
Tarama etkinliği: Tarama optimizasyonu nasıl üst düzeye çıkarılır?
Yayınlanan: 2022-10-27Googlebot'un sitenizde erişebildiği her URL'yi tarayacağı garanti edilmez. Aksine, sitelerin büyük çoğunluğunda önemli miktarda sayfa eksik.
Gerçek şu ki, Google bulduğu her sayfayı tarayacak kaynaklara sahip değil. Googlebot'un keşfettiği, ancak henüz taramadığı tüm URL'ler ile yeniden taramayı amaçladığı URL'ler bir tarama kuyruğunda önceliklendirilir.
Bu, Googlebot'un yalnızca yeterince yüksek öncelik atanmış olanları taradığı anlamına gelir. Ve tarama sırası dinamik olduğundan, Google yeni URL'leri işlerken sürekli olarak değişir. Ve tüm URL'ler sıranın arkasına katılmaz.
Peki, sitenizin URL'lerinin VIP olmasını nasıl sağlıyorsunuz ve sırayı nasıl atlıyorsunuz?
Tarama, SEO için kritik öneme sahiptir

İçeriğin görünürlük kazanması için önce Googlebot'un onu taraması gerekir.
Ancak faydalar bundan daha nüanslıdır çünkü bir sayfa şu andan itibaren o kadar hızlı taranır:
- Oluşturulduysa , yeni içerik Google'da o kadar erken görünebilir. Bu, özellikle zaman sınırlı veya pazara ilk giren içerik stratejileri için önemlidir.
- Güncellendi , yenilenen içerik o kadar çabuk sıralamaları etkilemeye başlayabilir. Bu, hem içerik yeniden yayınlama stratejileri hem de teknik SEO taktikleri için özellikle önemlidir.
Bu nedenle, tüm organik trafiğiniz için tarama gereklidir. Yine de sık sık tarama optimizasyonunun yalnızca büyük web siteleri için faydalı olduğu söylenir.
Ancak bu, web sitenizin boyutu, sıklık içeriğinin güncellenmesi veya Google Search Console'da “Keşfedildi – şu anda dizine eklenmemiş” hariç tutmalarınız olup olmadığıyla ilgili değildir.
Tarama optimizasyonu her web sitesi için faydalıdır. Değerinin yanlış anlaşılması, anlamsız ölçümlerden, özellikle tarama bütçesinden kaynaklanıyor gibi görünüyor.
Tarama bütçesi önemli değil

Çok sık olarak tarama, tarama bütçesine göre değerlendirilir. Bu, Googlebot'un belirli bir web sitesinde belirli bir süre içinde tarayacağı URL sayısıdır.
Google, bunun iki faktör tarafından belirlendiğini söylüyor:
- Tarama hızı sınırı (veya Googlebot'un tarayabileceği şey): Googlebot'un site performansını etkilemeden web sitesinin kaynaklarını getirebildiği hız. Esasen, duyarlı bir sunucu daha yüksek bir tarama hızına yol açar.
- Tarama talebi (veya Googlebot'un taramak istediği şey): Site içeriğinin popülerliğinden ve bayatlığından etkilenen (yeniden) dizine ekleme talebine bağlı olarak Googlebot'un tek bir tarama sırasında ziyaret ettiği URL'lerin sayısı.
Googlebot, tarama bütçesini "harcadığında" bir siteyi taramayı durdurur.
Google, tarama bütçesi için bir rakam sağlamaz. En yakın olanı, Google Arama Konsolu tarama istatistikleri raporundaki toplam tarama isteklerini göstermektir.
Geçmişte kendim de dahil olmak üzere pek çok SEO uzmanı, tarama bütçesi çıkarmaya çalışmak için büyük acılar çekti.
Sıklıkla sunulan adımlar şu şekildedir:
- Sitenizde kaç tane taranabilir sayfanız olduğunu belirleyin, genellikle XML site haritanızdaki URL sayısına bakmanızı veya sınırsız bir tarayıcı çalıştırmanızı önerir.
- Google Arama Konsolu Tarama İstatistikleri raporunu dışa aktararak veya günlük dosyalarındaki Googlebot isteklerini temel alarak günlük ortalama taramaları hesaplayın.
- Sayfa sayısını günlük ortalama taramaya bölün. Sonuç 10'un üzerindeyse, tarama bütçesi optimizasyonuna odaklanın.
Ancak bu süreç sorunludur.
Her URL'nin bir kez tarandığını varsaydığı için değil, gerçekte bazıları birden çok kez taranırken, diğerleri hiç taranmaz.
Sadece bir taramanın bir sayfaya eşit olduğunu varsaydığı için değil. Gerçekte bir sayfa, onu yüklemek için gereken kaynakları (JS, CSS, vb.) getirmek için birçok URL taraması gerektirebilir.
Ancak en önemlisi, günlük ortalama tarama sayısı gibi hesaplanmış bir metriğe damıtıldığında, tarama bütçesi boş bir metrikten başka bir şey değildir.
"Tarama bütçesi optimizasyonunu" hedefleyen herhangi bir taktik (diğer bir deyişle, toplam tarama miktarını sürekli olarak artırmayı amaçlayan) bir aptalın işidir.
Değeri olmayan URL'lerde veya son taramadan bu yana değiştirilmemiş sayfalarda kullanılıyorsa, toplam tarama sayısını artırmayı neden önemsemelisiniz? Bu tür taramalar SEO performansına yardımcı olmaz.
Ayrıca, tarama istatistiklerine daha önce bakan herkes, herhangi bir sayıda faktöre bağlı olarak bir günden diğerine, genellikle oldukça çılgınca dalgalandıklarını bilir. Bu dalgalanmalar, SEO ile ilgili sayfaların hızlı (yeniden) dizine eklenmesiyle ilişkili olabilir veya olmayabilir.
Taranan URL sayısındaki artış veya düşüş, doğası gereği ne iyi ne de kötüdür.
Tarama etkinliği bir SEO KPI'dır

Dizine eklenmesini istediğiniz sayfa(lar) için, taranıp taranmadığına değil, yayınlandıktan veya önemli ölçüde değiştirildikten sonra ne kadar hızlı tarandığına odaklanılmalıdır.
Esasen amaç, SEO ile ilgili bir sayfanın oluşturulması veya güncellenmesi ile bir sonraki Googlebot taraması arasındaki süreyi en aza indirmektir. Bu zaman gecikmesini tarama etkinliği olarak adlandırıyorum.
Tarama etkinliğini ölçmenin ideal yolu, veritabanı oluşturma veya güncelleme tarihi ile sunucu günlük dosyalarından URL'nin bir sonraki Googlebot taraması arasındaki farkı hesaplamaktır.
Bu veri noktalarına erişmek zorsa, XML site haritası son mod tarihini proxy olarak kullanabilir ve son tarama durumu için Google Arama Konsolu URL Denetleme API'sindeki URL'leri sorgulayabilirsiniz (günde 2.000 sorgu sınırına kadar).
Ayrıca, URL Denetleme API'sini kullanarak, yeni oluşturulan URL'ler için bir dizin oluşturma etkinliğini hesaplamak için dizin oluşturma durumunun ne zaman değiştiğini de izleyebilirsiniz; bu, yayınlama ile başarılı dizine ekleme arasındaki farktır.
Çünkü, indeksleme durumunu etkilemeden veya sayfa içeriğinin yenilenmesini işlemeden tarama yapmak sadece bir israftır.
Tarama etkinliği eyleme geçirilebilir bir ölçümdür çünkü azaldıkça, SEO açısından daha kritik içerik Google'da hedef kitlenize gösterilebilir.
SEO sorunlarını teşhis etmek için de kullanabilirsiniz. Sitenizin çeşitli bölümlerindeki içeriğin ne kadar hızlı tarandığını ve organik performansı engelleyen şeyin bu olup olmadığını anlamak için URL modellerini inceleyin.
Googlebot'un taramasının saatler, günler veya haftalar sürdüğünü ve dolayısıyla yeni oluşturduğunuz veya yakın zamanda güncellenen içeriğinizi dizine eklediğini görürseniz, bu konuda ne yapabilirsiniz?
Arama pazarlamacılarının güvendiği günlük bültenleri alın.
Şartlara bakın.
Taramayı optimize etmek için 7 adım
Tarama optimizasyonu tamamen Googlebot'u önemli URL'leri taramaya yönlendirmekle ilgilidir. (yeniden) yayınlandıklarında hızlı. Aşağıdaki yedi adımı izleyin.
1. Hızlı, sağlıklı bir sunucu yanıtı sağlayın
Yüksek performanslı bir sunucu kritik öneme sahiptir. Googlebot, şu durumlarda taramayı yavaşlatır veya durdurur:
- Sitenizi taramak performansı etkiler. Örneğin, ne kadar çok tararlarsa, sunucu yanıt süresi o kadar yavaş olur.
- Sunucu, dikkate değer sayıda hata veya bağlantı zaman aşımı ile yanıt verir.
Diğer taraftan, daha fazla sayfanın sunulmasına izin veren sayfa yükleme hızının iyileştirilmesi, Googlebot'un aynı süre içinde daha fazla URL taramasına yol açabilir. Bu, bir kullanıcı deneyimi ve sıralama faktörü olmanın sayfa hızına ek bir avantajdır.
Henüz yapmadıysanız, sunucularda benzer yüke sahip daha fazla URL talep etme olanağı sağladığından HTTP/2 desteğini düşünün.
Ancak performans ve tarama hacmi arasındaki korelasyon yalnızca bir noktaya kadardır . Siteden siteye değişen bu eşiği geçtikten sonra, sunucu performansındaki herhangi bir ek kazancın, taramadaki bir artışla ilişkilendirilmesi olası değildir.
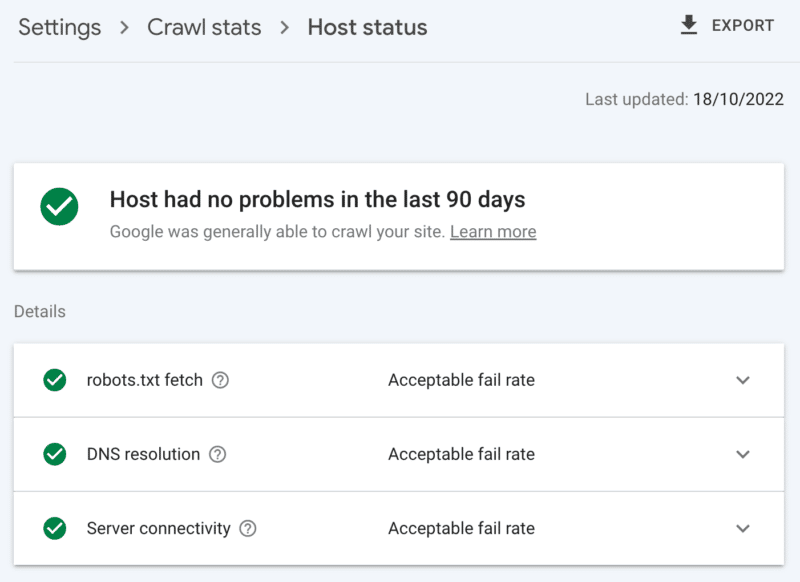
Sunucu sağlığı nasıl kontrol edilir
Google Arama Konsolu tarama istatistikleri raporu:
- Ana bilgisayar durumu: Yeşil onay işaretlerini gösterir.
- 5xx hataları: %1'den daha azını oluşturur.
- Sunucu yanıt süresi çizelgesi: Trend 300 milisaniyenin altında.
2. Düşük değerli içeriği temizleyin
Önemli miktarda site içeriği eski, yinelenen veya düşük kaliteliyse, tarama etkinliği için rekabete neden olarak yeni içeriğin dizine eklenmesini veya güncellenen içeriğin yeniden dizine eklenmesini potansiyel olarak geciktirir.

Düşük değerli içeriği düzenli olarak temizlemenin, dizin şişkinliğini ve anahtar kelime yamyamlığını da azalttığını ve kullanıcı deneyimi için faydalı olduğunu ekleyin, bu bir SEO zahmetsizdir.
Net bir ikame olarak görülebilecek başka bir sayfanız olduğunda, içeriği 301 yönlendirmesiyle birleştirin; Bunu anlamak, işleme için iki katına mal olacak, ancak bu, bağlantı eşitliği için değerli bir fedakarlıktır.
Eşdeğer bir içerik yoksa, 301 kullanmak yalnızca soft 404 ile sonuçlanır. URL'yi tekrar taramamak için güçlü bir sinyal vermek için 410 (en iyi) veya 404 (yakın saniye) durum kodu kullanarak bu tür içeriği kaldırın.
Düşük değerli içerik nasıl kontrol edilir
Google Arama Konsolu sayfalarındaki URL'lerin sayısı, 'taranan – şu anda dizine eklenmemiş' hariç tutmaları bildirir. Bu yüksekse, klasör kalıpları veya diğer sorun göstergeleri için sağlanan örnekleri inceleyin.
3. İndeksleme kontrollerini gözden geçirin
Rel=kanonik bağlantılar dizine ekleme sorunlarından kaçınmak için güçlü bir ipucudur, ancak genellikle aşırı güvenilir ve her kurallı URL, biri kendisi için diğeri iş ortağı için olmak üzere en az iki taramaya mal olduğundan, tarama sorunlarına neden olur.
Benzer şekilde, noindex robots yönergeleri, dizin şişkinliğini azaltmak için yararlıdır, ancak çok sayıda olması taramayı olumsuz etkileyebilir - bu nedenle bunları yalnızca gerektiğinde kullanın.
Her iki durumda da kendinize sorun:
- Bu indeksleme direktifleri, SEO zorluğunun üstesinden gelmenin en uygun yolu mu?
- Bazı URL yolları robots.txt dosyasında birleştirilebilir, kaldırılabilir veya engellenebilir mi?
Kullanıyorsanız, AMP'yi uzun vadeli teknik bir çözüm olarak ciddi şekilde yeniden düşünün.
Temel web hayati konularına odaklanan sayfa deneyimi güncellemesi ve site hızı gereksinimlerini karşıladığınız sürece tüm Google deneyimlerine AMP olmayan sayfaların dahil edilmesiyle, AMP'nin iki kez taranmaya değer olup olmadığına yakından bakın.
İndeksleme kontrollerine aşırı güven nasıl kontrol edilir
Açık bir neden olmaksızın hariç tutmalar altında kategorize edilen Google Arama Konsolu kapsam raporundaki URL'lerin sayısı:
- Uygun kurallı etikete sahip alternatif sayfa.
- noindex etiketi tarafından hariç tutuldu.
- Yinelenen, Google, kullanıcıdan farklı bir standart seçti.
- Yinelenen, gönderilen URL standart olarak seçilmedi.
4. Arama motoru örümceklerine neyi ne zaman tarayacaklarını söyleyin
Googlebot'un önemli site URL'lerine öncelik vermesine ve bu tür sayfalar güncellendiğinde iletişim kurmasına yardımcı olacak önemli bir araç, bir XML site haritasıdır.
Etkili tarayıcı rehberliği için şunları yaptığınızdan emin olun:
- Yalnızca SEO için hem dizine eklenebilir hem de değerli URL'leri ekleyin - genellikle, SERP'lerde görünürlüğünü önemsediğiniz "index,follow" robot etiketine sahip 200 durum kodu, kurallı, orijinal içerik sayfası.
- Tek tek URL'lere ve site haritasının kendisine mümkün olduğunca gerçek zamana yakın doğru <lastmod> zaman damgası etiketleri ekleyin.
Google, bir site her tarandığında bir site haritasını kontrol etmez. Bu nedenle, her güncellendiğinde, Google'ın dikkatine ping atmak en iyisidir. Bunu yapmak için tarayıcınıza veya komut satırına bir GET isteği gönderin:
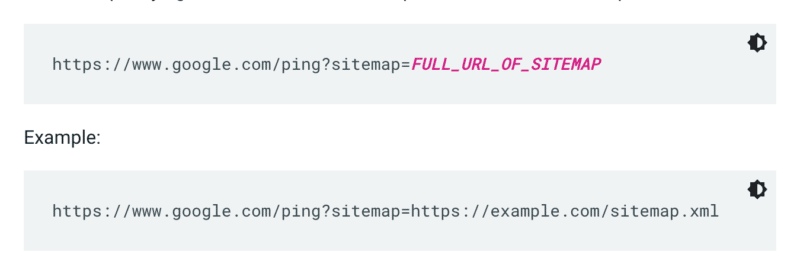
Ayrıca, robots.txt dosyasında site haritasının yollarını belirtin ve site haritaları raporunu kullanarak Google Search Console'a gönderin.
Kural olarak Google, site haritalarındaki URL'leri diğerlerinden daha sık tarar. Ancak site haritanızdaki URL'lerin küçük bir yüzdesi düşük kalitede olsa bile, bu, Googlebot'u tarama önerileri için kullanmaktan vazgeçirebilir.
XML site haritaları ve bağlantıları, normal tarama kuyruğuna URL'ler ekler. Ayrıca, iki giriş yöntemi olan bir öncelikli tarama sırası da vardır.
İlk olarak, iş ilanları veya canlı videoları olanlar için URL'leri Google'ın Dizine Ekleme API'sine gönderebilirsiniz.
Veya Microsoft Bing veya Yandex'in dikkatini çekmek istiyorsanız, herhangi bir URL için IndexNow API'sini kullanabilirsiniz. Ancak, kendi testlerimde, URL'lerin taranması üzerinde sınırlı bir etkisi oldu. Bu nedenle IndexNow kullanıyorsanız, Bingbot için tarama etkinliğini izlediğinizden emin olun.
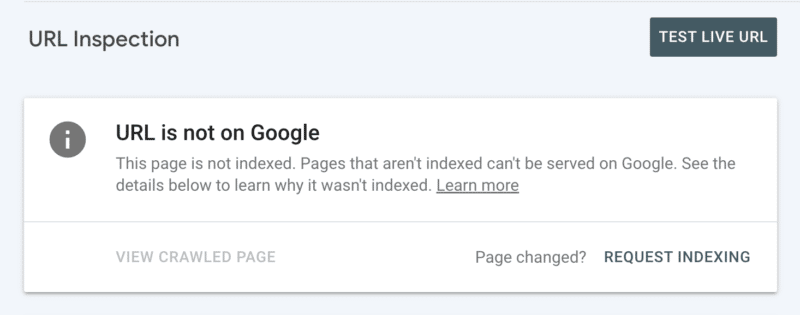
İkinci olarak, Search Console'da URL'yi inceledikten sonra indekslemeyi manuel olarak talep edebilirsiniz. Her ne kadar günlük 10 URL'lik bir kota olduğunu ve taramanın hala birkaç saat sürebileceğini unutmayın. Tarama sorununuzun kökenini keşfetmek için kazarken bunu geçici bir yama olarak görmek en iyisidir.
Temel Googlebot tarama kılavuzu olup olmadığı nasıl kontrol edilir
Google Arama Konsolunda, XML site haritanız "Başarılı" durumunu gösterir ve yakın zamanda okunmuştur.
5. Arama motoru örümceklerine neleri taramamaları gerektiğini söyleyin
Bazı sayfalar kullanıcılar veya site işlevleri için önemli olabilir, ancak bunların arama sonuçlarında görünmesini istemezsiniz. Bir robots.txt dosyasına izin vermeyerek bu tür URL yollarının tarayıcıların dikkatini dağıtmasını önleyin. Bu şunları içerebilir:
- API'ler ve CDN'ler . Örneğin, Cloudflare müşterisiyseniz, sitenize eklenen /cdn-cgi/ klasörüne izin vermediğinizden emin olun.
- Önemsiz resimler, komut dosyaları veya stil dosyaları , bu kaynaklar olmadan yüklenen sayfalar kayıptan önemli ölçüde etkilenmez.
- Alışveriş sepeti gibi işlevsel bir sayfa .
- Takvim sayfaları tarafından oluşturulanlar gibi sonsuz boşluklar .
- Parametre sayfaları . Özellikle, her bir kombinasyon tarayıcılar tarafından ayrı bir sayfa olarak sayıldığından filtreleyen (örneğin, ?fiyat aralığı=20-50), yeniden sıralayan (örneğin, ?sort=) veya arama yapan (örneğin, ?q=) yönlü gezinmeden olanlar.
Sayfalandırma parametresini tamamen engellememeye dikkat edin. Bir noktaya kadar taranabilir sayfalandırma, Googlebot'un içeriği keşfetmesi ve dahili bağlantı eşitliğini işlemesi için genellikle gereklidir. (Nedeniyle ilgili daha fazla ayrıntı öğrenmek için sayfalandırmayla ilgili bu Semrush web seminerine göz atın.)
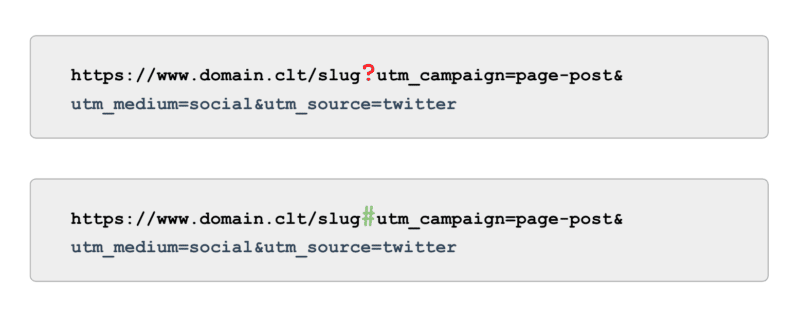
Ve izleme söz konusu olduğunda, parametreler tarafından desteklenen UTM etiketlerini (diğer bir deyişle '?') kullanmak yerine, çapaları (diğer adıyla '#') kullanın. Google Analytics'te taranabilir olmadan aynı raporlama avantajlarını sunar.
Googlebot'un tarama yapmadığını kontrol etme kılavuzu
Google Search Console'daki 'Dizine eklendi, site haritasında gönderilmedi' URL'leri örneğini inceleyin. Sayfalandırmanın ilk birkaç sayfasını göz ardı ederek, başka hangi yolları buluyorsunuz? Bir XML site haritasına dahil edilmeli mi, taranmaları engellenmeli mi yoksa izin verilmeli mi?
Ayrıca, "Keşfedildi - şu anda dizine eklenmemiş" listesini inceleyin – robots.txt dosyasında Google için düşük veya sıfır değer sunan URL yollarını engelleyin.
Bunu bir sonraki düzeye taşımak için, değersiz yollar için sunucu günlük dosyalarındaki tüm Googlebot akıllı telefon taramalarını inceleyin.
6. İlgili bağlantıları küratörlüğünü yapın
Bir sayfaya verilen geri bağlantılar, SEO'nun birçok yönü için değerlidir ve tarama da bir istisna değildir. Ancak belirli sayfa türleri için harici bağlantılar almak zor olabilir. Örneğin, ürünler gibi derin sayfalar, site mimarisinde alt seviyelerdeki kategoriler ve hatta makaleler.
Öte yandan, ilgili dahili bağlantılar şunlardır:
- Teknik olarak ölçeklenebilir.
- Tarama için bir sayfaya öncelik vermesi için Googlebot'a güçlü sinyaller.
- Derin sayfa tarama için özellikle etkilidir.
Ekmek kırıntıları, ilgili içerik blokları, hızlı filtreler ve iyi seçilmiş etiketlerin kullanımı, tarama etkinliği için önemli faydalardır. SEO açısından kritik içerik olduklarından, bu tür dahili bağlantıların JavaScript'e bağlı olmadığından emin olun, bunun yerine standart, taranabilir bir <a> bağlantısı kullanın.
Bu tür dahili bağlantıların da kullanıcı için gerçek değer katması gerektiğini akılda tutmak.
İlgili bağlantılar nasıl kontrol edilir
ScreamingFrog'un SEO örümceği gibi bir araçla sitenizin tamamını manuel olarak tarayın ve şunları arayın:
- Yetim URL'ler.
- Robots.txt tarafından engellenen dahili bağlantılar.
- 200 olmayan herhangi bir durum koduna dahili bağlantılar.
- Dahili olarak bağlantılı dizine eklenemeyen URL'lerin yüzdesi.
7. Kalan tarama sorunlarını denetleyin
Yukarıdaki optimizasyonların tümü tamamlandıysa ve tarama etkinliğiniz yetersiz kalırsa, bir derin dalış denetimi yapın.
Tarama sorunlarını belirlemek için kalan Google Search Console hariç tutma örneklerini inceleyerek başlayın.
Bunlar ele alındıktan sonra, site yapısındaki tüm sayfaları Googlebot'un yaptığı gibi taramak için manuel bir tarama aracı kullanarak daha derine inin. Bu sayfalardan hangilerinin taranıp taranmadığını anlamak için bunu Googlebot IP'lerine daraltılmış günlük dosyalarıyla karşılaştırın.
Son olarak, ideal olarak daha fazla, en az dört haftalık veri için Googlebot IP'sine daraltılmış günlük dosyası analizine başlayın.
Günlük dosyalarının biçimine aşina değilseniz, bir günlük analiz aracından yararlanın. Sonuç olarak bu, Google'ın sitenizi nasıl taradığını anlamak için en iyi kaynaktır.
Denetiminiz tamamlandıktan ve tespit edilen tarama sorunlarının bir listesine sahip olduğunuzda, her sorunu beklenen çaba düzeyine ve performans üzerindeki etkisine göre sıralayın.
Not : Diğer SEO uzmanları, SERP'lerden gelen tıklamaların açılış sayfası URL'sinin taranmasını artırdığından bahsetmiştir. Ancak, bunu henüz testlerle doğrulayamadım.
Tarama bütçesine göre tarama verimliliğine öncelik verin
Taramanın amacı, en yüksek miktarda tarama elde etmek veya bir web sitesinin her sayfasının tekrar tekrar taranmasını sağlamak değil, SEO ile ilgili içeriğin, bir sayfanın oluşturulduğu veya güncellendiği zamana mümkün olduğunca yakın bir zamanda taranmasını sağlamaktır.
Genel olarak, bütçeler önemli değil. Önemli olan neye yatırım yaptığınızdır.
Bu makalede ifade edilen görüşler konuk yazara aittir ve mutlaka Search Engine Land değildir. Personel yazarları burada listelenir.