
Python を使用して SERP で Web ページをランキングする際の語彙の違いを比較する
公開: 2022-09-01語彙のサイズと違いは、数学的および質的言語学の意味論的および言語学的概念です。
たとえば、ヒープの法則は、記事の長さと語彙のサイズが相関関係にあると主張しています。 それでも、一定のしきい値を超えると、語彙のサイズを改善することなく、同じ単語が引き続き表示されます。
Word2Vec は、Continuous Bag of Words (CBOW) と Skip-gram を使用して、ローカルに文脈的に関連する単語とそれらの単語間の距離を理解します。 同時に、GloVe はコンテキスト ウィンドウで行列分解を使用しようとします。
Zipf の法則は Heaps の法則を補完する理論です。 最も頻繁に使用される単語と 2 番目に頻繁に使用される単語の間には、一定のパーセンテージの差があることが示されています。
統計的自然言語処理には、他の分布意味論と言語理論があります。
しかし、「語彙の比較」は、検索エンジンが「話題性の違い」、「ドキュメントの主なトピック」、または全体的な「ドキュメントの専門知識」を理解するための基本的な方法論です。
Google の Paul Haahr は、「クエリ語彙」を「ドキュメント語彙」と比較すると述べています。
David C. Taylor と彼のコンテキスト ドメインの設計では、ベクトル検索で特定の単語ベクトルを使用して、どのドキュメントとどのドキュメントのサブセクションが何に関するものであるかを確認します。これにより、検索エンジンは、検索クエリの変更に基づいてドキュメントをランク付けおよび再ランク付けできます。
検索エンジンの結果ページ (SERP) でランク付けされている Web ページ間の語彙の違いを比較すると、SEO の専門家は、競合他社と比較してスキップしているコンテキスト、同時発生する単語、および単語の近接性を確認できます。
ドキュメント内のコンテキストの違いを確認すると便利です。
このガイドでは、Python プログラミング言語を使用して Google で検索し、SERP アイテム (スニペット) を取得してコンテンツをクロールし、トークン化し、語彙を相互に比較します。

ランキング Web ドキュメントのボキャブラリーを Python と比較するには?
ランキング Web ドキュメントのボキャブラリーを (Python で) 比較するために、使用されている Python プログラミング言語のライブラリとパッケージを以下に示します。
- Googlesearch は、クエリ、地域、言語、結果数、リクエスト頻度、または安全な検索フィルターを使用して Google 検索を実行するための Python パッケージです。
- URLlib は、URL を netloc、スキーム、またはパスに解析するための Python ライブラリです。
- リクエスト (オプション) は、SERP アイテム (スニペット) のタイトル、説明、およびリンクを取得することです。
- Fake_useragent は、フェイクでランダムなユーザー エージェントを使用して 429 ステータス コードを防ぐ Python パッケージです。
- Advertools は、Google クエリ検索結果の URL をクロールして、テキストのクリーニングと処理のために本文テキストを取得するために使用されます。
- Pandas は、SERP 上のドキュメントの分布セマンティクスをさらに分析するために、データを調整および集約します。
- Natural LanguageTool キットを使用してドキュメントのコンテンツをトークン化し、英語のストップ ワードを使用してストップ ワードを削除します。
- 単語の出現をカウントするための「Counter」メソッドを使用するコレクション。
- 文字列は、句読点のクリーニングのためにリスト内のすべての句読点を呼び出す Python モジュールです。
Web ページ間の語彙サイズとコンテンツの比較の手順は?
ランキングの Web ページ間で語彙のサイズと内容を比較する手順を以下に示します。
- Web ページのテキスト コンテンツを取得して処理するために必要な Python ライブラリとパッケージをインポートします。
- Google 検索を実行して、SERP で結果の URL を取得します。
- URL をクロールして、コンテンツを含む本文テキストを取得します。
- NLP 方法論でのテキスト処理のために Web ページのコンテンツをトークン化します。
- ストップ ワードと句読点を削除して、よりクリーンなテキスト分析を行います。
- Web ページのコンテンツに出現する単語の数を数えます。
- さらに優れたテキスト分析のために Pandas Data フレームを構築します。
- 2 つの URL を選択し、それらの単語の頻度を比較します。
- 選択した URL の語彙のサイズと内容を比較します。
1. Web ページのテキスト コンテンツの取得と処理に必要な Python ライブラリとパッケージをインポートする
「from」および「import」コマンドとメソッドを使用して、必要な Python ライブラリとパッケージをインポートします。
from googlesearch import search from urllib.parse import urlparse import requests from fake_useragent import UserAgent import advertools as adv import pandas as pd from nltk.tokenize import word_tokenize import nltk from collections import Counter from nltk.corpus import stopwords import string nltk.download()初めて NLTK を使用する場合にのみ、「nltk.download」を使用してください。 すべてのコーパス、モデル、およびパッケージをダウンロードします。 以下のようなウィンドウが開きます。
 著者のスクリーンショット、2022 年 8 月
著者のスクリーンショット、2022 年 8 月時々ウィンドウをリフレッシュしてください。 すべてが緑色の場合は、ウィンドウを閉じて、コード エディターで実行中のコードが停止して完了するようにします。
上記のモジュールがない場合は、「pip install」メソッドを使用してそれらをローカル マシンにダウンロードします。 クローズド環境のプロジェクトがある場合は、Python で仮想環境を使用します。
2. Google 検索を実行して、検索エンジンの結果ページで結果 URL を取得する
Google 検索を実行して SERP アイテムの結果 URL を取得するには、「Googlesearch」パッケージに含まれる「検索」オブジェクトで for ループを使用します。
serp_item_url = [] for i in search("search engine optimization", num=10, start=1, stop=10, pause=1, lang="en", country="us"): serp_item_url.append(i) print(i)上記のコード ブロックの説明は次のとおりです。
- 「serp_item_url」などの空のリスト オブジェクトを作成します。
- クエリ、言語、結果数、最初と最後の結果、および国の制限を示す「検索」オブジェクト内で for ループを開始します。
- すべての結果を「serp_item_url」オブジェクトに追加します。これには Python リストが必要です。
- Google SERP から取得したすべての URL を印刷します。
以下に結果を示します。
クエリ「検索エンジン最適化」のランキング URL は上記のとおりです。
次のステップは、これらの URL を解析してさらにクリーニングすることです。
結果に「動画コンテンツ」が含まれる場合、動画の説明が長くなかったり、コメントが多すぎたりするコンテンツ タイプが異なると、健全なテキスト分析を実行できないためです。
3. 結果の Web ページからビデオ コンテンツの URL を消去する
ビデオ コンテンツの URL をクリーンアップするには、以下のコード ブロックを使用します。
parsed_urls = [] for i in range(len(serp_item_url)): parsed_url = urlparse(serp_item_url[i]) i += 1 full_url = parsed_url.scheme + '://' + parsed_url.netloc + parsed_url.path if ('youtube' not in full_url and 'vimeo' not in full_url and 'dailymotion' not in full_url and "dtube" not in full_url and "sproutvideo" not in full_url and "wistia" not in full_url): parsed_urls.append(full_url)YouTube、Vimeo、Dailymotion、Sproutvideo、Dtube、Wistia などのビデオ検索エンジンは、結果に表示される場合、結果の URL から削除されます。
分析の効率を低下させたり、独自のコンテンツ タイプで結果を損なったりすると思われる Web サイトに対して、同じクリーニング方法を使用できます。
たとえば、競合するドキュメント間の「語彙サイズ」の違いを確認するのに、Pinterest やその他のビジュアル重視の Web サイトは必要ない場合があります。
上記のコード ブロックの説明:
- 「parsed_urls」などのオブジェクトを作成します。
- 取得結果URL数の長さの範囲でforループを作成します。
- 「URLlib」の「urlparse」で URL を解析します。
- 「i」の数を増やして繰り返します。
- 「スキーム」、「ネットロック」、「パス」を結合して完全な URL を取得します。
- クリーンアップするドメインの「and」条件を含む「if」ステートメントで条件を使用して検索を実行します。
- それらを「dict.fromkeys」メソッドでリストに取り込みます。
- 調べる URL を出力します。
以下に結果を示します。
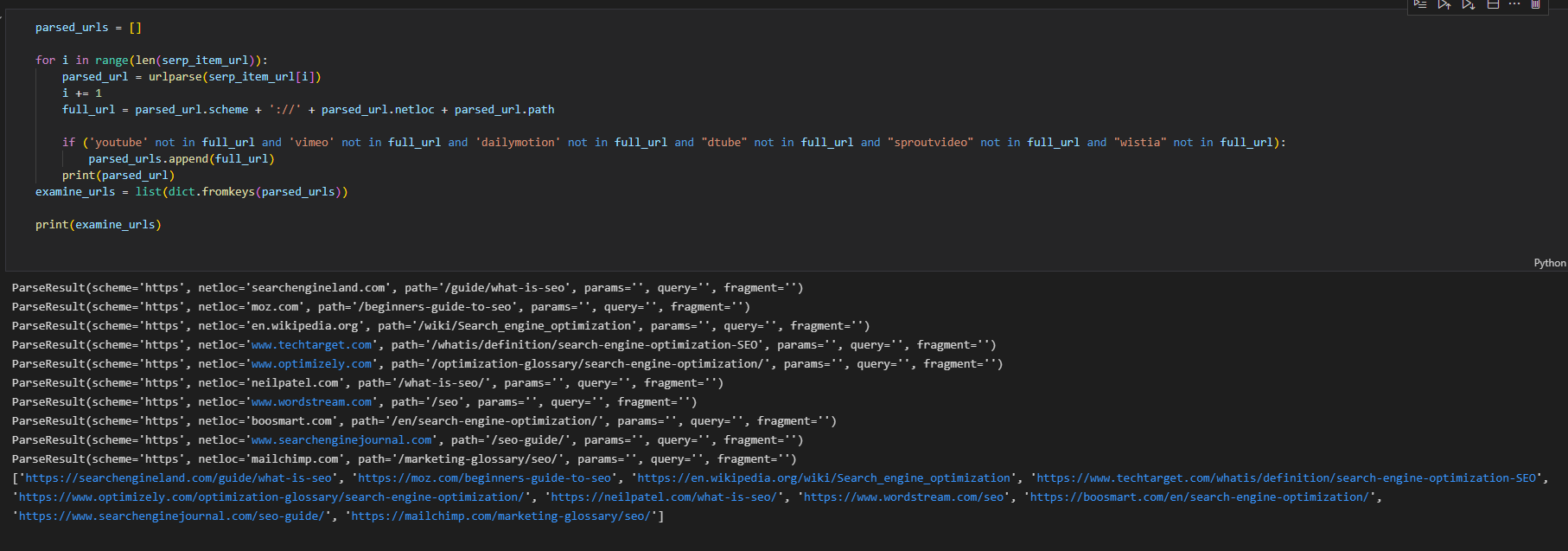 著者のスクリーンショット、2022 年 8 月
著者のスクリーンショット、2022 年 8 月4. クリーンアップされた URL をクロールしてコンテンツを取得する
advertools でコンテンツを取得するために、クリーンアップされた検査 URL をクロールします。
for ループとリストの追加方法でリクエストを使用することもできますが、advertools の方が高速にクロールし、結果の出力でデータ フレームを作成できます。
リクエストでは、すべての「p」要素と「heading」要素を手動で取得して結合します。
adv.crawl(examine_urls, output_file="examine_urls.jl", follow_links=False, custom_settings={"USER_AGENT": UserAgent().random, "LOG_FILE": "examine_urls.log", "CRAWL_DELAY": 2}) crawled_df = pd.read_json("examine_urls.jl", lines=True) crawled_df上記のコード ブロックの説明:
- 「examine_urls」オブジェクトのクロールには「adv.crawl」を使用します。
- 拡張子が「jl」の出力ファイルのパスを作成します。これは他のファイルよりも小さくなります。
- リストされた URL のクロールのみを停止するには、「follow_links=false」を使用します。
- 一部の URL がクロール リクエストに応答しない場合は、カスタム設定を使用して「ランダム ユーザー エージェント」とクロール ログ ファイルを指定します。 クロール遅延構成を使用して、429 ステータス コードの可能性を防ぎます。
- 結果を読み取るには、pandas の「read_json」に「lines=True」パラメーターを指定して使用します。
- 以下のように「crawled_df」を呼び出します。
以下に結果を示します。
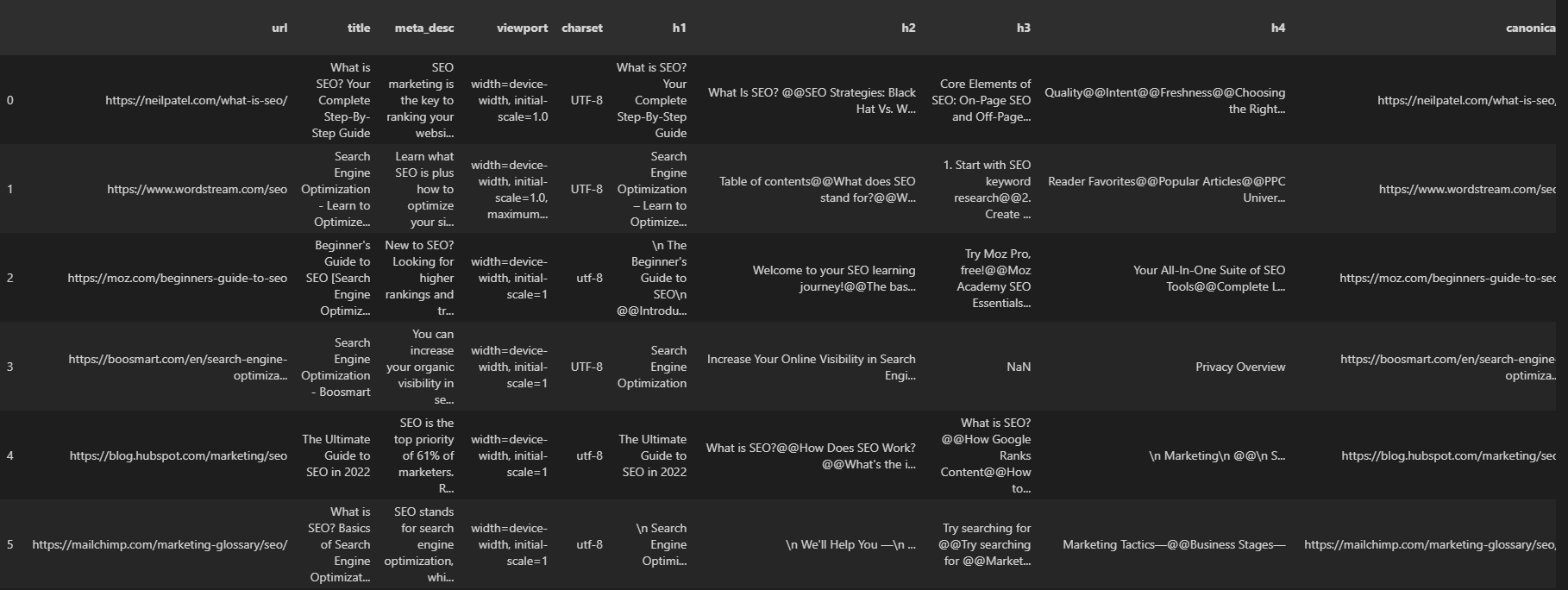 著者のスクリーンショット、2022 年 8 月
著者のスクリーンショット、2022 年 8 月結果の URL と、応答ヘッダー、応答サイズ、構造化データ情報など、ページ上のすべての SEO 要素を確認できます。
5. NLP 方法論でのテキスト処理のために Web ページのコンテンツをトークン化する
Web ページのコンテンツのトークン化には、advertools クロール出力の「body_text」列を選択し、NLTK の「word_tokenize」を使用する必要があります。
crawled_df["body_text"][0]上記のコード行は、以下の結果ページの 1 つのコンテンツ全体を呼び出します。
 著者のスクリーンショット、2022 年 8 月
著者のスクリーンショット、2022 年 8 月これらの文をトークン化するには、以下のコード ブロックを使用します。
tokenized_words = word_tokenize(crawled_df["body_text"][0]) len(tokenized_words)最初の文書の内容をトークン化し、単語数を確認しました。
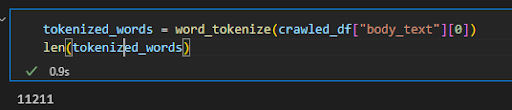 著者のスクリーンショット、2022 年 8 月
著者のスクリーンショット、2022 年 8 月「検索エンジンの最適化」というクエリ用にトークン化した最初のドキュメントには、11211 語が含まれています。 定型文の内容もこの数に含まれます。
6.コーパスから句読点とストップワードを削除する
以下のように、句読点とストップ ワードを削除します。
stop_words = set(stopwords.words("english")) tokenized_words = [word for word in tokenized_words if not word.lower() in stop_words and word.lower() not in string.punctuation] len(tokenized_words)上記のコード ブロックの説明:
- 「stopwords.words(“english”)」を使用してセットを作成し、英語のストップ ワードをすべて含めます。 Python セットには重複する値は含まれません。 したがって、競合を防ぐために、リストではなくセットを使用しました。
- 「if」および「else」ステートメントでリスト内包表記を使用します。
- 「lower」メソッドを使用して、「and」または「to」タイプの単語をストップ ワード リストの小文字バージョンと適切に比較します。
- 「文字列」モジュールを使用し、「句読点」を含めます。 ここで注意すべきことは、文字列モジュールには必要なすべての句読点が含まれていない可能性があるということです。 このような状況では、独自の句読点リストを作成し、正規表現と「regex.sub.」を使用してこれらの文字をスペースに置き換えます。
- オプションで、句読点やその他のアルファベット以外の数値を削除するには、Python 文字列の「isalnum」メソッドを使用できます。 ただし、フレーズに基づいて、異なる結果が得られる場合があります。 たとえば、単語の中央にある「-」は英数字ではないため、「isalnum」は「keyword-related」などの単語を削除します。 ただし、string.punctuation は「キーワード関連」は句読点ではないため、「-」は句読点であっても削除しません。
- 新しいリストの長さを測定します。
トークン化された単語リストの新しい長さは「5319」です。 ドキュメントのボキャブラリの半分近くがストップ ワードまたは句読点で構成されていることがわかります。
これは、単語の 54% のみが文脈的であり、残りは機能的であることを意味する場合があります。
7. Web ページのコンテンツ内の単語の出現回数を数えます
コーパスからの単語の出現をカウントするには、「コレクション」モジュールの「カウンター」オブジェクトを以下のように使用します。
counted_tokenized_words = Counter(tokenized_words) counts_of_words_df = pd.DataFrame.from_dict( counted_tokenized_words, orient="index").reset_index() counts_of_words_df.sort_values(by=0, ascending=False, inplace=True) counts_of_words_df.head(50)コードブロックの説明は以下です。
- 「counted_tokenized_words」などの変数を作成して、Counter メソッドの結果を含めます。
- Pandas の「DataFrame」コンストラクターを使用して、トークン化されてクリーンアップされたテキストの Counter メソッドの結果から新しいデータ フレームを構築します。
- 「Counter」は辞書オブジェクトを与えるため、「from_dict」メソッドを使用します。
- 行に基づいてソートすることを意味する「by=0」で「sort_values」を使用し、「ascending=False」は最大値を一番上に配置することを意味します。 「Inpace=True」は、ソートされた新しいバージョンを永続的にするためのものです。
- pandas の「head()」メソッドで最初の 50 行を呼び出して、データ フレームの最初の外観を確認します。
以下に結果を示します。
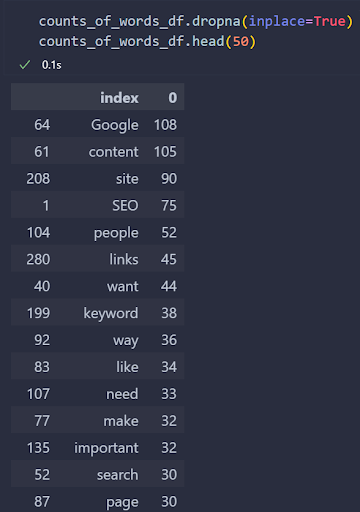 著者のスクリーンショット、2022 年 8 月
著者のスクリーンショット、2022 年 8 月結果にストップ ワードは表示されませんが、興味深い句読点がいくつか残っています。
これは、一部の Web サイトでは、カーリー クォーテーション (スマート クォーテーション)、ストレート シングル クォーテーション、ダブル ストレート クォーテーションなど、同じ目的で異なる文字を使用しているために発生します。
また、文字列モジュールの「関数」モジュールにはそれらが含まれていません。
したがって、データ フレームをきれいにするために、以下のようにカスタム ラムダ関数を使用します。
removed_curly_quotes = "'“”" counts_of_words_df["index"] = counts_of_words_df["index"].apply(lambda x: float("NaN") if x in removed_curly_quotes else x) counts_of_words_df.dropna(inplace=True) counts_of_words_df.head(50)コードブロックの説明:
- 「removed_curly_quotes」という名前の変数を作成して、カーリーの一重引用符、二重引用符、およびまっすぐな二重引用符を含めます。
- パンダの「適用」機能を使用して、可能な値を持つすべての列をチェックしました。
- Pandas の dropna メソッドを使用できるように、ラムダ関数を float(“NaN”) で使用しました。
- 特定のカーリー クォート バージョンを置き換える NaN 値を削除するには、「dropna」を使用します。 NaN 値を永続的に削除するには、「inplace=True」を追加します。
- データフレームの新しいバージョンを呼び出して確認します。
以下に結果を示します。
著者のスクリーンショット、2022 年 8 月「検索エンジン最適化」関連のランキング Web ドキュメントで最も使用されている単語を確認します。
Panda の「プロット」方法論を使用すると、以下のように簡単に視覚化できます。
counts_of_words_df.head(20).plot(kind="bar",x="index", orientation="vertical", figsize=(15,10), xlabel="Tokens", ylabel="Count", colormap="viridis", table=False, grid=True, fontsize=15, rot=35, position=1, title="Token Counts from a Website Content with Punctiation", legend=True).legend(["Tokens"], loc="lower left", prop={"size":15})上記のコード ブロックの説明:
- head メソッドを使用して、最初の意味のある値を確認し、視覚化を明確にします。
- 「棒グラフ」を表示するには、「種類」属性を指定して「プロット」を使用します。
- 単語を含む列を「x」軸に置きます。
- 方向属性を使用して、プロットの方向を指定します。
- 高さと幅を指定するタプルで figsize を決定します。
- x 軸と y 軸の名前に x と y のラベルを付けます。
- 「viridis」などの構造を持つカラーマップを決定します。
- フォント サイズ、ラベルの回転、ラベルの位置、プロットのタイトル、凡例の存在、凡例のタイトル、凡例の位置、および凡例のサイズを決定します。
Pandas DataFrame プロットは広範なトピックです。 「Plotly」を Pandas ビジュアライゼーション バックエンドとして使用する場合は、ニュース SEO のホット トピックのビジュアライゼーションを確認してください。
以下に結果を示します。
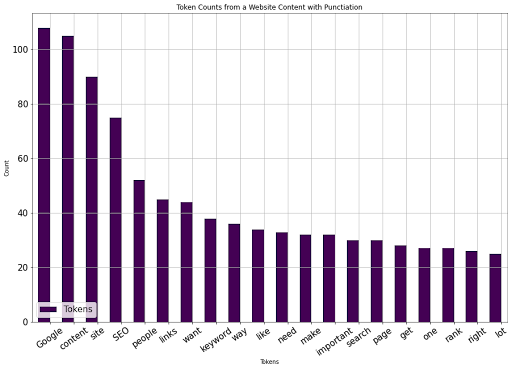 著者からの画像、2022 年 8 月
著者からの画像、2022 年 8 月ここで、2 番目の URL を選択して、語彙のサイズと単語の出現の比較を開始できます。

8. 語彙のサイズと単語の出現頻度を比較するために 2 番目の URL を選択します
以前の SEO コンテンツを競合する Web ドキュメントと比較するには、SEJ の SEO ガイドを使用します。 2 番目の記事では、これまでの手順を圧縮したバージョンをご覧いただけます。
def tokenize_visualize(article:int): stop_words = set(stopwords.words("english")) removed_curly_quotes = "'“”" tokenized_words = word_tokenize(crawled_df["body_text"][article]) print("Count of tokenized words:", len(tokenized_words)) tokenized_words = [word for word in tokenized_words if not word.lower() in stop_words and word.lower() not in string.punctuation and word.lower() not in removed_curly_quotes] print("Count of tokenized words after removal punctations, and stop words:", len(tokenized_words)) counted_tokenized_words = Counter(tokenized_words) counts_of_words_df = pd.DataFrame.from_dict( counted_tokenized_words, orient="index").reset_index() counts_of_words_df.sort_values(by=0, ascending=False, inplace=True) #counts_of_words_df["index"] = counts_of_words_df["index"].apply(lambda x: float("NaN") if x in removed_curly_quotes else x) counts_of_words_df.dropna(inplace=True) counts_of_words_df.head(20).plot(kind="bar", x="index", orientation="vertical", figsize=(15,10), xlabel="Tokens", ylabel="Count", colormap="viridis", table=False, grid=True, fontsize=15, rot=35, position=1, title="Token Counts from a Website Content with Punctiation", legend=True).legend(["Tokens"], loc="lower left", prop={"size":15})トークン化、ストップ ワードの削除、句読点、カーリー クォーテーションの置換、単語のカウント、データ フレームの構築、データ フレームの並べ替え、および視覚化のためにすべてを収集しました。
以下に、結果を示します。
 著者によるスクリーンショット、2022 年 8 月
著者によるスクリーンショット、2022 年 8 月SEJ記事は8位にランクイン。
tokenize_visualize(8)数字の 8 は、クロール出力データ フレームで 8 位にランクされていることを意味し、SEJ の SEO 記事と同じです。 以下に結果を示します。
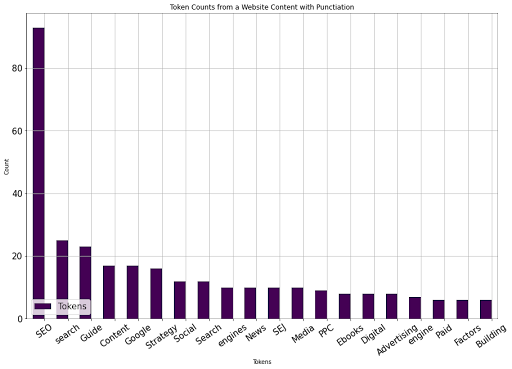 著者からの画像、2022 年 8 月
著者からの画像、2022 年 8 月SEJ SEO 記事と競合する他の SEO 記事では、最も使用されている 20 の単語が異なることがわかります。
9.単語の出現回数と語彙の違いの視覚化を自動化するカスタム関数を作成する
Python で SEO タスクを自動化するための基本的なステップは、さまざまな可能性を持つ特定の Python 関数の下にすべてのステップと必要性をラップすることです。
以下に示す関数には、条件ステートメントがあります。 単一の記事を渡す場合、単一の視覚化呼び出しが使用されます。 複数の場合、サブプロット数に従ってサブプロットを作成します。
def tokenize_visualize(articles:list, article:int=None): if article: stop_words = set(stopwords.words("english")) removed_curly_quotes = "'“”" tokenized_words = word_tokenize(crawled_df["body_text"][article]) print("Count of tokenized words:", len(tokenized_words)) tokenized_words = [word for word in tokenized_words if not word.lower() in stop_words and word.lower() not in string.punctuation and word.lower() not in removed_curly_quotes] print("Count of tokenized words after removal punctations, and stop words:", len(tokenized_words)) counted_tokenized_words = Counter(tokenized_words) counts_of_words_df = pd.DataFrame.from_dict( counted_tokenized_words, orient="index").reset_index() counts_of_words_df.sort_values(by=0, ascending=False, inplace=True) #counts_of_words_df["index"] = counts_of_words_df["index"].apply(lambda x: float("NaN") if x in removed_curly_quotes else x) counts_of_words_df.dropna(inplace=True) counts_of_words_df.head(20).plot(kind="bar", x="index", orientation="vertical", figsize=(15,10), xlabel="Tokens", ylabel="Count", colormap="viridis", table=False, grid=True, fontsize=15, rot=35, position=1, title="Token Counts from a Website Content with Punctiation", legend=True).legend(["Tokens"], loc="lower left", prop={"size":15}) if articles: source_names = [] for i in range(len(articles)): source_name = crawled_df["url"][articles[i]] print(source_name) source_name = urlparse(source_name) print(source_name) source_name = source_name.netloc print(source_name) source_names.append(source_name) global dfs dfs = [] for i in articles: stop_words = set(stopwords.words("english")) removed_curly_quotes = "'“”" tokenized_words = word_tokenize(crawled_df["body_text"][i]) print("Count of tokenized words:", len(tokenized_words)) tokenized_words = [word for word in tokenized_words if not word.lower() in stop_words and word.lower() not in string.punctuation and word.lower() not in removed_curly_quotes] print("Count of tokenized words after removal punctations, and stop words:", len(tokenized_words)) counted_tokenized_words = Counter(tokenized_words) counts_of_words_df = pd.DataFrame.from_dict( counted_tokenized_words, orient="index").reset_index() counts_of_words_df.sort_values(by=0, ascending=False, inplace=True) #counts_of_words_df["index"] = counts_of_words_df["index"].apply(lambda x: float("NaN") if x in removed_curly_quotes else x) counts_of_words_df.dropna(inplace=True) df_individual = counts_of_words_df dfs.append(df_individual) import matplotlib.pyplot as plt figure, axes = plt.subplots(len(articles), 1) for i in range(len(dfs) + 0): dfs[i].head(20).plot(ax = axes[i], kind="bar", x="index", orientation="vertical", figsize=(len(articles) * 10, len(articles) * 10), xlabel="Tokens", ylabel="Count", colormap="viridis", table=False, grid=True, fontsize=15, rot=35, position=1, title= f"{source_names[i]} Token Counts", legend=True).legend(["Tokens"], loc="lower left", prop={"size":15})記事を簡潔にするために、それらの説明は追加しません。 それでも、私が書いた以前の SEJ Python SEO チュートリアルを確認すると、同様のラッパー関数に気付くでしょう。
使ってみましょう。
tokenize_visualize(articles=[1, 8, 4])
1 番目、8 番目、4 番目の記事を取り上げて、上位 20 の単語とその出現箇所を視覚化したいと考えました。 以下の結果を見ることができます。
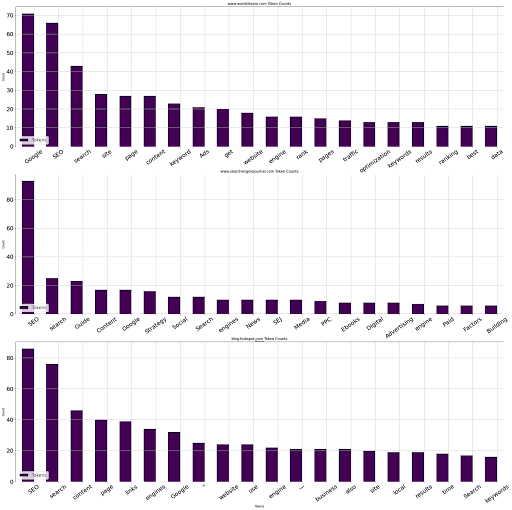 著者からの画像、2022 年 8 月
著者からの画像、2022 年 8 月10.文書間の一意の単語数を比較する
パンダのおかげで、ドキュメント間の一意の単語数を比較するのは非常に簡単です。 以下のカスタム関数を確認できます。
def compare_unique_word_count(articles:list): source_names = [] for i in range(len(articles)): source_name = crawled_df["url"][articles[i]] source_name = urlparse(source_name) source_name = source_name.netloc source_names.append(source_name) stop_words = set(stopwords.words("english")) removed_curly_quotes = "'“”" i = 0 for article in articles: text = crawled_df["body_text"][article] tokenized_text = word_tokenize(text) tokenized_cleaned_text = [word for word in tokenized_text if not word.lower() in stop_words if not word.lower() in string.punctuation if not word.lower() in removed_curly_quotes] tokenized_cleanet_text_counts = Counter(tokenized_cleaned_text) tokenized_cleanet_text_counts_df = pd.DataFrame.from_dict(tokenized_cleanet_text_counts, orient="index").reset_index().rename(columns={"index": source_names[i], 0: "Counts"}).sort_values(by="Counts", ascending=False) i += 1 print(tokenized_cleanet_text_counts_df, "Number of unique words: ", tokenized_cleanet_text_counts_df.nunique(), "Total contextual word count: ", tokenized_cleanet_text_counts_df["Counts"].sum(), "Total word count: ", len(tokenized_text)) compare_unique_word_count(articles=[1, 8, 4])結果は以下です。
結果の下部には、ドキュメント内の一意の単語の数を示す一意の値の数が表示されます。
www.wordstream.com カウント
16 グーグル 71
82 ソ 66
186 検索 43
228 サイト 28
274 27ページ
… … …
510 マークアップ/構造化 1
1 最近 1
514 間違い 1
515 下 1
1024 リンクトイン 1
【1025行×2列】 ユニークワード数:
www.wordstream.com 1025
カウント 24
dtype: int64 文脈上の総単語数: 2399 総単語数: 4918
www.searchenginejournal.com カウント
9 SEO 93
242 検索 25
64 ガイド 23
40 コンテンツ 17
13 グーグル 17
.. … …
229 アクション1
228 ムービング 1
227 アジャイル 1
226 32 1
465 ニュース 1
【466行×2列】 ユニークワード数:
www.searchenginejournal.com 466
カウント16
dtype: int64 文脈上の総単語数: 1019 総単語数: 1601
blog.hubspot.com カウント
166 SEO 86
160 検索 76
32 コンテンツ 46
368 ページ 40
327 リンク 39
… … …
695 アイデア 1
697話 1
698 以前 1
699 分析中 1
1326 セキュリティ 1
【1327行×2列】 ユニークワード数:
blog.hubspot.com 1327
カウント 31
dtype: int64 文脈上の総単語数: 3418 総単語数: 6728
2399 個の非ストップワードおよび非句読点の文脈上の単語のうち、1025 個の固有の単語があります。 総単語数は 4918 です。
最もよく使用される 5 つの単語は、「Google」、「SEO」、「検索」、「サイト」、および「Wordstream」の「ページ」です。 同じ番号の他のものを見ることができます。
11. SERP上のドキュメント間の語彙の違いを比較する
競合するドキュメントに表示される特徴的な単語を監査することで、ドキュメントの重要性がどこにあり、どのように違いが生じるかを確認できます。
方法論は単純です。「set」オブジェクト タイプには、2 つのセット間の異なる値を示す「difference」メソッドがあります。
def audit_vocabulary_difference(articles:list): stop_words = set(stopwords.words("english")) removed_curly_quotes = "'“”" global dfs global source_names source_names = [] for i in range(len(articles)): source_name = crawled_df["url"][articles[i]] source_name = urlparse(source_name) source_name = source_name.netloc source_names.append(source_name) i = 0 dfs = [] for article in articles: text = crawled_df["body_text"][article] tokenized_text = word_tokenize(text) tokenized_cleaned_text = [word for word in tokenized_text if not word.lower() in stop_words if not word.lower() in string.punctuation if not word.lower() in removed_curly_quotes] tokenized_cleanet_text_counts = Counter(tokenized_cleaned_text) tokenized_cleanet_text_counts_df = pd.DataFrame.from_dict(tokenized_cleanet_text_counts, orient="index").reset_index().rename(columns={"index": source_names[i], 0: "Counts"}).sort_values(by="Counts", ascending=False) tokenized_cleanet_text_counts_df.dropna(inplace=True) i += 1 df_individual = tokenized_cleanet_text_counts_df dfs.append(df_individual) global vocabulary_difference vocabulary_difference = [] for i in dfs: vocabulary = set(i.iloc[:, 0].to_list()) vocabulary_difference.append(vocabulary) print( "Words that appear on :", source_names[0], "but not on: ", source_names[1], "are below: \n", vocabulary_difference[0].difference(vocabulary_difference[1]))簡潔にするために、関数行を 1 つずつ説明することはしませんが、基本的には、複数の記事で固有の単語を取り上げて比較します。
以下に結果を示します。
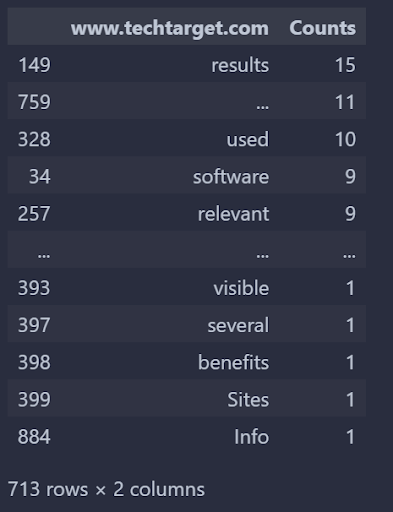
www.techtarget.com に表示され、moz.com には表示されない単語は次のとおりです。
 著者によるスクリーンショット、2022 年 8 月
著者によるスクリーンショット、2022 年 8 月以下のカスタム関数を使用して、これらの単語が特定の文書でどのくらいの頻度で使用されているかを確認してください。
def unique_vocabulry_weight(): audit_vocabulary_difference(articles=[3, 1]) vocabulary_difference_list = vocabulary_difference_df[0].to_list() return dfs[0][dfs[0].iloc[:, 0].isin(vocabulary_difference_list)] unique_vocabulry_weight()結果は以下のとおりです。
 著者によるスクリーンショット、2022 年 8 月
著者によるスクリーンショット、2022 年 8 月TechTarget の観点から見た「検索エンジン最適化」クエリの TechTarget と Moz の語彙の違いは上記のとおりです。 それを逆にすることができます。
def unique_vocabulry_weight(): audit_vocabulary_difference(articles=[1, 3]) vocabulary_difference_list = vocabulary_difference_df[0].to_list() return dfs[0][dfs[0].iloc[:, 0].isin(vocabulary_difference_list)] unique_vocabulry_weight()番号の順序を変更します。 別の観点からチェックします。
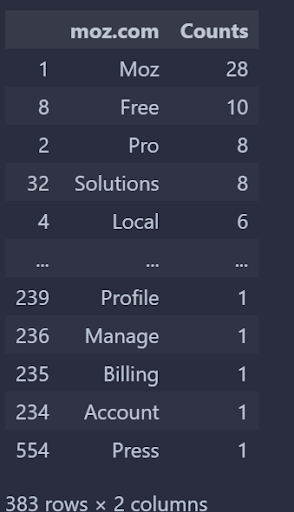 著者によるスクリーンショット、2022 年 8 月
著者によるスクリーンショット、2022 年 8 月Wordstream には、Boosmart には表示されない 868 個の固有の単語があることがわかります。上位 5 位と下位 5 位は、それらの出現とともに上に示されています。
語彙違い監査は、クエリ情報とネットワークをチェックすることで、「加重頻度」で改善できます。
ただし、教育目的のため、これはすでに、重く、詳細で、高度な Python、データ サイエンス、および SEO の集中コースです。
次のガイドとチュートリアルでお会いしましょう。
その他のリソース:
- Python + Streamlit を使用して、射程距離のキーワードの機会を見つける
- 検索クエリとキーワードの違いは何ですか?
- 高度なテクニカル SEO: 完全ガイド
主な画像:VectorMine / Shutterstock