
Korzystanie z regresji programu Excel w celu lepszego zrozumienia wskaźników KPI
Opublikowany: 2021-10-23Grupa z nas tutaj w Hanapin niedawno wzięła udział w bezpłatnym 21-dniowym kursie Excela prowadzonym przez znanego eksperta Microsoft Excel, dr. Wayne'a Winstona. Sam kurs początkowo wydawał się powolny, ale ostatecznie ujawnił kilka możliwości programu Excel, których nigdy nie znałem. Najbardziej ekscytującą z nich jest dla mnie zdolność do regresji wielu zmiennych bez zaawansowanego oprogramowania statystycznego (takiego jak STATA). W tym poście przedstawię krok po kroku konfigurowanie i uruchamianie regresji w programie Excel oraz sposób, w jaki to narzędzie może pomóc w analizach PPC i zarządzaniu kontem.
Przepraszam, cofam się
Zanim zagłębimy się w implementację techniczną, możesz się zastanawiać: „Czym u licha jest regresja?” Krótko mówiąc, regresje przyglądają się związkom między zmiennymi. W przypadku dowolnej zmiennej zależnej („Y”), jaki zestaw zmiennych niezależnych („X”) przyczynia się do zmiany Y i ile z tego zachowania wyjaśnia model regresji? (Zobacz tutaj, aby uzyskać szczegółowy przegląd analiz regresji)
Regresje liniowe (lub wielokrotne regresje liniowe) są najczęstsze, pasujące do zsumowanego równania postaci:
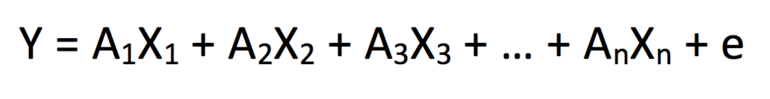
gdzie Y jest zmienną zależną, X 1 – X n reprezentują zbiór n zmiennych niezależnych, a A 1 – A n są stałymi współczynnikami odpowiadającymi X 1 – X n . Jest to podstawowe budowanie modeli statystycznych, dlatego zdajemy sobie sprawę, że będzie pewna niespójność między naszymi przewidywanymi i obserwowanymi wynikami dla każdej iteracji „y”. W związku z tym dodano termin błędu „+ e”, aby uwzględnić taką wariancję.
Dlaczego regres w PPC?
Regresje można stosować w dowolnej liczbie analiz. Możesz na przykład zastanowić się, jaki wpływ zmiany stawek CPC na śr. Pozycja, utracony udział w wyświetleniach lub Wynik Jakości. Możesz sprawdzić, który element (oczekiwany CTR, jakość strony docelowej lub trafność reklamy) ma największy wpływ na Wynik Jakości na poziomie konta, kampanii lub słowa kluczowego. Być może, jak zobaczymy w poniższym przykładzie, chcesz odkryć rolę, jaką CPC w sieci wyszukiwania i reklamowej oraz współczynniki konwersji odgrywają w ogólnym CPA Twojego konta.
Niezależnie od tego, jaki jest twój cel końcowy, proces konfigurowania i określania wartości modelu regresji jest taki sam.
Krok 1: Przygotuj swoje dane
Jak w przypadku każdej analizy, dobry wynik wymaga wysokiej jakości danych, które zostały prawidłowo przygotowane. Aby uzyskać dobre wyniki regresji, potrzebujesz wystarczającej ilości danych (co najmniej tyle punktów danych, ile jest zmiennych niezależnych, ale im więcej dostępnych danych, tym dokładniejszy może być Twój model regresji). Aby zwiększyć liczbę punktów danych, możesz rozważyć segmentację danych według dnia, tygodnia lub miesiąca (w zależności od badanego przedziału czasowego).
W naszym przykładzie w AdWords wykorzystujemy dane z ostatnich 24 miesięcy. Po pobraniu raportu kampanii (podzielonego na segmenty według miesiąca) tworzymy tabelę przestawną w celu zbadania kliknięć, kosztu i konwersji według miesiąca i typu kampanii:

Stąd możemy obliczyć CPA, CPC i CVR dla każdej sieci, a także całkowity CPA. Następnie wystarczy jedno szybkie skopiowanie i wklejenie danych do nowego arkusza, jesteśmy gotowi do rozpoczęcia regresji!
Krok 2: Zbuduj swój model (wybór zmiennych)
Budowanie modelu składa się z dwóch głównych elementów: przemyślanego planowania i elastycznej wersji. Przemyślane planowanie polega na rozważeniu, które zmienne najlepiej pasują do modelu (i jakie dane są dostępne do użycia). Poświęcenie trochę więcej czasu na etapie planowania może zaoszczędzić czas i zdrowie psychiczne w późniejszym czasie podczas testowania i ponownego testowania modelu. Nawet przy starannym przygotowaniu nadal może być konieczne elastyczne korygowanie modelu w miarę cofania się i identyfikowania zmiennych, które są istotne, a nie ważne.
Dwie ważne uwagi przy wyborze zmiennych niezależnych:
- Zmienne niezależne powinny mieć możliwy do wyobrażenia, logiczny związek ze zmienną zależną (np. średnia ilość opadów w Tokio i liczba zawałów serca w Wisconsin byłaby niska na mojej liście korelacji do zbadania)
- Zmienne niezależne nie powinny być ze sobą silnie skorelowane (tj. uwzględnienie kosztu, kliknięć i CPC jako zmiennych niezależnych w ramach tej samej regresji spowodowałoby błąd współliniowości w modelu)
W naszym przykładzie chcemy sprawdzić, co wpływa na CPA naszego konta. Wiemy, że są dwie sieci, w których wyświetlamy reklamy w Adwords – w sieci wyszukiwania i reklamowej – i wiemy, że dwie główne zmienne decydujące o CPA (koszt/konwersja) dla każdej sieci to CPC (koszt/kliknięcie) i CVR (konwersja/kliknięcie ).

Dlatego zaczniemy od oddzielnej regresji CPA dla CPC i CVR dla sieci wyszukiwania i reklamowej, aby określić, które zmienne niezależne są istotne i dlatego powinny zostać uwzględnione w naszym ostatecznym modelu.
Krok 3: Cofnij się i zrewiduj
Aby uruchomić regresję w programie Excel:
1. Przed zainicjowaniem regresji w programie Excel najpierw sprawdź, czy zmienne niezależne (kolumny danych) sąsiadują ze sobą.
2. Następnie potwierdź, że dodatek „Analysis ToolPak” jest włączony dla programu Excel (widoczny na wstążce „Dane” po włączeniu).
3. W przyborniku analizy danych wybierz „Regresja”.
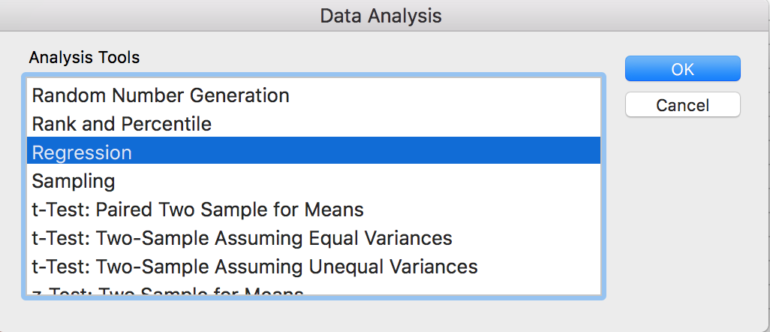
4. Wprowadź zakres zmiennej zależnej (Y) i zakres zmiennych niezależnych (X), wybierając „Etykiety”, jeśli zdecydujesz się uwzględnić nagłówki kolumn
5. Wybierz miejsce docelowe wyniku regresji (nowy lub istniejący arkusz)
6. Wybierz „resztki”, jeśli chcesz sprawdzić i usunąć wartości odstające z danych
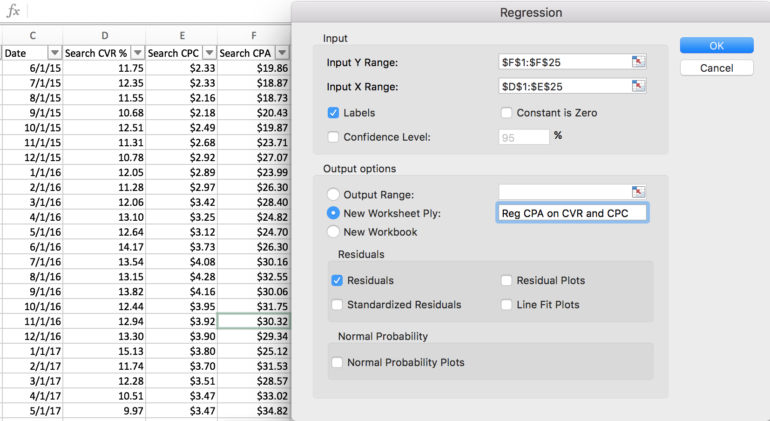
7. Kliknij „OK”, aby uruchomić regresję. Zostaniesz automatycznie przekierowany do arkusza zawierającego podsumowanie i szczegóły wyników.
8. Jeśli badanie danych wyjściowych regresji ujawni nieistotne zmienne niezależne (zazwyczaj wartości p są większe niż 0,1) lub R-kwadrat niższy niż oczekiwany (patrz „A” poniżej), możesz powtórzyć proces w razie potrzeby, aby udoskonalić model.
Krok 4: Zrozumienie wyników
Spojrzenie po raz pierwszy na podsumowanie może być onieśmielające i zniechęcające. Aby to ułatwić, poniżej wyróżniono kluczowe sekcje danych wyjściowych, które pomogą Ci ocenić model, który właśnie zbudowałeś.

(A) Kwadrat R i Dopasowany kwadrat R: Jest to miara tego, jak dobrze Twój model „dopasowuje” dane. Krótko mówiąc, R Square mówi, jaka część zmienności zmiennej zależnej jest wyjaśniona przez wybrane zmienne niezależne. Skorygowany kwadrat R jest zasadniczo taki sam, ale uwzględnia również liczbę uwzględnionych zmiennych niezależnych, zapewniając nieco dokładniejszy pomiar. (Nie ma czegoś takiego jak „dobry” lub „właściwy” kwadrat R, ponieważ zależy to od typu modelu i danych, których używasz, ale im wyższy, tym lepiej).
(B) Błąd standardowy: Pierwiastek kwadratowy z sumy kwadratów różnic między wynikami przewidywanymi a rzeczywistymi. W przypadku rozkładu normalnego około 65% reszt (patrz „E” poniżej) będzie mniejsze niż jeden błąd standardowy, a 95% będzie mniejsze niż 2. Reszty większe niż dwukrotność błędu standardowego są zwykle oznaczane w danych jako wartości odstające.
(C) Współczynniki zmiennych niezależnych: Współczynniki to terminy „A” we wzorze regresji. Zatem w tym przykładzie wzrost CPC o 1 jednostkę powinien równać się wzrostowi CPA o 8,4 (zakładając, że CVR pozostaje stały).
(D) Wartość P zmiennych niezależnych: W kategoriach laika wartość P mówi o znaczeniu zmiennej niezależnej. Niskie wartości P są istotne (dążąc do mniej niż 0,1), podczas gdy wysokie wartości P wskazują, że postrzegana korelacja może być czystym przypadkiem. Zmienne niezależne o wysokich wartościach P należy wykluczyć na etapie „elastycznej weryfikacji”.
(E) Reszty: Pokazuje różnicę między przewidywaną wartością zmiennej zależnej dla każdej iteracji a rzeczywistą zarejestrowaną wartością. Jak wspomniano powyżej, większość reszt powinna być mniejsza niż 1 błąd standardowy, a prawie wszystkie powinny być mniejsze niż wartość 2 * błąd standardowy. Możesz zdecydować, czy uwzględnić lub wykluczyć wszelkie zidentyfikowane wartości odstające (reszty większe niż dwukrotność błędu standardowego) z modelu.
Krok 5: Składanie wszystkiego (część na wynos!)
Po przeprowadzeniu trzech regresji znaleźliśmy następujące trzy równania łączące CPC i CVR w sieci wyszukiwania i reklamowej oraz CVR w sieci i całkowity CPA:



Te równania weryfikują to, co już wiedzieliśmy (lub myśleliśmy, że wiemy): że CPC i CVR w sieci wyszukiwania i reklamowej oraz CVR odgrywają znaczącą rolę w zachowaniu naszego całkowitego CPA. Poza tym ujawnili jednak również 3 rzeczy, których standardowa mapa cieplna nie byłaby.
- Wzrost CPC w sieci wyszukiwania ma 3,5-krotny wpływ na CPA w sieci wyszukiwania niż równoważny wzrost CVR w sieci wyszukiwania
- Wahania CPC w sieci reklamowej mają prawie pięciokrotnie większy wpływ CVR w sieci reklamowej na CPA w sieci reklamowej
- Ogólnie rzecz biorąc, zmiany w wydajności sieci reklamowej mają większy wpływ na całkowity CPA niż zmiany o podobnej wielkości w wydajności sieci wyszukiwania
Wynika z tego jasno, że CPC w sieci reklamowej jest celem nr 1 optymalizacji, jeśli zamierzam obniżyć całkowity CPA. CPC w sieci wyszukiwania i CVR w sieci reklamowej są następne, a CVR w sieci wyszukiwania to najmniej z moich priorytetów.
Regresje są potężnym narzędziem i doskonałym dodatkiem do paska narzędzi Menedżera PPC. Ten podstawowy przykład pokazuje tylko jeden z wielu sposobów, w jakie regresje mogą pomóc w zrozumieniu relacji między ukochanymi wskaźnikami KPI. Mamy nadzieję, że przetestujesz lub będziesz nadal korzystać z funkcji regresji w programie Excel i podzielisz się z nami swoimi doświadczeniami/przemyśleniami/wnioskami na Twitterze!