
Uzmana sorun: Aramada yapay zeka ve makine öğreniminin gizemini ortadan kaldırma
Yayınlanan: 2021-08-27AI ve Makine Öğrenimi dünyasının birçok katmanı vardır ve öğrenmesi oldukça karmaşık olabilir. Pek çok terim var ve manzara hakkında temel bir anlayışa sahip değilseniz, oldukça kafa karıştırıcı olabilir. Bu yazıda, uzman Eric Enge, temel kavramları tanıtacak ve sizin için bunların gizemini çözmeye çalışacak. Bu aynı zamanda AI ortamının daha ilginç yönlerinin çoğunu kapsayan dört bölümlük bir makale serisinin ilkidir.
Bu serideki diğer üç makale şöyle olacak:
- Doğal Dil İşlemeye Giriş
- GPT-3: Nedir ve Nasıl Kullanılır?
- Mevcut Google AI Algoritmaları: Rankbrain, BERT, MUM ve SMITH
AI hakkında temel arka plan
O kadar çok farklı terim var ki, hepsinin ne anlama geldiğini anlamak zor olabilir. O halde bazı tanımlarla başlayalım:
- Yapay Zeka – Bu, insanlarda ve diğer hayvanlarda gördüğümüz doğal zekanın aksine, makinelerin sahip olduğu/gösterdiği zekayı ifade eder.
- Yapay Genel Zeka (AGI) – Bu, makinelerin bir insanın yapabileceği herhangi bir görevi yerine getirebildiği bir zeka seviyesidir. Henüz mevcut değil, ancak çoğu onu yaratmaya çalışıyor.
- Makine Öğrenimi – Bu, belirli görevlerin nasıl gerçekleştirileceğini öğrenmek için verileri ve yinelemeli testleri kullanan bir AI alt kümesidir.
- Derin Öğrenme – Bu, daha karmaşık makine öğrenimi sorunlarını çözmek için oldukça karmaşık sinir ağlarından yararlanan bir makine öğrenimi alt kümesidir.
- Doğal Dil İşleme (NLP) – Bu, özellikle dili işlemeye ve anlamaya yönelik AI odaklı bir alandır.
- Sinir Ağları – Bu, nöronların beyindeki etkileşim şeklini modellemeye çalışan daha popüler makine öğrenme algoritmalarından biridir.
Bunların hepsi birbiriyle yakından ilişkilidir ve hepsinin nasıl bir araya geldiğini görmek yardımcı olur:

Özetle, Yapay zeka tüm bu kavramları kapsar, derin öğrenme makine öğreniminin bir alt kümesidir ve doğal dil işleme, dili daha iyi anlamak için çok çeşitli AI algoritmaları kullanır.
Bir sinir ağının nasıl çalıştığına dair örnek çizim
Birçok farklı türde makine öğrenme algoritması vardır. Bunların en bilinenleri sinir ağı algoritmalarıdır ve size biraz bağlam sağlamak için bundan sonra bahsedeceğim.
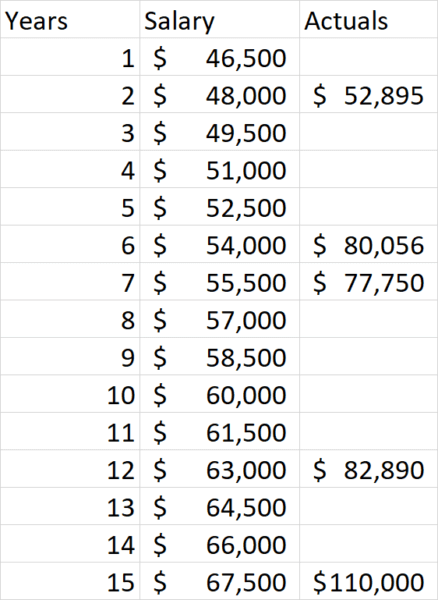
Bir çalışanın maaşını belirleme sorununu düşünün. Örneğin, 10 yıllık deneyime sahip birine ne ödüyoruz? Bu soruyu yanıtlamak için, diğerlerinin ne kadar maaş aldığı ve yıllara dayanan deneyimleri hakkında bazı veriler toplayabiliriz ve bu şöyle görünebilir:

Bunun gibi verilerle, bir çizgi grafiği oluşturarak bu çalışanın ne kadar ödeme yapması gerektiğini kolayca hesaplayabiliriz:

Bu kişi için, yılda 90.000 doların biraz üzerinde bir maaş önermektedir. Ancak, işin niteliğini ve çalışanın performans düzeyini de dikkate almamız gerektiğinden, bunun gerçekten yeterli bir görüş olmadığını hepimiz hemen anlayabiliriz. Bu iki değişkeni tanıtmak bizi daha çok şuna benzer bir veri grafiğine götürecektir:

Çözülmesi çok daha zor ama makine öğreniminin nispeten kolayca yapabileceği bir problem. Ancak, bulunduğunuz yerin de büyük bir etkisi olduğu için, maaşları etkileyen faktörlere karmaşıklık eklemekle gerçekten işimiz bitmedi. Örneğin, teknolojideki San Francisco Körfez Bölgesi işleri, büyük ölçüde yaşam maliyetindeki büyük farklılıklar nedeniyle, ülkenin diğer birçok yerindeki aynı işlerden önemli ölçüde daha fazla ödüyor.

Sinir ağlarının kullanacağı temel yaklaşım, değişkenleri (iş, yılların deneyimi, performans düzeyi) kullanarak doğru denklemi tahmin etmek ve bu denklemi kullanarak potansiyel maaşı hesaplamak ve gerçek dünya verilerimizle ne kadar iyi eşleştiğini görmektir. Bu süreç, sinir ağlarının nasıl ayarlandığıdır ve “gradyan inişi” olarak adlandırılır. Bunu açıklamanın basit İngilizce yolu, ona “ardışık yaklaşım” demek olacaktır.
Orijinal maaş verileri, bir sinir ağının "eğitim verileri" olarak kullanacağı şeydir, böylece gerçek dünya deneyimiyle eşleşen bir algoritma oluşturduğunda bunu bilebilir. Sadece yılların deneyimi ve maaş verileriyle orijinal veri setimizle başlayarak basit bir örnek üzerinden gidelim.

Örneğimizi daha basit tutmak için, bunun için kullanacağımız sinir ağının 0 yıllık tecrübenin 45.000$ maaşa eşit olduğunu anladığını ve denklemin temel formunun şu şekilde olması gerektiğini varsayalım: Maaş = Hizmet Yılı * X + 45.000$ . Kullanılacak doğru denklemi bulmak için X'in değerini bulmamız gerekiyor. İlk adım olarak, sinir ağı X'in değerinin 1.500 dolar olduğunu tahmin edebilir. Uygulamada, bu algoritmalar bu ilk tahminleri rastgele yapar, ancak bu şimdilik yeterli olacaktır. 1500 dolarlık bir değer denediğimizde elde ettiğimiz şey:

Ortaya çıkan verilerden de gördüğümüz gibi hesaplanan değerler çok düşük. Sinir ağları, hesaplanan değerleri gerçek değerlerle karşılaştırmak ve daha sonra doğru cevabın ne olduğuna dair ikinci bir tahmin denemek için kullanılabilecek geri bildirim olarak sağlamak için tasarlanmıştır. Örneğimiz için, X için doğru değer olarak bir sonraki tahminimiz 3.000$ olsun. Bu sefer elde ettiğimiz sonuç şudur:

Gördüğümüz gibi sonuçlarımız iyileşti, ki bu iyi! Ancak yine de doğru değerlere yeterince yakın olmadığımız için tekrar tahmin etmemiz gerekiyor. Bu sefer 6000$'lık bir tahminde bulunmayı deneyelim:

İlginç bir şekilde, şimdi hata payımızın biraz arttığını görüyoruz, ancak artık çok yüksekteyiz! Belki de denklemlerimizi biraz daha aşağı ayarlamamız gerekiyor. 4500$ deneyelim:

Şimdi görüyoruz ki oldukça yakınız! Sonuçları ne kadar iyileştirebileceğimizi görmek için ek değerler denemeye devam edebiliriz. Bu, makine öğreniminde algoritmamızın ne kadar hassas olmasını istediğimiz ve yinelemeyi ne zaman durduracağımızla ilgili başka bir önemli değeri devreye sokar. Ancak buradaki örneğimiz açısından yeterince yakınız ve umarım tüm bunların nasıl çalıştığına dair bir fikriniz vardır.
Örnek makine öğrenimi alıştırmamız, yalnızca bu biçimde bir denklem türetmemiz gerektiğinden, oluşturmamız için son derece basit bir algoritmaya sahipti: Maaş = Hizmet Yılı * X + 45.000 ABD Doları (diğer adıyla y = mx + b). Ancak, kullanıcı maaşlarını etkileyen tüm faktörleri dikkate alan gerçek bir maaş algoritması hesaplamaya çalışıyor olsaydık, şunlara ihtiyacımız olurdu:
- eğitim verimiz olarak kullanmak için çok daha büyük bir veri seti
- çok daha karmaşık bir algoritma oluşturmak için
Makine öğrenimi modellerinin nasıl hızla son derece karmaşık hale gelebileceğini görebilirsiniz. Doğal dil işleme ölçeğinde bir şeyle uğraşırken karmaşıklığı hayal edin!
Diğer temel makine öğrenimi algoritmaları türleri
Yukarıda paylaşılan makine öğrenimi örneği, "denetimli makine öğrenimi" dediğimiz şeyin bir örneğidir. Biz buna denetimli diyoruz çünkü hedef çıktı değerlerini içeren bir eğitim veri seti sağladık ve algoritma bunu aynı (veya aynıya yakın) çıktı sonuçlarını üretecek bir denklem üretmek için kullanabildi. Ayrıca "denetimsiz makine öğrenimi" gerçekleştiren bir makine öğrenimi algoritmaları sınıfı da vardır.
Bu algoritma sınıfıyla, yine de bir girdi veri seti sağlıyoruz, ancak çıktı verilerinin örneklerini sağlamıyoruz. Makine öğrenimi algoritmalarının verileri gözden geçirmesi ve veriler içinde kendi başlarına anlam bulması gerekir. Bu kulağa ürkütücü bir şekilde insan zekası gibi gelebilir ama hayır, henüz tam olarak orada değiliz. Dünyadaki bu tür makine öğrenmesine iki örnekle açıklayalım.
Denetimsiz makine öğrenimine bir örnek Google Haberler'dir. Google, yeni etkinlikler tarafından yönlendiriliyor gibi görünen yeni arama sorgularından en fazla trafiği alan makaleleri keşfedecek sistemlere sahiptir. Ancak tüm makalelerin aynı konuda olduğunu nereden biliyor? Google Haberler'de normal aramada yaptıkları gibi geleneksel alaka düzeyi eşleştirmesi yapabilse de bu, içerik parçaları arasındaki benzerliği belirlemelerine yardımcı olan algoritmalar tarafından yapılır.

Yukarıdaki örnek resimde gösterildiği gibi, Google, 10 Ağustos 2021'de altyapı faturasının geçmesiyle ilgili çok sayıda makaleyi başarılı bir şekilde gruplandırmıştır. Tahmin edebileceğiniz gibi, olayı açıklamaya odaklanan her makale ve faturanın kendisi büyük olasılıkla önemli benzerliklere sahiptir. içerik. Bu benzerlikleri tanımak ve makaleleri tanımlamak, aynı zamanda denetimsiz makine öğreniminin bir örneğidir.
Bir başka ilginç makine öğrenimi sınıfı, "tavsiye edici sistemler" dediğimiz şeydir. Bunu gerçek dünyada Amazon gibi e-ticaret sitelerinde veya Netflix gibi film sitelerinde görüyoruz. Amazon'da, bir ürün sayfasındaki listelemenin altında "Birlikte Sıkça Satın Alınanlar" ifadesini görebiliriz. Diğer sitelerde bu, "Bunu satın alanlar bunu da aldı" şeklinde etiketlenebilir.
Netflix gibi film siteleri size film önerilerinde bulunmak için benzer sistemler kullanır. Bunlar, belirtilen tercihlere, derecelendirdiğiniz filmlere veya film seçim geçmişinize dayalı olabilir. Buna popüler bir yaklaşım, izlediğiniz ve yüksek puan aldığınız filmleri, diğer kullanıcılar tarafından benzer şekilde izlenen ve puanlanan filmlerle karşılaştırmaktır.
Örneğin, 4 aksiyon filmine oldukça yüksek puan verdiyseniz ve farklı bir kullanıcı (ki buna John diyeceğiz) aksiyon filmlerine de yüksek puan verdiyse, sistem size John'un izlediği ancak sizin izlemediğiniz başka filmleri önerebilir. . Bu genel yaklaşım, "işbirlikçi filtreleme" olarak adlandırılan şeydir ve bir tavsiye sistemi oluşturmaya yönelik birkaç yaklaşımdan biridir.
Not: Bu makaleyi incelediği ve rehberlik sağladığı için Chris Penn'e teşekkür ederiz.
Bu makalede ifade edilen görüşler konuk yazara aittir ve mutlaka Search Engine Land değildir. Personel yazarları burada listelenir.