
5 ameaças comuns à validade do seu teste A / B
Publicados: 2016-11-17Más notícias: esses 30% de conversão aumentaram seu último teste A / B produzido? Provavelmente não é tão alto quanto você pensava.
Na verdade, há uma chance de que ele nem exista.
“Pelo menos 80% dos testes vencedores são completamente inúteis”, escreve o líder de pesquisa do Qubit, Martin Goodson, em um white paper da empresa. Os que não são normalmente trazem elevadores pequenos e sustentáveis em vez dos gigantes que você vê divulgado em toda a web.
Então, por que seu software de teste A / B está dizendo o contrário?
Porque ele não consegue detectar as inúmeras ameaças invisíveis à validade que têm o potencial de envenenar seus dados. Conceitos como efeito de novidade, regressão à média, efeito de instrumentação e outros podem fazer com que você veja grandes elevações de conversão onde não há nenhuma.
Portanto, se você está tomando decisões de negócios com base em seus testes A / B apenas porque eles alcançaram significância estatística, pare agora. Você precisa alcançar significância estatística antes de fazer qualquer inferência com base em seus resultados, mas isso não é tudo de que você precisa. Você também deve executar um teste válido.
Clique para tweetar
A diferença entre significância estatística e validade
Significância estatística e validade são duas necessidades muito diferentes, mas igualmente importantes para a execução de testes de divisão com sucesso.
A significância estatística indica, com certo grau de confiança, a probabilidade de os resultados do teste serem confiáveis e não devido ao acaso. Para alcançar significância estatística, você precisa saber:
- A taxa de conversão de linha de base da sua página de controle
- A mudança mínima na taxa de conversão que você deseja detectar
- Quão confiante você deseja ter de que seus resultados são significativos e não devidos ao acaso (o nível de confiança padrão aceito é de 95%)
- O tamanho da amostra, também conhecido como quanto tráfego você precisa gerar antes de alcançar significância estatística (use esta calculadora para descobrir)
A validade, por outro lado, tem a ver com o fato de outros fatores fora do tamanho da amostra estarem ou não afetando seus dados negativamente.
Então, por que você precisa saber os dois?
Porque mesmo 53% dos testes A / A (testes da mesma página vs. testes da mesma página usados para avaliar a configuração do seu experimento) atingirão 95% de significância em algum ponto. Se os testes com duas páginas idênticas podem atingir significância estatística metade do tempo, como você pode ter certeza de que os resultados dos seus testes A / B são confiáveis?
Você não pode, explica Peep Laja da CXL:
“Se você interromper o teste assim que perceber a importância, há 50% de chance de que seja um golpe de sorte completo. Um cara ou coroa. Elimina totalmente a ideia de testar em primeiro lugar. ”
Em vez de depender apenas da significância estatística para determinar o vencedor de um teste de divisão, você precisa coletar o máximo de dados válidos que puder. E para fazer isso, você precisa entender que tipo de ameaças se interpõem em seu caminho.
Ameaças comuns à validade do teste A / B
1. Regressão em direção à média
“O tamanho da amostra é fundamental quando se trata de testes A / B”, diz o comerciante digital Chase Dumont. Quanto mais pessoas você testar, mais precisos serão os resultados.
Muitas vezes, os testadores A / B encerram seus experimentos mais cedo. Eles ficam entusiasmados quando veem um grande elevador e declaram o vencedor com confiança. Mas, estudos de caso mostraram que mesmo quando um teste atinge 95% de significância estatística ou mais - mesmo quando está sendo executado por um mês inteiro - os resultados podem enganar.
Tome Chase, por exemplo, que testou duas páginas de vendas de formato longo para uma de suas empresas. Em suas palavras:
No início, a versão original superou a variável. Fiquei surpreso com isso porque achei a variável melhor e mais bem escrita e projetada.
Na verdade, a variável era melhor do que a original, como os instintos de Chase haviam indicado. Mas foi somente após 6 meses de testes que ele apareceu. Naquela época, a taxa de conversão da página original não só havia regredido em direção à média, mas passado, a ponto de ser superada pela variável:

Então, o que queremos dizer com “regredido à média”?
Em termos de teste A / B, isso significa que a variação de alta conversão (neste caso, a página original representada pela linha azul no gráfico) começou a ter um desempenho mais próximo da média esperada conforme mais amostras eram coletadas. Em termos ainda mais claros, é outra maneira de dizer "as coisas ficam uniformes com o tempo".
Considere um exemplo do mundo real. No Torneio Internacional Martini de 1971, o jogador de golfe inglês John Anthony Hudson se tornou a única pessoa a acertar dois buracos em um consecutivos em um torneio profissional.
Em dois buracos, um par 4 e um par 3, ele atirou 2 - 5 tacadas combinadas melhor do que a média de 7 que leva a maioria dos profissionais.
Se olharmos apenas esses dois buracos para comparar seu desempenho com o dos outros participantes do torneio, diríamos “Uau, Hudson é muito melhor do que qualquer outro jogador de golfe no torneio. Ele com certeza vai ganhar. ”
E ele teria feito se eles convocassem o torneio com base apenas nesses dois buracos.
Mas os buracos em um são raros e os torneios duram muitos buracos. E assim, quanto mais Hudson tocava, mais sua pontuação regredia à média. No final da competição, ele foi amarrado para 9º lugar, longe de ganhar.
Da mesma forma, quanto mais dados você coletar, mesmo depois de atingir significância estatística, mais precisos serão seus resultados.
Você poderia marcar dois buracos em um convertendo os dois primeiros visitantes de sua variação de página de destino pós-clique? Absolutamente. Mas isso significa que sua nova página terá uma conversão de 100%? Sem chance. Em algum ponto, essa taxa de conversão de 100% regredirá em direção à média.
Lembre-se de que elevadores de conversão gigantes, como orifícios em um, são raros. A maioria dos testes bem-sucedidos produzirá elevadores menores e sustentáveis.
2. O efeito novidade
Digamos que você esteja testando uma variação de página de destino pós-clique com um botão laranja maior, quando todas as páginas de destino pós-clique até agora apresentam um pequeno botão verde. Inicialmente, você pode descobrir que o botão laranja maior produz mais conversões - mas o motivo pode não ser o resultado da mudança e, em vez disso, algo chamado de “efeito novidade”.
O efeito de novidade entra em ação quando você faz uma alteração que seu visitante típico não está acostumado a ver. A mudança na taxa de conversão é resultado da mudança da cor do botão? Ou é porque eles são atraídos pela novidade da mudança? Uma maneira de descobrir é segmentando seu tráfego.
Os visitantes que retornam estão acostumados a ver o pequeno botão verde, então o grande botão laranja pode atrair mais atenção simplesmente porque é diferente do que está acostumado. Mas os novos visitantes nunca viram seu pequeno botão verde, então se ele chamar a atenção deles , não será porque eles estão acostumados com algo diferente. Nesse caso, é mais provável que o botão laranja maior seja apenas mais atraente no geral.

Quando você testa algo muito diferente do que seu público está acostumado a ver, considere direcionar um novo tráfego para isso para garantir que o efeito de novidade não afete seus resultados.
3. O efeito da instrumentação
A ameaça mais comum à validade, chamada de “efeito da instrumentação (ou instrumento)”, tem a ver com sua ferramenta de teste. Está funcionando da maneira que deveria? Todo o seu código está implementado corretamente?
Não há truques para derrotar este fora da vigilância. Teste suas campanhas antes de irem ao ar, olhando para páginas de destino pós-clique e anúncios em diferentes navegadores e dispositivos. Insira os dados do lead de teste para ter certeza de que seus pixels de conversão estão disparando e seu CRM está sincronizado com seu formulário.
Quando eles forem ao ar, observe todas as métricas de perto e fique atento a relatórios suspeitos. Sua ferramenta pode estar falhando, você pode estar conduzindo um tráfego ruim ou pode ser vítima da próxima ameaça de validade….
4. O efeito histórico
Seu teste A / B não está sendo administrado em um laboratório. Está sendo executado no mundo real e, como resultado, é afetado por eventos do mundo real fora do seu controle. Podem ser feriados, clima, falhas no servidor e até mesmo data e hora.
O que acontece se você estiver testando o tráfego do Twitter e o site ficar offline? E se você testar uma página de destino pós-clique de varejo antes do Natal e, em seguida, executar um teste de acompanhamento em fevereiro?
Seus dados serão distorcidos.
Faça este teste da MarketingExperiments, por exemplo, que teve como objetivo otimizar o click-through de anúncios nas páginas de resultados de buscadores. O destino era um site de registro de criminosos sexuais que permitiria aos visitantes procurar predadores em sua área.
Nele, quatro anúncios com texto idêntico, mas diferentes títulos foram testados uns contra os outros.
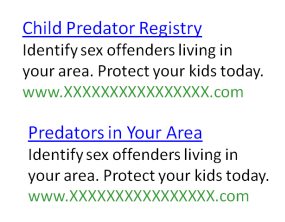
O teste foi chamado após 7 dias e 55.000 impressões e, à primeira vista, parecia que o vencedor era claro. Mas, após uma inspeção mais detalhada, os testadores notaram algo que envenenou seus dados. Dr. Flint McGlaughlin elabora:
“Aqui está o problema. Durante o teste, o Dateline exibiu um especial chamado 'To Catch a Predator'. Foi visto por 10 milhões de pessoas. As palavras predador tornaram-se o termo-chave associado ao agressor sexual. Agora, vamos voltar.
Você vê que seu filho está seguro. Você pode encontrar predador infantil, predadores em sua área e registro de predador infantil. E então, olhe na cópia. Identifique criminosos sexuais, identifique criminosos sexuais. Todos iguais, exceto pelo título, mas temos três desses títulos com a palavra predador neles. Qual foi o resultado? ”

As manchetes com a palavra “predador” tiveram uma taxa de cliques 133% maior do que aquelas sem ela - tudo por causa de um especial de TV.
Para combater o efeito histórico, use uma ferramenta de monitoramento de mídia e certifique-se de que todos em sua empresa saibam que você está testando. Quanto mais membros da equipe você acessa o mundo exterior, mais provável é que um de vocês identifique algo que pode impactar os resultados do seu teste.
5. O efeito de seleção
O efeito de seleção ocorre quando um experimentador testa uma amostra de assuntos que não é representativa do público-alvo.
Por exemplo, digamos que quiséssemos descobrir qual time profissional de futebol era o mais popular nos Estados Unidos, mas perguntamos apenas a pessoas da região da Nova Inglaterra. Provavelmente ouviríamos um apoio esmagador aos Patriotas, o que não seria representativo de todo o país.
Em termos de teste A / B, o efeito da seleção pode ter um impacto em seu teste quando você gera tráfego de fontes diferentes. É algo que Nick Usborne, da MarketingExperiments, encontrou ao trabalhar com uma grande editora de notícias:
“Tínhamos redesenhado radicalmente seu processo de oferta de assinatura para a versão eletrônica e estávamos no meio de um teste quando eles lançaram uma nova campanha de anúncio de link de texto de seu site principal para o produto eletrônico.
Isso mudou o mix de tráfego que chegava ao processo de oferta de assinatura de um em que praticamente todo o tráfego vinha de mecanismos de pesquisa pagos para um em que muito tráfego vinha de um link interno para seu site (tráfego altamente pré-qualificado).
A taxa de conversão média aumentou durante a noite de 0,26% para mais de 2%. Se não estivéssemos monitorando de perto, poderíamos ter concluído que o novo processo alcançou um aumento de 600% + na taxa de conversão. ”
Ficar de olho em seus clientes é importante, mas tão importante quanto garantir que você está projetando seu teste de uma forma que não o torne vulnerável ao efeito da seleção. Saiba de onde vem seu tráfego e não altere as origens no meio de um teste. Sua amostra deve permanecer o mais consistente possível o tempo todo.
Quando você pode terminar um teste A / B com segurança?
Se você não pode confiar na significância estatística e todas essas ameaças à validade podem potencialmente envenenar seus dados, então ... quando você pode encerrar seu teste com segurança e confiar nos resultados?
A infeliz resposta é que você nunca pode ter certeza de que seus resultados são 100% confiáveis. Você pode, no entanto, tomar precauções para ter certeza de chegar o mais perto possível. O Otimizador de Taxa de Conversão, Peep Laja, descobre que seguir esses 4 critérios geralmente resolve:
- A duração do teste deve ser de no mínimo 3 semanas, 4 se possível.
- O tamanho da amostra deve ser calculado de antemão, usando várias ferramentas.
- As conversões devem atingir entre 250 e 400 para cada variação que você está testando.
- A significância estatística deve ser de no mínimo 95%.
Ele acrescenta que, se você não atingir 250-400 conversões em 3 semanas, deverá continuar a executar o teste até atingir. E se você precisar, certifique-se de que está testando em ciclos de uma semana inteira. Se você iniciar o teste em uma segunda-feira e atingir 400 conversões 5 semanas depois em uma quarta-feira, continue testando até a segunda-feira seguinte (caso contrário, você pode se tornar vítima do efeito histórico).
Não se esqueça de ficar atento às ameaças de validade acima e avise a todos em sua equipe (e a equipe de seu cliente) que você está testando. Quanto mais você informa sobre sua organização, menos provável que alguém altere um aspecto do teste (efeito de seleção) e mais provável que alguém perceba quando uma ameaça de validade, como o efeito de instrumentação ou o efeito de histórico, entra em ação.
Como você melhorou seu site com os testes A / B?
Use o teste A / B para otimizar seu site e detectar quaisquer ameaças à validade. Comece criando páginas pós-clique, solicite uma demonstração Instapage Enterprise hoje.