
Fragen Sie den Experten: Entmystifizierung von KI und maschinellem Lernen in der Suche
Veröffentlicht: 2021-08-27Die Welt der KI und des maschinellen Lernens ist vielschichtig und kann sehr komplex zu lernen sein. Es gibt viele Begriffe, und wenn Sie nicht über ein grundlegendes Verständnis der Landschaft verfügen, kann dies ziemlich verwirrend sein. In diesem Artikel stellt Experte Eric Enge die grundlegenden Konzepte vor und versucht, alles für Sie zu entmystifizieren. Dies ist auch der erste einer vierteiligen Artikelserie, die viele der interessanteren Aspekte der KI-Landschaft abdeckt.
Die anderen drei Artikel in dieser Serie werden sein:
- Einführung in die Verarbeitung natürlicher Sprache
- GPT-3: Was es ist und wie man es nutzt
- Aktuelle KI-Algorithmen von Google: Rankbrain, BERT, MUM und SMITH
Grundlegender Hintergrund zu KI
Es gibt so viele verschiedene Begriffe, dass es schwierig sein kann, ihre Bedeutung zu verstehen. Beginnen wir also mit einigen Definitionen:
- Künstliche Intelligenz – Dies bezieht sich auf Intelligenz, die Maschinen besitzen/zeigen, im Gegensatz zu natürlicher Intelligenz, die wir bei Menschen und anderen Tieren sehen.
- Künstliche Allgemeine Intelligenz (AGI) – Dies ist eine Intelligenzebene, bei der Maschinen in der Lage sind, jede Aufgabe zu bewältigen, die ein Mensch erledigen kann. Es existiert noch nicht, aber viele bemühen sich, es zu schaffen.
- Maschinelles Lernen – Dies ist eine Teilmenge der KI, die Daten und iterative Tests verwendet, um zu lernen, wie bestimmte Aufgaben ausgeführt werden.
- Deep Learning – Dies ist eine Teilmenge des maschinellen Lernens, die hochkomplexe neuronale Netze nutzt, um komplexere Probleme des maschinellen Lernens zu lösen.
- Natural Language Processing (NLP) – Dies ist das Gebiet der KI, das sich speziell auf die Verarbeitung und das Verständnis von Sprache konzentriert.
- Neuronale Netzwerke – Dies ist eine der beliebtesten Arten von Algorithmen für maschinelles Lernen, die versuchen, die Art und Weise zu modellieren, wie Neuronen im Gehirn interagieren.
Diese sind alle eng miteinander verbunden und es ist hilfreich zu sehen, wie sie alle zusammenpassen:

Zusammenfassend umfasst künstliche Intelligenz all diese Konzepte, Deep Learning ist eine Teilmenge des maschinellen Lernens, und die Verarbeitung natürlicher Sprache verwendet eine breite Palette von KI-Algorithmen, um Sprache besser zu verstehen.
Beispieldarstellung der Funktionsweise eines neuronalen Netzes
Es gibt viele verschiedene Arten von maschinellen Lernalgorithmen. Die bekanntesten davon sind neuronale Netzwerkalgorithmen, und um Ihnen einen kleinen Kontext zu geben, werde ich darauf als nächstes eingehen.
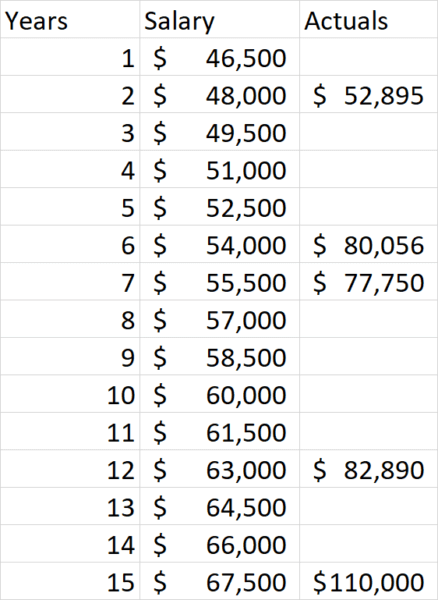
Betrachten Sie das Problem der Bestimmung des Gehalts für einen Mitarbeiter. Was zahlen wir zum Beispiel jemandem mit 10 Jahren Erfahrung? Um diese Frage zu beantworten, können wir einige Daten darüber sammeln, was andere bezahlt werden, und ihre jahrelange Erfahrung, und das könnte so aussehen:

Mit Daten wie diesen können wir leicht berechnen, was dieser bestimmte Mitarbeiter verdienen sollte, indem wir ein Liniendiagramm erstellen:

Für diese bestimmte Person wird ein Gehalt von etwas mehr als 90.000 US-Dollar pro Jahr vorgeschlagen. Wir alle erkennen jedoch schnell, dass dies nicht wirklich ausreicht, da wir auch die Art der Tätigkeit und das Leistungsniveau des Mitarbeiters berücksichtigen müssen. Die Einführung dieser beiden Variablen führt uns zu einem Datendiagramm, das eher diesem ähnelt:

Es ist ein viel schwierigeres Problem zu lösen, aber eines, das maschinelles Lernen relativ einfach lösen kann. Wir sind jedoch noch nicht damit fertig, die Faktoren, die sich auf die Gehälter auswirken, noch komplexer zu machen, da auch der Standort einen großen Einfluss hat. Zum Beispiel werden Arbeitsplätze in der San Francisco Bay Area im Technologiebereich deutlich besser bezahlt als die gleichen Jobs in vielen anderen Teilen des Landes, was zum großen Teil auf die großen Unterschiede bei den Lebenshaltungskosten zurückzuführen ist.

Der grundlegende Ansatz, den neuronale Netze verwenden würden, besteht darin, die richtige Gleichung anhand der Variablen (Job, Erfahrung in Jahren, Leistungsniveau) zu erraten und das potenzielle Gehalt anhand dieser Gleichung zu berechnen und zu sehen, wie gut es mit unseren realen Daten übereinstimmt. Durch diesen Prozess werden neuronale Netze abgestimmt und er wird als „Gradientenabstieg“ bezeichnet. Die einfache englische Art, dies zu erklären, wäre, es „sukzessive Approximation“ zu nennen.
Die ursprünglichen Gehaltsdaten würde ein neuronales Netzwerk als „Trainingsdaten“ verwenden, damit es wissen kann, wann es einen Algorithmus entwickelt hat, der mit der realen Erfahrung übereinstimmt. Lassen Sie uns ein einfaches Beispiel durchgehen, beginnend mit unserem ursprünglichen Datensatz mit nur der jahrelangen Erfahrung und den Gehaltsdaten.

Um unser Beispiel einfacher zu halten, nehmen wir an, dass das neuronale Netzwerk, das wir dafür verwenden, versteht, dass 0 Jahre Erfahrung einem Gehalt von 45.000 $ entsprechen und dass die Grundform der Gleichung lauten sollte: Gehalt = Dienstjahre * X + 45.000 $ . Wir müssen den Wert von X berechnen, um die richtige Gleichung zu finden. Als ersten Schritt könnte das neuronale Netzwerk vermuten, dass der Wert von X 1.500 $ beträgt. In der Praxis machen diese Algorithmen diese anfänglichen Vermutungen zufällig, aber das reicht für den Moment. Folgendes erhalten wir, wenn wir einen Wert von 1500 $ versuchen:

Wie wir aus den resultierenden Daten sehen können, sind die berechneten Werte zu niedrig. Neuronale Netze sind so konzipiert, dass sie die berechneten Werte mit den realen Werten vergleichen und dies als Feedback liefern, das dann verwendet werden kann, um eine zweite Vermutung zu versuchen, was die richtige Antwort ist. Lassen Sie uns zu unserer Veranschaulichung 3.000 $ als den richtigen Wert für X annehmen. Diesmal erhalten wir Folgendes:

Wie wir sehen können, haben sich unsere Ergebnisse verbessert, was gut ist! Wir müssen jedoch noch einmal raten, weil wir nicht nah genug an den richtigen Werten sind. Versuchen wir es also diesmal mit einer Schätzung von 6000 US-Dollar:

Interessanterweise sehen wir jetzt, dass unsere Fehlerspanne leicht gestiegen ist, aber wir sind jetzt zu hoch! Vielleicht müssen wir unsere Gleichungen wieder etwas nach unten korrigieren. Versuchen wir es mit 4500 $:

Jetzt sehen wir, dass wir ganz nah dran sind! Wir können weitere Werte ausprobieren, um zu sehen, wie viel mehr wir die Ergebnisse verbessern können. Dies bringt einen weiteren Schlüsselwert beim maschinellen Lernen ins Spiel, nämlich wie genau unser Algorithmus sein soll und wann wir mit der Iteration aufhören. Aber für die Zwecke unseres Beispiels hier sind wir nah genug dran und hoffentlich haben Sie eine Vorstellung davon, wie das alles funktioniert.
Unsere Beispielübung für maschinelles Lernen hatte einen extrem einfachen Algorithmus zum Erstellen, da wir nur eine Gleichung in dieser Form herleiten mussten: Gehalt = Dienstjahre * X + 45.000 $ (auch bekannt als y = mx + b). Wenn wir jedoch versuchen würden, einen echten Gehaltsalgorithmus zu berechnen, der alle Faktoren berücksichtigt, die sich auf die Benutzergehälter auswirken, bräuchten wir:
- ein viel größerer Datensatz, der als unsere Trainingsdaten verwendet werden kann
- um einen viel komplexeren Algorithmus zu bauen
Sie sehen, wie Machine-Learning-Modelle schnell sehr komplex werden können. Stellen Sie sich die Komplexität vor, wenn wir es mit etwas in der Größenordnung der Verarbeitung natürlicher Sprache zu tun haben!
Andere Arten von grundlegenden Algorithmen für maschinelles Lernen
Das oben geteilte Beispiel für maschinelles Lernen ist ein Beispiel für das, was wir „überwachtes maschinelles Lernen“ nennen. Wir nennen es überwacht, weil wir einen Trainingsdatensatz bereitgestellt haben, der Zielausgabewerte enthielt, und der Algorithmus diesen verwenden konnte, um eine Gleichung zu erstellen, die dieselben (oder nahezu dieselben) Ausgabeergebnisse erzeugen würde. Es gibt auch eine Klasse von Algorithmen für maschinelles Lernen, die „unüberwachtes maschinelles Lernen“ durchführen.
Bei dieser Klasse von Algorithmen stellen wir immer noch einen Eingabedatensatz bereit, aber keine Beispiele für die Ausgabedaten. Die maschinellen Lernalgorithmen müssen die Daten überprüfen und selbst eine Bedeutung in den Daten finden. Das mag beängstigend nach menschlicher Intelligenz klingen, aber nein, so weit sind wir noch nicht. Lassen Sie uns dies anhand von zwei Beispielen für diese Art des maschinellen Lernens in der Welt veranschaulichen.
Ein Beispiel für unüberwachtes maschinelles Lernen ist Google News. Google hat die Systeme, um Artikel zu entdecken, die den meisten Verkehr durch heiße neue Suchanfragen erhalten, die anscheinend von neuen Ereignissen angetrieben werden. Aber woher weiß es, dass alle Artikel dasselbe Thema behandeln? Während es traditionelle Relevanzabgleiche wie bei der regulären Suche in Google News durchführen kann, geschieht dies durch Algorithmen, die ihnen helfen, Ähnlichkeiten zwischen Inhalten zu bestimmen.

Wie im obigen Beispielbild gezeigt, hat Google erfolgreich zahlreiche Artikel zur Verabschiedung des Infrastrukturgesetzes vom 10. August 2021 gruppiert. Wie zu erwarten, weist jeder Artikel, der sich auf die Beschreibung des Ereignisses konzentriert, und das Gesetz selbst wahrscheinlich erhebliche Ähnlichkeiten auf Inhalt. Das Erkennen dieser Ähnlichkeiten und das Identifizieren von Artikeln ist auch ein Beispiel für unüberwachtes maschinelles Lernen in Aktion.
Eine weitere interessante Klasse des maschinellen Lernens ist das, was wir „Empfehlungssysteme“ nennen. Wir sehen dies in der realen Welt auf E-Commerce-Sites wie Amazon oder auf Filmseiten wie Netflix. Bei Amazon sehen wir möglicherweise „Häufig zusammen gekauft“ unter einem Angebot auf einer Produktseite. Auf anderen Websites könnte dies so beschriftet sein wie „Personen, die das gekauft haben, haben auch das gekauft“.
Filmseiten wie Netflix verwenden ähnliche Systeme, um Ihnen Filmempfehlungen zu geben. Diese können auf bestimmten Einstellungen, von Ihnen bewerteten Filmen oder Ihrem Filmauswahlverlauf basieren. Ein beliebter Ansatz dafür ist, die Filme, die Sie gesehen und hoch bewertet haben, mit Filmen zu vergleichen, die von anderen Benutzern gesehen und ähnlich bewertet wurden.
Wenn Sie zum Beispiel 4 Actionfilme ziemlich gut bewertet haben und ein anderer Benutzer (den wir John nennen) ebenfalls Actionfilme hoch bewertet, empfiehlt Ihnen das System möglicherweise andere Filme, die John gesehen hat, die Sie aber noch nicht gesehen haben . Dieser allgemeine Ansatz wird als „kollaboratives Filtern“ bezeichnet und ist einer von mehreren Ansätzen zum Aufbau eines Empfehlungssystems.
Hinweis: Vielen Dank an Chris Penn für die Durchsicht dieses Artikels und die Bereitstellung von Anleitungen.
Die in diesem Artikel geäußerten Meinungen sind die des Gastautors und nicht unbedingt Search Engine Land. Mitarbeiter Autoren sind hier aufgelistet.