクレポートによるAhrefsのベストを使用したリンク構築の機会の特定
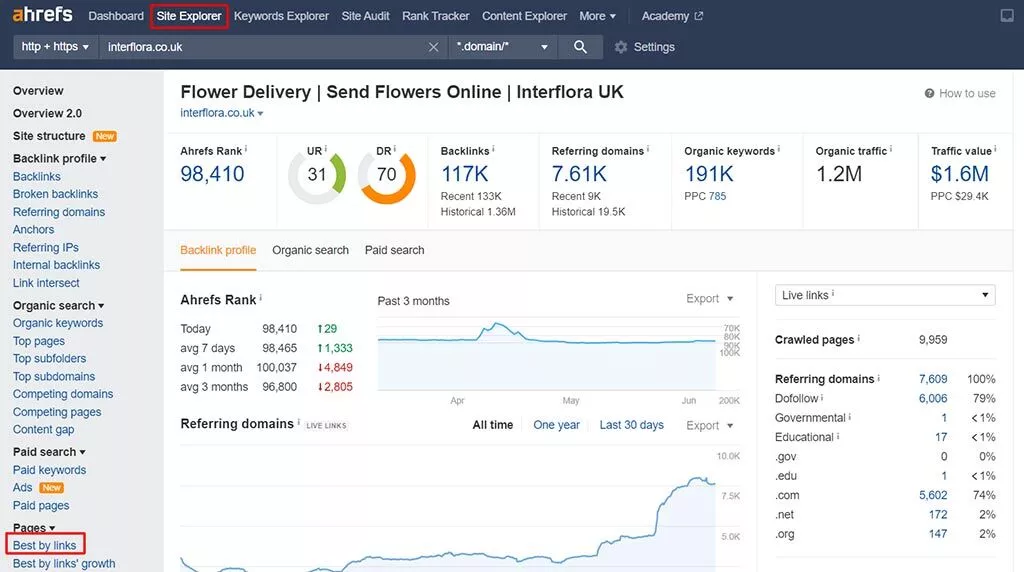
AhrefsのBestbyLinksレポートは、Webサイトのどのページに内部リンクと外部リンクが最も多いか最も少ないかを特定するのに最適です。
- ドメインをサイトエクスプローラーに入力します
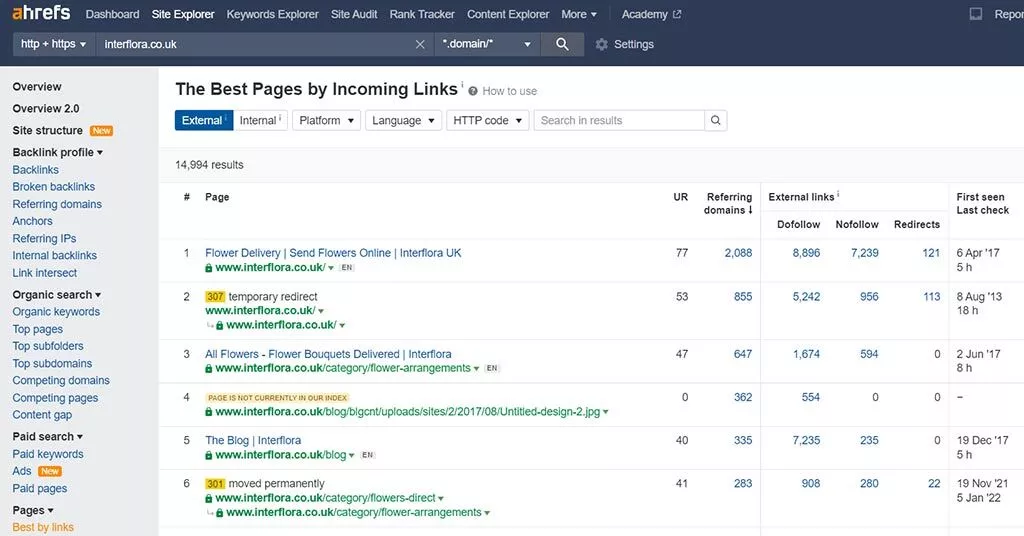
- 左側のサイドバーで、 [ページ]>[リンクによるベスト]を見つけます
- 次に、「外部」が選択されていることと、結果をフィルタリングして、ライブのページのみが表示されるようにします。つまり、リダイレクトされないか、404が見つかりませんを返します。
また、参照ドメインに基づいて結果を昇順で並べ替えます。
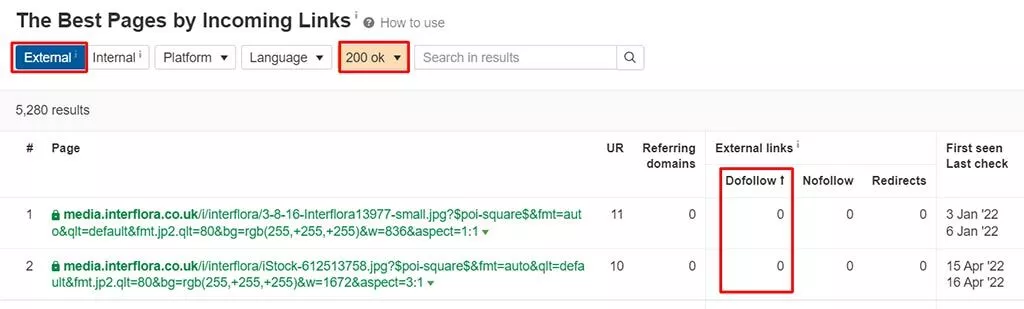
- 検索機能を使用して、バックリンクが不足している可能性のある特定の種類のページを特定することにより、結果をさらにフィルタリングします。
これらの結果を確認するときは、Webサイトにとって重要なページを特定してください。 これらは、メインメニューに表示される可能性が最も高いページです。つまり、eコマースWebサイトのカテゴリページまたはSaaSWebサイトのサービスページです。
重要なキーワードをターゲットにしていて、ウェブサイトの収益やコンバージョンを増やすために重要であることがわかっているページを選択してください。 これらは、主にリンクを作成するページです。
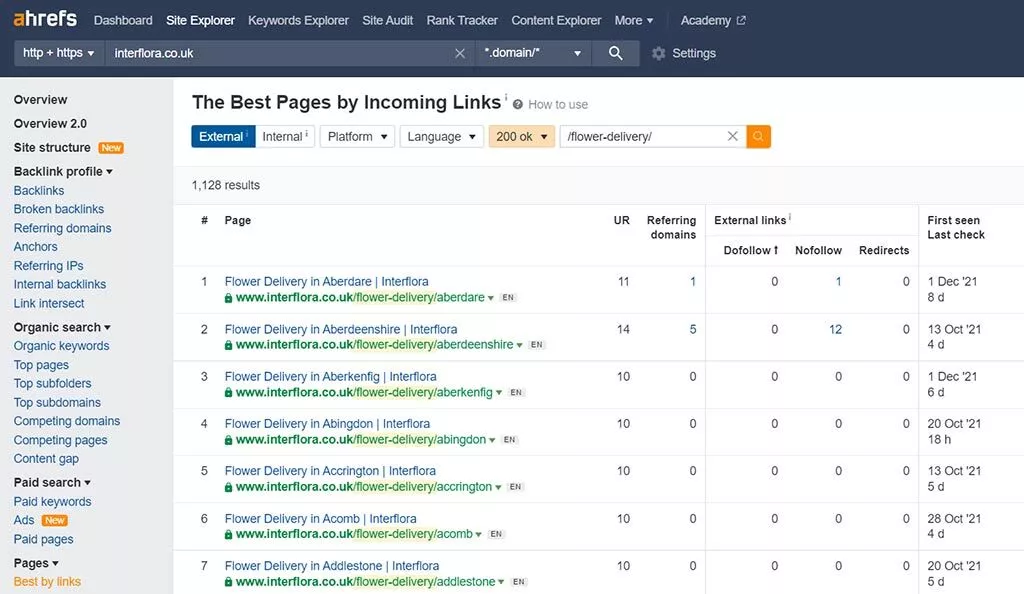
これで、参照ドメインの数が最も少ないWebサイトの重要なページのリストができました。 これらは上記の「お金のページ」(つまり、メインメニューのカテゴリ/サービスページ)である可能性がありますが、大量のキーワードをランク付けする能力の観点から重要だと思われるブログ投稿を含めることもできます。
これらのページを特定したら、次のステップは、ページの権限とランク付け性を高めるために、それらへの実際のリンクの構築を開始することです。
使用できる効果的な戦術は、ブロガーへの働きかけです。主な手順は次のとおりです。
- あなたの見込み客を見つけてください–あなたがあなたのニッチの中からバックリンクを持っていない潜在的なウェブサイトのリストを集めてください。 これを行うための優れた方法は、AhrefsのLink Intersectツールを使用することです。このツールを使用すると、サイトへの参照ドメインを競合他社と比較できます。
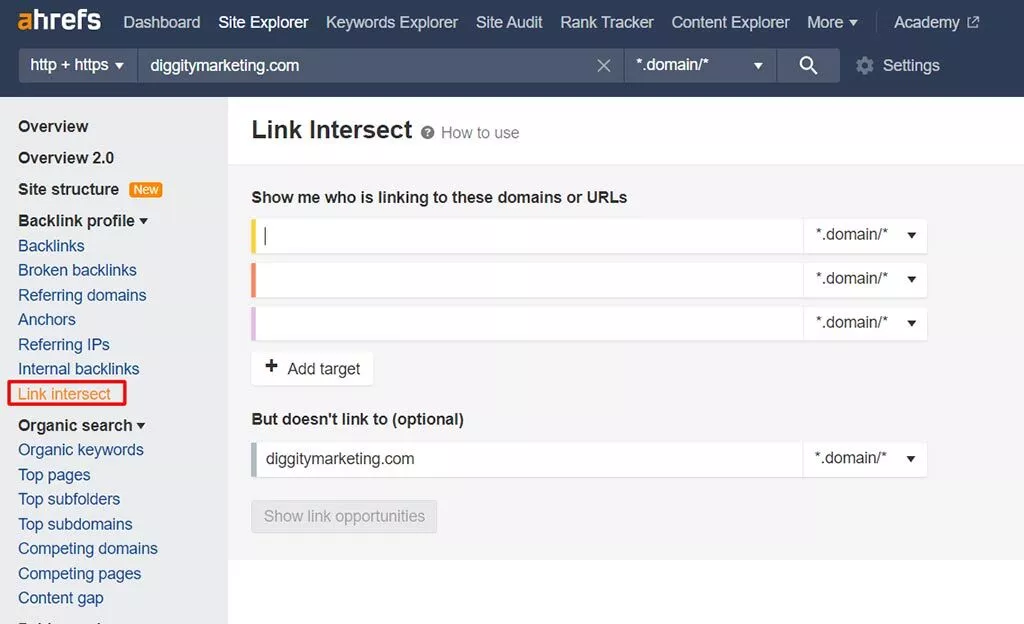
競合他社のリンクプロファイルを確認することから始めるのが最適です。競合他社は、ニッチ内のトピックに関連するWebサイトからのリンクをすでに持っているからです。
- 連絡先の詳細を見つける–候補リストを作成したら、サイトの連絡先情報を見つけます。 これは、そこで働く人への電子メールアドレスまたは一般的な連絡フォームである可能性があります。 メールアドレスを見つけるのに最適な方法は、Hunter.ioなどのツールを使用することです。GoogleChrome拡張機能をダウンロードすると、ボタンをクリックするだけでこの情報を取得できます。
- 売り込みを作成する–売り込みは、リンクを取得する可能性を高めたり壊したりする可能性があるため、アウトリーチプロセスの最も重要な部分です。 売り込み先のWebサイトに関する関連情報を追加して、売り込みがパーソナライズされていることを確認します。 これは書き込みに時間がかかる場合がありますが、結果として応答率が高くなる可能性があります。
ピッチを短く簡潔にすることを忘れないでください。
- あなたが誰であるかを説明する
- なぜ彼らに連絡しているのか
- あなたが提供しなければならないもの
ピッチに使用できるテンプレートは次のとおりです。
こんにちは _____________、
私の名前は[あなたの名前]であり、私は[あなたがしていること、あなたが誰であるか]です。
私はあなたの記事で[パーソナライズされた文]を本当に楽しんだ[彼らのページのタイトル、それにリンクされている
[あなたの記事のタイトル/トピック]に関する自分の記事を調査しているときに出くわしたURL]。
しかし、あなたがこの古いページ[古い記事のURL]にリンクしていることに気づきました。
だから私は私のより最新の記事があなたのページで言及する価値があるかどうか尋ねたかった:[あなたの記事へのリンクを追加する]。
いずれにせよ、素晴らしい仕事を続けてください!
あなたからのお便りを楽しみにしています。
よろしくお願いします、
[名前]
- 送信、監視、繰り返し–提案を送信したら、進捗状況を監視し、件名と電子メールのコピーを試して、どれが最良の結果をもたらすかを見つけることが重要です。 これにより、プロセスを合理化し、スケーリングすることもできます。
ブロガーのアウトリーチを実施する方法について詳しくは、こちらをご覧ください。
結果
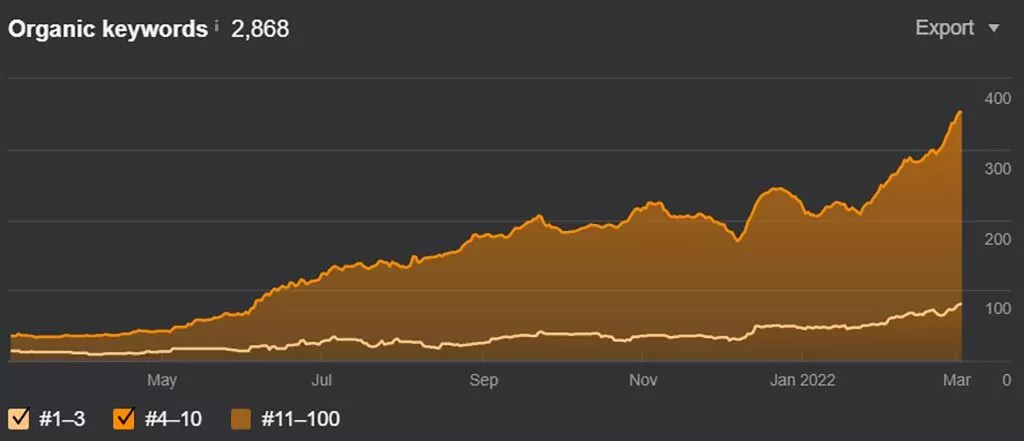
上記の戦略を6か月強で実行することで達成したことは次のとおりです。
前年比で比較すると、オーガニックトラフィックは96%増加しました。

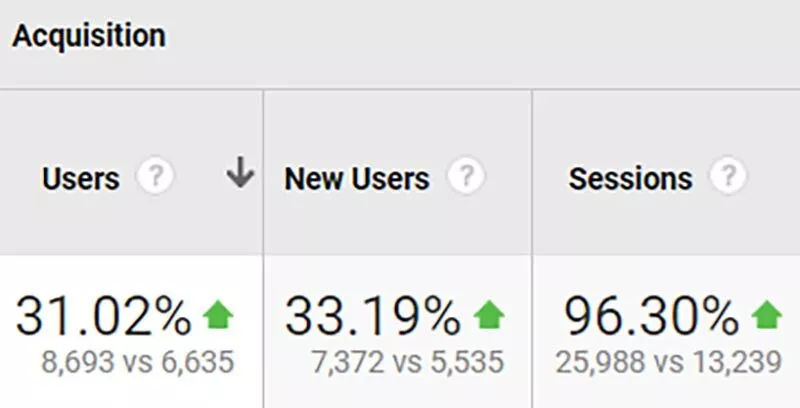
以下のグラフはAhrefsから取得したもので、Googleの上位10位以内でのサイトのキーワードの可視性を示しています。
グーグルのトップ10の位置でサイトがランク付けしているキーワードの数は、1年後に259キーワードから357キーワードに増加しました– 37.8%の増加。
結論
技術的に健全な基盤がなければ、あなたが書いたコンテンツとあなたが構築したリンクはどこにも効果的ではありません。 ランク付けしたいページをGoogleができるだけ簡単に見つけてインデックスに登録できるようにする必要があります。これが、技術的なSEOのすべてです。
このケーススタディでは、次の方法を学びました。
- インデックスから不要なページを特定して削除することにより、クロール予算を管理します
- XMLサイトマップを作成して公開し、Googleに送信します
- さまざまな言語/ターゲットの場所でコンテンツを提供するWebサイトのhreflang属性を正しく実装します。
- 以前はリンク権限が不足していたページへの被リンクを作成します。
上記の戦略を実装すると、適切なページがGoogleのインデックスに登録され、検索結果内での可視性を最大化できるようになります。 これを行うには、特に数千ページの大規模なWebサイトがある場合は、かなり時間がかかる可能性があります。
SEOのすべてのニーズに対応するチームをお探しの場合は、検索イニシアチブの私のチームにご連絡ください。

による記事
マットディギティ
Mattは、Diggity Marketing、LeadSpring、The Search Initiative、The Affiliate Lab、Chiang MaiSEOConferenceの創設者です。 彼は実際にSEOも行っています。