
Ecossistema Hadoop e seus componentes
Publicados: 2015-04-23Big Data é a palavra da moda que circula no setor de TI desde 2008. A quantidade de dados gerados por redes sociais, manufatura, varejo, ações, telecomunicações, seguros, bancos e setores de saúde está muito além de nossa imaginação.
Antes do advento do Hadoop, o armazenamento e o processamento de big data eram um grande desafio. Mas agora que o Hadoop está disponível, as empresas perceberam o impacto do Big Data nos negócios e como a compreensão desses dados impulsionará o crescimento. Por exemplo:
• Os setores bancários têm mais chances de entender clientes fiéis, inadimplentes e transações fraudulentas.
• Os setores de varejo agora têm dados suficientes para prever a demanda.
• Os setores de manufatura não precisam depender de mecanismos caros para testes de qualidade. Capturar dados de sensores e analisá-los revelaria muitos padrões.
• E-Commerce, as redes sociais podem personalizar as páginas com base nos interesses dos clientes.
• Os mercados de ações geram uma enorme quantidade de dados, correlacionando-os de tempos em tempos, revelando belos insights.
Big Data tem muitas aplicações úteis e perspicazes.
O Hadoop é a resposta direta para o processamento de Big Data. O ecossistema Hadoop é uma combinação de tecnologias que têm vantagem proficiente na resolução de problemas de negócios.
Vamos entender os componentes do Hadoop Ecosytem para construir as soluções certas para um determinado problema de negócios.
Ecossistema Hadoop:
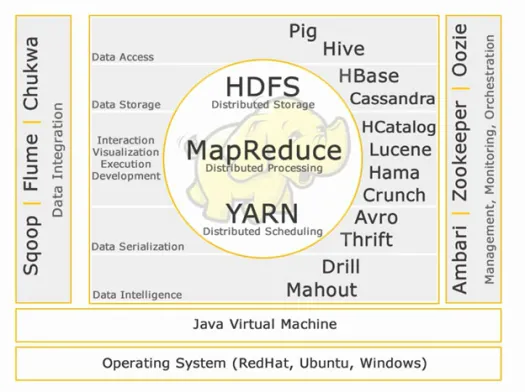

Núcleo Hadoop:
HDFS:
HDFS significa Hadoop Distributed File System para gerenciar grandes conjuntos de dados com alto volume, velocidade e variedade. O HDFS implementa a arquitetura mestre-escravo. O mestre é o nó de nome e o escravo é o nó de dados.
Recursos:
• Escalável
• De confiança
• Hardware de comodidade
HDFS é o bem conhecido para armazenamento de Big Data.
Reduzir mapa:
Map Reduce é um modelo de programação projetado para processar dados distribuídos de alto volume. A plataforma é construída usando Java para melhor manipulação de exceções. Map Reduce inclui dois deamons, Job tracker e Task Tracker.
Recursos:
• Programação Funcional.
• Funciona muito bem em Big Data.
• Pode processar grandes conjuntos de dados.
Map Reduce é o principal componente conhecido por processar big data.
FIO:
YARN significa mais um negociador de recursos. Também é chamado de MapReduce 2 (MRv2). As duas principais funcionalidades do Job Tracker no MRv1, gerenciamento de recursos e agendamento/monitoramento de trabalhos são divididos em daemons separados que são ResourceManager, NodeManager e ApplicationMaster.
Recursos:
• Melhor gerenciamento de recursos.
• Escalabilidade
• Alocação dinâmica de recursos de cluster.
Acesso de dados:
Porco:
Apache Pig é uma linguagem de alto nível construída em cima do MapReduce para analisar grandes conjuntos de dados com programas simples de análise de dados ad hoc. Pig também é conhecido como linguagem de fluxo de dados. Está muito bem integrado com python. É desenvolvido inicialmente pelo yahoo.
Características salientes do porco:
• Facilidade de programação
• Oportunidades de otimização
• Extensibilidade.
Os scripts Pig internamente serão convertidos em programas de redução de mapa.

Colmeia:
Apache Hive é outra linguagem de consulta de alto nível e infraestrutura de data warehouse construída sobre o Hadoop para fornecer resumo, consulta e análise de dados. Ele é inicialmente desenvolvido pelo yahoo e feito de código aberto.
Características salientes da colmeia:
• SQL como linguagem de consulta chamada HQL.
• Particionamento e bucketing para processamento de dados mais rápido.
• Integração com ferramentas de visualização como o Tableau.
As consultas do Hive internamente serão convertidas em programas de redução de mapa.
Se você quer se tornar um analista de big data, essas duas linguagens de alto nível são obrigatórias!!

Armazenamento de dados:
Hbase:
Apache HBase é um banco de dados NoSQL construído para hospedar grandes tabelas com bilhões de linhas e milhões de colunas em cima de máquinas de hardware Hadoop. Use o Apache Hbase quando precisar de acesso de leitura/gravação aleatório e em tempo real ao seu Big Data.
Recursos:
• Leituras e gravações estritamente consistentes. Nas operações de memória.
• API Java fácil de usar para acesso do cliente.
• Bem integrado com porco, colmeia e sqoop.
• É um sistema consistente e tolerante a partição no teorema CAP.

Cassandra:
Cassandra é um banco de dados NoSQL projetado para escalabilidade linear e alta disponibilidade. O Cassandra é baseado no modelo de valor-chave. Desenvolvido pelo Facebook e conhecido pela resposta mais rápida às consultas.
Recursos:
• Índices de coluna
• Suporte para desnormalização
• Visualizações materializadas
• Cache integrado poderoso.

Interação -Visualização-execução-desenvolvimento:
Catálogo H:

HCatalog é uma camada de gerenciamento de tabelas que fornece integração de metadados de hive para outros aplicativos Hadoop. Ele permite que usuários com diferentes ferramentas de processamento de dados, como Apache Pig, Apache MapReduce e Apache Hive, leiam e gravem dados com mais facilidade.
Recursos:
• Visualização tabular para diferentes formatos.
• Notificações de disponibilidade de dados.
• APIs REST para sistemas externos acessarem metadados.
Lucene:
Apache LuceneTM é uma biblioteca de mecanismo de pesquisa de texto de alto desempenho e com todos os recursos, escrita inteiramente em Java. É uma tecnologia adequada para praticamente qualquer aplicativo que exija pesquisa de texto completo, especialmente entre plataformas.
Recursos:
• Indexação escalável e de alto desempenho.
• Algoritmos de busca poderosos, precisos e eficientes.
• Solução multiplataforma.
Hama:
Apache Hama é um framework distribuído baseado em computação Bulk Synchronous Parallel (BSP). Capaz e bem conhecido por cálculos científicos massivos como algoritmos de matriz, gráfico e rede.
Recursos:
• Modelo de programação simples
• Adequado para algoritmos iterativos
• Suporte para YARN
• Aprendizado de máquina não supervisionado com filtragem colaborativa.
• Agrupamento de K-Means.
Crunch:
O Apache crunch foi desenvolvido para canalizar programas MapReduce que são simples e eficientes. Essa estrutura é usada para escrever, testar e executar pipelines MapReduce.
Recursos:
• Focado no desenvolvedor.
• Abstrações mínimas
• Modelo de dados flexível.
Serialização de dados:
Avro:
Apache Avro é uma estrutura de serialização de dados que é neutra em termos de linguagem. Projetado para portabilidade de idioma, permitindo que os dados potencialmente sobrevivam ao idioma para lê-lo e escrevê-lo.

Economia:
Thrift é uma linguagem desenvolvida para construir interfaces para interagir com tecnologias construídas no Hadoop. Ele é usado para definir e criar serviços para vários idiomas.
Inteligência de dados:
Furar:
Apache Drill é um mecanismo de consulta SQL de baixa latência para Hadoop e NoSQL.
Recursos:
• Agilidade
• Flexibilidade
• Familiaridade.

Mahout:
O Apache Mahout é uma biblioteca de aprendizado de máquina escalável projetada para criar análises preditivas em Big Data. Mahout agora tem implementações apache spark para mais rapidez na computação de memória.
Recursos:
• Filtragem colaborativa.
• Classificação
• Agrupamento
• Redução de dimensionalidade

Integração de dados:
Apache Sqoop:

Apache Sqoop é uma ferramenta projetada para transferências de dados em massa entre bancos de dados relacionais e o Hadoop.
Recursos:
• Importação e exportação de e para HDFS.
• Importação e exportação de e para Hive.
• Importação e exportação para HBase.
Apache Flume:
O Flume é um serviço distribuído, confiável e disponível para coletar, agregar e mover com eficiência grandes quantidades de dados de log.
Recursos:
• Robusto
• Tolerante a falhas
• Arquitetura simples e flexível baseada em fluxos de dados de streaming.

Apache Chukwa:
Coletor de log escalável usado para monitorar grandes sistemas de arquivos distribuídos.
Recursos:
• Escala para milhares de nós.
• Entrega confiável.
• Deve ser capaz de armazenar dados indefinidamente.

Gerenciamento, Monitoramento e Orquestração:
Apache Ambari:
O Ambari foi projetado para simplificar o gerenciamento de hadoop, fornecendo uma interface para provisionamento, gerenciamento e monitoramento de clusters Apache Hadoop.
Recursos:
• Provisione um cluster Hadoop.
• Gerenciar um cluster Hadoop.
• Monitorar um cluster do Hadoop.

Apache Zookeeper:
O Zookeeper é um serviço centralizado projetado para manter informações de configuração, nomear, fornecer sincronização distribuída e fornecer serviços de grupo.
Recursos:
• Serialização
• Atomicidade
• Confiabilidade
• API simples

Apache Oozie:
Oozie é um sistema de agendador de fluxo de trabalho para gerenciar tarefas do Apache Hadoop.
Recursos:
• Sistema escalável, confiável e extensível.
• Suporta vários tipos de tarefas do Hadoop, como Map-Reduce, Hive, Pig e Sqoop.
• Simples e fácil de usar.

Discutiremos sobre os componentes em detalhes nos próximos artigos. Fique ligado.