
W jaki sposób Google wykorzystuje NLP, aby lepiej zrozumieć zapytania wyszukiwania, treść
Opublikowany: 2022-08-23Przetwarzanie języka naturalnego otworzyło drzwi do wyszukiwania semantycznego w Google.
SEO muszą zrozumieć przejście na wyszukiwanie oparte na jednostkach, ponieważ jest to przyszłość wyszukiwarki Google.
W tym artykule zagłębimy się w przetwarzanie języka naturalnego oraz sposób, w jaki Google używa go do interpretowania zapytań i treści wyszukiwania, eksploracji jednostek i nie tylko.
Co to jest przetwarzanie języka naturalnego?
Przetwarzanie języka naturalnego lub NLP umożliwia zrozumienie znaczenia słów, zdań i tekstów w celu wygenerowania informacji, wiedzy lub nowego tekstu.
Składa się z rozumienia języka naturalnego (NLU) – które umożliwia semantyczną interpretację tekstu i języka naturalnego – oraz generowania języka naturalnego (NLG).
NLP może być używany do:
- Rozpoznawanie mowy (z tekstu na mowę i mowy na tekst).
- Podział wcześniej przechwyconej mowy na pojedyncze słowa, zdania i frazy.
- Rozpoznawanie podstawowych form wyrazowych i przyswajanie informacji gramatycznej.
- Rozpoznawanie funkcji poszczególnych słów w zdaniu (podmiot, czasownik, dopełnienie, przedimek itp.)
- Wyodrębnianie znaczenia zdań i części zdań lub fraz, takich jak frazy przymiotnikowe (np. „za długo”), frazy przyimkowe (np. „do rzeki”) lub frazy nominalne (np. „długa impreza”).
- Rozpoznawanie kontekstów zdań, relacji zdań i bytów.
- Analiza językowa tekstu, analiza sentymentu, tłumaczenia (w tym dla asystentów głosowych), chatboty i podstawowe systemy pytań i odpowiedzi.
Oto podstawowe elementy NLP:
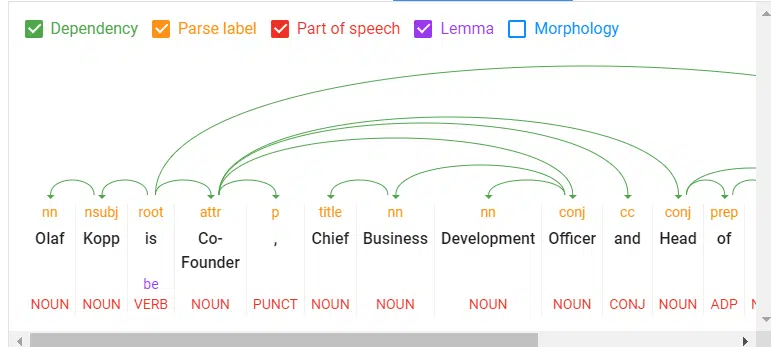
- Tokenizacja : dzieli zdanie na różne terminy.
- Etykietowanie typu słowa : klasyfikuje słowa według obiektu, podmiotu, predykatu, przymiotnika itp.
- Zależności słów : Identyfikuje relacje między słowami na podstawie reguł gramatycznych.
- Lematyzacja : Określa, czy słowo ma różne formy i normalizuje warianty formy podstawowej. Na przykład podstawową formą słowa „samochody” jest „samochód”.
- Parsing labels : Etykietuje słowa na podstawie relacji między dwoma słowami połączonymi zależnością.
- Analiza i wyodrębnianie nazwanych jednostek : Identyfikuje słowa o „znanym” znaczeniu i przypisuje je do klas typów jednostek. Ogólnie rzecz biorąc, nazwanymi jednostkami są organizacje, ludzie, produkty, miejsca i rzeczy (rzeczowniki). W zdaniu podmioty i przedmioty mają być identyfikowane jako byty.
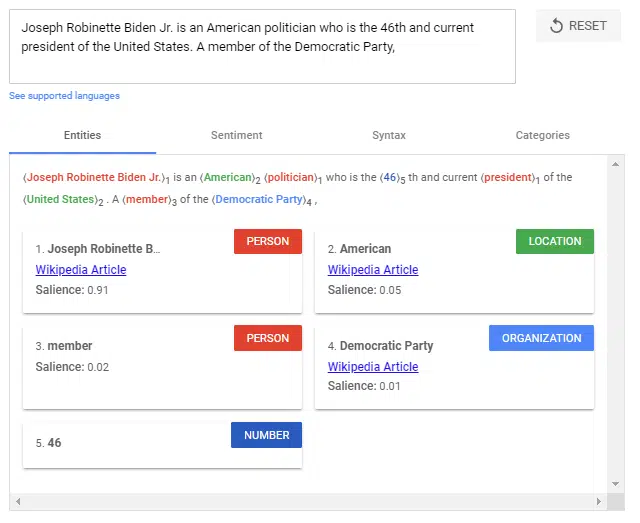
- Salience scoring : określa, jak intensywnie tekst jest powiązany z tematem. Istotność jest zazwyczaj określana przez współcytowanie słów w sieci i relacje między podmiotami w bazach danych, takich jak Wikipedia i Freebase. Doświadczeni SEO znają podobną metodę z analizy TF-IDF.
- Analiza sentymentu : Identyfikuje opinię (pogląd lub postawę) wyrażoną w tekście na temat podmiotów lub tematów.
- Kategoryzacja tekstu : na poziomie makr NLP klasyfikuje tekst na kategorie treści. Kategoryzacja tekstu pomaga ogólnie określić, o czym jest tekst.
- Klasyfikacja i funkcja tekstu : NLP może pójść dalej i określić zamierzoną funkcję lub cel treści. Bardzo interesujące jest dopasowanie intencji wyszukiwania do dokumentu.
- Wyodrębnianie typu treści : na podstawie wzorców strukturalnych lub kontekstu wyszukiwarka może określić typ treści tekstu bez danych strukturalnych. Kod HTML, formatowanie i typ danych tekstu (data, lokalizacja, adres URL itp.) pozwalają określić, czy jest to przepis, produkt, wydarzenie, czy inny typ zawartości bez używania znaczników.
- Identyfikuj niejawne znaczenie na podstawie struktury : formatowanie tekstu może zmienić jego dorozumiane znaczenie. Nagłówki, podziały wierszy, listy i bliskość przekazują wtórne rozumienie tekstu. Na przykład, gdy tekst jest wyświetlany na liście posortowanej w formacie HTML lub serii nagłówków z liczbami przed nimi, prawdopodobnie jest to lista lub ranking. Strukturę określają nie tylko znaczniki HTML, ale także wizualny rozmiar/grubość czcionki i bliskość podczas renderowania.
Wykorzystanie NLP w wyszukiwaniu
Od lat Google szkoli modele językowe, takie jak BERT lub MUM, do interpretacji tekstu, zapytań wyszukiwania, a nawet treści wideo i audio. Modele te są zasilane przez przetwarzanie języka naturalnego.
Wyszukiwarka Google wykorzystuje głównie przetwarzanie języka naturalnego w następujących obszarach:
- Interpretacja zapytań wyszukiwania.
- Klasyfikacja przedmiotu i celu dokumentów.
- Analiza podmiotów w dokumentach, zapytaniach wyszukiwania i postach w mediach społecznościowych.
- Do generowania polecanych fragmentów i odpowiedzi w wyszukiwaniu głosowym.
- Interpretacja treści wideo i audio.
- Rozbudowa i udoskonalenie Grafu Wiedzy.
Google podkreślił znaczenie zrozumienia języka naturalnego w wyszukiwarce, gdy w październiku 2019 r. opublikował aktualizację BERT.
„Sednem wyszukiwania jest zrozumienie języka. Naszym zadaniem jest zorientowanie się, czego szukasz i uzyskanie przydatnych informacji w sieci, bez względu na to, jak piszesz lub łączysz słowa w zapytaniu. Chociaż przez lata stale ulepszaliśmy nasze możliwości rozumienia języka, czasami wciąż nie do końca rozumiemy, zwłaszcza w przypadku złożonych lub konwersacyjnych zapytań. W rzeczywistości jest to jeden z powodów, dla których ludzie często używają „keyword-ese”, wpisując ciągi słów, które ich zdaniem zrozumiemy, ale w rzeczywistości nie są takie, jak naturalnie zadają pytanie”.
BERT & MUM: NLP do interpretacji zapytań wyszukiwania i dokumentów
Mówi się, że BERT jest najbardziej krytycznym postępem w wyszukiwarce Google w ciągu kilku lat po RankBrain. Oparta na NLP aktualizacja została zaprojektowana w celu poprawy interpretacji zapytań wyszukiwania i początkowo wpłynęła na 10% wszystkich zapytań wyszukiwania.
BERT odgrywa rolę nie tylko w interpretacji zapytań, ale także w rankingu i kompilacji wyróżnionych fragmentów, a także w interpretacji kwestionariuszy tekstowych w dokumentach.
„Cóż, stosując modele BERT zarówno do rankingu, jak i polecanych fragmentów w wyszukiwarce, jesteśmy w stanie wykonać znacznie lepszą pracę, pomagając Ci znaleźć przydatne informacje. W rzeczywistości, jeśli chodzi o wyniki rankingowe, BERT pomoże wyszukiwarce lepiej zrozumieć jedno na 10 wyszukiwań w USA w języku angielskim, a z czasem wprowadzimy to do większej liczby języków i lokalizacji”.
Wprowadzenie aktualizacji MUM zostało ogłoszone podczas Search On '21. Oparta również na NLP, MUM jest wielojęzyczna, odpowiada na złożone zapytania wyszukiwania danymi multimodalnymi i przetwarza informacje z różnych formatów mediów. Oprócz tekstu MUM rozumie również obrazy, pliki wideo i audio.
MUM łączy kilka technologii, aby wyszukiwania Google były jeszcze bardziej semantyczne i kontekstowe, aby poprawić wrażenia użytkownika.
Dzięki MUM Google chce odpowiadać na złożone zapytania wyszukiwania w różnych formatach mediów, aby dołączyć do użytkownika na ścieżce klienta.
Stosowany w BERT i MUM, NLP jest niezbędnym krokiem do lepszego zrozumienia semantyki i bardziej zorientowanej na użytkownika wyszukiwarki.
Zrozumienie zapytań wyszukiwania i treści za pośrednictwem podmiotów oznacza przejście od „ciągów” do „rzeczy”. Celem Google jest rozwinięcie semantycznego zrozumienia zapytań i treści wyszukiwania.
Identyfikując podmioty w zapytaniach wyszukiwania, znaczenie i zamiar wyszukiwania stają się jaśniejsze. Poszczególne słowa wyszukiwanego hasła nie są już samodzielne, ale są brane pod uwagę w kontekście całego zapytania.
Magia interpretacji wyszukiwanych haseł pojawia się podczas przetwarzania zapytań. Ważne są tutaj następujące kroki:
- Identyfikacja ontologii tematycznej, w której znajduje się zapytanie. Jeśli kontekst tematyczny jest jasny, Google może wybrać korpus treści zawierający dokumenty tekstowe, filmy i obrazy jako potencjalnie odpowiednie wyniki wyszukiwania. Jest to szczególnie trudne w przypadku niejednoznacznych wyszukiwanych haseł.
- Identyfikowanie jednostek i ich znaczenie w wyszukiwanym terminie (rozpoznawanie nazwanych jednostek).
- Zrozumienie semantycznego znaczenia zapytania wyszukiwania.
- Identyfikacja celu wyszukiwania.
- Adnotacja semantyczna zapytania.
- Doprecyzowanie wyszukiwanego hasła.

Otrzymuj codzienne newslettery, na których polegają marketerzy.
Zobacz warunki.
NLP to najważniejsza metodologia wydobywania podmiotów
Przetwarzanie języka naturalnego będzie odgrywać najważniejszą rolę dla Google w identyfikowaniu podmiotów i ich znaczeń, umożliwiając wydobywanie wiedzy z nieustrukturyzowanych danych.
Na tej podstawie można następnie tworzyć relacje między podmiotami a Grafem wiedzy. Tagowanie mowy częściowo w tym pomaga.
Rzeczowniki są potencjalnymi bytami, a czasowniki często reprezentują stosunek tych bytów do siebie. Przymiotniki opisują jednostkę, a przysłówki opisują relację.
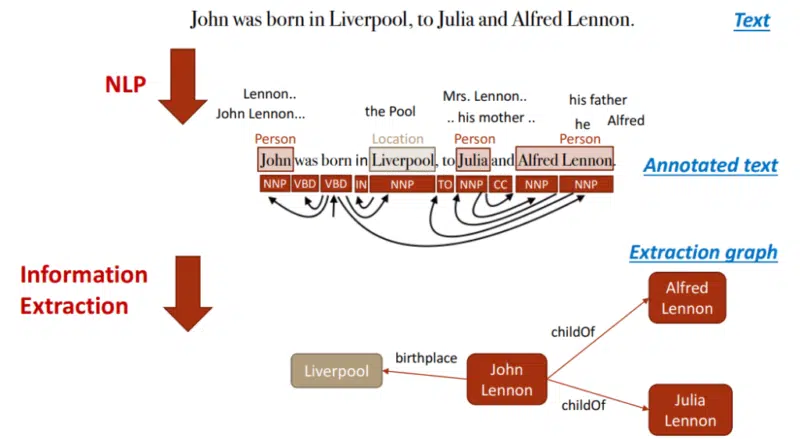
Do tej pory firma Google w minimalnym stopniu wykorzystywała nieustrukturyzowane informacje do przesyłania danych do Grafu wiedzy.
Można założyć, że:
- Jednostki zarejestrowane do tej pory na Grafie wiedzy to tylko wierzchołek góry lodowej.
- Google dodatkowo zasila kolejne repozytorium wiedzy informacjami o podmiotach z długim ogonem.
NLP odgrywa kluczową rolę w zasilaniu tego repozytorium wiedzy.
Google jest już całkiem dobry w NLP, ale nie osiąga jeszcze zadowalających wyników w ocenie automatycznie wyodrębnionych informacji dotyczących dokładności.
Eksploracja danych dla bazy wiedzy, takiej jak Wykres wiedzy, z danych nieustrukturyzowanych, takich jak witryny internetowe, jest złożona.
Oprócz kompletności informacji niezbędna jest poprawność. Obecnie Google gwarantuje kompletność na dużą skalę poprzez NLP, ale udowodnienie poprawności i dokładności jest trudne.
Zapewne dlatego Google nadal ostrożnie podchodzi do bezpośredniego pozycjonowania informacji o podmiotach typu long-tail w SERP.
Indeks encji a klasyczny indeks oparty na treści
Wprowadzenie aktualizacji Koliber utorowało drogę do wyszukiwania semantycznego. Skupiało się również na Grafie wiedzy – a tym samym na jednostkach.
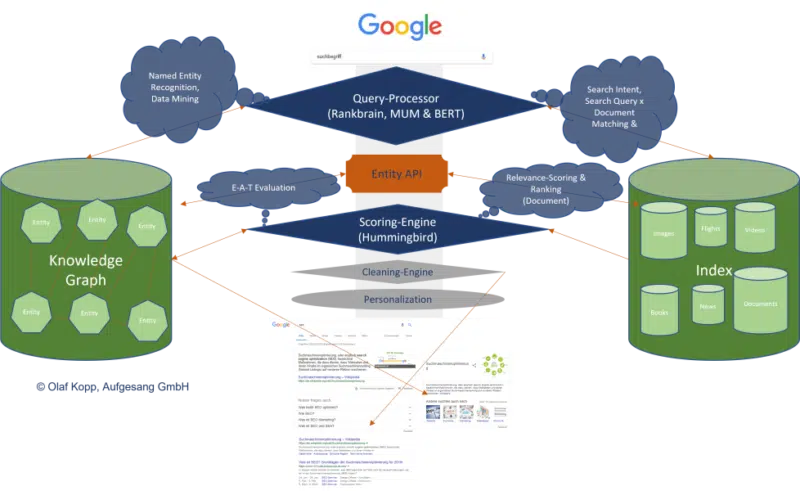
Graf wiedzy to indeks jednostek Google. Wszystkie atrybuty, dokumenty i obrazy cyfrowe, takie jak profile i domeny, są zorganizowane wokół jednostki w indeksie opartym na jednostce.
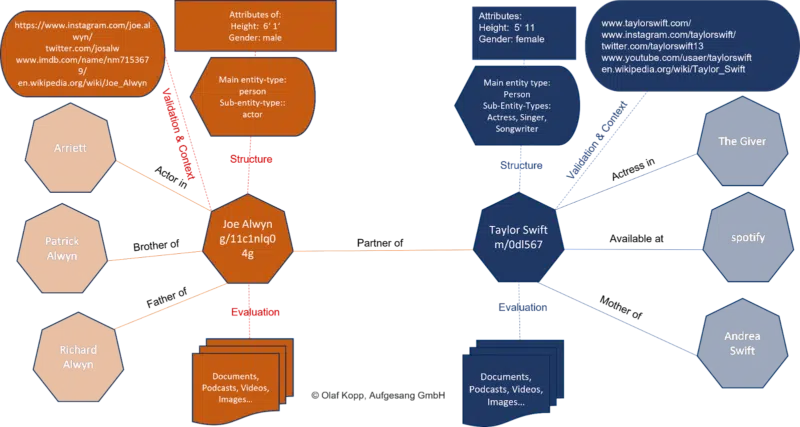
Graf wiedzy jest obecnie używany do rankingu równolegle z klasycznym indeksem Google.
Załóżmy, że Google rozpoznaje w zapytaniu, że chodzi o jednostkę zarejestrowaną w Grafie wiedzy. W takim przypadku uzyskuje się dostęp do informacji w obu indeksach, z podmiotem będącym w centrum uwagi i uwzględniane są również wszystkie informacje i dokumenty związane z podmiotem.
Do wymiany informacji między tymi dwoma indeksami wymagany jest interfejs lub interfejs API między klasycznym indeksem Google a Grafem wiedzy lub innym rodzajem repozytorium wiedzy.
Ten interfejs encji-treści służy do odkrywania:
- Czy w treści znajdują się encje.
- Czy istnieje główna jednostka, której dotyczy treść.
- Do jakiej ontologii lub ontologii można przypisać główny byt.
- Któremu autorowi lub jakiemu podmiotowi przypisano treść.
- Jak podmioty w treści odnoszą się do siebie.
- Jakie właściwości lub atrybuty mają być przypisane do jednostek.
Może to wyglądać tak:
Dopiero zaczynamy odczuwać wpływ wyszukiwania opartego na jednostkach w SERP, ponieważ Google powoli rozumie znaczenie poszczególnych jednostek.
Podmioty są rozumiane odgórnie przez znaczenie społeczne. Najistotniejsze z nich są zapisane odpowiednio w Wikidanych i Wikipedii.
Dużym zadaniem będzie identyfikacja i weryfikacja podmiotów typu long-tail. Nie jest również jasne, jakie kryteria sprawdza Google w celu uwzględnienia jednostki w Grafie wiedzy.
Na niemieckim Hangoucie dla webmasterów w styczniu 2019 r. John Mueller z Google powiedział, że pracują nad prostszym sposobem tworzenia podmiotów dla wszystkich.
„Nie sądzę, że mamy jasną odpowiedź. Myślę, że mamy różne algorytmy, które sprawdzają coś takiego, a następnie używamy różnych kryteriów, aby złożyć całość w całość, rozdzielić i rozpoznać, które rzeczy są naprawdę oddzielnymi bytami, które są tylko wariantami lub mniej oddzielnymi bytami… Ale o ile obawiam się, że to zauważyłem, pracujemy nad tym, aby to nieco rozszerzyć i wyobrażam sobie, że ułatwi to również wyróżnienie się na Grafie wiedzy. Ale nie wiem dokładnie, jakie są plany.
NLP odgrywa kluczową rolę w zwiększaniu skali tego wyzwania.
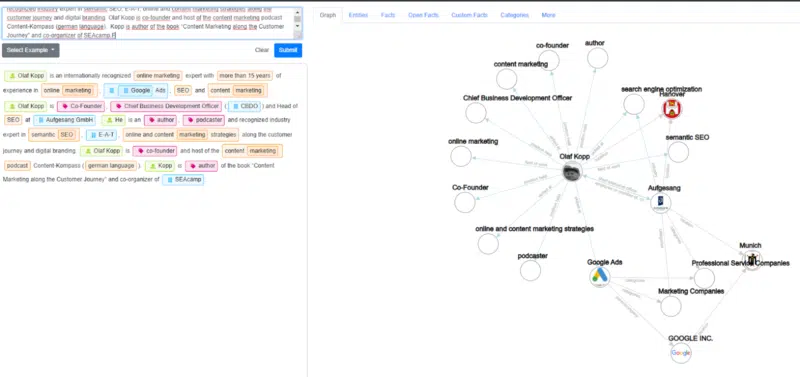
Przykłady z demo diffbota pokazują, jak dobrze NLP może być wykorzystane do wydobywania jednostek i konstruowania Grafu wiedzy.
NLP w wyszukiwarce Google zostanie na zawsze
RankBrain został wprowadzony w celu interpretacji zapytań wyszukiwania i terminów poprzez analizę przestrzeni wektorowej, która nie była wcześniej wykorzystywana w ten sposób.
BERT i MUM wykorzystują przetwarzanie języka naturalnego do interpretacji zapytań i dokumentów.
Oprócz interpretacji zapytań i treści wyszukiwania, MUM i BERT otworzyły drzwi, aby umożliwić rozwój bazy wiedzy, takiej jak Graf wiedzy, na dużą skalę, a tym samym postęp w wyszukiwaniu semantycznym w Google.
Zmiany w wyszukiwarce Google poprzez podstawowe aktualizacje są również ściśle związane z MUM i BERT, a ostatecznie z wyszukiwaniem NLP i semantycznym.
W przyszłości będziemy widzieć coraz więcej wyników wyszukiwania Google opartych na podmiotach, zastępujących klasyczne indeksowanie i ranking oparte na frazach.
Opinie wyrażone w tym artykule są opiniami gościa i niekoniecznie Search Engine Land. Lista autorów personelu znajduje się tutaj.