
Cómo aprovechar al máximo la API de Google Search Console usando expresiones regulares
Publicado: 2022-11-02Google Search Console es una herramienta increíble que proporciona datos de búsqueda invaluables por parte de usuarios reales directamente desde Google. Si bien es fácil trabajar con gráficos y tablas, no se puede acceder a una gran parte de los datos desde la interfaz de usuario.
La única forma de acceder a estos datos ocultos es usar la API y extraer todos esos valiosos datos de búsqueda que están disponibles para usted, si sabe cómo hacerlo. Esto es posible con expresiones regulares.
Así es como puede maximizar la API de Google Search Console mediante expresiones regulares, según Eric Wu, vicepresidente de crecimiento de productos de Honey, una empresa de PayPal, que habló en SMX Advanced.
Diagnóstico de problemas de SEO con GSC
¿Trabaja en un sitio web que experimenta un crecimiento estancado o en declive o una caída de actualización principal?
La mayoría de los profesionales de SEO recurren a Google Search Console (GSC) para diagnosticar tales problemas.
(O si los recursos lo permiten, incluso puede usar una herramienta paga como Ryte o crear su propia plataforma).
Afortunadamente para la comunidad de SEO, no faltan los paneles de Looker Studio (anteriormente Google Data Studio) útiles para el análisis de GSC, que incluyen:
- El panel de control gratuito de Aleyda Solis, que utiliza datos de GSC para identificar fácilmente posibles cambios en las clasificaciones en los últimos días a partir de Google Core Update.
- Panel de control de tráfico de búsqueda de Google, que ahora extrae datos de tráfico de Discover y Google News.
- Search Console Explorer Studio de Hannah Butler. (Y si desea manipular los datos de GSC de forma práctica y encontrar información rápida, puede usar la hoja del explorador de la consola de búsqueda de Butler).
Los paneles permiten a los SEO ver una descripción general de las diferentes tendencias en lugar de usar GSC y hacer varios clics para obtener los datos que necesita.
Pero si está analizando sitios empresariales, puede encontrarse con algunos obstáculos.
- Looker Studio y Google Sheets se cargan lentamente, especialmente cuando se trata de sitios grandes.
- La interfaz de GSC tiene un límite de exportación de 1000 filas.
- GSC tiene un gran problema de muestreo. Los equipos de SEO empresarial pierden el 90 % de sus palabras clave de GSC, según Similar.ai. Y si sabe cómo extraer los datos, puede obtener 14 veces más palabras clave.
Superando el problema de muestreo de GSC
Explorer for Search es otra herramienta que puede utilizar para el análisis de GSC. De Noah Learner y el equipo de Two Octobers, está diseñado con canalizaciones de datos que utilizan la API de GSC, que luego envía datos a BigQuery (básicamente, sin pasar por Google Sheets y descargando archivos CSV), y luego visualiza la información con Data Studio.
Con esto, puede estar seguro de que está obteniendo casi todos los datos.
Todavía hay una advertencia debido al problema de muestreo de GSC, especialmente para grandes sitios de comercio electrónico con muchas categorías diferentes. GSC no necesariamente mostrará todos los datos que provienen de esos directorios.
Después de realizar varias pruebas para obtener la mayor cantidad de datos de la API de GSC, el equipo de Similar.ai descubrió una forma de cerrar la brecha de muestreo de GSC.
Descubrieron que al agregar más subdirectorios como diferentes perfiles dentro de su tablero de GSC, puede extraer aún más datos ya que Google le brinda más información en ese nivel inferior.
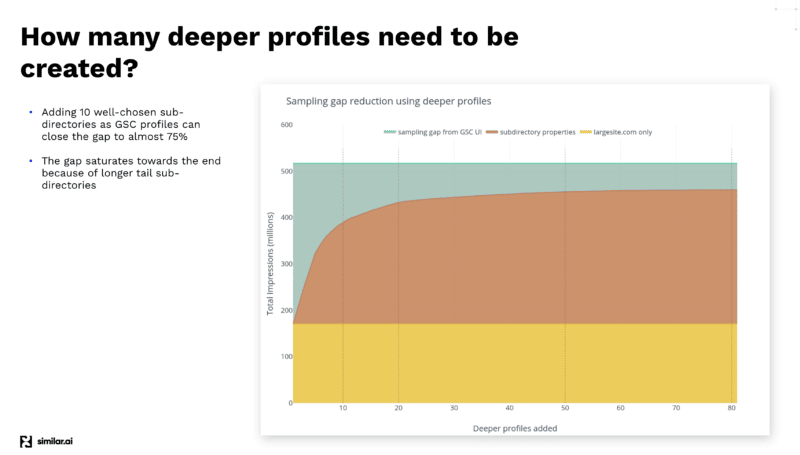
Por ejemplo, si está buscando en example.com/televisions y agrega "televisiones" como un subdirectorio en su perfil de GSC, Google le dará solo las palabras clave y la información de clics para ese subdirectorio y hacia abajo.
Y al agregar muchos de estos diferentes subdirectorios, puede extraer mucha más información.
Eso resuelve el problema del muestreo, pero puede obtener aún más datos usando expresiones regulares.
Obtener más datos de GSC con expresiones regulares
La expresión regular, o regex, es una herramienta poderosa para comprender sus datos.
En abril de 2021, Google agregó compatibilidad con expresiones regulares a GSC, lo que brinda a los SEO más formas de dividir los datos de búsqueda orgánicos.
Muchas veces, los datos no son útiles a menos que puedas comprenderlos. Y regex ayuda a extraer información procesable de los datos enriquecidos de GSC.
Pero a pesar de lo poderosa que puede ser, la expresión regular puede ser difícil de aprender.
El mejor lugar para comprender y profundizar en las expresiones regulares es la documentación oficial de Google en GitHub. (Google usa RE2 en sus productos, que es una especie de expresión regular).
Si bien la expresión regular está disponible en todo tipo de lenguajes de programación diferentes, la encontrará en casi todas partes, incluso para aquellos que modifican archivos .htaccess.
En las siguientes secciones, se muestran casos de uso para aprovechar expresiones regulares para GSC.
Consultas informativas Regex
Al mirar las consultas de búsqueda informativas reales en GSC, normalmente desea comprender:
- ¿Cómo llegan realmente las personas a su sitio?
- ¿Qué preguntas están extrayendo?
Mirar esas cosas desde un punto de vista único, dentro de GSC puede ser difícil.
Siempre estás buscando las palabras "qué", "cómo", "por qué" y luego "cuándo".
Hay un par de formas de hacer que la extracción de consultas informativas sea menos tediosa con expresiones regulares.
Daniel K. Cheung compartió una cadena de expresiones regulares que le mostrará todas las consultas que contienen "qué", "cómo", "por qué" y "cuándo" que obtuvieron un clic o una impresión:
-
"what|how|why|when"
Y esta cadena de expresiones regulares compartida por Steve Toth lleva el ejemplo anterior a un nivel superior:
-
^(who|what|where|when|why|how)[" "]
Puede usar esta cadena si desea capturar consultas basadas en preguntas que comienzan con "quién", "qué", "dónde", "cuándo", "por qué" y "cómo" y luego seguidas por un espacio.
Esta es una gran lista para usar cuando buscas cualquier tipo de palabra que inicie una pregunta:
- son, pueden, no pueden, podrían, no pudieron, hicieron, no hicieron, hacen, hacen, no hacen, cómo, si, es, no es, debería, no debería, era, no era, fueron, no fueron, qué, cuándo, dónde, quién, a quién, de quién, por qué, será, no será, sería, no sería
Poner todo esto en forma de expresiones regulares se vería así:
-
^(are|can|can't|could|couldn't|did|didn't|do|does|doesn't|how|if|is|isn't|should|shouldn't|was|wasn't|were|weren't|what|when|where|who|whom|whose|why|will|won't|would|wouldn't)\s
En esta cadena de 178 caracteres:
- Tiene el signo de intercalación (
^) que le indica que la consulta debe comenzar con esta palabra: - Las palabras se separan con barras verticales (
|) en lugar de comas. - Todas las palabras están entre paréntesis.
- Hay una barra invertida y la "s" (
\s) que denota un espacio después de la palabra.
Esto es bueno, pero también puede volverse tedioso.
A continuación, Wu simplificó la lista anterior de palabras para que sea más compatible con las expresiones regulares y más corta, lo que es ideal para copiar y pegar. Mantenerlo de esta manera también ayuda con la eficiencia.
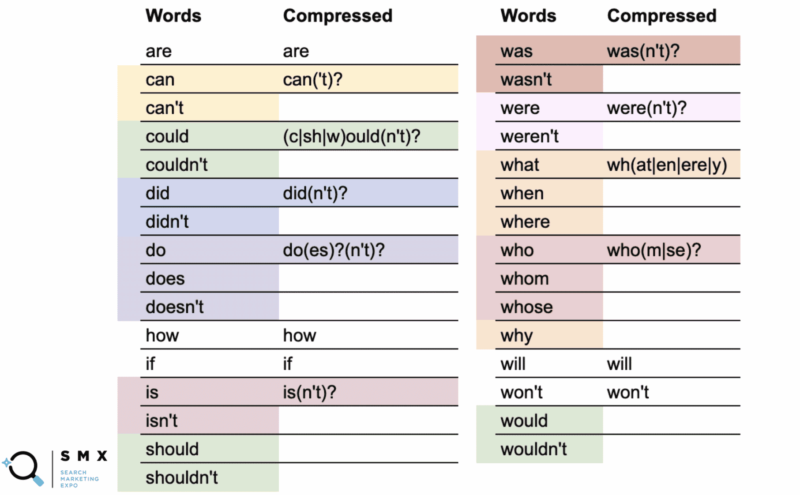
En la primera columna están las palabras normales y en la segunda columna, la expresión regular comprimida.
Por ejemplo, la palabra “can” usa la versión comprimida can('t)? .
Lo que indica el signo de interrogación es que cualquier cosa entre paréntesis es opcional. La sintaxis comprimida le permite cubrir tanto la palabra "puede" como la "no puede".
Más interesante aún, puede hacer esto con podría/no podría, debería/no debería y no haría/donde la parte -ould de las palabras es la base común, como (c|sh|w)ould(n't)? . Esta breve cadena cubre los seis casos.
Si bien la simplificación de esa larga lista de palabras hizo que la cadena fuera menos legible, lo mejor es que se ajusta más al campo de expresiones regulares y le permite copiar y pegar más fácilmente.
-
^(are|can('t)?|(c|sh|w)ould(n't)?|did(n't)?|do(es)?(n't)?|how|if|is(n't)?|was(n't)?|were(n't)?|wh(at|en|ere|y)who(m|se)?|will|won't)\s
Si vas un paso más allá, puedes comprimirlo aún más. En este caso, Wu redujo el número de caracteres de 135 a 113 caracteres.
-
^(are|can('t)?|how|if|wh(at|en|ere|y)|who(m|se)?|will|won't|((c|sh|w)ould|did(n't)?|do(es)?|was|is|were)(n't)?)\s
Las expresiones regulares pueden volverse realmente complicadas. Si está recibiendo una cadena de expresiones regulares de otra persona y le gustaría eliminar la ambigüedad de qué está haciendo qué, puede usar Regexper para ayudarlo a visualizarlo.
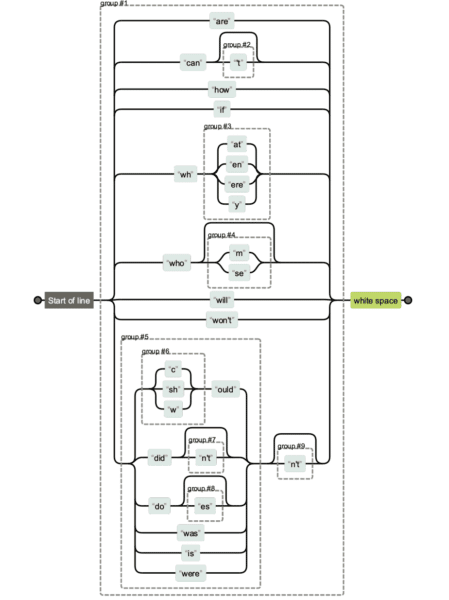
A continuación, verá una comparación de las diferentes versiones de cadenas de expresiones regulares. Es más fácil mantener el primero y obviamente más difícil mantener y leer el último.

Pero a veces el número de caracteres realmente importa, especialmente cuando tiene expresiones regulares más largas.
Los límites del filtro Regex para GSC son 4096 caracteres, según el defensor de búsqueda de Google, Daniel Waisberg.
Eso parecería bastante. Sin embargo, si tiene un sitio de comercio electrónico y tiene que agregar nombres de dominio, subdominios o directorios más largos, lo más probable es que llegue a ese límite.
Consultas de marca Regex
Otra instancia en la que puede comenzar a alcanzar el límite de caracteres de expresiones regulares en GSC es cuando lo usa para consultas de marca.

Cuando piensa en todos los diferentes tipos de errores ortográficos de una marca que una persona podría escribir, rápidamente se encontrará con ese recuento de 4096 caracteres. Por ejemplo:
- sam sung , samsung g, samsunb, samsund, samsund, samsunh, samsunt…
Aquí es donde la comprensión de expresiones regulares ayuda. Con esta cadena, puede capturar el nombre de la marca "samsung" junto con errores ortográficos:
-
(s+|a|d|z)[az\s]{1,4}m?[az\s]{1,6}(m|u|n|g|t|h|b|v)
Muchas veces, las personas escriben mal las partes medias de la palabra. Pero, en general, obtienen el formato y la longitud correctos y puede abordar su sintaxis de esta manera.
Para errores ortográficos de consulta de marca, considere lo siguiente:
- Letras principales que componen la consulta de marca.
- consonantes
- Letras que rodean consonantes duras .

En rojo están las consonantes duras que las personas normalmente no pasan por alto cuando escriben el nombre de una marca. Estas son las letras principales que componen esa marca en particular. Para "samsung", la "s" al principio, la "m" en el medio, y luego "n" y "g" al final.

Las letras azules que rodean esas consonantes principales en el teclado son las que la gente suele escribir mal. En el ejemplo, alrededor de la “s”, ves la “a”, la “d” y la “z”. (Si bien el diseño es diferente para los teclados internacionales, el concepto sigue siendo el mismo).
La cadena de expresiones regulares anterior captura todas las variantes posibles de "samsung".
El otro truco importante aquí está en [az\s]{1,4} .
En forma de expresión regular, esto básicamente dice: "Quiero hacer coincidir cualquier letra "a" con "z", o un espacio, de una a cuatro veces".
Esto captura todos esos extraños errores ortográficos que pueden ocurrir en medio de una consulta de marca, donde una persona puede presionar la misma tecla varias veces o presionar espacio accidentalmente.
Además, el nombre de la marca tiene cierta longitud ("samsung" tiene siete caracteres). Es probable que la gente no termine escribiendo entre 20 y 50 caracteres.
Entonces, en esta expresión regular, suponemos que entre "s" y "m" en "samsung", alguien va a escribir mal entre 1 y 4 caracteres. Y luego, de la "m" a la "g" al final, escribirán incorrectamente de 1 a 6 caracteres, con espacios incluidos.
Agregar todo esto le permite capturar las muchas variaciones de una consulta de marca de manera integral.
La otra cosa a tener en cuenta es que el nombre de la marca podría aparecer en diferentes partes de la consulta.

Por lo tanto, debemos asegurarnos de que se capture el nombre de la marca en sí. Debería ser:
- Al inicio de la consulta.
- En el medio de la consulta (por lo tanto, rodeado de espacios).
- O al final de la consulta.
La expresión regular para esto es la siguiente:
-
(^|\s)(s+|a|d|z)[az\s]{1,4}m?[az\s]{1,6}(m|u|n|g|t|h|b|v)(\s|$)
Esto captura todas las consultas en las que el nombre de la marca "samsung" se encuentra al principio, en el medio o al final.
- Inicio de cadena =
^ - Rodeado de espacios =
\s - Fin de cadena =
$
La publicación de JC Chouinard, Expresiones regulares (RegEx) en Google Search Console, profundiza aún más en los ejemplos de expresiones regulares.
Regex y la API de GSC en acción
Las expresiones regulares resultaron útiles para Wu y su equipo cuando trabajaron con un cliente que experimentó caídas de tráfico luego de una actualización central.
Después de analizar los diferentes problemas del sitio de comercio electrónico, descubrieron que el problema residía en algunas páginas de detalles del producto.
Necesitaban segmentar tipos de página para su análisis en GSC. Pero esta fue una tarea compleja debido a las diferentes estructuras de URL para productos estadounidenses e internacionales.

Las URL de productos internacionales del sitio incluían códigos de idioma y de país, mientras que las URL de productos de EE. UU. no lo hacían.
Incluso usar la sintaxis de expresiones regulares fue complicado porque existen letras y guiones en el slug, las categorías y las subcategorías del producto. Además, necesitaban filtrar las URL de productos internacionales para capturar solo las páginas de EE. UU.
Para obtener todas las páginas de aterrizaje + detalles de los productos de EE. UU. ( no las páginas i18n), crearon las siguientes cadenas de expresiones regulares:
Incluir: /([^/]+/){1,2}p?
Excluir: /[a-zA-Z]{2}|[a-zA-Z]{2}-[a-zA-Z]{2}/
Aquí hay un desglose:

El equipo quería hacer coincidir la categoría, la subcategoría y todos los productos, por lo que incluyeron:
- Cualquier carácter que no sea una barra inclinada =
[^/]+ - 1 o 2 directorios =
/){1,2} - A veces, seguido de un slug de producto =
p?
Un signo de intercalación ( ^ ) generalmente significa el comienzo de la cadena. Pero cuando está entre corchetes (como en [^/] ), indica una negación (es decir, "no hay nada dentro de este cuadro").
Entonces esta cadena /([^/]+/){1,2}p? significa "Quiero cualquier número de caracteres que no sea una barra inclinada, que conduzcan a una barra inclinada (que denota el directorio) y, a veces, seguidos de la letra 'p' (el prefijo de las barras de productos)".
Al mismo tiempo, el equipo no quería hacer coincidir la combinación de país e idioma que también contenía letras y guiones, por lo que excluyó:
- Cualquier directorio de 2 letras =
[a-zA-Z]{2} - Combinación de 2 letras + 2 letras lang-country =
[a-zA-Z]{2}-[a-zA-Z]{2}
Crear una expresión regular para que coincida con todos los códigos de idioma y país por sí solo sería tedioso debido a todas las combinaciones posibles, por lo que no pudieron abordar esto de la forma en que lo hicieron para las consultas informativas (donde se excluyó cada tipo de combinación).
Pero incluso después de crear estas cadenas de expresiones regulares, tenían un problema.
En Google Search Console, solo hay un campo para pegar una cadena de expresiones regulares. Tendrá que elegir Coincide con la expresión regular o No coincide con la expresión regular ; no puede usar ambas al mismo tiempo.
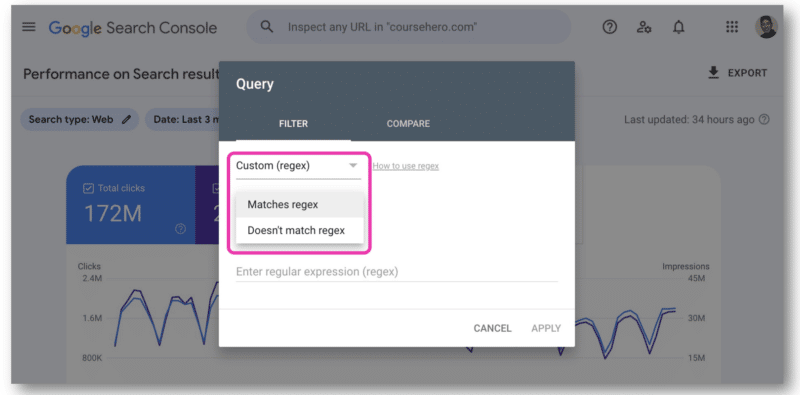
Aquí es donde la API de GSC resultó útil, ya que permite unir cadenas de expresiones regulares.
En la documentación de la API de Google Search Console, hay un enlace Pruébelo ahora .
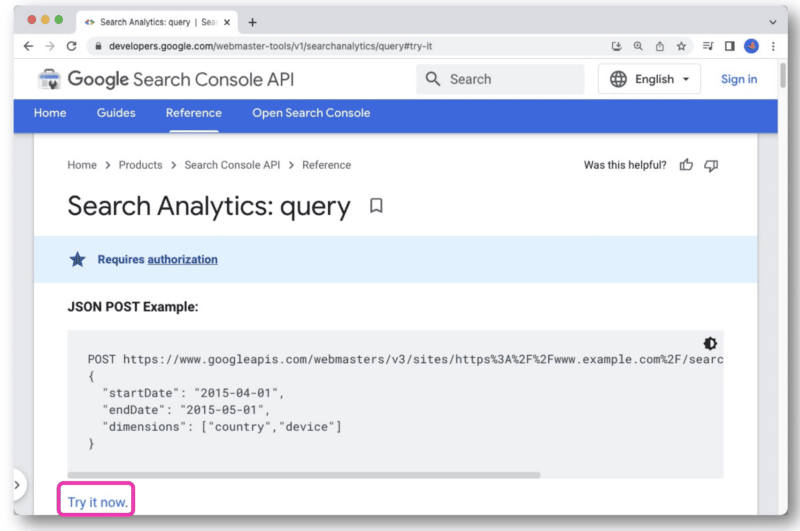
Una vez que haga clic, se abrirá una consola que le permitirá seleccionar un sitio y realizar su solicitud de API a través de la vista web.
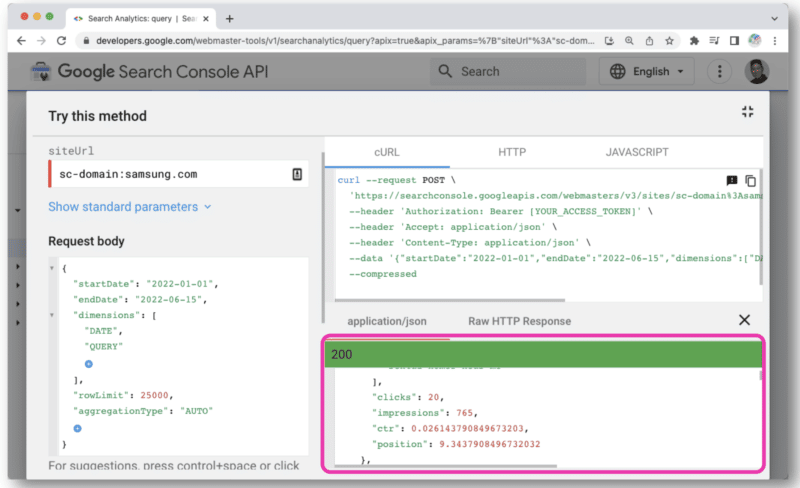
Pero para administrar mejor las consultas de API, Wu recomienda usar Postman en el escritorio o Paw (que es nativo de Mac).
Postman le permite crear consultas y guardarlas para más adelante. Y si tiene acceso a otros sitios, no tiene que crear una nueva consulta cada vez. Simplemente cambia el nombre del sitio con una variable y luego realiza varias solicitudes.
Paw, por otro lado, es mucho más fácil de ver y utilizar.
Para acceder a la API, deberá obtener sus claves de API. (Aquí hay un útil tutorial de Chouinard.)
Una vez que obtenga esta información, tendrá su ID de cliente y sus secretos de cliente, que agregará a su autenticación OAuth 2.0 dentro de Postman o Paw.
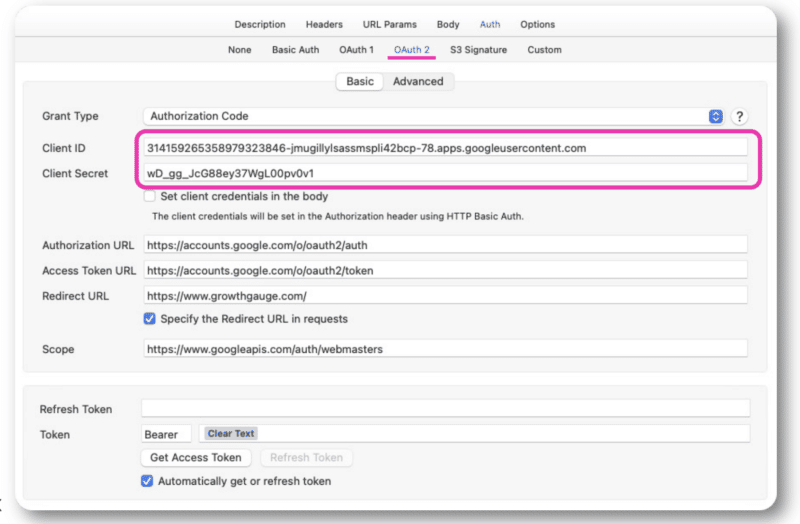
A partir de ahí, podrá iniciar sesión con su cuenta normal.
Wu realizó principalmente solicitudes de API de GSC utilizando las cadenas de expresiones regulares en Paw. La consulta se ingresa en el medio de la interfaz.
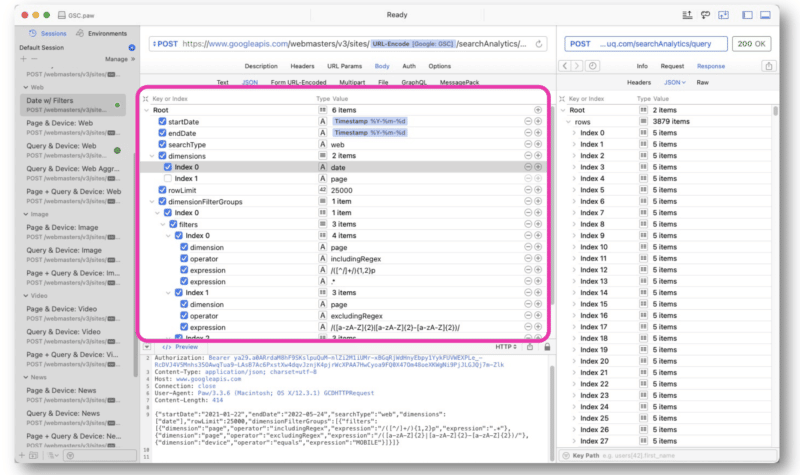
La respuesta de Google es similar a la de la vista web de la API de GSC. A continuación, los datos se pueden exportar para su procesamiento.
Dado que los datos están en JSON, la información puede ser desordenada y difícil de leer.

Para esto, puede usar un procesador JSON de línea de comandos gratuito y de código abierto llamado JQ para imprimir la información.

Los datos no son tan útiles hasta que los ingresa en una hoja de cálculo. Pipe en el archivo que ha exportado de Paw a JQ. Ábralo y luego itere sobre cada fila, guardando cada elemento para que pueda enviarlos a un CSV.
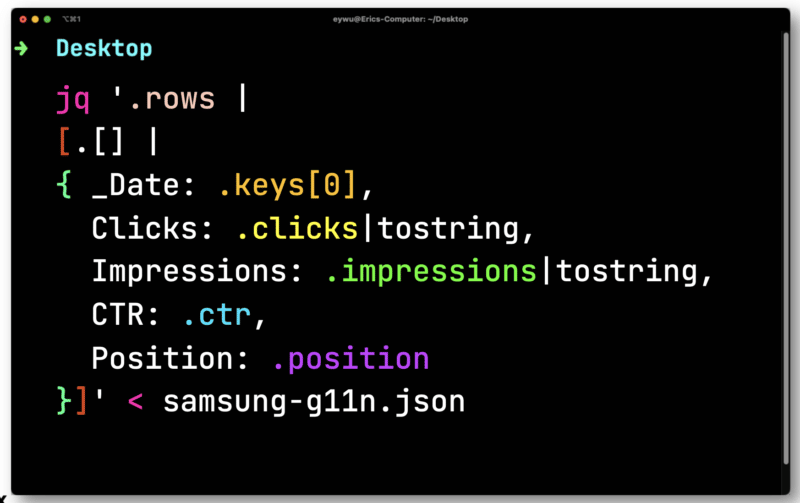
Aquí, deberá convertir los clics y las impresiones que son flotantes (un número que tiene un lugar decimal). Ambos deben convertirse en cadenas compatibles con un CSV.
JQ luego generará el siguiente formato mucho más simple.
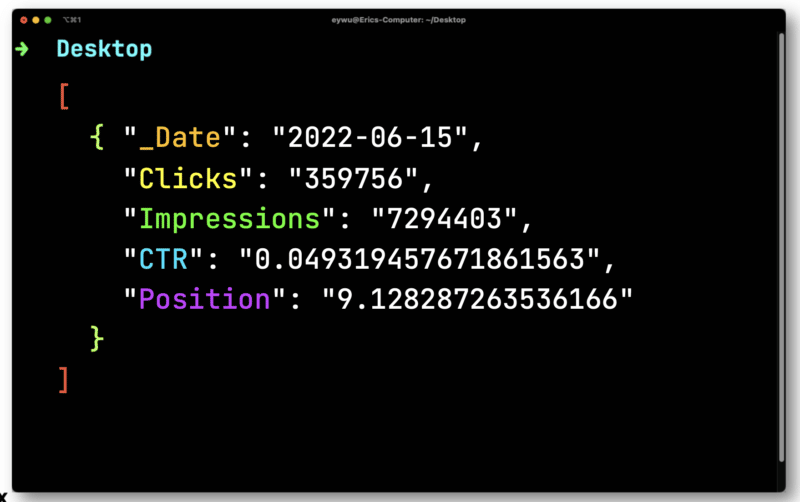
A continuación, usará Dasel para tomar este formato y luego convertirlo en un CSV.
Y aquí está el resultado final.
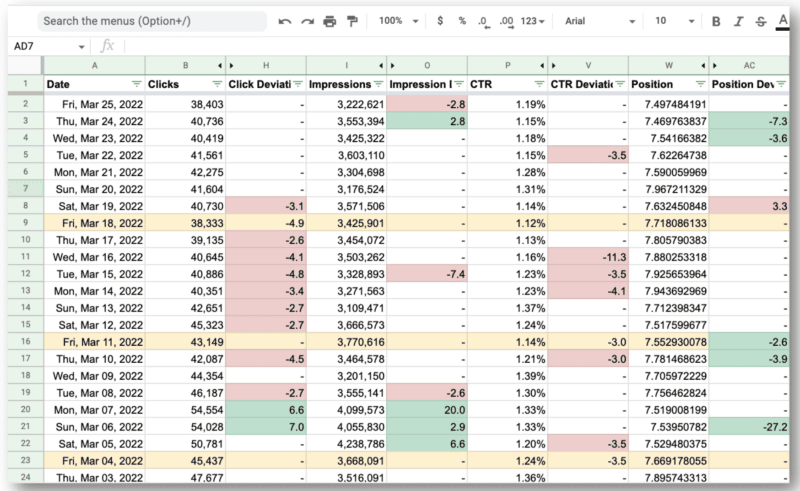
Lo sorprendente para el equipo de Wu es que pudieron usar la API de Google Search Console y las expresiones regulares para:
- Filtre todas las consultas internacionales y mire solo a los EE. UU., donde tenían los principales problemas.
- Identifique los días en que el sitio tuvo problemas.
Ver: Cómo aprovechar al máximo la API de Google Search Console
A continuación se muestra el video completo de la presentación SMX Advanced de Wu.