
Apache Spark 如何為航空公司分析提供支持?
已發表: 2015-10-30全球航空業繼續快速增長,但持續強勁的盈利能力仍有待觀察。 根據國際航空運輸協會 (IATA) 的數據,該行業的收入在過去十年中翻了一番,從 2005 年的 3690 億美元增至 2015 年的預期 7270 億美元。

在商業航空領域,價值鏈中的每個參與者——機場、飛機製造商、噴氣發動機製造商、旅行社和服務公司都獲得了可觀的利潤。
由於較高的航班交易流失率,所有這些參與者都單獨生成了非常大量的數據。 識別和捕捉需求是這裡的關鍵,它為航空公司提供了更大的差異化機會。 因此,航空業可以利用大數據洞察力來提高銷售額並提高利潤率。
大數據是一個數據集集合的術語,該數據集如此龐大和復雜,以至於傳統的數據處理系統或現有的 DBMS 工具無法處理其計算。
Apache Spark 是一個開源的分佈式集群計算框架,專為交互式查詢和迭代算法而設計。
Spark DataFrame 抽像是一個表格數據對象,類似於 R 的原生 dataframe 或 Pythons pandas 包,但存儲在集群環境中。
根據《財富》最新調查,Apache Spark 是 2015 年最流行的技術。
最大的 Hadoop 供應商 Cloudera 也在向 Hadoop MapReduce 說再見,向 Spark 說你好。
真正讓 Spark 優於 Hadoop 的是速度。 Spark在內存中處理其大部分操作——將它們從分佈式物理存儲複製到速度更快的邏輯 RAM 內存中。 這減少了需要在 Hadoops MapReduce 系統下完成的緩慢、笨重的機械硬盤驅動器的寫入和讀取所消耗的時間。
此外,Spark 還包括精心設計的工具(實時處理、機器學習和交互式 SQL),用於支持業務目標,例如通過結合來自連接設備(也稱為物聯網)的歷史數據來分析實時數據。
今天,讓我們收集一些關於使用Apache Spark的示例機場數據的見解。
在之前的博客中,我們看到瞭如何使用新的 Dataframes API 在 Spark 中處理結構化和半結構化數據,還介紹瞭如何有效地處理 JSON 數據。
在這篇博客中,我們將了解如何使用 SQL 查詢 DataFrames 中的數據,以及如何將輸出以 CSV 格式保存到文件系統。
使用 Databricks CSV 解析庫
為此,我將使用 Databricks 提供的 CSV 解析庫,Databricks 是一家由 Apache Spark 的創建者創立的公司,目前負責處理 Spark 開發和分發。
Spark 社區由大約 600 名貢獻者組成,就貢獻者的數量而言,他們使其成為整個 Apache 軟件基金會(開源軟件的主要管理機構)中最活躍的項目。
Spark-csv 庫幫助我們在 spark 中解析和查詢 csv 數據。 我們可以使用這個庫來讀取和寫入任何 Hadoop 兼容文件系統的 csv 數據。
將數據加載到 Spark DataFrames
讓我們使用來自 Databricks 的 spark-csv 解析庫將我們的輸入文件加載到 Spark DataFrames 中。
您可以通過指定–packages com.databricks 在 Spark shell 中使用此庫:spark-csv_2.10:1.0.3
啟動shell時如下所示:
$ bin/spark-shell –packages com.databricks:spark-csv_2.10:1.0.3
請記住,您應該連接到互聯網,因為當您發出此命令時,會自動下載 spark-csv 包。 我正在使用 spark 1.4.0 版本
讓我們用已經創建的 SparkContext(sc) 對象創建 sqlContext
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
import sqlContext.implicits._
現在讓我們從 airports.csv (airport csv github) 文件加載我們的 csv 數據,其架構如下
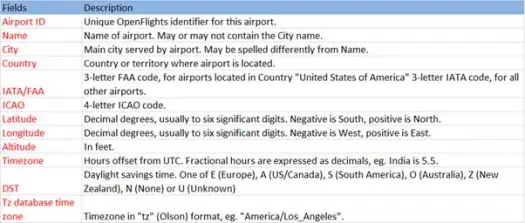
scala> val airportDF = sqlContext.load("com.databricks.spark.csv", Map("path" -> "/home /poonam/airports.csv", "header" -> "true"))加載操作將使用 Databricks spark-csv 庫解析 *.csv 文件,並返回一個列名與文件中第一個標題行相同的數據框。
以下是傳遞給 load 方法的參數。
- 來源: “com.databricks.spark.csv”告訴 spark 我們要加載為 csv 文件。
- 選項:
- path – 文件的路徑,它所在的位置。
- Header : "header" -> "true"告訴 spark 將文件的第一行映射到結果數據幀的列名。
讓我們看看我們的 Dataframe 的架構是什麼
查看我們數據框中的示例數據
scala> airportDF.show

使用臨時表查詢 CSV 數據:
要對錶執行查詢,我們調用 SQLContext 上的 sql() 方法。
我們創建了 airports DataFrame 並加載了 CSV 數據,要查詢這個 DF 數據,我們必須將其註冊為名為 airports 的臨時表。
>
scala> airportDF.registerTempTable("airports")
讓我們找出數據集中東南部有多少個機場
scala> sqlContext.sql("select AirportID, Name, Latitude, Longitude from airports where Latitude<0 and Longitude>0").collect.foreach(println)
[1,Goroka,-6.081689,145.391881]
[2,Madang,-5.207083,145.7887]
[3,Mount Hagen,-5.826789,144.295861
]
[4,Nadzab,-6.569828,146.726242]
[5,Port Moresby Jacksons Intl,-9.443383,147.22005]
[6,Wewak Intl,-3.583828,143.669186]

我們可以在 Spark 上的 sql 查詢中進行聚合
我們將找出每個國家有多少個獨特的城市有機場
scala> sqlContext.sql("select Country, count(distinct(City)) from airports group by Country").collect.foreach(println)
[Iceland,10]
[Greenland,4]
[Canada,131]
[Papua New Guinea,6]
每個國家/地區機場的平均海拔高度(英尺)是多少?
scala> sqlContext.sql("select Country , avg(Altitude) from airports group by Country").collect
res6: Array[org.apache.spark.sql.Row] =Array(
[Iceland,72.8],
[Greenland,202.75],
[Canada,852.6666666666666],
[Papua New Guinea,1849.0])
現在要了解每個時區有多少個機場正在運營?
scala> sqlContext.sql("select Tz , count(Tz) from airports group by Tz").collect.foreach(println)
[America/Dawson_Creek,1]
[America/Coral_Harbour,3]
[America/Halifax,9]
[America/Toronto,48]
[America/Vancouver,19]
[America/Godthab,3]
[Pacific/Port_Moresby,6]
[Atlantic/Reykjavik,10]
[America/Thule,1]
[America/St_Johns,4]
[America/Winnipeg,14]
[America/Edmonton,27]
[America/Regina,10]
我們還可以計算每個國家/地區這些機場的平均緯度和經度
scala> sqlContext.sql("select Country, avg(Latitude), avg(Longitude) from airports group by Country").collect.foreach(println)
[Iceland,65.0477736,-19.5969224]
[Greenland,67.22490275,-54.124131999999996]
[Canada,53.94868565185185,-93.950036237037]
[Papua New Guinea,-6.118766666666666,145.51532]
讓我們計算一下有多少不同的 DST
scala> sqlContext.sql("select count(distinct(DST)) from airports").collect.foreach(println)
[4]
以 CSV 格式保存數據
到目前為止,我們加載並查詢了 csv 數據。 現在我們將看到如何將結果以 CSV 格式保存回文件系統。
假設我們要向客戶發送有關所有國家西北部所有機場的報告。
讓我們先計算一下。
scala> val NorthWestAirportsDF=sqlContext.sql("select AirportID, Name, Latitude, Longitude from airports where Latitude>0 and Longitude<0")
NorthWestAirportsDF: org.apache.spark.sql.DataFrame = [AirportID: string, Name: string, Latitude: string, Longitude: string]
並將其保存為 CSV 文件
scala> NorthWestAirportsDF.save("com.databricks.spark.csv", org.apache.spark.sql.SaveMode.ErrorIfExists, Map("path" -> "/home/poonam/NorthWestAirports.csv","header"->"true"))
以下是傳遞給 save 方法的參數。
- 來源:它與加載方法com.databricks.spark.csv相同,它告訴 spark 將數據保存為 csv。
- SaveMode :如果給定的輸出路徑已經存在,這允許用戶提前指定需要做什麼。 這樣現有數據就不會被錯誤地丟失/覆蓋。 您可以拋出錯誤、追加或覆蓋。 在這裡,我們拋出了一個錯誤ErrorIfExists ,因為我們不想覆蓋任何現有文件。
- 選項:這些選項與我們傳遞給加載方法的選項相同。 選項:
- path – 文件的路徑,它應該被存儲在哪裡。
- Header : "header" -> "true"告訴 spark 將數據幀的列名映射到結果輸出文件的第一行。
將其他數據格式轉換為 CSV
我們還可以使用此庫將任何其他數據格式(如 JSON、parquet、文本)轉換為 CSV。
在之前的博客中,我們創建了 json 數據。 你可以在github上找到它
scala> val employeeDF = sqlContext.read.json("/home/poonam/employee.json")
讓我們將其保存為 CSV。
scala> employeeDF.save("com.databricks.spark.csv", org.apache.spark.sql.SaveMode.ErrorIfExists, Map("path" -> "/home/poonam/employee.csv", "header"->"true"))
結論:
在這篇文章中,我們使用SparkSQL交互式查詢收集了一些關於機場數據的見解
並探索了Spark 的 csv 解析庫
下一篇博客我們將探討 Spark 中非常重要的組件,即 Spark Streaming。
Spark Streaming 允許用戶將實時數據收集到 Spark 中並在發生時對其進行處理並立即給出結果。