
ถามผู้เชี่ยวชาญ: ทำความเข้าใจ AI และการเรียนรู้ของเครื่องในการค้นหา
เผยแพร่แล้ว: 2021-08-27โลกของ AI และแมชชีนเลิร์นนิงมีหลายชั้นและอาจซับซ้อนในการเรียนรู้ มีคำศัพท์หลายคำที่ใช้อยู่ และหากคุณไม่มีความเข้าใจพื้นฐานเกี่ยวกับภูมิประเทศ ก็อาจทำให้สับสนได้ ในบทความนี้ ผู้เชี่ยวชาญ Eric Enge จะแนะนำแนวคิดพื้นฐานและพยายามอธิบายให้เข้าใจทั้งหมดสำหรับคุณ นี่เป็นบทความชุดแรกในบทความสี่ตอนที่ครอบคลุมแง่มุมที่น่าสนใจมากขึ้นของภูมิทัศน์ AI
อีกสามบทความในชุดนี้จะเป็น:
- ความรู้เบื้องต้นเกี่ยวกับการประมวลผลภาษาธรรมชาติ
- GPT-3: มันคืออะไรและจะใช้ประโยชน์จากมันอย่างไร
- อัลกอริทึม Google AI ปัจจุบัน: Rankbrain, BERT, MUM และ SMITH
พื้นหลังพื้นฐานเกี่ยวกับ AI
มีคำศัพท์ที่แตกต่างกันมากมายจนยากที่จะแยกแยะว่าคำเหล่านั้นหมายถึงอะไร มาเริ่มด้วยคำจำกัดความกันก่อน:
- ปัญญาประดิษฐ์ – หมายถึง ปัญญาที่ครอบครอง/แสดงโดยเครื่องจักร ตรงข้ามกับความฉลาดทางธรรมชาติ ซึ่งเป็นสิ่งที่เราเห็นในมนุษย์และสัตว์อื่นๆ
- ปัญญาประดิษฐ์ทั่วไป (AGI) – นี่คือระดับของความฉลาดที่เครื่องจักรสามารถจัดการกับงานใดๆ ที่มนุษย์สามารถทำได้ มันยังไม่มีอยู่จริง แต่หลายคนพยายามที่จะสร้างมันขึ้นมา
- การเรียนรู้ของเครื่อง – นี่คือชุดย่อยของ AI ที่ใช้ข้อมูลและการทดสอบซ้ำเพื่อเรียนรู้วิธีการทำงานเฉพาะ
- การเรียนรู้เชิงลึก – นี่คือส่วนย่อยของการเรียนรู้ของเครื่องที่ใช้ประโยชน์จากโครงข่ายประสาทเทียมที่มีความซับซ้อนสูง เพื่อแก้ปัญหาการเรียนรู้ของเครื่องที่ซับซ้อนยิ่งขึ้น
- การประมวลผลภาษาธรรมชาติ (NLP) – เป็นสาขาของ AI ที่เน้นการประมวลผลและการทำความเข้าใจภาษาโดยเฉพาะ
- โครงข่ายประสาทเทียม – นี่เป็นหนึ่งในอัลกอริธึมการเรียนรู้ของเครื่องที่ได้รับความนิยมมากขึ้น ซึ่งพยายามจำลองวิธีที่เซลล์ประสาทโต้ตอบในสมอง
สิ่งเหล่านี้มีความเกี่ยวข้องอย่างใกล้ชิดและเป็นประโยชน์ที่จะเห็นว่าพวกเขาเข้ากันได้อย่างไร:

โดยสรุป ปัญญาประดิษฐ์ครอบคลุมแนวคิดเหล่านี้ทั้งหมด การเรียนรู้เชิงลึกเป็นส่วนย่อยของการเรียนรู้ของเครื่อง และการประมวลผลภาษาธรรมชาติใช้อัลกอริธึม AI ที่หลากหลายเพื่อให้เข้าใจภาษาได้ดีขึ้น
ภาพประกอบตัวอย่างการทำงานของโครงข่ายประสาทเทียม
อัลกอริธึมการเรียนรู้ของเครื่องมีหลายประเภท อัลกอริทึมที่รู้จักกันดีที่สุดคืออัลกอริธึมโครงข่ายประสาทเทียม และเพื่อให้คุณมีบริบทเล็กๆ น้อยๆ นั่นคือสิ่งที่ฉันจะพูดถึงต่อไป
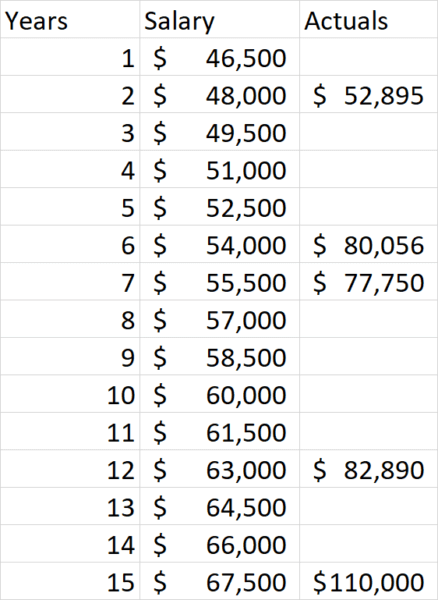
พิจารณาปัญหาในการกำหนดเงินเดือนพนักงาน เช่น เราจ่ายให้คนที่มีประสบการณ์ 10 ปี อะไร? เพื่อตอบคำถามนั้น เราสามารถรวบรวมข้อมูลบางอย่างเกี่ยวกับสิ่งที่ผู้อื่นได้รับและประสบการณ์หลายปีของพวกเขา ซึ่งอาจมีลักษณะดังนี้:

ด้วยข้อมูลเช่นนี้ เราสามารถคำนวณได้อย่างง่ายดายว่าพนักงานรายนี้ควรได้รับเงินเท่าใดโดยการสร้างกราฟเส้น:

สำหรับบุคคลนี้โดยเฉพาะ แนะนำให้มีเงินเดือนที่มากกว่า $90,000 ต่อปีเพียงเล็กน้อย อย่างไรก็ตาม เราทุกคนสามารถทราบได้อย่างรวดเร็วว่านี่ไม่ใช่มุมมองที่เพียงพอจริงๆ เนื่องจากเราจำเป็นต้องพิจารณาลักษณะของงานและระดับการปฏิบัติงานของพนักงานด้วย การแนะนำตัวแปรทั้งสองนี้จะนำเราไปสู่แผนภูมิข้อมูลในลักษณะนี้มากขึ้น:

มันเป็นปัญหาที่ยากกว่ามากที่จะแก้ไข แต่อย่างใดอย่างหนึ่งที่แมชชีนเลิร์นนิงสามารถทำได้ค่อนข้างง่าย ถึงกระนั้น เราไม่ได้เพิ่มความซับซ้อนให้กับปัจจัยที่ส่งผลกระทบต่อเงินเดือน จริงๆ แล้ว ตำแหน่งที่คุณอยู่ก็ส่งผลกระทบอย่างมากเช่นกัน ตัวอย่างเช่น งานในซานฟรานซิสโกเบย์แอเรียในด้านเทคโนโลยีจ่ายมากกว่างานเดียวกันในหลายส่วนของประเทศอย่างมีนัยสำคัญ โดยส่วนใหญ่เนื่องจากค่าครองชีพต่างกันมาก

แนวทางพื้นฐานที่โครงข่ายประสาทเทียมจะใช้คือการเดาสมการที่ถูกต้องโดยใช้ตัวแปร (งาน ประสบการณ์หลายปี ระดับผลงาน) และคำนวณเงินเดือนที่เป็นไปได้โดยใช้สมการนั้น และดูว่าตรงกับข้อมูลจริงของเรามากน้อยเพียงใด กระบวนการนี้เป็นวิธีการปรับแต่งโครงข่ายประสาทเทียม และเรียกว่า "การไล่ระดับสีแบบค่อยเป็นค่อยไป" วิธีอธิบายภาษาอังกฤษแบบง่ายๆ คือเรียกว่า "การประมาณแบบต่อเนื่อง"
ข้อมูลเงินเดือนดั้งเดิมคือสิ่งที่โครงข่ายประสาทเทียมจะใช้เป็น "ข้อมูลการฝึกอบรม" เพื่อให้สามารถทราบได้เมื่อสร้างอัลกอริทึมที่ตรงกับประสบการณ์ในโลกแห่งความเป็นจริง มาดูตัวอย่างง่ายๆ โดยเริ่มจากชุดข้อมูลเดิมของเราด้วยประสบการณ์หลายปีและข้อมูลเงินเดือนกัน

เพื่อให้ตัวอย่างของเราง่ายขึ้น สมมติว่าโครงข่ายประสาทเทียมที่เราจะใช้สำหรับสิ่งนี้เข้าใจว่า 0 ปีของประสบการณ์เท่ากับ 45,000 ดอลลาร์ในเงินเดือนและรูปแบบพื้นฐานของสมการควรเป็น: เงินเดือน = ปีของการบริการ * X + 45,000 ดอลลาร์ . เราจำเป็นต้องหาค่าของ X เพื่อให้ได้สมการที่ถูกต้องมาใช้ ในขั้นแรก โครงข่ายประสาทเทียมอาจเดาได้ว่าค่าของ X คือ 1,500 ดอลลาร์ ในทางปฏิบัติ อัลกอริธึมเหล่านี้ทำให้การเดาเบื้องต้นเหล่านี้เป็นการสุ่ม แต่ตอนนี้จะทำได้ นี่คือสิ่งที่เราได้รับเมื่อเราลองมูลค่า $1500:

ดังที่เราเห็นจากข้อมูลผลลัพธ์ ค่าที่คำนวณได้นั้นต่ำเกินไป โครงข่ายประสาทเทียมได้รับการออกแบบมาเพื่อเปรียบเทียบค่าที่คำนวณได้กับค่าจริง และใช้เป็นข้อมูลป้อนกลับ ซึ่งสามารถใช้เพื่อลองเดาครั้งที่สองว่าคำตอบที่ถูกต้องคืออะไร สำหรับภาพประกอบของเรา ให้เงิน $3,000 เป็นการเดาครั้งต่อไปว่าเป็นค่าที่ถูกต้องสำหรับ X นี่คือสิ่งที่เราได้รับในครั้งนี้:

อย่างที่เราเห็นว่าผลลัพธ์ของเราดีขึ้นซึ่งเป็นสิ่งที่ดี! อย่างไรก็ตาม เรายังคงต้องเดาอีกครั้งเพราะเรายังใกล้เคียงกับค่าที่ถูกต้องไม่พอ คราวนี้มาลองเดา $6000 กัน:

ที่น่าสนใจคือ ตอนนี้เราเห็นว่าระยะขอบของข้อผิดพลาดเพิ่มขึ้นเล็กน้อย แต่ตอนนี้เราสูงเกินไป! บางทีเราจำเป็นต้องปรับสมการของเรากลับลงมาเล็กน้อย มาลองกัน $4500:

ตอนนี้เราเห็นว่าเราค่อนข้างสนิทกัน! เราสามารถลองใช้ค่าเพิ่มเติมเพื่อดูว่าเราสามารถปรับปรุงผลลัพธ์ได้มากน้อยเพียงใด สิ่งนี้ทำให้เกิดค่าสำคัญอีกอย่างหนึ่งในการเรียนรู้ของเครื่องซึ่งเราต้องการให้อัลกอริทึมของเรามีความแม่นยำเพียงใดและเมื่อใดที่เราจะหยุดการวนซ้ำ แต่สำหรับจุดประสงค์ของตัวอย่างของเราที่นี่ เราใกล้พอแล้ว และหวังว่าคุณจะพอมีไอเดียว่าทั้งหมดนี้ทำงานอย่างไร
ตัวอย่างแบบฝึกหัดแมชชีนเลิร์นนิงของเรามีอัลกอริธึมที่ง่ายมากในการสร้าง เนื่องจากเราต้องการเพียงเพื่อให้ได้สมการในรูปแบบนี้เท่านั้น: เงินเดือน = ปีของการบริการ * X + 45,000 ดอลลาร์ (aka y = mx + b) อย่างไรก็ตาม หากเราพยายามคำนวณอัลกอริธึมเงินเดือนที่แท้จริงซึ่งคำนึงถึงปัจจัยทั้งหมดที่ส่งผลกระทบต่อเงินเดือนของผู้ใช้ เราจะต้อง:
- ชุดข้อมูลขนาดใหญ่กว่ามากเพื่อใช้เป็นข้อมูลการฝึกอบรมของเรา
- เพื่อสร้างอัลกอริธึมที่ซับซ้อนมากขึ้น
คุณสามารถดูได้ว่าโมเดลการเรียนรู้ของเครื่องจะมีความซับซ้อนสูงอย่างรวดเร็วได้อย่างไร ลองนึกภาพความซับซ้อนเมื่อเราจัดการกับบางสิ่งในระดับการประมวลผลภาษาธรรมชาติ!
อัลกอริธึมการเรียนรู้ของเครื่องพื้นฐานประเภทอื่นๆ
ตัวอย่างแมชชีนเลิร์นนิงที่แชร์ข้างต้นเป็นตัวอย่างของสิ่งที่เราเรียกว่า “การเรียนรู้ของเครื่องภายใต้การดูแล” เราเรียกว่ามีการควบคุมดูแลเนื่องจากเราจัดเตรียมชุดข้อมูลการฝึกอบรมที่มีค่าเอาต์พุตเป้าหมาย และอัลกอริทึมก็สามารถใช้สิ่งนั้นเพื่อสร้างสมการที่จะสร้างผลลัพธ์เอาต์พุตที่เหมือนกัน (หรือใกล้เคียงกัน) นอกจากนี้ยังมีคลาสของอัลกอริธึมการเรียนรู้ของเครื่องที่ดำเนินการ
ด้วยอัลกอริธึมประเภทนี้ เรายังคงจัดเตรียมชุดข้อมูลอินพุตแต่ไม่ได้ให้ตัวอย่างข้อมูลเอาต์พุต อัลกอริทึมการเรียนรู้ของเครื่องจำเป็นต้องตรวจสอบข้อมูลและค้นหาความหมายภายในข้อมูลด้วยตนเอง นี่อาจฟังดูน่ากลัวเหมือนความฉลาดของมนุษย์ แต่ไม่ เรายังไม่ถึงจุดนั้น มาดูตัวอย่างสองตัวอย่างของแมชชีนเลิร์นนิงในโลกนี้กัน
ตัวอย่างหนึ่งของแมชชีนเลิร์นนิงที่ไม่มีผู้ดูแลคือ Google News Google มีระบบในการค้นหาบทความที่มีผู้เข้าชมมากที่สุดจากข้อความค้นหาใหม่ที่กำลังมาแรง ซึ่งดูเหมือนว่าจะมีแรงหนุนจากเหตุการณ์ใหม่ แต่จะรู้ได้อย่างไรว่าบทความทั้งหมดอยู่ในหัวข้อเดียวกัน แม้ว่าจะสามารถจับคู่ความเกี่ยวข้องแบบดั้งเดิมกับวิธีที่พวกเขาทำในการค้นหาปกติใน Google News ได้ แต่ก็ทำโดยอัลกอริทึมที่ช่วยระบุความคล้ายคลึงกันระหว่างส่วนต่างๆ ของเนื้อหา

ดังที่แสดงในภาพตัวอย่างด้านบน Google ได้จัดกลุ่มบทความจำนวนมากเกี่ยวกับร่างกฎหมายโครงสร้างพื้นฐานได้สำเร็จเมื่อวันที่ 10 สิงหาคม 2021 อย่างที่คุณคาดไว้ บทความแต่ละบทความที่เน้นที่การอธิบายเหตุการณ์และร่างกฎหมายนั้นมีแนวโน้มว่าจะมีความคล้ายคลึงกันอย่างมากใน เนื้อหา. การตระหนักถึงความคล้ายคลึงเหล่านี้และการระบุบทความยังเป็นตัวอย่างของการเรียนรู้ของเครื่องที่ไม่ได้รับการดูแล
การเรียนรู้ด้วยเครื่องที่น่าสนใจอีกประเภทหนึ่งคือสิ่งที่เราเรียกว่า "ระบบผู้แนะนำ" เราเห็นสิ่งนี้ในโลกแห่งความเป็นจริงในเว็บไซต์อีคอมเมิร์ซเช่น Amazon หรือเว็บไซต์ภาพยนตร์เช่น Netflix ใน Amazon เราอาจเห็น "Frequently Buyed Together" ใต้รายการสินค้าในหน้าผลิตภัณฑ์ ในไซต์อื่นๆ อาจมีป้ายกำกับว่า "ผู้ที่ซื้อสิ่งนี้ก็ซื้อสิ่งนี้ด้วย"
เว็บไซต์ภาพยนตร์เช่น Netflix ใช้ระบบที่คล้ายกันเพื่อให้คำแนะนำภาพยนตร์แก่คุณ สิ่งเหล่านี้อาจขึ้นอยู่กับการตั้งค่าที่ระบุ ภาพยนตร์ที่คุณเคยให้คะแนน หรือประวัติการเลือกภาพยนตร์ของคุณ วิธีหนึ่งที่ได้รับความนิยมคือการเปรียบเทียบภาพยนตร์ที่คุณเคยดูและให้คะแนนสูงกับภาพยนตร์ที่เคยดูและให้คะแนนโดยผู้ใช้รายอื่นใกล้เคียงกัน
ตัวอย่างเช่น หากคุณให้คะแนนภาพยนตร์แอคชั่น 4 เรื่องค่อนข้างสูง และผู้ใช้คนอื่น (ซึ่งเราจะเรียกว่าจอห์น) ก็ให้คะแนนภาพยนตร์แอคชั่นสูงเช่นกัน ระบบอาจแนะนำภาพยนตร์อื่นๆ ที่จอห์นเคยดูแต่คุณยังไม่ได้ . วิธีการทั่วไปนี้เรียกว่า "การกรองการทำงานร่วมกัน" และเป็นหนึ่งในวิธีการต่างๆ ในการสร้างระบบผู้แนะนำ
หมายเหตุ: ขอขอบคุณ Chris Penn สำหรับการทบทวนบทความนี้และให้คำแนะนำ
ความคิดเห็นที่แสดงในบทความนี้เป็นความคิดเห็นของผู้เขียนรับเชิญและไม่จำเป็นต้องเป็น Search Engine Land ผู้เขียนพนักงานอยู่ที่นี่