
専門家に尋ねる:検索におけるAIと機械学習の謎を解き明かす
公開: 2021-08-27AIと機械学習の世界には多くの層があり、学習するのは非常に複雑になる可能性があります。 多くの用語が出回っていますが、風景の基本的な理解がない限り、かなり混乱する可能性があります。 この記事では、エキスパートのエリック・エンゲが基本的な概念を紹介し、すべてをわかりやすく説明します。 これは、AIランドスケープのより興味深い側面の多くをカバーする4部構成の記事シリーズの最初のものでもあります。
このシリーズの他の3つの記事は次のとおりです。
- 自然言語処理の概要
- GPT-3:それは何であり、それをどのように活用するか
- 現在のGoogleAIアルゴリズム:Rankbrain、BERT、MUM、SMITH
AIの基本的な背景
非常に多くの異なる用語があるため、それらすべてが何を意味するのかを整理するのは難しい場合があります。 それでは、いくつかの定義から始めましょう。
- 人工知能–これは、人間や他の動物に見られる自然の知能とは対照的に、機械が所有/実証する知能を指します。
- 人工知能(AGI) –これは、機械が人間が実行できるあらゆるタスクに対処できる知能のレベルです。 それはまだ存在していませんが、多くの人がそれを作成しようと努力しています。
- 機械学習–これは、データと反復テストを使用して特定のタスクを実行する方法を学習するAIのサブセットです。
- ディープラーニング–これは、非常に複雑な神経ネットワークを活用してより複雑な機械学習の問題を解決する機械学習のサブセットです。
- 自然言語処理(NLP) –これはAIの分野であり、特に言語の処理と理解に重点を置いています。
- ニューラルネットワーク–これは、ニューロンが脳内で相互作用する方法をモデル化しようとする、最も一般的なタイプの機械学習アルゴリズムの1つです。
これらはすべて密接に関連しており、すべてがどのように組み合わされているかを確認するのに役立ちます。

要約すると、人工知能はこれらすべての概念を網羅し、深層学習は機械学習のサブセットであり、自然言語処理は言語をよりよく理解するために幅広いAIアルゴリズムを使用します。
ニューラルネットワークがどのように機能するかのサンプル図
機械学習アルゴリズムにはさまざまな種類があります。 これらの中で最もよく知られているのはニューラルネットワークアルゴリズムであり、次に取り上げる内容である小さなコンテキストを提供します。
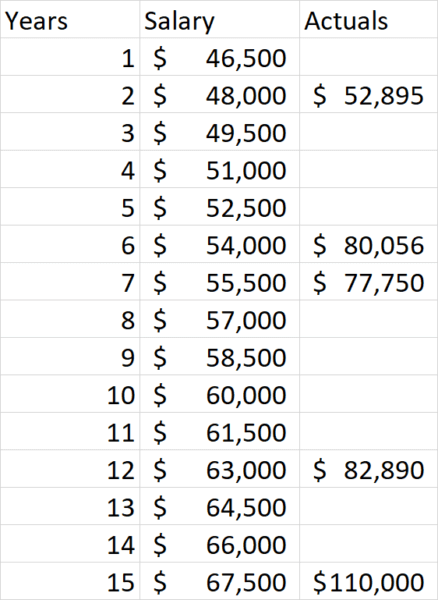
従業員の給与を決定する問題を考えてみましょう。 たとえば、10年の経験を持つ人に何を支払いますか? その質問に答えるために、他の人に支払われているものと彼らの長年の経験に関するいくつかのデータを収集することができます。これは次のようになります。

このようなデータを使用すると、折れ線グラフを作成することで、この特定の従業員に支払われるべき金額を簡単に計算できます。

この特定の人にとって、それは年間90,000ドル強の給料を示唆しています。 しかし、仕事の性質や従業員のパフォーマンスレベルも考慮する必要があるため、これは実際には十分な見解ではないことをすぐに認識できます。 これらの2つの変数を導入すると、次のようなデータチャートが表示されます。

解決するのははるかに難しい問題ですが、機械学習で比較的簡単に実行できる問題です。 しかし、あなたがいる場所も大きな影響を与えるため、給与に影響を与える要因に複雑さを加えることは実際には完了していません。 たとえば、サンフランシスコベイエリアのテクノロジー分野の仕事は、主に生活費の大きな違いのために、国の他の多くの地域での同じ仕事よりもはるかに多く支払っています。

ニューラルネットワークが使用する基本的なアプローチは、変数(仕事、年数、パフォーマンスレベル)を使用して正しい方程式を推測し、その方程式を使用して潜在的な給与を計算し、それが実際のデータとどの程度一致するかを確認することです。 このプロセスは、ニューラルネットワークがどのように調整されるかであり、「最急降下法」と呼ばれます。 それを説明する簡単な英語の方法は、それを「逐次近似」と呼ぶことです。
元の給与データは、ニューラルネットワークが「トレーニングデータ」として使用するものであり、実際の経験と一致するアルゴリズムをいつ構築したかを知ることができます。 長年の経験と給与データを使用した元のデータセットから始めて、簡単な例を見ていきましょう。

例を簡単にするために、これに使用するニューラルネットワークが、0年の経験が給与で45,000ドルに相当し、方程式の基本形式が次のようになることを理解していると仮定します。給与=勤続年数* X +45,000ドル。 使用する正しい方程式を考え出すには、Xの値を計算する必要があります。 最初のステップとして、ニューラルネットワークはXの値が$1,500であると推測する場合があります。 実際には、これらのアルゴリズムはこれらの初期推測をランダムに行いますが、今のところこれで十分です。 $ 1500の値を試してみると、次のようになります。

結果のデータからわかるように、計算された値は低すぎます。 ニューラルネットワークは、計算された値を実際の値と比較し、それをフィードバックとして提供するように設計されています。フィードバックは、正解が何であるかを2番目に推測するために使用できます。 この例では、Xの正しい値として次の推測として$3,000を使用します。今回は次のようになります。

ご覧のとおり、結果は改善されています。これは良いことです。 ただし、適切な値に十分に近づいていないため、もう一度推測する必要があります。 それでは、今回は$6000の見積もりを試してみましょう。

興味深いことに、許容誤差がわずかに増加していることがわかりましたが、高すぎます。 おそらく、方程式を少し下に調整する必要があります。 $ 4500を試してみましょう:

今、私たちはかなり接近していることがわかります! 追加の値を試し続けて、結果をさらに改善できるかどうかを確認できます。 これにより、機械学習のもう1つの重要な価値がもたらされます。それは、アルゴリズムをどれだけ正確にしたいのか、いつ反復を停止するのかということです。 しかし、ここでの例の目的のために、私たちは十分に近いです、そしてうまくいけば、あなたはこれらすべてがどのように機能するかについての考えを持っています。
この例の機械学習演習では、次の形式で方程式を導出するだけでよいため、非常に単純なアルゴリズムを構築できました。給与=勤続年数* X + $ 45,000(別名y = mx + b)。 ただし、ユーザーの給与に影響を与えるすべての要因を考慮した真の給与アルゴリズムを計算しようとすると、次のようになります。
- トレーニングデータとして使用するはるかに大きなデータセット
- はるかに複雑なアルゴリズムを構築する
機械学習モデルが急速に非常に複雑になる可能性があることがわかります。 自然言語処理の規模で何かを扱っているときの複雑さを想像してみてください!
他のタイプの基本的な機械学習アルゴリズム
上で共有した機械学習の例は、「教師あり機械学習」と呼ばれるものの例です。 ターゲット出力値を含むトレーニングデータセットを提供し、アルゴリズムがそれを使用して同じ(またはほぼ同じ)出力結果を生成する方程式を生成できたため、これを監視対象と呼びます。 「教師なし機械学習」を実行する機械学習アルゴリズムのクラスもあります。
このクラスのアルゴリズムでは、入力データセットを提供しますが、出力データの例は提供しません。 機械学習アルゴリズムは、データを確認し、データ内の意味を独自に見つける必要があります。 これは人間の知性のように恐ろしく聞こえるかもしれませんが、いいえ、私たちはまだそこにいません。 このタイプの機械学習の世界での2つの例を使って説明しましょう。
教師なし機械学習の一例は、Googleニュースです。 グーグルは、新しいイベントによって引き起こされているように見えるホットな新しい検索クエリから最も多くのトラフィックを獲得している記事を発見するシステムを持っています。 しかし、すべての記事が同じトピックにあることをどうやって知るのでしょうか? Googleニュースでの通常の検索と同じように従来の関連性を一致させることができますが、これはコンテンツ間の類似性を判断するのに役立つアルゴリズムによって行われます。

上の画像の例に示されているように、Googleは2021年8月10日のインフラストラクチャ法案の可決に関する多数の記事をグループ化することに成功しました。ご想像のとおり、イベントの説明と法案自体に焦点を当てた各記事は、コンテンツ。 これらの類似点を認識し、記事を特定することも、教師なし機械学習が実際に行われている例です。
機械学習のもう1つの興味深いクラスは、「レコメンダーシステム」と呼ばれるものです。 これは、AmazonのようなeコマースサイトやNetflixのような映画サイトで実際に見られます。 Amazonでは、商品ページのリストの下に「FrequentlyBoughtTogether」と表示される場合があります。 他のサイトでは、これは「これを購入した人もこれを購入した」のようなラベルが付けられている可能性があります。
Netflixのような映画サイトは、同様のシステムを使用して映画のおすすめを作成します。 これらは、指定された設定、評価した映画、または映画の選択履歴に基づいている場合があります。 これに対する一般的なアプローチの1つは、自分が視聴して評価の高い映画を、他のユーザーが同様に視聴して評価した映画と比較することです。
たとえば、4つのアクション映画を非常に高く評価し、別のユーザー(ジョンと呼びます)もアクション映画を高く評価している場合、システムは、ジョンが視聴したがまだ視聴していない他の映画を推奨する場合があります。 。 この一般的なアプローチは、いわゆる「協調フィルタリング」であり、レコメンダーシステムを構築するためのいくつかのアプローチの1つです。
注:この記事を確認し、ガイダンスを提供してくれたChrisPennに感謝します。
この記事で表明された意見はゲスト著者の意見であり、必ずしも検索エンジンランドではありません。 スタッフの作者はここにリストされています。