
Yandex raschia Google e altri apprendimenti SEO dalla fuga di codice sorgente
Pubblicato: 2023-01-31"Frammenti" della base di codice di Yandex sono trapelati online la scorsa settimana. Proprio come Google, Yandex è una piattaforma con molti aspetti come e-mail, mappe, un servizio di taxi, ecc. La perdita di codice presentava parti di tutto ciò.
Secondo la documentazione ivi contenuta, la base di codice di Yandex è stata ripiegata in un grande repository chiamato Arcadia nel 2013. La base di codice trapelata è un sottoinsieme di tutti i progetti in Arcadia e vi troviamo diversi componenti relativi al motore di ricerca nel "Kernel", "Libreria , "Robot", "Cerca" e "ExtSearch".
La mossa è del tutto senza precedenti. Non dai tempi dei dati delle query di ricerca di AOL del 2006 c'era qualcosa di così materiale relativo a un motore di ricerca web diventato di pubblico dominio.
Sebbene manchino i dati e molti file a cui viene fatto riferimento, questo è il primo esempio di uno sguardo tangibile su come funziona un moderno motore di ricerca a livello di codice.
Personalmente, non riesco a capire quanto sia fantastico il tempismo per poter effettivamente vedere il codice mentre finisco il mio libro "The Science of SEO" in cui parlo di Information Retrieval, come funzionano effettivamente i motori di ricerca moderni e come per costruirne uno semplice tu stesso.
In ogni caso, è da giovedì scorso che sto analizzando il codice e qualsiasi ingegnere ti dirà che non è abbastanza tempo per capire come funziona il tutto. Quindi, sospetto che ci saranno molti altri post mentre continuo ad armeggiare.
Prima di entrare, voglio ringraziare Ben Wills di Ontolo per aver condiviso il codice con me, indicandomi la direzione iniziale di dove si trovano le cose buone e andando avanti e indietro con me mentre decifravamo le cose. Sentiti libero di prendere il foglio di calcolo con tutti i dati che abbiamo raccolto qui sui fattori di ranking.
Inoltre, ringrazia Ryan Jones per aver scavato e condiviso alcuni risultati chiave con me tramite messaggistica istantanea.
Ok, diamoci da fare!
Non è il codice di Google, quindi perché ci interessa?
Alcuni credono che la revisione di questa base di codice sia una distrazione e che non ci sia nulla che influirà sul modo in cui prendono le decisioni aziendali. Lo trovo curioso considerando che si tratta di persone della stessa comunità SEO che ha utilizzato il modello CTR dei dati AOL del 2006 come standard del settore per la modellazione su qualsiasi motore di ricerca per molti anni a seguire.
Detto questo, Yandex non è Google. Eppure i due sono motori di ricerca web all'avanguardia che hanno continuato a rimanere all'avanguardia della tecnologia.
Gli ingegneri del software di entrambe le società partecipano alle stesse conferenze (SIGIR, ECIR, ecc.) e condividono scoperte e innovazioni nel recupero delle informazioni, nell'elaborazione/comprensione del linguaggio naturale e nell'apprendimento automatico. Yandex è presente anche a Palo Alto e Google in precedenza era presente a Mosca.
Una rapida ricerca su LinkedIn scopre alcune centinaia di ingegneri che hanno lavorato in entrambe le società, anche se non sappiamo quanti di loro abbiano effettivamente lavorato alla ricerca in entrambe le società.
In una sovrapposizione più diretta, Yandex utilizza anche le tecnologie open source di Google che sono state fondamentali per le innovazioni nella ricerca come TensorFlow, BERT, MapReduce e, in misura molto minore, Protocol Buffers.
Quindi, sebbene Yandex non sia certamente Google, non è nemmeno un progetto di ricerca casuale di cui stiamo parlando qui. C'è molto che possiamo imparare su come viene costruito un moderno motore di ricerca dalla revisione di questa base di codice.
Per lo meno, possiamo liberarci di alcune nozioni obsolete che ancora permeano gli strumenti SEO come i rapporti testo-codice e la conformità al W3C o la convinzione generale che i 200 segnali di Google siano semplicemente 200 singole funzionalità all'interno e all'esterno della pagina piuttosto che classi di fattori compositi che potenzialmente utilizzano migliaia di misure individuali.
Qualche contesto sull'architettura di Yandex
Senza il contesto o la capacità di compilarlo, eseguirlo e analizzarlo correttamente, è molto difficile dare un senso al codice sorgente.
In genere, i nuovi ingegneri ottengono documentazione, procedure dettagliate e si impegnano nella programmazione in coppia per essere inseriti in una base di codice esistente. Inoltre, nell'archivio dei documenti è presente una documentazione di onboarding limitata relativa all'impostazione del processo di compilazione. Tuttavia, il codice di Yandex fa riferimento anche a wiki interni, ma questi non sono trapelati e anche i commenti nel codice sono piuttosto scarsi.
Fortunatamente, Yandex fornisce alcuni spunti sulla sua architettura nella sua documentazione pubblica. Ci sono anche un paio di brevetti che hanno pubblicato negli Stati Uniti che aiutano a fare un po' di luce. Vale a dire:
- Metodo e sistema implementati da computer per la ricerca in un indice invertito avente una pluralità di elenchi di invio
- Classifica dei risultati di ricerca
Mentre facevo ricerche su Google per il mio libro, ho sviluppato una comprensione molto più profonda della struttura dei suoi sistemi di classificazione attraverso vari white paper, brevetti e discorsi di ingegneri espressi contro la mia esperienza SEO. Ho anche passato molto tempo ad affinare la mia comprensione delle migliori pratiche generali di recupero delle informazioni per i motori di ricerca web. Non sorprende che ci siano effettivamente alcune best practice e somiglianze in gioco con Yandex.
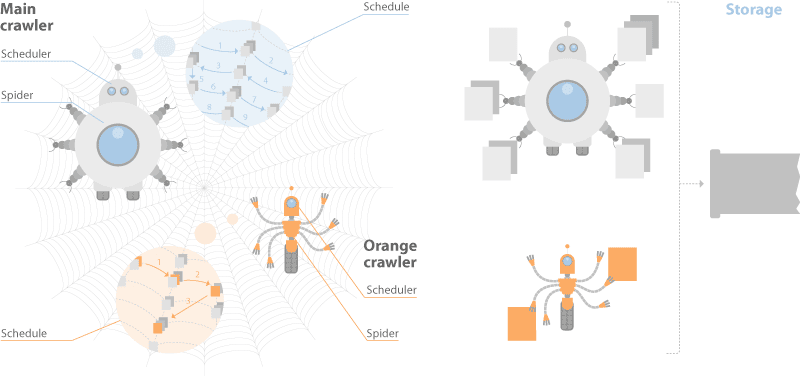
La documentazione di Yandex parla di un sistema crawler a doppia distribuzione. Uno per la scansione in tempo reale chiamato "Orange Crawler" e un altro per la scansione generale.
Storicamente, si dice che Google abbia avuto un indice stratificato in tre bucket, uno per la scansione in tempo reale dell'alloggiamento, uno per la scansione regolare e uno per la scansione rara. Questo approccio è considerato una best practice in IR.
Yandex e Google differiscono sotto questo aspetto, ma l'idea generale di scansione segmentata guidata dalla comprensione della frequenza di aggiornamento è valida.
Una cosa che vale la pena sottolineare è che Yandex non ha un sistema di rendering separato per JavaScript. Lo dicono nella loro documentazione e, sebbene dispongano di un sistema basato su Webdriver per i test di regressione visiva chiamato Gemini, si limitano alla scansione basata su testo.
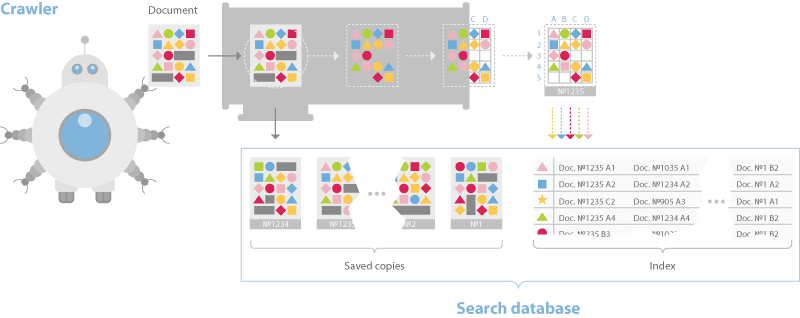
La documentazione discute anche una struttura di database frammentata che suddivide le pagine in un indice invertito e un server di documenti.
Proprio come la maggior parte degli altri motori di ricerca Web, il processo di indicizzazione crea un dizionario, memorizza nella cache le pagine e quindi inserisce i dati nell'indice invertito in modo tale da rappresentare bigrammi e trigrammi e il loro posizionamento nel documento.
Ciò differisce da Google in quanto sono passati all'indicizzazione basata su frasi, il che significa n-grammi che possono essere molto più lunghi dei trigrammi molto tempo fa.
Tuttavia, il sistema Yandex utilizza anche BERT nella sua pipeline, quindi a un certo punto i documenti e le query vengono convertiti in incorporamenti e le tecniche di ricerca del vicino più vicino vengono impiegate per il posizionamento.
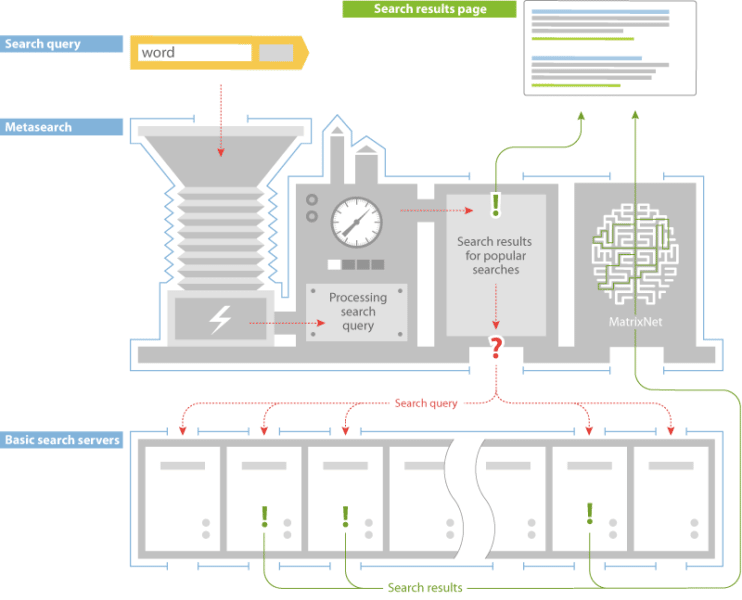
Il processo di classificazione è dove le cose iniziano a diventare più interessanti.
Yandex ha un livello chiamato Metasearch in cui i risultati di ricerca popolari memorizzati nella cache vengono offerti dopo aver elaborato la query. Se i risultati non vengono trovati lì, la query di ricerca viene inviata simultaneamente a una serie di migliaia di macchine diverse nel livello di ricerca di base . Ognuno crea un elenco di pubblicazione di documenti pertinenti, quindi lo restituisce a MatrixNet, l'applicazione di rete neurale di Yandex per il riposizionamento, per creare la SERP.
Sulla base dei video in cui gli ingegneri di Google hanno parlato dell'infrastruttura della Ricerca, il processo di classificazione è abbastanza simile alla Ricerca Google. Parlano della tecnologia di Google che si trova in ambienti condivisi in cui varie applicazioni sono su ogni macchina e i lavori sono distribuiti su quelle macchine in base alla disponibilità della potenza di calcolo.
Uno dei casi d'uso è esattamente questo, la distribuzione di query a un assortimento di macchine per elaborare rapidamente i frammenti di indice pertinenti. Il calcolo degli elenchi di invio è il primo posto che dobbiamo considerare i fattori di ranking.
Ci sono 17.854 fattori di ranking nella base di codice
Il venerdì successivo alla fuga di notizie, l'inimitabile Martin MacDonald ha condiviso con entusiasmo un file dalla base di codice chiamato web_factors_info/factors_gen.in. Il file proviene dall'archivio "Kernel" nella perdita della base di codice e presenta 1.922 fattori di classificazione.
Naturalmente, la comunità SEO ha funzionato con quel numero e quel file per diffondere con entusiasmo notizie delle intuizioni in esso contenute. Molte persone hanno tradotto le descrizioni e creato strumenti o Fogli Google e ChatGPT per dare un senso ai dati. Tutti ottimi esempi del potere della comunità. Tuttavia, il 1.922 rappresenta solo uno dei molti insiemi di fattori di classificazione nella base di codice.
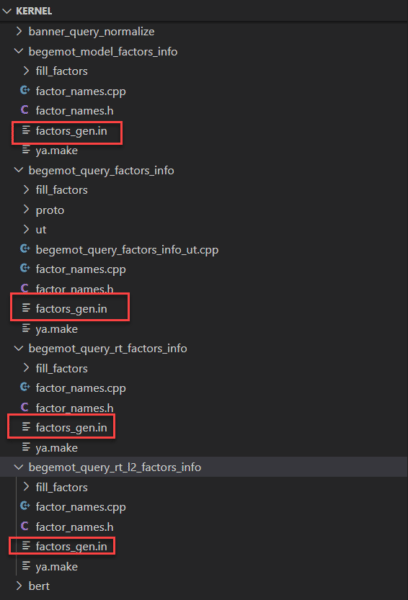
Un'analisi più approfondita della base di codice rivela che esistono numerosi file dei fattori di classificazione per diversi sottoinsiemi dei sistemi di elaborazione delle query e classificazione di Yandex.
Spulciandoli, scopriamo che in realtà ci sono 17.854 fattori di ranking in totale. Inclusi in questi fattori di ranking vi sono una serie di metriche relative a:
- Clic.
- Tempo di sosta.
- Sfruttando l'equivalente di Google Analytics di Yandex, Metrika.
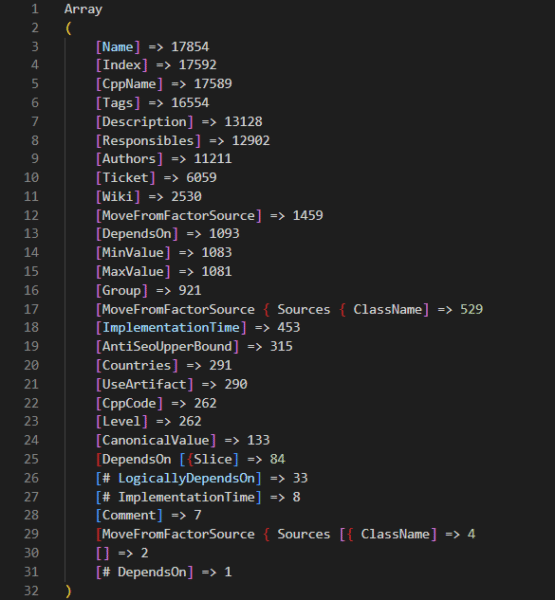
Esiste anche una serie di notebook Jupyter che hanno altri 2.000 fattori oltre a quelli nel codice principale. Presumibilmente, questi notebook Jupyter rappresentano test in cui gli ingegneri stanno prendendo in considerazione fattori aggiuntivi da aggiungere alla base di codice. Ancora una volta, puoi rivedere tutte queste funzionalità con i metadati che abbiamo raccolto da tutta la base di codice a questo link.
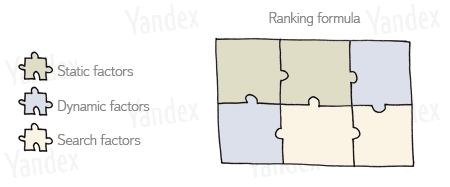
La documentazione di Yandex chiarisce inoltre che hanno tre classi di fattori di ranking: statico, dinamico e quelli relativi specificamente alla ricerca dell'utente e al modo in cui è stata eseguita. Con le loro stesse parole:

Nella codebase questi sono indicati nei file dei fattori di rango con i tag TG_STATIC e TG_DYNAMIC. I fattori relativi alla ricerca hanno più tag come TG_QUERY_ONLY, TG_QUERY, TG_USER_SEARCH e TG_USER_SEARCH_ONLY.
Mentre abbiamo scoperto un potenziale fattore di ranking 18k tra cui scegliere, la documentazione relativa a MatrixNet indica che il punteggio è costruito da decine di migliaia di fattori e personalizzato in base alla query di ricerca.

Ciò indica che l'ambiente di ranking è altamente dinamico, simile a quello dell'ambiente Google. Secondo il brevetto "Framework per la valutazione delle funzioni di punteggio" di Google, hanno a lungo avuto qualcosa di simile in cui vengono eseguite più funzioni e viene restituito il miglior set di risultati.
Infine, considerando che la documentazione fa riferimento a decine di migliaia di fattori di ranking, dovremmo anche tenere presente che ci sono molti altri file referenziati nel codice che mancano dall'archivio. Quindi, probabilmente sta succedendo di più che non siamo in grado di vedere. Ciò è ulteriormente illustrato esaminando le immagini nella documentazione di onboarding che mostra altre directory che non sono presenti nell'archivio.
Ad esempio, sospetto che ci sia qualcosa di più correlato al DSSM nella directory /semantic-search/.
La ponderazione iniziale dei fattori di ranking
Per prima cosa ho operato partendo dal presupposto che la base di codice non avesse alcun peso per i fattori di classificazione. Poi sono rimasto scioccato nel vedere che il file nav_linear.h nella directory /search/relevance/ presenta i coefficienti iniziali (o pesi) associati ai fattori di ranking a schermo intero.
Questa sezione del codice evidenzia 257 degli oltre 17.000 fattori di ranking che abbiamo identificato. ( Mancia di cappello a Ryan Jones per averli estratti e allineati con le descrizioni dei fattori di ranking.)
Per chiarezza, quando pensi all'algoritmo di un motore di ricerca, probabilmente stai pensando a una lunga e complessa equazione matematica in base alla quale ogni pagina viene valutata in base a una serie di fattori. Sebbene questa sia una semplificazione eccessiva, lo screenshot seguente è un estratto di tale equazione. I coefficienti rappresentano l'importanza di ciascun fattore e il punteggio calcolato risultante è quello che verrebbe utilizzato per valutare la pertinenza delle pagine di selezione.

Il fatto che questi valori siano hardcoded suggerisce che questo non è certamente l'unico posto in cui avviene la classifica. Invece, questa funzione è molto probabile dove viene eseguito il punteggio di pertinenza iniziale per generare una serie di elenchi di pubblicazione per ogni frammento preso in considerazione per la classifica. Nel primo brevetto sopra elencato, ne parlano come un concetto di rilevanza indipendente dalla query (QIR) che quindi limita i documenti prima di esaminarli per rilevanza specifica della query (QSR).
Gli elenchi di pubblicazione risultanti vengono quindi trasferiti a MatrixNet con funzionalità di query da confrontare. Quindi, anche se non conosciamo (ancora) le specifiche delle operazioni a valle, questi pesi sono comunque preziosi da comprendere perché ti dicono i requisiti affinché una pagina sia idonea per l'insieme di considerazione.
Tuttavia, questo fa sorgere la domanda successiva: cosa sappiamo di MatrixNet?
C'è un codice di classificazione neurale nell'archivio del kernel e ci sono numerosi riferimenti a MatrixNet e "mxnet", così come molti riferimenti a Deep Structured Semantic Models (DSSM) in tutta la base di codice.
La descrizione di uno dei fattori di ranking FI_MATRIXNET indica che MatrixNet è applicato a tutti i fattori.
Fattore {
Indice: 160
Nome Cpp: "FI_MATRIXNET"
Nome: “MatrixNet”
Tag: [TG_DOC, TG_DYNAMIC, TG_TRANS, TG_NOT_01, TG_REARR_USE, TG_L3_MODEL_VALUE, TG_FRESHNESS_FROZEN_POOL]
Descrizione: “MatrixNet si applica a tutti i fattori – la formula”
}
Ci sono anche un sacco di file binari che potrebbero essere gli stessi modelli pre-addestrati, ma mi ci vorrà più tempo per svelare quegli aspetti del codice.
Ciò che è subito chiaro è che ci sono più livelli di classifica (L1, L2, L3) e c'è un assortimento di modelli di classifica che possono essere selezionati a ogni livello.
Il file selection_rankings_model.cpp suggerisce che diversi modelli di classificazione possono essere considerati a ogni livello durante il processo. Questo è fondamentalmente il modo in cui funzionano le reti neurali. Ogni livello è un aspetto che completa le operazioni e i loro calcoli combinati producono l'elenco riclassificato di documenti che alla fine appare come SERP. Seguirò un'immersione profonda su MatrixNet quando avrò più tempo. Per coloro che hanno bisogno di un'anteprima, dai un'occhiata al brevetto del ranking dei risultati di ricerca.
Per ora, diamo un'occhiata ad alcuni interessanti fattori di ranking.
I primi 5 fattori di ranking iniziali ponderati negativamente
Di seguito è riportato un elenco dei fattori di classificazione iniziale con la ponderazione negativa più elevata con i relativi pesi e una breve spiegazione basata sulle loro descrizioni tradotte dal russo.

- FI_ADV: -0.2509284637 -Questo fattore determina la presenza di pubblicità di qualsiasi tipo sulla pagina e applica la penalità ponderata più pesante per un singolo fattore di ranking.
- FI_DATER_AGE: -0.2074373667 – Questo fattore è la differenza tra la data corrente e la data del documento determinata da una funzione data. Il valore è 1 se la data del documento è la stessa di oggi, 0 se il documento ha 10 anni o più o se la data non è definita. Ciò indica che Yandex ha una preferenza per i contenuti meno recenti.
- FI_QURL_STAT_POWER: -0.1943768768 – Questo fattore è il numero di impressioni URL in relazione alla query. Sembra che vogliano retrocedere un URL che appare in molte ricerche per promuovere la diversità dei risultati.
- FI_COMM_LINKS_SEO_HOSTS: -0.1809636391 – Questo fattore è la percentuale di link in entrata con anchor text “commerciale”. Il fattore ritorna a 0,1 se la proporzione di tali collegamenti è superiore al 50%, altrimenti viene impostato a 0.
- FI_GEO_CITY_URL_REGION_COUNTRY: -0.168645758 – Questo fattore è la coincidenza geografica del documento e del paese da cui l'utente ha effettuato la ricerca. Questo non ha molto senso se 1 significa che il documento e il paese corrispondono.
In sintesi, questi fattori indicano che, per ottenere il miglior punteggio, dovresti:
- Evita gli annunci.
- Aggiorna i contenuti meno recenti piuttosto che creare nuove pagine.
- Assicurati che la maggior parte dei tuoi link abbia un testo di ancoraggio con marchio.
Tutto il resto in questo elenco è al di fuori del tuo controllo.
I primi 5 fattori di ranking iniziali ponderati positivamente
Per seguire, ecco un elenco dei fattori di ranking positivi ponderati più alti.
- FI_URL_DOMAIN_FRACTION: +0.5640952971 – Questo fattore è una strana sovrapposizione di mascheramento della query rispetto al dominio dell'URL. L'esempio fornito è la lotteria di Chelyabinsk, abbreviata in chelloto. Per calcolare questo valore, Yandex trova le tre lettere coperte (che, hel, lot, olo), guarda quale proporzione di tutte le combinazioni di tre lettere si trova nel nome di dominio.
- FI_QUERY_DOWNER_CLICKS_COMBO: +0.3690780393 – La descrizione di questo fattore è che è "abilmente combinato di FRC e pseudo-CTR". Non vi è alcuna indicazione immediata di cosa sia FRC.
- FI_MAX_WORD_HOST_CLICKS: +0.3451158835 – Questo fattore è la cliccabilità della parola più importante nel dominio. Ad esempio, per tutte le query in cui è presente la parola “wikipedia” cliccare sulle pagine di wikipedia.
- FI_MAX_WORD_HOST_YABAR: +0.3154394573 – La descrizione del fattore dice "la parola di ricerca più caratteristica corrispondente al sito, secondo la barra". Suppongo che questo significhi la parola chiave più cercata in Yandex Toolbar associata al sito.
- FI_IS_COM: +0.2762504972 – Il fattore è che il dominio è un .COM.
In altre parole:
- Gioca a giochi di parole con il tuo dominio.
- Assicurati che sia un punto com.
- Incoraggia le persone a cercare le tue parole chiave target nella barra Yandex.
- Continua a generare clic.
Ci sono molti fattori di ranking iniziali inaspettati
La cosa più interessante nei fattori di ranking ponderati iniziali sono quelli inaspettati. Di seguito è riportato un elenco di diciassette fattori che si sono distinti.
- FI_PAGE_RANK: +0.1828678331 – PageRank è il 17° fattore ponderato più alto in Yandex. In precedenza avevano rimosso completamente i collegamenti dal loro sistema di classificazione, quindi non è troppo scioccante quanto sia in basso nell'elenco.
- FI_SPAM_KARMA: +0.00842682963 – Lo Spam karma prende il nome da “antispammer” ed è la probabilità che l'host sia spam; sulla base di informazioni Whois
- FI_SUBQUERY_THEME_MATCH_A: +0.1786465163 – La corrispondenza tematica tra la query e il documento. Questo è il diciannovesimo fattore ponderato più alto.
- FI_REG_HOST_RANK: +0.1567124399 – Yandex ha un fattore di ranking host (o dominio).
- FI_URL_LINK_PERCENT: +0.08940421124 – Rapporto tra link il cui testo di ancoraggio è un URL (piuttosto che testo) rispetto al numero totale di link.
- FI_PAGE_RANK_UKR: +0.08712279101 – C'è un PageRank ucraino specifico
- FI_IS_NOT_RU: +0.08128946612 – È positivo se il dominio non è un .RU. Apparentemente, il motore di ricerca russo non si fida dei siti russi.
- FI_YABAR_HOST_AVG_TIME2: +0.07417219313 – Questo è il tempo di permanenza medio riportato da YandexBar
- FI_LERF_LR_LOG_RELEV: +0.06059448504 – Questa è la pertinenza del collegamento basata sulla qualità di ciascun collegamento
- FI_NUM_SLASHES: +0.05057609417 – Il numero di barre nell'URL è un fattore di ranking.
- FI_ADV_PRONOUNS_PORTION: -0.001250755075 – La proporzione dei pronomi nella pagina.
- FI_TEXT_HEAD_SYN: -0.01291908335 – La presenza di parole [query] nell'intestazione, tenendo conto dei sinonimi
- FI_PERCENT_FREQ_WORDS: -0.02021022114 – La percentuale del numero di parole, ovvero le 200 parole più frequenti della lingua, dal numero di tutte le parole del testo.
- FI_YANDEX_ADV: -0.09426121965 – Diventando più specifico con il disgusto verso gli annunci, Yandex penalizza le pagine con annunci Yandex.
- FI_AURA_DOC_LOG_SHARED: -0.09768630485 – Il logaritmo del numero di herpes zoster (aree di testo) nel documento che non sono univoche.
- FI_AURA_DOC_LOG_AUTHOR: -0.09727752961 – Il logaritmo del numero di herpes zoster su cui questo proprietario del documento è riconosciuto come autore.
- FI_CLASSIF_IS_SHOP: -0.1339319854 – Apparentemente, Yandex ti darà meno amore se la tua pagina è un negozio.
L'aspetto principale della revisione di questi strani fattori di classificazione e della gamma di quelli disponibili nella base di codice Yandex è che ci sono molte cose che potrebbero essere un fattore di classificazione.
Sospetto che i "200 segnali" segnalati da Google siano in realtà 200 classi di segnale in cui ogni segnale è un composto composto da molti altri componenti. Più o meno allo stesso modo in cui Google Analytics ha dimensioni con molte metriche associate, la Ricerca Google ha probabilmente classi di segnali di ranking composte da molte funzioni.
Yandex raschia Google, Bing, YouTube e TikTok
La base di codice rivela anche che Yandex ha molti parser per altri siti Web e i rispettivi servizi. Per gli occidentali, i più notevoli sono quelli che ho elencato nel titolo sopra. Inoltre, Yandex ha parser per una varietà di servizi che non conoscevo così come quelli per i propri servizi.
Ciò che è immediatamente evidente è che i parser sono completi di funzionalità. Ogni componente significativo della SERP di Google viene estratto. In effetti, chiunque stia prendendo in considerazione l'idea di eseguire lo scraping di uno di questi servizi potrebbe fare bene a rivedere questo codice.
C'è un altro codice che indica che Yandex sta utilizzando alcuni dati di Google come parte dei calcoli DSSM, ma gli stessi 83 fattori di classificazione denominati da Google chiariscono che Yandex si è appoggiato piuttosto pesantemente ai risultati di Google.
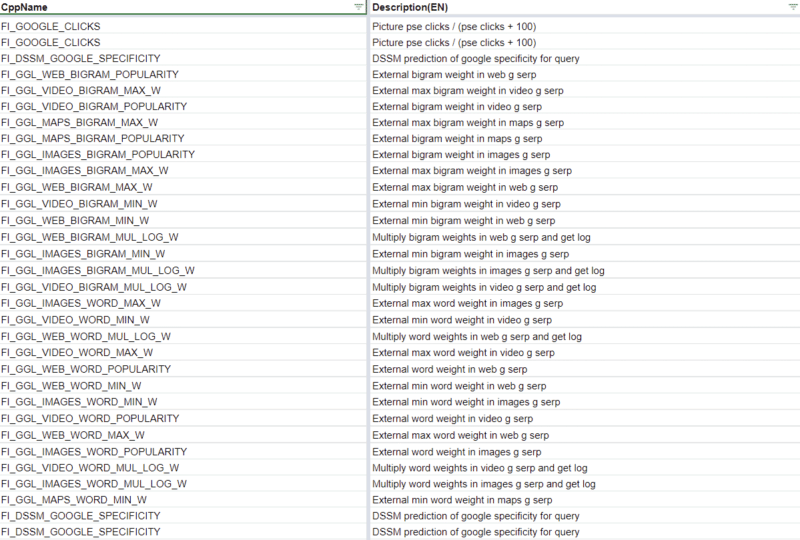
Ovviamente, Google non farebbe mai la mossa di Bing di copiare i risultati di un altro motore di ricerca né fare affidamento su uno per i calcoli del ranking principale.
Yandex ha limiti superiori anti-SEO per alcuni fattori di ranking
315 fattori di ranking hanno soglie alle quali qualsiasi valore calcolato al di là di quello indica al sistema che quella caratteristica della pagina è eccessivamente ottimizzata. 39 di questi fattori di ranking fanno parte dei fattori ponderati inizialmente che possono impedire a una pagina di essere inclusa nell'elenco dei post iniziali. Puoi trovarli nel foglio di calcolo che ho collegato sopra filtrando per il coefficiente di rango e la colonna anti-SEO.
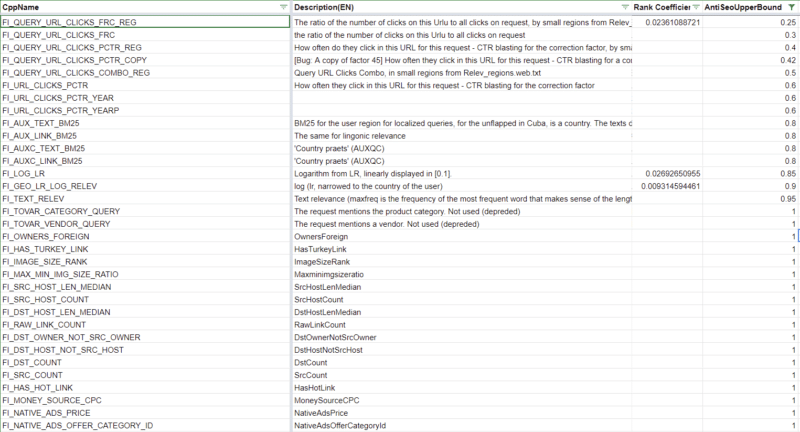
Concettualmente non è inverosimile aspettarsi che tutti i moderni motori di ricerca fissino soglie su determinati fattori di cui i SEO hanno storicamente abusato come anchor text, CTR o keyword stuffing. Ad esempio, si diceva che Bing sfruttasse l'uso abusivo delle meta parole chiave come fattore negativo.
Yandex potenzia gli "host vitali"
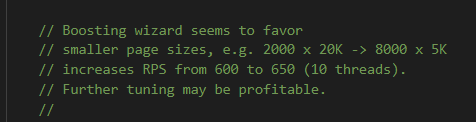
Yandex ha una serie di meccanismi di potenziamento in tutta la sua base di codice. Si tratta di miglioramenti artificiali a determinati documenti per garantire che ottengano punteggi più alti quando vengono presi in considerazione per la classifica.
Di seguito è riportato un commento della "procedura guidata di potenziamento" che suggerisce che i file più piccoli beneficiano al meglio dell'algoritmo di potenziamento.
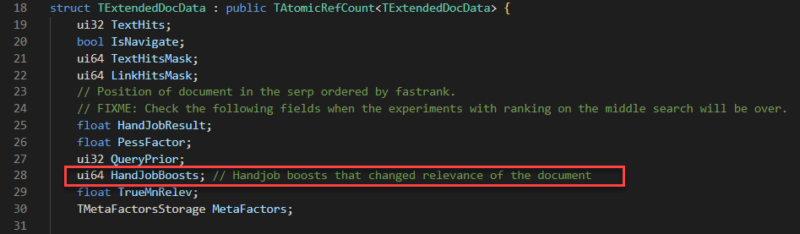
Esistono diversi tipi di boost; Ho visto un potenziamento relativo ai collegamenti e ho visto anche una serie di "HandJobBoost" che posso solo supporre sia una strana traduzione di modifiche "manuali".
Uno di questi potenziamenti che ho trovato particolarmente interessante è legato a "Vital Host". Dove un host vitale può essere qualsiasi sito specificato. Specificamente menzionato nelle variabili è NEWS_AGENCY_RATING, il che mi porta a credere che Yandex dia una spinta che distorce i suoi risultati a determinate testate giornalistiche.
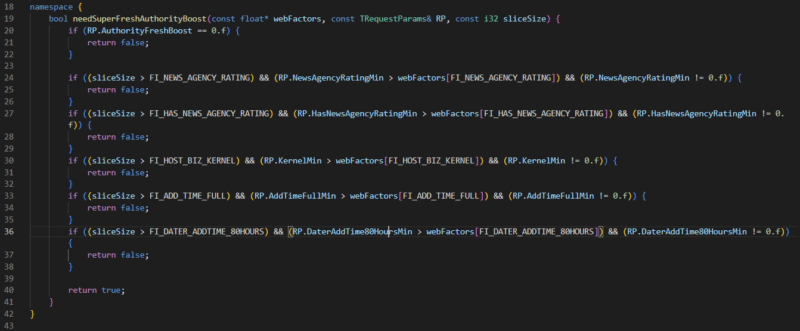
Senza entrare nella geopolitica, questo è molto diverso da Google in quanto sono stati irremovibili nel non introdurre pregiudizi come questo nei loro sistemi di ranking.
La struttura del server di documenti
La base di codice rivela come i documenti vengono archiviati nel server di documenti di Yandex. Questo è utile per capire che un motore di ricerca non crea semplicemente una copia della pagina e la salva nella sua cache, ma acquisisce varie caratteristiche come metadati da utilizzare poi nel processo di posizionamento a valle.
Lo screenshot qui sotto evidenzia un sottoinsieme di quelle caratteristiche che sono particolarmente interessanti. Altri file con query SQL suggeriscono che il server del documento ha più di 200 colonne tra cui l'albero DOM, la lunghezza delle frasi, il tempo di recupero, una serie di date e il punteggio antispam, la catena di reindirizzamento e se il documento è tradotto o meno. L'elenco più completo che ho trovato è in /robot/rthub/yql/protos/web_page_item.proto.
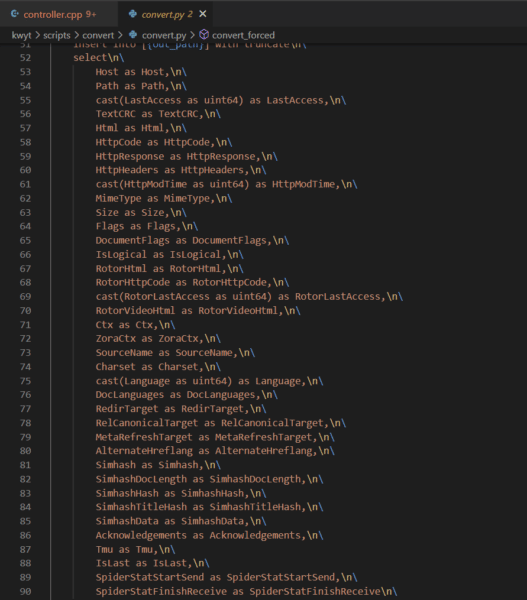
La cosa più interessante nel sottoinsieme qui è il numero di simhash impiegati. I simhash sono rappresentazioni numeriche del contenuto e i motori di ricerca li utilizzano per un confronto fulmineo per la determinazione del contenuto duplicato. Ci sono vari casi nell'archivio del robot che indicano che il contenuto duplicato è esplicitamente retrocesso.

Inoltre, come parte del processo di indicizzazione, la base di codice include TF-IDF, BM25 e BERT nella sua pipeline di elaborazione del testo. Non è chiaro perché tutti questi meccanismi esistano nel codice perché c'è una certa ridondanza nell'usarli tutti.
Fattori di collegamento e priorità
Il modo in cui Yandex gestisce i fattori di collegamento è particolarmente interessante perché in precedenza ne disabilitavano del tutto l'impatto. La base di codice rivela anche molte informazioni sui fattori di collegamento e su come viene assegnata la priorità ai collegamenti.
Il calcolatore di link spam di Yandex ha 89 fattori che esamina. Tutto ciò che è contrassegnato come SF_RESERVED è deprecato. Dove previsto, puoi trovare le descrizioni di questi fattori nel Foglio Google linkato sopra.
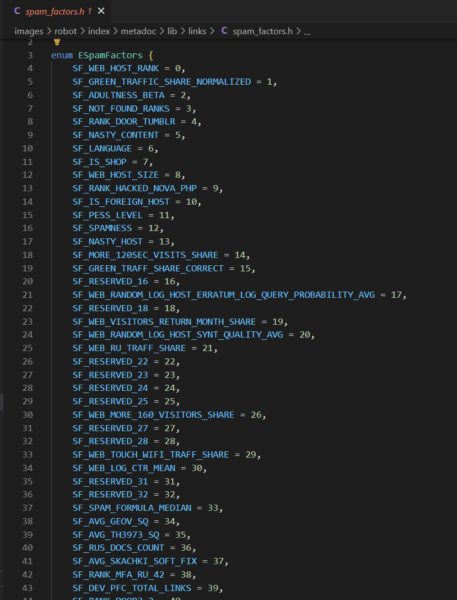
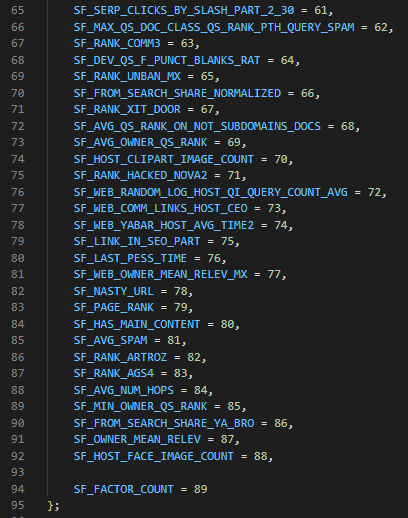
In particolare, Yandex ha un host rank e alcuni punteggi che sembrano vivere a lungo termine dopo che un sito o una pagina ha sviluppato una reputazione per lo spam.
Un'altra cosa che Yandex fa è rivedere la copia in un dominio e determinare se ci sono contenuti duplicati con quei collegamenti. Può trattarsi di posizionamenti di collegamenti in tutto il sito, collegamenti su pagine duplicate o semplicemente collegamenti con lo stesso testo di ancoraggio provenienti dallo stesso sito.
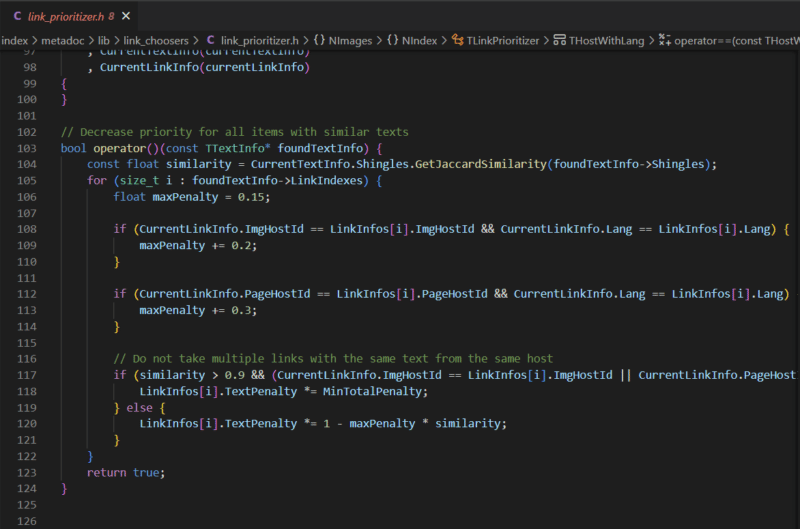
Ciò illustra quanto sia banale scartare più collegamenti dalla stessa fonte e chiarisce quanto sia importante scegliere come target collegamenti più univoci da fonti più diverse.
Cosa possiamo applicare da Yandex a ciò che sappiamo su Google?
Naturalmente, questa è ancora la domanda nella mente di tutti. Sebbene ci siano certamente molti analoghi tra Yandex e Google, in verità, solo un ingegnere del software di Google che lavora sulla ricerca potrebbe rispondere definitivamente a questa domanda.
Eppure, questa è la domanda sbagliata.
Davvero, questo codice dovrebbe aiutarci ad espandere il nostro pensiero sulla ricerca moderna. Gran parte della comprensione collettiva della ricerca è costruita da ciò che la comunità SEO ha appreso nei primi anni 2000 attraverso i test e dalle bocche degli ingegneri di ricerca quando la ricerca era molto meno opaca. Che purtroppo non ha tenuto il passo con il rapido ritmo dell'innovazione.
Gli approfondimenti dalle numerose caratteristiche e fattori della fuga di Yandex dovrebbero produrre più ipotesi di cose da testare e considerare per il posizionamento su Google. Dovrebbero anche introdurre più cose che possono essere analizzate e misurate da SEO crawling, analisi dei link e strumenti di ranking.
Ad esempio, una misura della somiglianza del coseno tra query e documenti che utilizzano gli incorporamenti BERT potrebbe essere preziosa da comprendere rispetto alle pagine della concorrenza poiché è qualcosa che i motori di ricerca moderni stanno facendo.
Proprio come i log di AOL Search ci hanno impedito di indovinare la distribuzione dei clic sulla SERP, la base di codice Yandex ci sposta dall'astratto al concreto e le nostre affermazioni "dipende" possono essere qualificate meglio.
A tal fine, questa base di codice è un dono che continuerà a fare. È passato solo un fine settimana e abbiamo già raccolto alcuni spunti molto interessanti da questo codice.
Prevedo che alcuni ingegneri SEO ambiziosi con molto più tempo a disposizione continueranno a scavare e forse riempiranno anche abbastanza di ciò che manca per compilare questa cosa e farla funzionare. Credo anche che anche gli ingegneri dei diversi motori di ricerca stiano esaminando e analizzando le innovazioni da cui possono imparare e aggiungere ai loro sistemi.
Allo stesso tempo, gli avvocati di Google stanno probabilmente redigendo lettere di cessazione e cessazione aggressive relative a tutto lo scraping.
Sono ansioso di vedere l'evoluzione del nostro spazio che è guidata dalle persone curiose che massimizzeranno questa opportunità.
Ma, ehi, se ottenere informazioni dal codice reale non è prezioso per te, puoi tornare a fare qualcosa di più importante come discutere di sottodomini contro sottodirectory.
Le opinioni espresse in questo articolo sono quelle dell'autore ospite e non necessariamente Search Engine Land. Gli autori dello staff sono elencati qui.