
5 menaces courantes pour la validité de votre test A/B
Publié: 2016-11-17Mauvaise nouvelle : cette conversion de 30 % a augmenté votre dernier test A/B ? Ce n'est probablement pas aussi élevé que vous le pensiez.
En fait, il y a une chance qu'il n'existe pas du tout.
"Au moins 80 % des tests gagnants ne valent rien", écrit le responsable de la recherche Qubit, Martin Goodson, dans un livre blanc de l'entreprise. Ceux qui ne le sont généralement pas apportent de petits ascenseurs durables au lieu de ceux géants que vous voyez diffusés partout sur le Web.
Alors pourquoi votre logiciel de test A/B vous dit le contraire ?
Parce qu'il ne peut pas détecter les nombreuses menaces invisibles à la validité qui ont le potentiel d'empoisonner vos données. Des concepts tels que l'effet de nouveauté, la régression vers la moyenne, l'effet d'instrumentation et autres, peuvent tous vous faire voir de grandes augmentations de conversion là où il n'y en a pas.
Donc, si vous prenez des décisions commerciales sur la base de vos tests A/B simplement parce qu'ils ont atteint une signification statistique, arrêtez-vous maintenant. Vous devez atteindre une signification statistique avant de pouvoir faire des inférences en fonction de vos résultats, mais ce n'est pas tout ce dont vous avez besoin. Vous devez également exécuter un test valide.
Cliquez pour tweeter
La différence entre la signification statistique et la validité
La signification et la validité statistiques sont deux nécessités très différentes mais tout aussi importantes pour exécuter des tests fractionnés réussis.
La signification statistique indique, à un degré de confiance, la probabilité que vos résultats de test soient fiables et non dus au hasard. Pour atteindre la signification statistique, vous devez savoir :
- Le taux de conversion de référence de votre page de contrôle
- La variation minimale du taux de conversion que vous souhaitez pouvoir détecter
- Dans quelle mesure vous voulez être sûr que vos résultats sont significatifs et non dus au hasard (le niveau de confiance standard accepté est de 95 %)
- La taille de votre échantillon, c'est-à-dire la quantité de trafic que vous devez générer avant de pouvoir atteindre une signification statistique (utilisez cette calculatrice pour le déterminer)
La validité, d'autre part, a à voir avec le fait que d'autres facteurs en dehors de la taille de l'échantillon affectent négativement vos données.
Alors pourquoi avez-vous besoin de connaître les deux ?
Parce que même 53 % des tests A/A (même page par rapport aux mêmes tests utilisés pour évaluer la configuration de votre expérience) atteindront 95 % de signification à un moment donné. Si les tests comportant deux pages identiques peuvent atteindre une signification statistique ½ du temps, comment pouvez-vous être sûr que les résultats de vos tests A/B sont fiables ?
Vous ne pouvez pas, explique Peep Laja de CXL :
« Si vous arrêtez votre test dès que vous voyez une signification, il y a 50 % de chances que ce soit un coup de chance. Un tirage au sort. Tue totalement l'idée de tester en premier lieu.
Au lieu de vous fier uniquement à la signification statistique pour déterminer le gagnant d'un test fractionné, vous devez collecter autant de données valides que possible. Et pour ce faire, vous devez comprendre quel type de menaces se dresse sur votre chemin.
Menaces courantes pour la validité des tests A/B
1. Régression vers la moyenne
« La taille de l'échantillon est primordiale lorsqu'il s'agit de tests A/B », déclare Chase Dumont, spécialiste du marketing numérique. Plus vous testez de personnes, plus vos résultats deviennent précis.
Trop souvent, les testeurs A/B terminent prématurément leurs expérimentations. Ils sont excités lorsqu'ils voient un grand ascenseur et déclarent avec confiance un gagnant. Mais, des études de cas ont montré que même lorsqu'un test atteint 95 % de signification statistique ou plus, même s'il a duré un mois complet, les résultats peuvent être trompeurs.
Prenez Chase, par exemple, qui a testé deux pages de vente détaillées pour l'une de ses entreprises. Dans ses mots :
Au début, la version originale surpassait la variable. J'ai été surpris par cela parce que je pensais que la variable était meilleure et plus étroitement écrite et conçue.
En effet, la variable était meilleure que l'originale, comme l'avait indiqué l'instinct de Chase. Mais ce n'est qu'après 6 mois d'essais que cela s'est révélé. À ce moment-là, le taux de conversion de la page d'origine avait non seulement régressé vers la moyenne, mais l'avait dépassé, au point d'être dépassé par la variable :

Alors, qu'entendons-nous par « régressé à la moyenne » ?
En termes de test A/B, cela signifie que la variation à conversion élevée (dans ce cas, la page d'origine représentée par la ligne bleue sur le graphique) a commencé à se rapprocher de la moyenne attendue à mesure que davantage d'échantillons étaient collectés. En termes encore plus clairs, c'est une autre façon de dire « les choses s'améliorent avec le temps ».
Prenons un exemple du monde réel. Lors du tournoi international Martini de 1971, le golfeur anglais John Anthony Hudson est devenu la seule personne à avoir réussi deux trous consécutifs lors d'un tournoi professionnel.
Sur deux trous, un par 4 et un par 3, il a tiré un combiné de 2 à 5 coups mieux que la moyenne de 7 qu'il faut à la plupart des professionnels.
Si nous ne regardions que ces deux trous pour comparer sa performance à celle des autres participants au tournoi, nous dirions « Wow, Hudson est bien meilleur que n'importe quel autre golfeur du tournoi. Il est sûr de gagner.
Et il l'aurait fait s'ils avaient appelé le tournoi en se basant uniquement sur ces deux trous.
Mais les trous en un sont rares et les tournois durent de nombreux trous. Et donc plus Hudson jouait, plus son score régressait vers la moyenne. Il a été attaché à la fin de la compétition, pour la 9e place, loin de gagner.
De la même manière, plus vous collectez de données même après avoir atteint la signification statistique, plus vos résultats seront précis.
Pourriez-vous marquer deux trous en un en convertissant les deux premiers visiteurs de votre variante de page de destination post-clic ? Absolument. Mais cela signifie-t-il que votre nouvelle page va être convertie à 100 % ? Certainement pas. À un moment donné, ce taux de conversion de 100 % régressera vers la moyenne.
N'oubliez pas que les ascenseurs de conversion géants, comme les trous en un, sont rares. La majorité des tests réussis vont plutôt produire des ascenseurs plus petits et durables.
2. L'effet nouveauté
Disons que vous testez une variante de page de destination post-clic avec un bouton orange plus gros lorsque toutes vos pages de destination post-clic jusqu'à présent ont présenté un petit vert. Au départ, vous constaterez peut-être que le plus gros bouton orange produit plus de conversions - mais la raison n'est peut-être pas le résultat du changement, mais plutôt quelque chose appelé "l'effet de nouveauté".
L'effet de nouveauté entre en jeu lorsque vous effectuez une modification que votre visiteur type n'est pas habitué à voir. Le changement de taux de conversion est-il le résultat d'un changement de couleur du bouton ? Ou est-ce parce qu'ils sont attirés par la nouveauté du changement ? Une façon de comprendre est de segmenter votre trafic.
Les visiteurs qui reviennent sont habitués à voir le petit bouton vert, de sorte que le gros bouton orange peut attirer plus d'attention simplement parce qu'il est différent de ce à quoi ils sont habitués. Mais les nouveaux visiteurs n'ont jamais vu votre petit bouton vert, donc s'il attire leur attention, ce ne sera pas parce qu'ils sont habitués à quelque chose de différent. Dans ce cas, il est plus probable que le plus gros bouton orange soit globalement plus accrocheur.

Lorsque vous testez quelque chose de très différent de ce que votre public a l'habitude de voir, envisagez de générer un nouveau trafic pour vous assurer que l'effet de nouveauté n'affecte pas vos résultats.
3. L'effet instrumentation
La menace la plus courante pour la validité, appelée « l'effet instrumentation (ou instrument) », a à voir avec votre outil de test. Fonctionne-t-il comme il se doit ? Tout votre code est-il implémenté correctement ?
Il n'y a pas d'astuces pour battre celui-ci en dehors de la vigilance. Testez vos campagnes avant leur mise en ligne en consultant les pages de destination post-clic et les annonces sur différents navigateurs et appareils. Saisissez les données des pistes de test pour vous assurer que vos pixels de conversion se déclenchent et que votre CRM est synchronisé avec votre formulaire.
Lorsqu'ils sont mis en ligne, surveillez attentivement chaque métrique et gardez un œil sur les rapports suspects. Votre outil pourrait vous faire défaut, vous pourriez générer un mauvais trafic ou vous pourriez être victime de la prochaine menace de validité….
4. L'effet historique
Votre test A/B n'est pas administré dans un laboratoire. Il fonctionne dans le monde réel et, par conséquent, il est affecté par des événements du monde réel hors de votre contrôle. Il peut s'agir de jours fériés, de météo, de pannes de serveur et même de date et d'heure.
Que se passe-t-il si vous testez le trafic de Twitter et que le site se déconnecte ? Et si vous testiez une page de destination post-clic de vente au détail avant Noël, puis exécutiez un test de suivi en février ?
Vos données vont être faussées.
Prenez ce test de MarketingExperiments, par exemple, qui visait à optimiser le clic des annonces sur les pages de résultats des moteurs de recherche. La destination était un site Web d'enregistrement des délinquants sexuels qui permettrait aux visiteurs de rechercher des prédateurs dans leur région.
Dans ce document, quatre annonces avec un corps de texte identique mais des titres différents ont été testées les unes contre les autres.
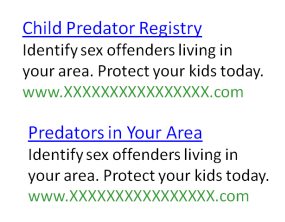
Le test a été lancé après 7 jours et 55 000 impressions, et à première vue, il semblait que le gagnant était clair. Mais, en y regardant de plus près, les testeurs ont remarqué quelque chose qui a empoisonné leurs données. Le Dr Flint McGlaughlin précise :
« Voici le problème. Pendant le test, Dateline a diffusé une émission spéciale intitulée "Pour attraper un prédateur". Il a été vu par 10 millions de personnes. Les mots prédateur sont devenus le terme clé associé au délinquant sexuel. Maintenant, revenons en arrière.
Vous voyez que votre enfant est en sécurité. Vous voyez trouver un prédateur d'enfants, des prédateurs dans votre région et un registre des prédateurs d'enfants. Et puis, regardez dans la copie. Identifier les délinquants sexuels, identifier les délinquants sexuels. Tout de même à l'exception du titre, mais nous avons trois de ces titres avec le mot prédateur dedans. Quel a été le résultat ?

Les titres avec le mot "prédateur" ont eu un taux de clics 133% plus élevé que ceux qui n'en ont pas, tout cela à cause d'un spécial télévisé.
Pour lutter contre l'effet historique, utilisez un outil de surveillance des médias et assurez-vous que tout le monde dans votre entreprise sait que vous testez. Plus vous avez de membres de l'équipe connectés au monde extérieur, plus il est probable que l'un d'entre vous remarque quelque chose qui pourrait avoir un impact sur les résultats de votre test.
5. L'effet de sélection
L'effet de sélection se produit lorsqu'un expérimentateur teste un échantillon de sujets qui n'est pas représentatif du public cible.
Par exemple, disons que nous voulions savoir quelle équipe de football professionnel était la plus populaire aux États-Unis, mais nous n'avons interrogé que des personnes de la région de la Nouvelle-Angleterre. Nous entendrions probablement un soutien écrasant pour les Patriots, qui ne serait pas représentatif de l'ensemble du pays.
En termes de test A/B, l'effet de sélection peut avoir un impact sur votre test lorsque vous générez du trafic à partir de différentes sources. C'est quelque chose que Nick Usborne de MarketingExperiments a rencontré lorsqu'il travaillait avec un grand éditeur d'actualités :
« Nous avions radicalement repensé leur processus d'offre d'abonnement pour la version électronique et étions en train de tester lorsqu'ils ont lancé une nouvelle campagne publicitaire de lien texte de leur site Web principal vers le produit électronique.
Cela a changé le mélange de trafic arrivant au processus d'offre d'abonnement d'un trafic où pratiquement tout le trafic provenait de moteurs de recherche payants à un trafic où une grande partie du trafic provenait d'un lien interne à leur site Web (trafic hautement pré-qualifié).
Le taux de conversion moyen est passé du jour au lendemain de 0,26 % à plus de 2 %. Si nous n'avions pas suivi de près, nous aurions pu conclure que le nouveau processus avait permis d'augmenter le taux de conversion de plus de 600 %. »
Garder un œil sur vos clients est important, mais il est tout aussi crucial de vous assurer que vous concevez votre test d'une manière qui ne le rend pas vulnérable à l'effet de sélection. Sachez d'où vient votre trafic et ne modifiez pas les sources au milieu d'un test. Votre échantillon doit rester aussi cohérent que possible tout au long.
Quand pouvez-vous terminer un test A/B en toute sécurité ?
Si vous ne pouvez pas faire confiance à la signification statistique et que toutes ces menaces à la validité peuvent potentiellement empoisonner vos données, alors… quand pouvez-vous terminer votre test en toute sécurité et vous fier aux résultats en toute confiance ?
La réponse malheureuse est que vous ne pouvez jamais vraiment être sûr que vos résultats sont fiables à 100 %. Vous pouvez cependant prendre des précautions pour vous rapprocher le plus possible. L'optimiseur de taux de conversion, Peep Laja, constate que ces 4 critères font généralement l'affaire :
- La durée du test doit être de 3 semaines minimum, 4 si possible.
- La taille de l'échantillon doit être calculée au préalable à l'aide de plusieurs outils.
- Les conversions doivent atteindre entre 250 et 400 pour chaque variante que vous testez.
- La signification statistique doit être de 95 % minimum.
Il ajoute que si vous n'atteignez pas 250 à 400 conversions en 3 semaines, vous devez continuer à exécuter le test jusqu'à ce que vous y parveniez. Et si vous en avez besoin, assurez-vous de tester par cycles d'une semaine complète. Si vous commencez le test un lundi et que vous atteignez 400 conversions 5 semaines plus tard un mercredi, continuez le test jusqu'au lundi suivant (sinon, vous pourriez vous retrouver victime de l'effet historique).
N'oubliez pas de faire attention aux menaces de validité ci-dessus et informez tous les membres de votre équipe (et l'équipe de votre client) que vous effectuez un test. Plus vous informez votre organisation, moins il est probable que quelqu'un modifie un aspect du test (effet de sélection) et plus il est probable que quelqu'un remarque quand une menace de validité comme l'effet d'instrumentation ou l'effet d'historique entre en jeu.
Comment avez-vous amélioré votre site Web avec les tests A/B ?
Utilisez les tests A/B pour optimiser votre site Web et détecter toute menace à la validité. Commencez par créer des pages post-clic, demandez une démo Instapage Enterprise dès aujourd'hui.