
Während wir 2016 abschließen, sprechen wir über den Abschluss von CRO-Tests
Veröffentlicht: 2021-10-23Während wir uns dem Abschluss eines weiteren Jahres nähern und während die Frage „Wann kann dieser Test abgeschlossen werden?“ immer noch mindestens einmal pro Woche in meinen Gesprächen auftaucht, hatte ich das Gefühl, dass es an der Zeit wäre, mich hinzusetzen und meinen Testabschlussprozess und alle Variablen, die bei dieser Entscheidung eine Rolle spielen, aufzuschreiben.
Heute werde ich Sie mit zwei Tipps aufwärmen, die Sie im Hinterkopf behalten sollten, wenn Sie sich der Entscheidung zum Abschluss nähern, und dann werde ich auf die vier Variablen eingehen, die ich bei dieser Entscheidung betrachte. Blasen Sie den Staub von diesem Statistik-Lehrbuch, das Sie vor langer Zeit vergraben haben, und fangen wir an.
Vorwort Tipp Nr. 1: Stellen Sie sicher, dass Ihre Daten schön und robust sind
Bevor Sie Ihren Test einrichten, sollten Sie Ihre Ziele bereits kennen. Beachten Sie, wie ich dort „Ziele“ gesagt habe. Ja, wir alle wissen, dass Sie eine zentralisierte Konvertierung durchführen sollten. die einzige große Sache, zu der Sie Ihre Benutzer führen. Es gibt jedoch viele andere Interaktionen mit jeder Website, die wir verfolgen können, um zu beobachten, ob unsere Änderung auch diese Interaktionen beeinflusst hat oder nicht. Sehen Sie das Bild unten für ein paar Beispiele.

Bevor Sie Testdaten analysieren, überprüfen Sie, ob Ihre Daten alle auf gleichem Spielfeld sind. Stellen Sie sicher, dass Sie Daten für jedes Ziel für denselben genauen Datumsbereich abgerufen haben, damit Sie die Datenpunkte entsprechend vergleichen können, ohne eine Datenzeichenfolge zu verzerren. Stellen Sie während Ihres Aufenthalts auch sicher, dass alle Ihre Zieldaten „normal“ aussehen und dass Sie keine Fehlzündungen oder toten Ziele vermuten, bei denen keine Aktion stattgefunden hat.
Vorwort Tipp #2: Schließen Sie niemals eine einzelne Variable ab
Eine Schlussfolgerungsentscheidung kann sich nicht auf eine einzige Variable stützen. Berücksichtigen Sie jede dieser vier Variablen, und wenn sich die meisten Variablen ergänzen, können Sie mit Zuversicht schließen.
Wenn sich alle Variablen widersprechen, können Sie sich eine Vielzahl unterschiedlicher Szenarien ansehen. Aber wenn Sie zu diesem Zeitpunkt schlussfolgern, könnten Sie eine unlogische Entscheidung mit kostspieligen Konsequenzen treffen.
Jede dieser Variablen wird von mindestens einer der anderen Variablen beeinflusst oder beeinflusst diese. Komplementäre Daten unterstützen sich also selbst, während widersprüchliche Daten Sie dazu zwingen, Punkte mit Lügennetzen zu verbinden. Tu es nicht!
Variable #1: Stichprobenumfang
Die Stichprobengröße ist wichtig, Leute. Die Stichprobengröße ermöglicht es uns, ein Verhalten basierend auf unserer Population (Gesamtnutzer) und unserer akzeptablen Fehlerquote (statistische Signifikanz mit 100 Zielen) sicher zu verallgemeinern.
Es dreht sich wirklich alles um die Proportionen, aber wenn Sie ständig dieselbe Site mit sehr geringen Traffic-Schwankungen betrachten, können Sie ein Endziel festlegen, von dem aus Sie arbeiten können.
Einhundert Benutzer für jedes Segment eines Tests sind ein rechtschaffenes Minimum. Selbst auf Websites mit geringem Traffic ist es sehr schwierig, Verhaltensweisen basierend auf den Daten einiger weniger Benutzer zu verallgemeinern. Je mehr, desto besser. Eine höhere Stichprobengröße trägt auch dazu bei, jegliche Verzerrungen zu beseitigen, die wir an Ausreißern erkennen könnten.
Auf einer ziemlich großen E-Commerce-Site, die mindestens 1.000 Benutzer pro Tag einbringt, würde ich jedoch auf keinen Fall 100 und eine angemessene Stichprobengröße von Benutzern in Betracht ziehen. Es dreht sich alles um die Proportionen und das regelmäßige Nutzeraufkommen Ihrer Website.
Diese Variable umfasst Conversions sowie Nutzer für die Ziele, die Sie berücksichtigen. Selbst wenn Sie eine Website mit geringen Conversions haben, gewinnt die Variante mit 2 Conversions definitiv, wenn Sie 0 Conversions mit 2 Conversions vergleichen, nur weil sie die einzige Variante war, die technisch konvertiert wurde.
Stellen Sie sicher, dass Ihre Conversions mindestens zweistellig sind. und wenn das Ihr absolutes Minimum (zweistellig) ist, stellen Sie sicher, dass Sie bei den anderen drei Variablen starke Komplimente haben.
Wenn Sie nicht viel Erfahrung mit Stichprobengrößen in einer statistischen Umgebung haben, können Sie diesen praktischen Stichprobengrößenrechner verwenden, um eine für Sie geeignete Stichprobengröße zu ermitteln.
Variable #2: Testdauer
Idealerweise führe ich Tests zwischen 2-6 Wochen durch.
Zwei Wochen sind ein solides Minimum, weil Sie die Möglichkeit ausschließen, dass jede Variable eine „gute“ oder eine „schlechte“ Woche hat und entweder glücklichen Verkehr einzieht oder wenig motivierten Verkehr vertreibt. Sechs Wochen sind ein schönes Maximum, weil es ein ausreichend breites zeitliches Netz ist, um alle Schwankungen zu erfassen, die Sie sehen können.
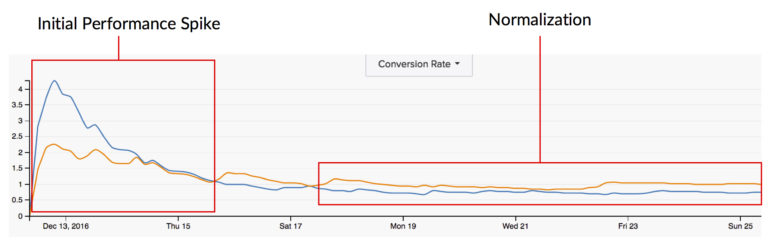
Beachten Sie jedoch, dass das Ausführen eines Tests für immer und ewig Ihrem Test schaden kann. Ein großer Faktor bei den Testergebnissen ist die Reaktion des Benutzers auf neuartige Reize. Wenn wir also zum ersten Mal einen Test starten, sehen wir oft große Sprünge, bei denen eine Variante dramatisch verliert, während die andere auf ihrer Siegesserie ausläuft. Im Laufe der Zeit tendiert diese riesige Lücke zwischen den Variationen dazu, sich zu normalisieren und zu schließen, weil das „Neue“ abgenutzt ist und die wiederkehrenden Benutzer nicht mehr so von der neuartigen Veränderung betroffen sind wie früher. Je länger die Testläufe dauern, desto weniger neuartig wird die Änderung und desto weniger beeinflusst sie das Verhalten dieser wiederkehrenden Benutzer.
Variable #3: Statistische Signifikanz
Während die statistische Signifikanz entscheidend ist, um Ihrer Schlussfolgerung „Vertrauen“ zu verleihen, kann sie auch sehr irreführend sein.
Die statistische Signifikanz bestimmt, ob eine Änderung von zwei Raten auf die normale Varianz oder auf einen externen Faktor zurückzuführen ist. Wenn wir also eine starke statistische Signifikanz erreichen, wissen wir theoretisch, dass unsere Änderung einen Einfluss auf die Benutzer hatte.
Idealerweise streben Sie eine statistische Signifikanz von möglichst 100 % an. Je näher Sie an 100 % sind, desto geringer ist Ihre Fehlerquote. Das bedeutet, dass Ihre Ergebnisse konsistenter reproduziert werden können. Je höher Ihre statistische Signifikanz ist, desto höher sind Ihre Chancen, diesen Anstieg der Conversion-Rate beizubehalten, wenn Sie die gewinnbringende Variante implementieren. 95 % sind ein gutes, hohes Ziel. 90% ist ein guter Ort, um sich niederzulassen. Bei weniger als 90% werden Sie riskant, tatsächlich „zuversichtlich“ schließen zu können.
Die Gefahr besteht darin, dass die Stichprobengröße wirklich wichtig ist. Sie könnten in wenigen Tagen eine statistische Signifikanz von 98% erreichen und buchstäblich nur auf insgesamt 16 Nutzer blicken, was offensichtlich keine vertrauenswürdige Stichprobengröße ist.
Die statistische Signifikanz kann auch die enorme Leistungsspitze erfassen, auf die ich zuvor beim ersten Start eines Tests verwiesen habe. Tests haben jede Fähigkeit zum Flip-Flop und wir wissen auch, dass sich die Daten im Laufe der Zeit normalisieren. Eine zu frühe Messung der statistischen Signifikanz könnte uns daher ein völlig falsches Bild davon vermitteln, wie sich diese Änderung höchstwahrscheinlich langfristig auf unsere Nutzer auswirken wird.
Außerdem gewinnt nicht jeder Test statistische Signifikanz. Einige von Ihnen vorgenommene Änderungen beeinflussen das Benutzerverhalten möglicherweise nicht stark genug, um als eine über die normale Abweichung hinausgehende Abweichung angesehen zu werden. Und das ist gut so! Das bedeutet einfach, dass Sie größere Änderungen testen müssen, um die Aufmerksamkeit eines Benutzers ein wenig mehr zu erregen.
Variable #4: Datenkonsistenz
Dieser geht an all diese Flip-Flopping-Tests da draußen. Es gibt einige Tests, die sich weigern, sich zu normalisieren und Ihnen einen klaren Gewinner zu präsentieren. Sie verbringen jeden Tag damit, Ihnen eine andere Variante als Gewinner zu präsentieren und werden Sie absolut verrückt machen.
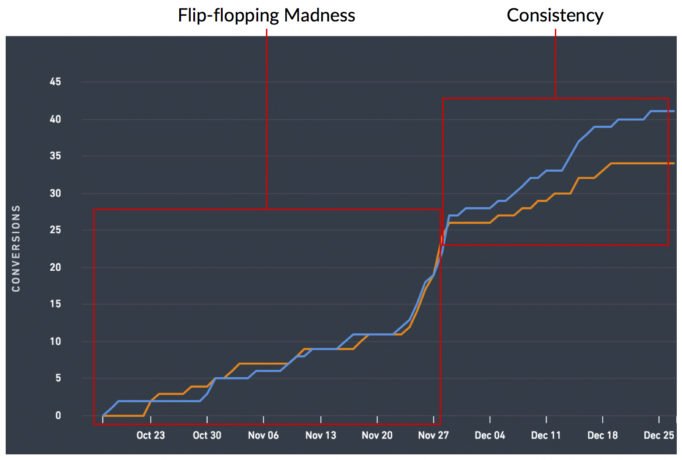
Aber es gibt sie, und genau deshalb ist es so wichtig, nach einer konsistenten Datenrichtung zu suchen. War die Variante, die Sie zum Gewinner erklären, schon immer ein Gewinner? Wenn nicht, warum war es nicht immer ein Gewinner? Wenn Sie das „Warum“ nicht sicher beantworten können Dann könnte die Implementierung des Gewinners Ihrem Endergebnis schaden, wenn Sie die Variation als Gewinner ausführen.
Ich messe auch den Unterschied zwischen der Konversionsrate der Kontrolle und der Konversionsrate der Variation (auch bekannt als „Lift“ oder „Drop“). Ich achte darauf, dass diese Metrik ebenfalls konsistent ist, damit ich sicherstellen kann, dass der Test aus der anfänglichen Spitzenphase heraus ist.
Es ist auch von Vorteil, die statistische Signifikanz regelmäßig zu berechnen, um zu sehen, wie konsistent diese Metrik auch dargestellt wird.
Abschließende Gedanken
Der Abschluss eines jeden Tests ist kein Scherz und mit Druck gefüllt. Wenn Sie den falschen Anruf tätigen und etwas implementieren, von dem Sie „glaubten“, dass es der Gewinner war, während die Daten das Gegenteil veranschaulichen, werden Ihr Endergebnis und Ihre Benutzer darunter leiden.
Gehen Sie eine Schlussfolgerung aus jedem praktikablen Blickwinkel an, damit Sie sicher sein können, dass Sie eine wirklich sichere Schlussfolgerung haben, die auf Daten basiert!