
Tanyakan pada ahlinya: Demystifying AI dan Machine Learning dalam pencarian
Diterbitkan: 2021-08-27Dunia AI dan Machine Learning memiliki banyak lapisan dan bisa sangat rumit untuk dipelajari. Banyak istilah di luar sana dan kecuali Anda memiliki pemahaman dasar tentang lanskap, itu bisa sangat membingungkan. Dalam artikel ini, pakar Eric Enge akan memperkenalkan konsep dasar dan mencoba mengungkap semuanya untuk Anda. Ini juga yang pertama dari seri artikel empat bagian yang mencakup banyak aspek yang lebih menarik dari lanskap AI.
Tiga artikel lainnya dalam seri ini adalah:
- Pengantar Pemrosesan Bahasa Alami
- GPT-3: Apa Itu dan Bagaimana Memanfaatkannya
- Algoritma AI Google Saat Ini: Rankbrain, BERT, MUM, dan SMITH
Latar belakang dasar tentang AI
Ada begitu banyak istilah yang berbeda sehingga sulit untuk memilah apa artinya semua. Jadi mari kita mulai dengan beberapa definisi:
- Kecerdasan Buatan – Ini mengacu pada kecerdasan yang dimiliki/ditunjukkan oleh mesin, sebagai lawan dari kecerdasan alami, yang kita lihat pada manusia dan hewan lain.
- Artificial General Intelligence (AGI) – Ini adalah tingkat kecerdasan di mana mesin dapat menangani tugas apa pun yang dapat dilakukan manusia. Itu belum ada, tetapi banyak yang berusaha untuk membuatnya.
- Pembelajaran Mesin – Ini adalah bagian dari AI yang menggunakan data dan pengujian berulang untuk mempelajari cara melakukan tugas tertentu.
- Pembelajaran Mendalam – Ini adalah bagian dari pembelajaran mesin yang memanfaatkan jaringan saraf yang sangat kompleks untuk memecahkan masalah pembelajaran mesin yang lebih kompleks.
- Natural Language Processing (NLP) – Ini adalah bidang AI yang berfokus khusus pada pemrosesan dan pemahaman bahasa.
- Neural Networks – Ini adalah salah satu jenis algoritma pembelajaran mesin yang lebih populer yang mencoba untuk memodelkan cara neuron berinteraksi di otak.
Ini semua terkait erat dan sangat membantu untuk melihat bagaimana mereka semua cocok satu sama lain:

Singkatnya, Kecerdasan buatan mencakup semua konsep ini, pembelajaran mendalam adalah bagian dari pembelajaran mesin, dan pemrosesan bahasa alami menggunakan berbagai algoritme AI untuk lebih memahami bahasa.
Contoh ilustrasi cara kerja jaringan saraf
Ada banyak jenis algoritma pembelajaran mesin. Yang paling terkenal dari ini adalah algoritma jaringan saraf dan untuk memberi Anda sedikit konteks itulah yang akan saya bahas selanjutnya.
Pertimbangkan masalah penentuan gaji untuk seorang karyawan. Misalnya, apa yang kita bayar untuk seseorang dengan pengalaman 10 tahun? Untuk menjawab pertanyaan itu, kami dapat mengumpulkan beberapa data tentang apa yang dibayar orang lain dan pengalaman mereka selama bertahun-tahun, dan itu mungkin terlihat seperti ini:

Dengan data seperti ini kita dapat dengan mudah menghitung berapa yang harus dibayar oleh karyawan ini dengan membuat grafik garis:

Untuk orang khusus ini, ini menunjukkan gaji sedikit di atas $90.000 per tahun. Namun, kita semua dapat dengan cepat menyadari bahwa ini bukanlah pandangan yang cukup karena kita juga perlu mempertimbangkan sifat pekerjaan dan tingkat kinerja karyawan. Memperkenalkan kedua variabel tersebut akan membawa kita ke bagan data yang lebih seperti ini:

Ini adalah masalah yang jauh lebih sulit untuk dipecahkan tetapi yang dapat dilakukan oleh pembelajaran mesin dengan relatif mudah. Namun, kami belum benar-benar selesai menambahkan kerumitan pada faktor-faktor yang memengaruhi gaji, karena lokasi Anda juga memiliki pengaruh yang besar. Misalnya, pekerjaan di San Francisco Bay Area di bidang teknologi membayar jauh lebih tinggi daripada pekerjaan yang sama di banyak bagian lain negara, sebagian besar karena perbedaan besar dalam biaya hidup.

Pendekatan dasar yang akan digunakan jaringan saraf adalah menebak persamaan yang benar menggunakan variabel (pekerjaan, pengalaman bertahun-tahun, tingkat kinerja) dan menghitung gaji potensial menggunakan persamaan itu dan melihat seberapa cocoknya dengan data dunia nyata kita. Proses ini adalah bagaimana jaringan saraf disetel dan disebut sebagai "gradient descending". Cara sederhana dalam bahasa Inggris untuk menjelaskannya adalah dengan menyebutnya “perkiraan berturut-turut.”
Data gaji asli adalah yang akan digunakan jaringan saraf sebagai "data pelatihan" sehingga dapat mengetahui kapan ia telah membangun algoritme yang cocok dengan pengalaman dunia nyata. Mari kita telusuri contoh sederhana yang dimulai dengan kumpulan data asli kami hanya dengan pengalaman bertahun-tahun dan data gaji.

Agar contoh kita lebih sederhana, mari kita asumsikan bahwa jaringan saraf yang akan kita gunakan untuk ini memahami bahwa 0 tahun pengalaman setara dengan gaji $45.000 dan bentuk dasar persamaannya adalah: Gaji = Tahun Kerja * X + $45.000 . Kita perlu mencari nilai X untuk menghasilkan persamaan yang tepat untuk digunakan. Sebagai langkah pertama, jaringan saraf mungkin menebak bahwa nilai X adalah $1.500. Dalam praktiknya, algoritme ini membuat tebakan awal ini secara acak, tetapi ini akan dilakukan untuk saat ini. Inilah yang kami dapatkan ketika kami mencoba nilai $ 1500:

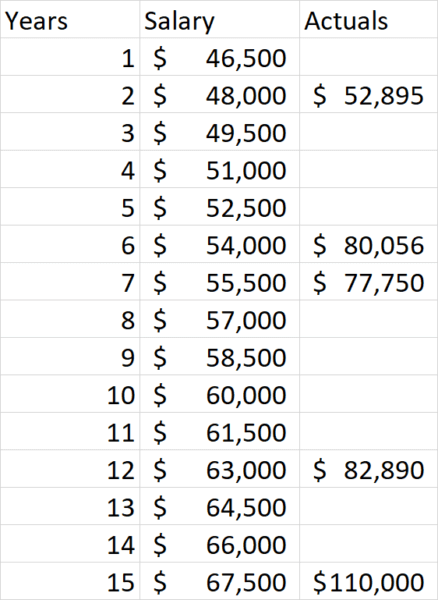
Seperti yang dapat kita lihat dari data yang dihasilkan, nilai yang dihitung terlalu rendah. Jaringan saraf dirancang untuk membandingkan nilai yang dihitung dengan nilai sebenarnya dan menyediakannya sebagai umpan balik yang kemudian dapat digunakan untuk mencoba menebak jawaban yang benar. Untuk ilustrasi kita, mari kita tebak $3.000 berikutnya sebagai nilai yang benar untuk X. Inilah yang kita dapatkan kali ini:

Seperti yang kita lihat, hasil kami telah meningkat, itu bagus! Namun, kita masih perlu menebak lagi karena kita tidak cukup dekat dengan nilai yang benar. Jadi, mari kita coba tebak $6000 kali ini:

Menariknya, kami sekarang melihat bahwa margin kesalahan kami sedikit meningkat, tetapi kami sekarang terlalu tinggi! Mungkin kita perlu sedikit menyesuaikan persamaan kita. Mari kita coba $4500:

Sekarang kita lihat kita cukup dekat! Kami dapat terus mencoba nilai-nilai tambahan untuk melihat seberapa jauh kami dapat meningkatkan hasil. Ini memainkan nilai kunci lain dalam pembelajaran mesin yaitu seberapa tepat algoritma yang kita inginkan dan kapan kita berhenti melakukan iterasi. Tetapi untuk tujuan contoh kami di sini kami cukup dekat dan mudah-mudahan Anda memiliki gagasan tentang bagaimana semua ini bekerja.
Contoh latihan pembelajaran mesin kami memiliki algoritme yang sangat sederhana untuk dibuat karena kami hanya perlu menurunkan persamaan dalam bentuk ini: Gaji = Tahun Kerja * X + $45,000 (alias y = mx + b). Namun, jika kami mencoba menghitung algoritme gaji sebenarnya yang memperhitungkan semua faktor yang memengaruhi gaji pengguna, kami akan membutuhkan:
- kumpulan data yang jauh lebih besar untuk digunakan sebagai data pelatihan kami
- untuk membangun algoritma yang jauh lebih kompleks
Anda dapat melihat bagaimana model pembelajaran mesin dapat dengan cepat menjadi sangat kompleks. Bayangkan kerumitannya ketika kita berurusan dengan sesuatu dalam skala pemrosesan bahasa alami!
Jenis lain dari algoritma pembelajaran mesin dasar
Contoh pembelajaran mesin yang dibagikan di atas adalah contoh dari apa yang kami sebut "pembelajaran mesin yang diawasi". Kami menyebutnya terawasi karena kami menyediakan kumpulan data pelatihan yang berisi nilai keluaran target dan algoritme dapat menggunakannya untuk menghasilkan persamaan yang akan menghasilkan hasil keluaran yang sama (atau mendekati sama). Ada juga kelas algoritme pembelajaran mesin yang melakukan "pembelajaran mesin tanpa pengawasan".
Dengan kelas algoritma ini, kami masih memberikan kumpulan data input tetapi tidak memberikan contoh data output. Algoritme pembelajaran mesin perlu meninjau data dan menemukan makna di dalam data itu sendiri. Ini mungkin terdengar menakutkan seperti kecerdasan manusia, tetapi tidak, kita belum sampai di sana. Mari kita ilustrasikan dengan dua contoh pembelajaran mesin jenis ini di dunia.
Salah satu contoh pembelajaran mesin tanpa pengawasan adalah Google Berita. Google memiliki sistem untuk menemukan artikel yang mendapatkan lalu lintas terbanyak dari kueri penelusuran baru yang tampaknya didorong oleh peristiwa baru. Tapi bagaimana ia tahu bahwa semua artikel memiliki topik yang sama? Meskipun dapat melakukan pencocokan relevansi tradisional seperti yang mereka lakukan dalam pencarian biasa di Google Berita, ini dilakukan oleh algoritme yang membantu mereka menentukan kesamaan di antara bagian konten.

Seperti yang ditunjukkan pada contoh gambar di atas, Google telah berhasil mengelompokkan banyak artikel tentang pengesahan RUU infrastruktur pada 10 Agustus 2021. Seperti yang Anda duga, setiap artikel yang difokuskan untuk menggambarkan peristiwa dan RUU itu sendiri kemungkinan memiliki kesamaan substansial dalam isi. Mengenali kesamaan ini dan mengidentifikasi artikel juga merupakan contoh penerapan pembelajaran mesin tanpa pengawasan.
Kelas pembelajaran mesin lain yang menarik adalah apa yang kami sebut "sistem rekomendasi". Kami melihat ini di dunia nyata di situs e-commerce seperti Amazon, atau di situs film seperti Netflix. Di Amazon, kita mungkin melihat "Sering Dibeli Bersama" di bawah daftar pada halaman produk. Di situs lain, ini mungkin diberi label seperti “Orang yang membeli ini juga membeli ini.”
Situs film seperti Netflix menggunakan sistem serupa untuk membuat rekomendasi film kepada Anda. Ini mungkin didasarkan pada preferensi tertentu, film yang Anda beri peringkat, atau riwayat pemilihan film Anda. Salah satu pendekatan populer untuk ini adalah membandingkan film yang telah Anda tonton dan berperingkat tinggi dengan film yang telah ditonton dan diberi peringkat serupa oleh pengguna lain.
Misalnya, jika Anda menilai 4 film aksi dengan cukup tinggi, dan pengguna lain (yang kami sebut John) juga menilai film aksi dengan sangat tinggi, sistem mungkin merekomendasikan kepada Anda film lain yang telah John tonton tetapi belum Anda tonton. . Pendekatan umum inilah yang disebut “collaborative filtering” dan merupakan salah satu dari beberapa pendekatan untuk membangun sistem rekomendasi.
Catatan: Terima kasih kepada Chris Penn karena telah meninjau artikel ini dan memberikan panduan.
Pendapat yang diungkapkan dalam artikel ini adalah dari penulis tamu dan belum tentu Search Engine Land. Penulis staf tercantum di sini.