
Frühstück mit einer Milliarde E-Mails
Veröffentlicht: 2020-02-05Ein reibungsloser Black Friday ist alles, worum wir bitten
Als ich am Black-Friday-Wochenende jeden Tag gegen 8:00 Uhr Pacific Standard Time (PST) frühstückte, hatte Twilio SendGrid bereits mehr als 1 Milliarde E-Mails verarbeitet, berechnet in US Eastern Standard Time (EST).
Wenn wir uns die Statistiken ansehen, haben wir von Thanksgiving bis Cyber Monday über 16,5 Milliarden E-Mails verarbeitet, und über 22,3 Milliarden für die Woche, die am Dienstag vor Thanksgiving beginnt. Das sind wirklich gute Zahlen für das Geschäft. Aus der Perspektive einer technischen Organisation war es unglaublich befriedigend, dies ohne das Auslösen von Warnungen oder eine verschlechterte Kundenerfahrung zu tun.
Ich empfehle die Lektüre dieses Blog-Artikels Scaling Our Infrastructure for 4+ Billion Emails in a Single Day von meiner Kollegin Sara Saedinia, in dem es um die Bedeutung eines reibungslosen Betriebs in dieser Größenordnung für unser Unternehmen und die Unternehmen geht, die sich auf uns verlassen. Hier konzentriere ich mich auf unsere Vorbereitungen, die das kritischste Wochenende des Jahres für unsere E-Mail-Kunden zum bisher reibungslosesten gemacht haben.
Wie haben wir es zu einem nahtlosen Black-Friday-Wochenende gemacht? Die Bewältigung unserer größten Versandtage erfordert eine sorgfältige Planung, zahlreiche regionale Swing-Tests, eine Vielzahl von Personen, die Daten analysieren, und engere Feedbackschleifen, während wir Verbesserungen an unseren Systemen auf der Grundlage von Telemetriebeobachtungen validieren. Wir haben noch mehr Automatisierung und Verbesserungen, die wir vornehmen werden, um sicherzustellen, dass wir unsere Kunden weiterhin begeistern und sicherstellen, dass wir die richtigen Mitteilungen schnell an die richtigen Empfänger senden.
Unser Geschäft verstehen
Das Geschäftsmodell von SendGrid erfordert, dass wir immer aktiv sind – wir haben keine Wartungsfenster für die Annahme und Zustellung von E-Mails. Unsere Kunden benötigen einen zuverlässigen Service, der Post ohne Unterbrechung annimmt und zustellt. Das bedeutet, dass alle unsere Infrastrukturänderungen, sowohl Hardware als auch Software, durchgeführt werden müssen, während wir ohne merkliche Verzögerung mit der Verarbeitung und Zustellung von E-Mails fortfahren.
Die Anzahl der von uns verarbeiteten E-Mails ist in den letzten Jahren enorm gestiegen, wie die folgende Grafik zeigt.
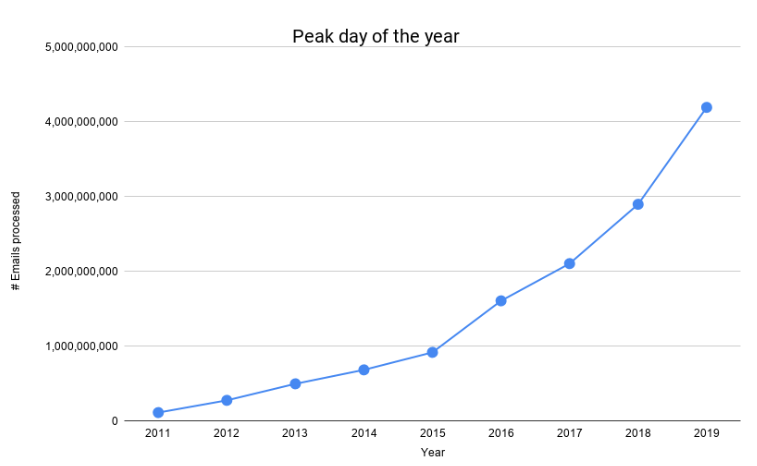
Wir hatten unseren ersten 1B-Tag Mitte 2016 und wir hatten unseren ersten 4B-Tag an diesem Black Friday. Das sind 400 % Wachstum in weniger als 4 Jahren. Um unserem ständig wachsenden Umfang Rechnung zu tragen, unsere Kosten überschaubar zu halten und unseren Kunden mehr Zuverlässigkeit zu bieten, mussten wir unsere Postverarbeitungspipeline neu gestalten und weiterentwickeln.
Der Schwarze Freitag kommt
Die Leute fragen mich: „Warum sind Black Friday und Cyber Monday so wichtig für dich?“ An diesem Cybermontag haben wir 45 % mehr E-Mails verarbeitet als am Spitzenwert des Vorjahres. Der Black Friday ist eine der wichtigsten Einzelhandels- und Ausgabenveranstaltungen in den Vereinigten Staaten. Traditionell ist es der Tag, an dem die Einzelhändler für das Jahr schwarze Zahlen schreiben (netto positiv). E-Mail-Marketing und die Verwendung von Transaktions-E-Mails sind für alle Unternehmen von entscheidender Bedeutung geworden.
Von Einzelhändlern bis hin zu Unternehmen, die Marketingautomatisierung anbieten, können Probleme bei der zuverlässigen Zustellung von E-Mails am Black Friday-Wochenende zu erheblichen Umsatzeinbußen führen. Infolgedessen ist dieses Wochenende für uns oft ein geschäftsbestimmendes Wochenende. Wir tun unser Bestes, um es unseren Ingenieuren, Supportmitarbeitern, Kundenerfolgsmanagern, Führungskräften und vor allem unseren Kunden so einfach wie möglich zu machen.
Vorbereitung auf den Schwarzen Freitag
Wie bereiten wir uns also auf den Black Friday vor? Wir kaufen T-Shirts! (Und eine Menge Arbeit erledigen.) Lesen Sie weiter, wie wir uns vorbereiten.
Mitglieder des Twilio SendGrid Irvine Office

Einige der Mitglieder des Büros von Twilio SendGrid in Denver.

Statistiken
Beginnen wir mit einigen Statistiken:
- Am Black Friday wurden über 4,1 Mrd. E-Mails und am Cyber Monday über 4,2 Mrd. E-Mails verarbeitet
- Verarbeitete mehr als 16,5 Milliarden E-Mails von Thanksgiving bis Cyber Monday
- Verarbeitete mehr als 315 Millionen E-Mails während der Spitzenzeit
- Black Friday und Cyber Monday hatten jeweils 8 aufeinanderfolgende Stunden, in denen 220 Millionen E-Mails oder mehr verarbeitet wurden
- All dies bei einer mittleren End-to-End-Zeit der zustellbaren E-Mails von 1,9 Sekunden
- Im Durchschnitt geben wir ungefähr 5,5 Ereignisse pro Nachricht aus. Basierend darauf haben unsere Systeme von Thanksgiving bis Cyber Monday mehr als 91 Milliarden Ereignisse ausgegeben und verarbeitet, allein am Cyber Monday mehr als 23 Milliarden
Die Herausforderungen
Nie zuvor gesehene Waage : Die Waage, die wir testen möchten, muss unserer vorhergesagten Spitzenlast entsprechen. Als wir Anfang April unseren ersten Test für die Vorbereitung des vergangenen Jahres durchführten, war unser durchschnittliches Volumen an Wochentagen weniger als die Hälfte unserer Spitzenvorhersage. Unsere stündlichen Spitzen waren nicht einmal die Hälfte dessen, was wir testen würden.
Verwaltung unserer Umgebungen : E-Mail ist ein zustandsbehafteter Workflow: Es ist notwendig, den Status einer Nachricht zu verfolgen. Während sich die Nachricht durch die Pipeline bewegt, verfolgen wir also, ob sie abprallt oder zurückgestellt wird, und verhindern eine Duplizierung. Daher ist unsere Mail-Pipeline eine hybride Cloud- und On-Premise-Architektur, und die automatische Skalierung ist keine magische Lösung. Unsere Herausforderung besteht darin, die Effizienz unserer Rechenzentrumsdienste zu maximieren und gleichzeitig Kapazitäten bereitzustellen, um massive Volumenspitzen zu bewältigen, ohne die Kosten für die Kunden zu beeinträchtigen.
Skalierung ist nicht linear : Nicht alle Systeme skalieren linear. Da unsere vorhergesagte Größenordnung so viel höher ist als zu Beginn des Testens, können wir unseren Hardwarebedarf nicht einfach mit einem einfachen mathematischen Modell berechnen. Es ist auch wichtig, sich daran zu erinnern, dass das blinde Skalieren von Diensten Abhängigkeiten überlasten würde, und Abhängigkeiten wie die Datenbank skalieren nicht auf die gleiche Weise wie unser Mail Transfer Agent (MTA).
Ausgleich unserer Investitionen : Da wir weiterhin innovativ sind und sicherstellen, dass wir die Kundenanforderungen in Bezug auf ihre E-Mail-Zustellung unterstützen, verstehen wir, dass unsere Funktionen unseren Kunden keinen Mehrwert bieten, wenn sie nicht zugänglich sind und nicht wie erforderlich funktionieren. Wir müssen ein Gleichgewicht finden und angemessen in das Testen, Lernen, Aktualisieren und Verbessern unserer Systeme investieren, um in unserem Umfang zuverlässig und widerstandsfähig zu sein. Wenn wir dies effizient tun, können wir weiterhin in Innovation investieren.

Wie haben wir es gemacht?
Wir haben es gemeinsam geschafft, als ein Team. Arm in Arm, wie wir sagen. Unsere diesjährigen Vorbereitungen von April bis November umfassten die Teilnahme von mehr als 100 Mitgliedern in vielen Teams. Das Modellieren von Spitzenvorhersagen, das Definieren von Beobachtbarkeitskriterien, das Lernen aus unseren Beobachtungen, das Entwickeln der notwendigen Änderungen, das Planen und Verwalten erfordert verschiedene Fähigkeiten von mehreren Personen.
Wir haben einander vertraut, während wir uns gegenseitig ehrlich gehalten haben, konzentriert geblieben sind und unsere Ziele erreicht haben.
Ein effektiver und sich ständig verbessernder Prozess war unser Freund.
Planung
Wir haben drei Rechenzentren, um die E-Mails der Kunden zu verarbeiten. Um eine unerreichte Größenordnung zu planen, validieren wir, dass wir unseren prognostizierten Spitzenverkehr mit nur zwei verfügbaren Rechenzentren bewältigen können. Um unsere Hochverfügbarkeits-SLA zu erfüllen, verfügt unsere Infrastruktur über ein integriertes Regions-Failover. Dies bedeutet, dass wir die Möglichkeit haben, den Datenverkehr zwischen Regionen umzuschalten.
Wir nutzen diese Fähigkeit mit einer häufigen Kadenz das ganze Jahr über als Standardbetriebsverfahren und beschleunigen es als Teil unserer Bemühungen, zu zeigen, dass wir in der Lage sind, Spitzenvolumina am Black Friday/Cyber Monday zu bedienen und gleichzeitig die Servicequalität aufrechtzuerhalten. Wenn sich die Systemtelemetrie dem Schwellenwert unseres Service-Level-Ziels (SLO) nähert, können wir schnell mehrere Regionen nutzen, um den Nennzustand wiederherzustellen. Wir nutzen dann die gesammelten Telemetriedaten, um festzustellen, wo wir Änderungen vornehmen müssen.
Parallel dazu hatten wir damit begonnen, unsere Service Level Objectives (SLOs), die uns ein präzises numerisches Ziel für die Systemverfügbarkeit liefern, und unsere Service Level Indicators (SLIs), die uns die Häufigkeit erfolgreicher Überprüfungen unserer Systeme angeben, zu überprüfen und zu festigen.
Beobachtungen, Erkenntnisse und Kommunikation
Jeder Test lieferte eine große Menge an Informationen. Eine der Herausforderungen, vor denen wir standen, war die effektive Dokumentation und Kommunikation der Beobachtungen zwischen den rotierenden Testteams und die anschließende Analyse der Daten über mehrere Systeme hinweg. Obwohl wir Standard-Team-Dashboards haben, könnte jedes Mitglied etwas Bestimmtes beobachten.
Wir begannen mit den Testteams eine Retrospektive durchzuführen, um alle technischen Informationen zu analysieren, die für mehrere Dienste ausgegeben wurden, die von mehreren Teams verwaltet wurden. Diese Retros waren lang und die meiste Zeit nur für ein oder zwei Teams pro Test nützlich. Wir sind schließlich dazu übergegangen, einen Slack-Thread für Retro-Notizen zu verwenden, was 10 Sekunden menschlicher Stunden an Besprechungszeit pro Test spart.
Unser Testmanagement-Team bestand aus zwei technischen Leitern, einem Architekten und einem leitenden Ingenieur. Die Manager spielten eine zentrale Rolle bei der Planung und dem Abhängigkeitsmanagement, während die eher technisch versierten Mitarbeiter bei der Verarbeitung und Analyse der Informationen auf End-to-End-Systemebene halfen.
Basierend auf der Analyse der verfügbaren Informationen haben wir iterativ validiert, dass unsere SLIs strikt mit unseren SLOs übereinstimmen. Wir haben unsere Warnungen verfeinert und bestimmte kritische Warnungen sensibler gemacht, um eine potenzielle Systembeeinträchtigung rechtzeitig zu erkennen.
Priorisierung und Umsetzung
Wir haben vorgeschlagene Änderungen mit einem Ticket versehen und die Teams haben diese Tickets priorisiert. Die erste Herausforderung bestand hier darin, diese Tickets über mehrere Team-Boards hinweg zu verwalten. Eine weitere Herausforderung bestand darin, die Arbeit am Schwarzen Freitag rücksichtslos gegenüber anderen Prioritäten zu priorisieren.
Wir mussten unseren Ingenieuren die kreative Freiheit geben, Lösungen für schwierige Probleme zu finden. Gleichzeitig mussten wir sicherstellen, dass diese Lösungen mit unseren langfristigen Plänen übereinstimmten. Es war auch sehr wichtig, dass wir uns immer aller Interessenkonflikte bewusst waren, was bedeutete, kurzfristige Lösungen zu vermeiden, die uns zurückwerfen könnten.
Die Validierung der implementierten Änderungen würde unser Ziel für kommende Tests werden.
Das Tempo beizubehalten und zu erhöhen, während wir uns dem Black Friday näherten, war eine große Herausforderung bei der Planung und Ausführung.
Die Beschleunigung
Zu Beginn des Septembers begannen wir, jede Woche mehrere Stresstests durchzuführen. Daher mussten wir Probleme schneller identifizieren, beheben und validieren. Es hat uns auch einen viel schnelleren Lern- und Anpassungszyklus ermöglicht.
Zusätzlich zu dem zuvor beschriebenen Full-Swing-Test der Mail-Pipeline haben wir zur gleichen Zeit auch mit dem Stresstest unserer unterstützenden Dienste begonnen. Im gleichen Zeitraum begannen wir mit der Durchführung von Belastungstests mit einem unserer größten Kunden, um sicherzustellen, dass unsere eingehenden Geopods ihre erwarteten Burst-Sends während der Ferienzeit ohne Bedenken bewältigen würden.
Aufgrund der langen Arbeitszeiten und der Herausforderung, die Arbeit zu verwalten, waren unsere Teams ausgebrannt. Wir haben die kritischsten Warnungen aufgelistet, die erforderlich sind, um unseren Test bei Bedarf zu stoppen, und sie sensibler gemacht. Dies ermöglichte es uns, mit unseren Tests zu beginnen, ohne dass wir früh morgens anwesend sein mussten, um unsere Systeme zu überwachen.
Geschwindigkeit mit Vorsicht
Als wir uns Ende September näherten, gab es Bedenken, dass wir uns möglicherweise nicht schnell genug in die richtige Richtung bewegen würden. Wir haben ein Tiger-Team geschaffen, ein Team von Spezialisten, das an jedem Ticket in mehreren Teams arbeiten konnte, und eines, das auf täglicher Ebene mit viel schlankeren Prozessen arbeitete.
Wir haben in Vorbereitung auf den Black Friday erhebliche Verbesserungen an unserer betrieblichen Infrastruktur sowie an unserer Postverarbeitungssoftware vorgenommen. Diese Änderungen wurden ausdrücklich priorisiert und die Teams mussten sehr gut aufeinander abgestimmt sein. Es war eine großartige Erfahrung für Leute, die SendGrid an die erste Stelle setzten. Wir nahmen Änderungen an den Anwendungen und der Infrastruktur vor und erhöhten unsere Hardwarekapazität, während wir die Kern-Engine einer Geschäftseinheit einer Aktiengesellschaft in einem Startup-Tempo betrieben. Das Beste daran ist, dass wir dies alles ohne Beeinträchtigung des Serviceerlebnisses für unsere Kunden getan haben.
Zukunftspläne
Wir haben viele menschliche Stunden damit verbracht, uns auf den Black Friday 2019 vorzubereiten. Unsere Erkenntnisse aus diesem Jahr werden uns helfen, einen Großteil unserer Vorbereitung auf den Black Friday und den Cyber Monday im Jahr 2020 zu automatisieren. Wir freuen uns auf ein weiteres erfolgreiches Jahr, gekrönt von stressfreien Rekorden -Breaking Volumina von Urlaubssendungen für unsere Kunden und unsere Mitarbeiter.